厂商集群拓扑案例
NVIDIA、Google、Meta、AMD、Intel、华为六家厂商的 AI 集群拓扑选型与部署差异
核心要点:
- NVIDIA: NVSwitch 全互联 + Rail-Optimized Fat-tree (IB),带宽断崖 18-36×
- Google TPU: 3D Torus + OCS 单拓扑贯穿,无带宽断崖
- Meta: Full Mesh + 5-tier Clos (RoCE),唯一大规模选 RoCE 的厂商
- AMD: IF4 Ring 8 XCD + Dragonfly (HPE Slingshot)
- Intel Gaudi:统一 RoCEv2,21/3 端口分配仍有 7:1 带宽断崖
- 华为:HCCS (910B 8 卡) → CloudMatrix 384 (UB 全光)
- 全互联域规模竞赛:NVL72 (72) vs CloudMatrix 384 (384)
各厂商拓扑层级总览
核心问题:六大厂商在节点内、节点间、集群级的拓扑选择分别是什么?一张表如何概括?
| 厂商 | 节点内拓扑 | 互联协议 | 集群级拓扑 | 带宽断崖 |
|---|---|---|---|---|
| NVIDIA | NVSwitch Full Mesh (H100: 8 GPU 900 GB/s, NVL72: 72 GPU 1800 GB/s) | ConnectX-7/8, IB NDR/XDR 400-800 Gbps | Rail-Optimized Fat-tree, 100K+ GPU, SHARP | 18-36× |
| Google TPU | 无节点概念,所有芯片 ICI 直连 (2.4-9.6 Tbps/chip) | ICI 自研,跨 rack OCS | 3D Torus + OCS (v5p: 8960, Ironwood: 9216) | 无断崖 |
| Meta | NVLink + NVSwitch (Grand Teton: 8 GPU 900 GB/s) | RoCE v2 400GbE,成本低 30-50% | 5-tier Clos Spine-Leaf, 35K+ GPU | ~18× |
| AMD | IF4 Ring 8 XCD (MI300X:相邻 200, RCCL 750-800 GB/s) | PCIe Gen5 / 以太网 ~63 GB/s | HPE Slingshot Dragonfly (El Capitan: 44,544 MI300A) | ~32× |
| Intel Gaudi | RoCEv2 Full Mesh (21 端口 scale-up, 8 芯片 4.2 Tbps) | RoCEv2 200GbE (3 端口 scale-out) | Fat-tree 以太网 | 7:1 |
| 华为昇腾 | HCCS/UB Full Mesh (910B: 8×~400 GB/s, CM384: 384×2.8 Tbps 全光) | RoCEv2 400 Gbps | CloudEngine Spine-Leaf | 待测 |
@tbl-topo-vd-overview 厂商集群互联拓扑层级对比
NVIDIA:全互联 + Fat-tree 怎么分工?
节点内不惜成本追求全互联,节点间用成熟 Fat-tree[1]。
