NVLink
NVLink 协议栈怎么组织、各代带宽如何演进
核心要点:
- NVLink 是 NVIDIA 专有 GPU 间高速互联协议
- 8 年 5 代,带宽从 160 GB/s 增至 1800 GB/s(11×)
- Flit 协议 256B payload 下效率 94.1%
- 小消息 (<256 KB) 由 NCCL 启动延迟主导,跑不到线速
- 节点内全连接需配合 NVSwitch
为什么 NVLink 8 年能涨 11×?
两次信号速率翻倍 + 链路数三次扩展叠加的结果。代际规格见 @tbl-hw-nvlink-gen。
| 代际 | 年份 | GPU 架构 | 信号速率 | 链路数/GPU | 单向带宽 | 双向带宽 |
|---|---|---|---|---|---|---|
| NVLink 1.0 | 2016 | Pascal (P100) | 20 Gbps/lane | 4 | 80 GB/s | 160 GB/s |
| NVLink 2.0 | 2017 | Volta (V100) | 25 Gbps/lane | 6 | 150 GB/s | 300 GB/s |
| NVLink 3.0 | 2020 | Ampere (A100) | 50 Gbps/lane (PAM4) | 12 | 300 GB/s | 600 GB/s |
| NVLink 4.0 | 2022 | Hopper (H100/H200) | 50 Gbps/lane | 18 | 450 GB/s | 900 GB/s |
| NVLink 5.0 | 2024 | Blackwell (B200/GB200) | 100 Gbps/lane (PAM4) | 18 | 900 GB/s | 1800 GB/s |
@tbl-hw-nvlink-gen NVLink 代际规格演进
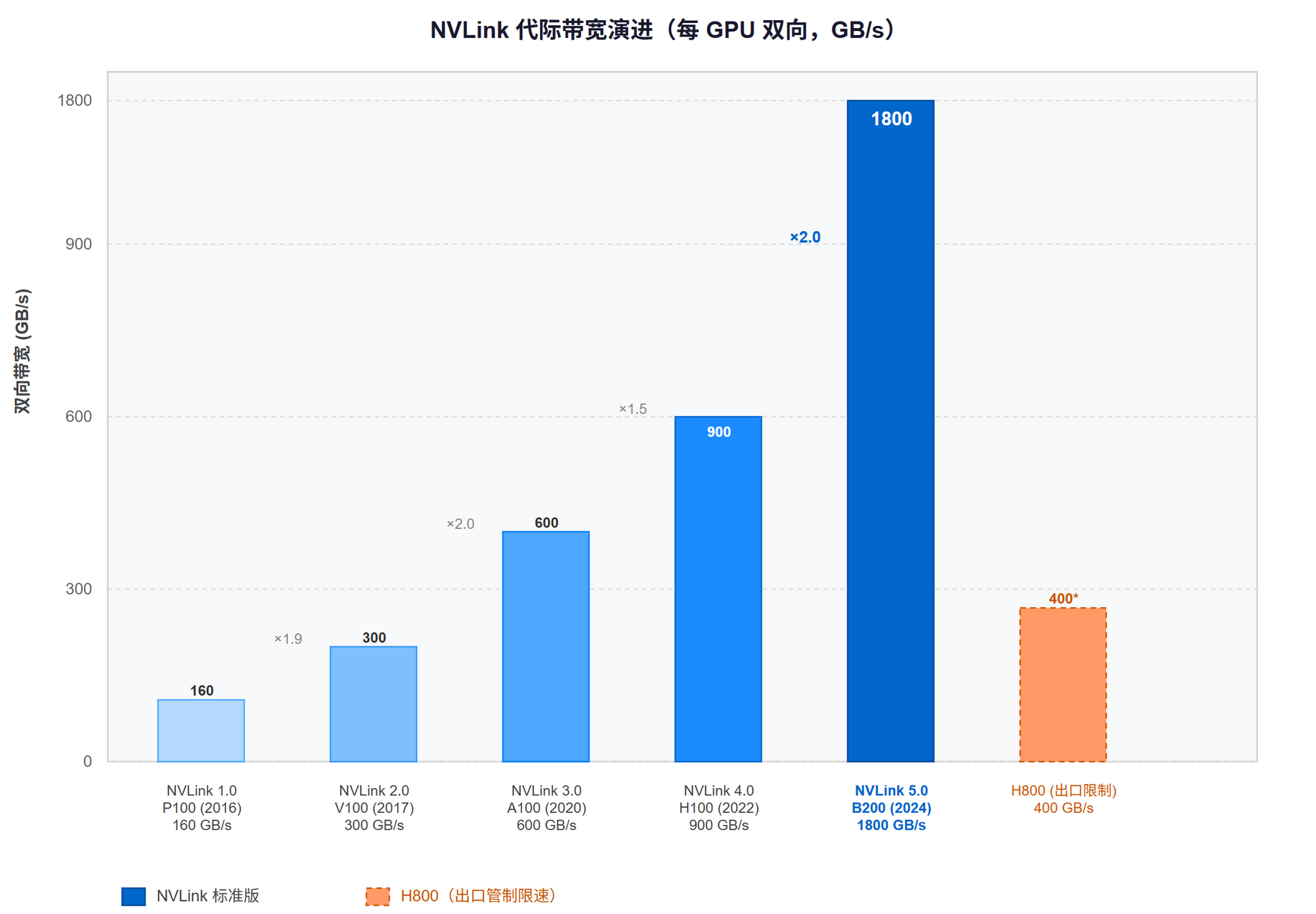
关键节点:NVLink 3.0 用 PAM4 把信号速率翻倍;NVLink 5.0 再次翻倍到 100 Gbps/lane。链路数从 4 增至 18。
出口管制:H800 是 H100 的中国版本,NVLink 带宽被限制到 400 GB/s 双向(链路数削减)。
NVLink 的协议开销长什么样?