设计逻辑:TP 通信量最大且延迟最敏感,必须在全互联域内完成。节点间通信 (DP/PP/EP) 容忍度更高,用 Fat-tree 成熟生态。
节点内:NVSwitch 全互联
DGX H100 (8 GPU):每颗 H100 有 18 条 NVLink 4.0 (25 GB/s 单向/50 GB/s 双向),分配到 4 颗 NVSwitch 3.0,总 900 GB/s/GPU。4 颗 NVSwitch 交叉连接 8 GPU 形成逻辑全互联[2]。
GB200 NVL72 (72 GPU):
| 参数 | 值 |
|---|---|
| GPU 数 | 72 (36 Superchip × 2 B200) |
| NVSwitch 数 | 18 (NVSwitch 4.0,72 端口/颗) |
| 每 GPU NVLink 链路 | 18 (NVLink 5.0, 50 GB/s/link) |
| 每 GPU 双向带宽 | 1,800 GB/s |
| 物理构成 | 1 rack: 18 compute trays × 4 GPUs + 9 Switch trays |
@tbl-topo-vd-nvl72 GB200 NVL72 参数
为什么 72: 36 Superchip × 2 GPU,受 D2D 链路和机架空间限制。NVSwitch 4.0 有 72 端口,18 颗提供 1296 端口恰好连接 72 GPU × 18 links。128 GPU 功耗散热超出单 rack[3]。
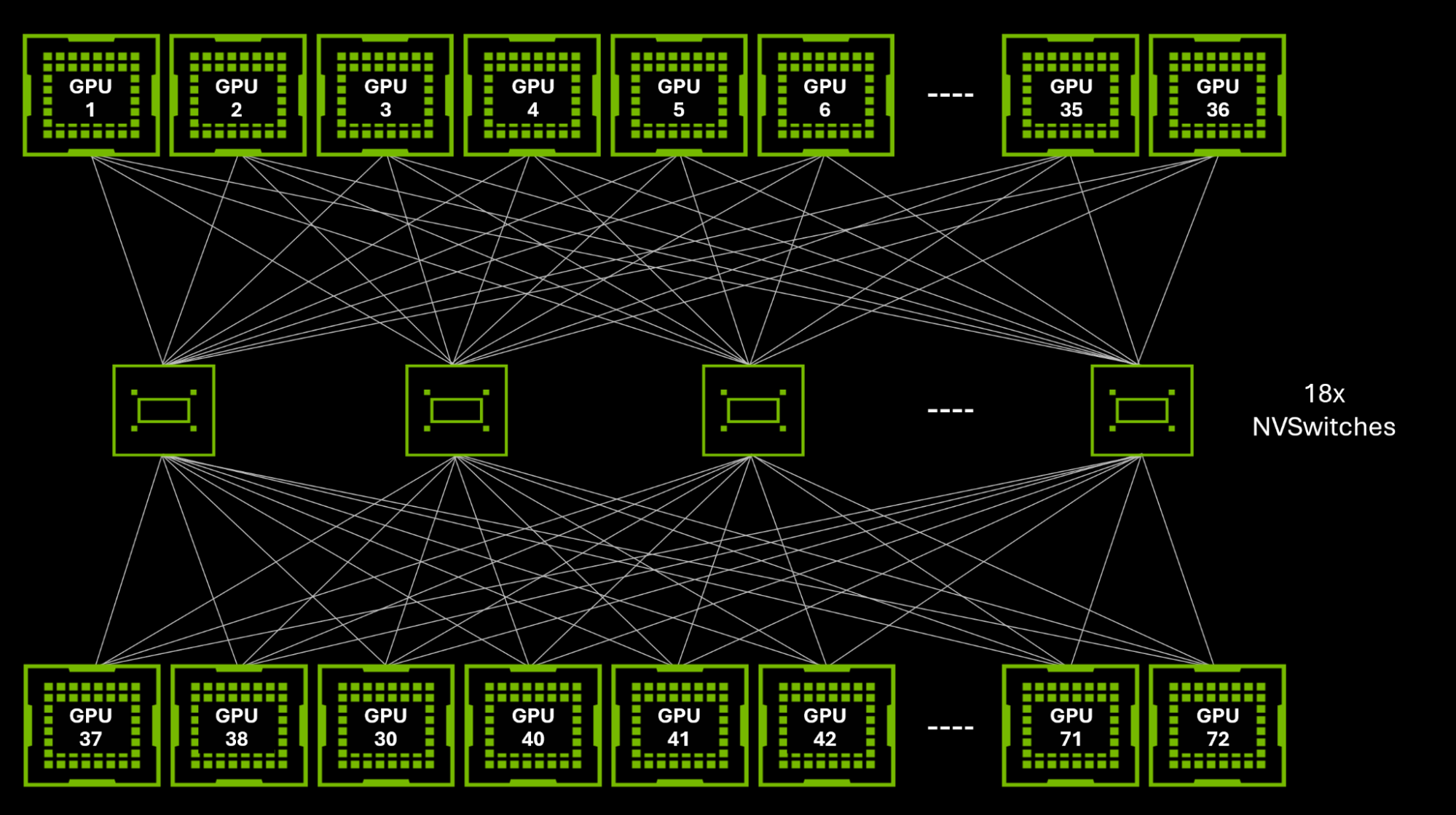
演进 (@tbl-topo-vd-nv-gen):
| 系统 | 规模 | 实现方式 | 每 GPU 带宽 |
|---|---|---|---|
| DGX A100 | 8 GPU | 6× NVSwitch 2.0 | 600 GB/s 双向 |
| DGX H100 | 8 GPU | 4× NVSwitch 3.0 | 900 GB/s 双向 |
| GB200 NVL72 | 72 GPU | 18× NVSwitch 4.0 | 1,800 GB/s 双向 |
@tbl-topo-vd-nv-gen NVIDIA 节点内拓扑代际
节点间:Rail-Optimized Fat-tree
SuperPOD (H100) (@tbl-topo-vd-superpod):
| 层级 | 组件 | 连接方式 |
|---|---|---|
| 节点内 | 8 GPU + 4 NVSwitch | NVLink 4.0 全互联,900 GB/s/GPU |
| 节点间 (同 Rail) | 所有节点的 GPU_i → ToR Rail-i | ConnectX-7 400Gbps IB NDR |
| 跨 Rail | ToR → Spine | IB NDR 400Gbps |
| 跨 SuperPOD | Spine → Core | IB NDR 400Gbps |
@tbl-topo-vd-superpod SuperPOD 层级
Rail-Optimized 设计要点:
- 每 DGX H100 的 8 GPU 各有一个 ConnectX-7 NIC (400Gbps)
- 同编号 GPU 连同一 ToR (称 Rail)
- DP AllReduce 天然在 Rail 内完成,不需 Spine
- Spine 只处理 TP/PP 跨节点和少量跨 Rail 流量
带宽断崖:NVLink 900 GB/s vs IB 400Gbps (50 GB/s) = 18:1。这是并行策略映射的核心约束 — TP 必须在 NVLink 域内,PP/DP 走网络。NVL72 断崖更大:1,800 GB/s vs 400Gbps = 36:1。
SHARP 网内计算
NVIDIA SHARP 在 IB Quantum 上实现网内 AllReduce[4] (@tbl-topo-vd-sharp):
| 指标 | 无 SHARP | 有 SHARP |
|---|---|---|
| AllReduce 延迟 | $2 \log_2 N \cdot \alpha$ | $\log_2 N \cdot \alpha$ |
| 网络总传输量 | $2 \cdot \frac{N-1}{N} \cdot M$ | $\frac{N-1}{N} \cdot M$ |
| 实测改善 | 基准 | 延迟降 2×,有效带宽提升 30-50% |
@tbl-topo-vd-sharp SHARP 性能
SHARP 要求 Mellanox/NVIDIA Quantum IB 交换机,是 NVIDIA IB 生态的护城河之一。
实测和典型集群
| 配置 | 消息大小 | AllReduce 带宽 | 来源 |
|---|---|---|---|
| 8× H100 NVLink | 1 GB | ~450 GB/s (bus BW) | NVIDIA 官方 |
| 32× H100 IB NDR | 1 GB | ~380 Gbps (per GPU) | nccl-tests |
| NVL72 NVLink | 1 GB | ~839 GB/s (bus BW) | CoreWeave nccl-tests |
| NVL72 AllGather | 1 GB | ~1,600 GB/s (bus BW) | CoreWeave nccl-tests |
@tbl-topo-vd-nv-bench NVIDIA 实测数据
典型集群 (@tbl-topo-vd-nv-cluster):
| 集群 | 规模 | 节点内 | 节点间 |
|---|---|---|---|
| NVIDIA Eos | 10,752 H100 | NVSwitch 全互联 | IB NDR Fat-tree |
| xAI Colossus | 100,000 H100 | NVSwitch 全互联 | IB Fat-tree |
| CoreWeave | 1,440 B200 | NVL72 | IB XDR + SHARP |
| Meta RSC | 16,384 A100 | NVSwitch 全互联 | IB HDR Fat-tree |
| Oracle OCI | ~16,000 H100 | NVSwitch 全互联 | IB NDR Fat-tree |
@tbl-topo-vd-nv-cluster NVIDIA 典型集群
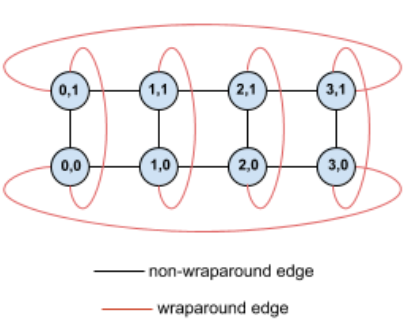
Google TPU:为什么用 3D Torus 单拓扑到底?