每个数据包带 1 个 16B header flit,payload 最大 256B。Flit (Flow Control Unit) 是链路层流量控制最小单元。
- Flit 大小:128-bit (16 bytes)
- Header flit 结构:25-bit CRC + 83-bit 事务层 + 20-bit 数据链路层 (DL layer)
- 数据包结构:1 个 header flit + 可选 AE/BE flit + 最多 16 个 data payload flit
最大 payload 16 × 16B = 256B。每个数据包必须携带 1 个 header flit,构成固定开销[1]。
协议效率随消息大小怎么变?
256B payload 下效率 94.1%;小于 32B 时降至 50% 以下。效率定义:Payload Flit 数 / 总 Flit 数。明细见 @tbl-hw-nvlink-eff。
| Payload 大小 | Header Flit | Payload Flit 数 | 总 Flit 数 | 单向效率 | 双向效率 |
|---|---|---|---|---|---|
| 256B | 1 (16B) | 16 | 17 | 94.1% | 88.9% |
| 128B | 1 (16B) | 8 | 9 | 88.9% | ~80% |
| 64B | 1 (16B) | 4 | 5 | 80.0% | 66.7% |
| 32B | 1 (16B) | 2 | 3 | 66.7% | ~57% |
| 16B | 1 (16B) | 1 | 2 | 50.0% | ~40% |
@tbl-hw-nvlink-eff Flit 协议效率随 payload 大小
实际影响:NCCL 集合通信通常用 256 KB+ chunk,每次传输大量 256B 最大 flit,协议开销可忽略(>94%)。小消息 (<32B) 效率骤降,但此时软件栈启动延迟才是主导因素。
为什么小消息跑不到线速?
NCCL 启动延迟 20-60 us 是与消息大小无关的固定开销,小消息下完全主导端到端时间。
- 启动延迟来源:NCCL kernel launch + 同步开销
- 小消息行为:消息 <256 KB 时启动延迟主导,实测 AlgBW 远低于线速
- 大消息行为:消息 >4 MB 时带宽饱和,线速利用率 90-95%
- NVLS 阈值:NCCL 2.17+ 在消息 >256 KB 时自动启用 NVLS (NVLink SHARP),进一步提升 AllReduce 效率
NVSwitch 角色
核心问题:NVSwitch 在 NVLink 生态中解决什么问题、提供什么额外能力?
NVSwitch 把 GPU-to-GPU 直连扩展到节点内 All-to-All 无阻塞交叉互联。从 Gen3 (Hopper) 起内置计算引擎支持 NVLS 网内计算。
详细内容见 1.3 NVSwitch + NVLS。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 代际演进 | 5 代 8 年 11×,靠 PAM4 + 链路数双扩展 |
| Flit 协议 | 128-bit flit,1 header + ≤16 payload,最大 256B/包 |
| 协议效率 | 256B 下 94%;32B 下 67%;16B 下 50% |
| 小消息瓶颈 | NCCL 启动延迟 20-60 us 主导,与消息大小无关 |
| 节点全连接 | 需 NVSwitch,详见 03-nvswitch-nvls.md |
参考资料
- WikiChip, NVLink Microarchitecture. https://en.wikichip.org/wiki/nvidia/nvlink