自研 TPU 芯片可集成 ICI 端口,无需外部交换机直接构建 Torus[5]。
所有 TPU 芯片地位平等,不区分"节点内"和"节点间"。跨机架用 OCS 光路交换将电信号转为光信号传输,逻辑上仍是 Torus 一部分。
TPU 代际演进
| 代际 | 拓扑 | 维度配置 | Pod 规模 | 每芯片 ICI 带宽 | 关键变化 |
|---|---|---|---|---|---|
| v2 (2017) | 2D Torus | 16×16 | 256 | ~500 Gbps | 首个 TPU Pod |
| v3 (2018) | 2D Torus | ~32×32 | 1,024 | ~656 Gbps | 规模 4× |
| v4 (2020) | 3D Torus | 4×4×4 cube, OCS 重配 | 4,096 | ~2.4 Tbps | 加入 OCS 层 |
| v5p (2023) | 3D Torus | 16×20×28 | 8,960 | ~4.8 Tbps | 最大 Torus Pod |
| Trillium v6e (2024) | 2D Torus | 16×16 | 256 | ~6.4 Tbps | 回退 2D,带宽提升 |
| Ironwood v7 (2025) | 3D Torus | 多维 | 9,216 | ~9.6 Tbps | 最大 ICI 带宽 |
@tbl-topo-vd-tpu-gen TPU 代际演进
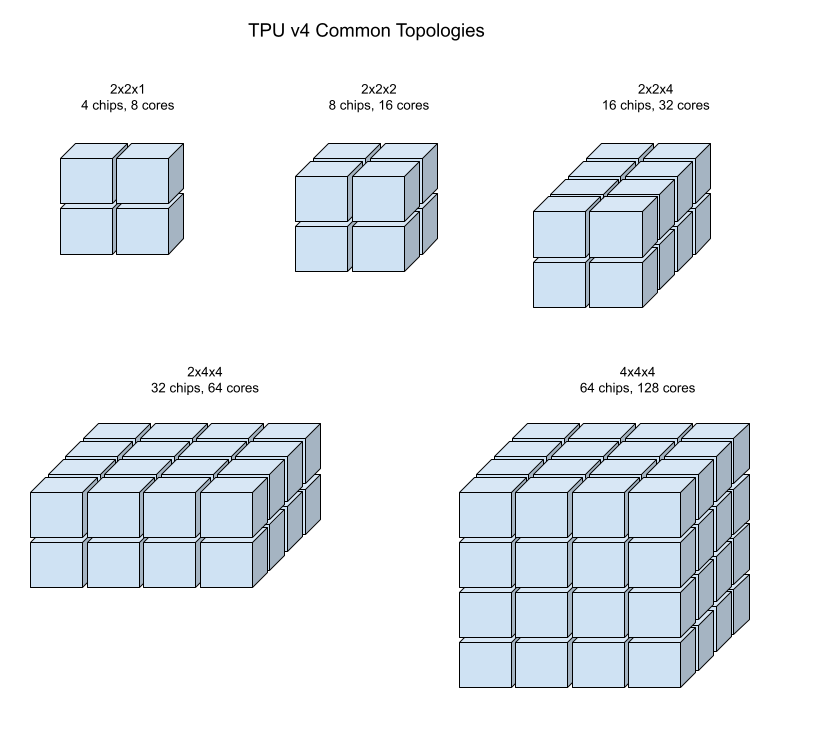
TPU v4: 4×4×4 cube + OCS 重配
- 每颗 v4 有 6 个 ICI 端口 (3 维 × 2 方向),每端口 ~400 Gbps,总 ~2.4 Tbps
- 基本块 4×4×4 cube (64 chips),物理上一个 rack
- cube 间通过 OCS 动态连接,可灵活组合 (8×8×64, 4×16×64 等)
OCS 层:每 4×4 slice 有 16 颗芯片的 Z 维出口端口,OCS 动态连到其他 slice 对应端口。支持将 4096 芯片灵活划分为多个独立 Torus 子集群 (如同时跑 4×4×128 和两个 4×4×64)。
Trillium v6e 为什么回退到 2D?
- 每芯片 ICI 带宽提升至 ~6.4 Tbps,4 个 ICI 端口 (2D × 2 方向)
- 回到 2D Torus (16×16 = 256 chips/pod),大规模扩展完全交跨 Pod OCS
- 设计哲学转变:Pod 内用高带宽小规模 Torus,Pod 间用 OCS 弹性扩展
与 NVIDIA 方案对比
| 维度 | NVIDIA | Google TPU |
|---|---|---|
| 节点内拓扑 | Full Mesh (NVSwitch) | 无"节点内"概念 |
| 节点间拓扑 | Fat-tree (IB) | 同一 Torus |
| 带宽断崖 | 18-36× (NVLink vs IB) | 无断崖 |
| 交换机 | 需大量 IB 交换机 | 无交换机 (直连 Torus) |
| 灵活性 | 标准化、多厂商 | 自研、定制化 |
| AllToAll 效率 | 高 (Fat-tree 全割集) | 低 (Torus 割集不足) |
| 网络成本占 TCO | 30-40% | <10% |
@tbl-topo-vd-nv-vs-tpu NVIDIA vs Google TPU
Meta:为什么选 RoCE 而非 IB?
Meta 是唯一大规模 AI 训练集群主动选 RoCE 的厂商[6][7]。
动机:
- 供应商多样性:避免锁定 NVIDIA/Mellanox 生态
- 运维一致性:AI 训练与存储、管理流量共用同一以太网
- 成本:以太网交换机比 IB 便宜 30-50%
- 开源控制:Arista/Broadcom 交换机 + 自研 SDN
网络架构
| 参数 | 值 |
|---|---|
| 拓扑 | 5-tier Clos |
| 过订阅比 | 1:1 (全带宽无阻塞) |
| 拥塞控制 | PFC + ECN + DCQCN + E-ECMP |
| 负载均衡 | ECMP + 自适应包喷射 |
| 交换机 | Arista 7800R3 (Spine) + 7060X5 (Leaf) |
| 单 GPU 上行 | 400GbE × 1 NIC |
@tbl-topo-vd-meta Meta 网络架构
5-tier 而非 3-tier 的原因:35K+ GPU 端口数超 3-tier Fat-tree 在 400GbE 下的容量。5-tier (Leaf → T1-T4 Spine) 提供足够端口密度。
RoCE vs IB 权衡
| 维度 | RoCE (Meta) | IB (NVIDIA) |
|---|---|---|
| 交换机成本 | ~$625-860/port | ~$940-1170/port |
| 拥塞控制 | 软件 (DCQCN) | 硬件 (Credit-based) |
| 无损保证 | 需 PFC + ECN 调优 | 原生信用流控 |
| 网内计算 | 无 | SHARP |
| 生态锁定 | 多厂商 | 单厂商 |
@tbl-topo-vd-roce-vs-ib RoCE vs IB
E-ECMP: Meta 在标准 ECMP 基础上开发增强版,结合自适应包喷射,在 Elephant flow 场景下将链路利用率从 ~60% 提升至 ~90%。
Llama 3 实测:16,384 颗 H100 训练 Llama 3 405B,整体 MFU 38-43%。网络是主要瓶颈 — 跨节点 AllReduce 占 DP 通信 ~30%[8]。
典型集群
| 集群 | 规模 | 节点 | 网络 |
|---|---|---|---|
| Meta RSC v1 | 6,144 A100 | Grand Teton | IB HDR Fat-tree |
| Meta RSC v2 | 16,384 A100 | Grand Teton | IB HDR Fat-tree |
| Meta AI Cluster | 35,000+ H100 | Grand Teton v2 | RoCE 400GbE 5-tier Clos |
@tbl-topo-vd-meta-cluster Meta 典型集群
AMD:封装内 Ring + 集群 Dragonfly
核心问题:AMD MI300X 的封装内拓扑是什么、为什么选 Ring、集群级为什么用 Dragonfly?
MI300X 封装内拓扑
8 个 XCD 排列在中央 IOD 周围,通过 IF4 环形连接[9]:
| 参数 | 值 |
|---|---|
| XCD 数 | 8 |
| 连接方式 | 环形 (每 XCD 连相邻 2 个) |
| 相邻 XCD 间带宽 | ~200 GB/s |
| 2-hop XCD 间带宽 | ~50-70 GB/s (经中间转发) |
| 总封装内带宽 | ~896 GB/s 聚合 |
@tbl-topo-vd-mi300x MI300X 封装内拓扑
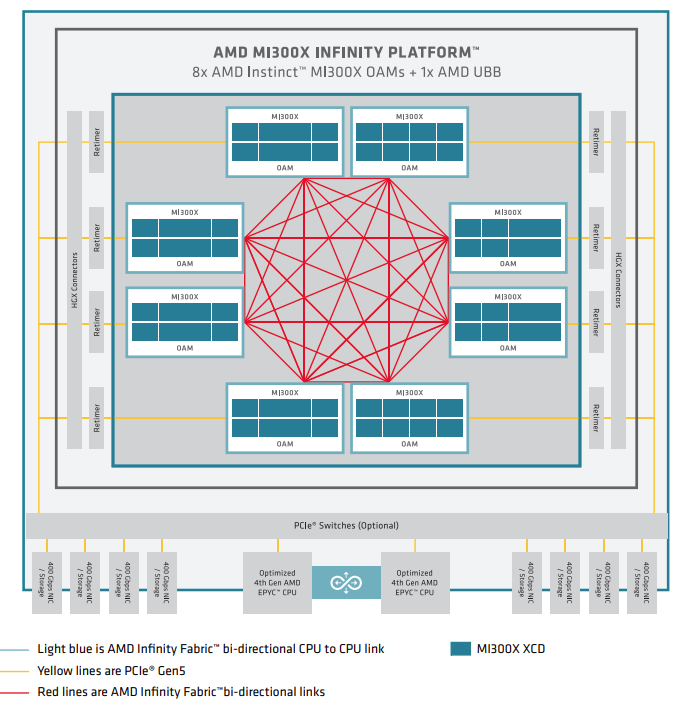
与 NVSwitch 关键差异:NVSwitch 全互联 (任意 GPU 等带宽),MI300X 环形导致非相邻 Die 带宽显著衰减。RCCL 需感知拓扑优化通信路径。
8-GPU 实测:MI300X 8-GPU 节点 RCCL AllReduce 实测 750-800 GB/s,接近理论峰值 ~896 GB/s 的 84-89%。
跨封装互联
MI300X 跨封装通过 PCIe Gen5 x16 (~63 GB/s) 或 Infinity Fabric over PCIe,远低于 NVLink。这是 AMD 方案在 TP 场景的主要短板。
集群级拓扑
AMD GPU 无自研集群互联,依赖第三方:
| 集群 | 规模 | 互联 | 拓扑 |
|---|---|---|---|
| El Capitan (LLNL) | 44,544 MI300A | HPE Slingshot-11 | Dragonfly |
| Frontier (ORNL) | 37,888 MI250X | HPE Slingshot-11 | Dragonfly |
@tbl-topo-vd-amd-cluster AMD 集群部署
AMD GPU 集群倾向 Dragonfly 而非 Fat-tree,是因 HPE Cray 集成商 Slingshot 是其自研互联。
Intel Gaudi:统一 RoCEv2 拓扑
核心问题:Intel Gaudi 为什么选全 RoCEv2 统一拓扑、不用专用互联协议?
Gaudi 是唯一不区分节点内/节点间互联协议的方案 — 全部 RoCEv2[10]。
Gaudi3 架构
| 参数 | 值 |
|---|---|
| 每芯片 RoCEv2 端口 | 24 × 200Gbps |
| 片上以太网交换引擎 | 内置 |
| 端口分配 | 21 端口 scale-up + 3 端口 scale-out |
| 节点内连接 | 8 芯片用 21 端口/芯片全互联 Mesh (每对 3 条链路) |
| 节点间连接 | 3 端口/芯片连外部以太网交换机 |
| 每芯片聚合带宽 | 4.8 Tbps (24 × 200G) |
| 节点内带宽 | 4.2 Tbps/芯片 (21 × 200G) |
| 节点间带宽 | 600 Gbps/芯片 (3 × 200G) |
@tbl-topo-vd-gaudi3 Gaudi3 架构
21/3 端口分配决定 7:1 带宽断崖:协议相同 (都是 RoCEv2),但物理端口数量不对称仍造成带宽层级差异。
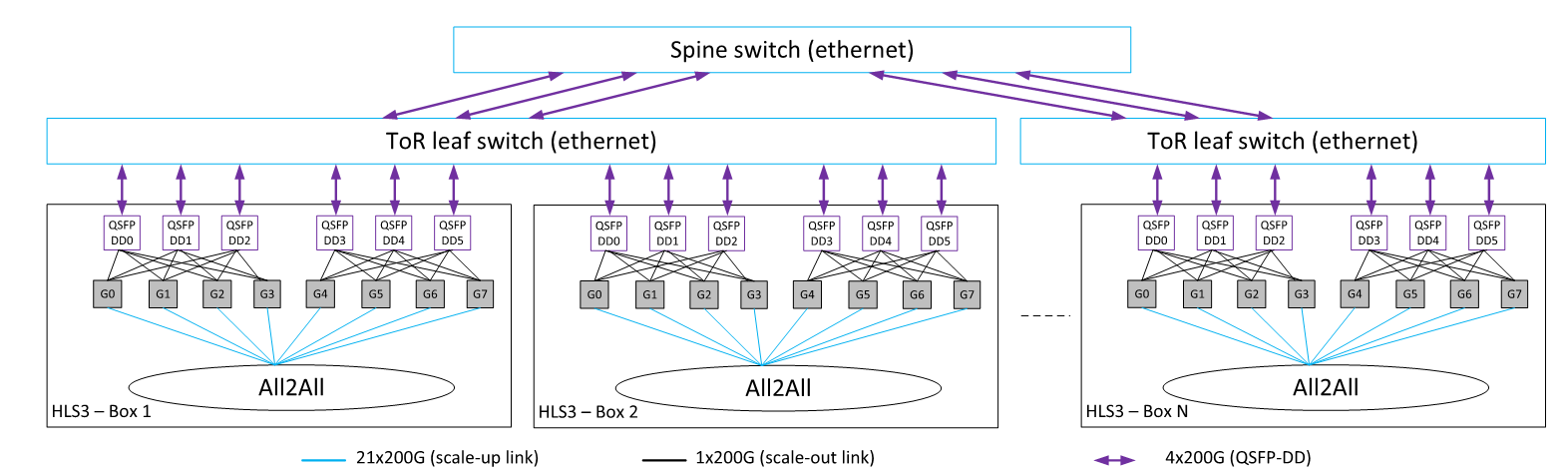
统一协议权衡:
| 维度 | 优势 | 劣势 |
|---|---|---|
| 协议统一 | 节点内外同一协议,运维简单 | - |
| 扩展平滑性 | 8 到数百芯片通信模式一致 | - |
| 带宽断崖 | - | 21/3 仍 7:1 |
| 节点内带宽 | - | ~525 GB/s 双向,低于 NVLink 900-1800 |
@tbl-topo-vd-gaudi-tradeoff Gaudi 统一协议权衡
华为昇腾:HCCS → UB-Mesh 三代演进
核心问题:华为昇腾从 HCCS 到 UB-Mesh 经历了哪三代演进、各代节点内/间拓扑如何变化?
三代技术路线
| 阶段 | 产品 | 节点内互联 | 规模 |
|---|---|---|---|
| 第一代 | Ascend 910B | HCCS (电互联) | 8 NPU 全互联 |
| 第二代 | CloudMatrix 384 | UB 全光 (L1/L2 交换) | 384 NPU |
| 第三代 | UB-Mesh | 分层 nD 全互联 | 8K+ NPU |
@tbl-topo-vd-hw-gen 华为互联三代演进
UB (Ultra Bus / Unified Bus):华为自研,设计目标统一替代 PCIe / CXL / NVLink / TCP/IP。Hot Chips 2025 宣布计划开源 UB-Mesh。
Ascend 910C UB 端口规格
每颗 910C 是双 Die 封装 (两个 910B Die 集成在同一基板):
| 参数 | 值 |
|---|---|
| Die 数 | 2 |
| UB 链路/Die | 7 × 224 Gbps (原始 SerDes) |
| 总 UB 带宽/芯片 | ~2.8 Tbps (14 链路 × ~200 Gbps 有效) |
| 光模块 | 14 × 400G LPO/芯片 |
@tbl-topo-vd-910c Ascend 910C UB 端口规格
注意单位:华为 2.8 Tbps 用"比特";NVLink 5.0 的 1.8 TB/s 用"字节" (= 14.4 Tbps)。换算后 NVLink 5.0 单芯片带宽约 UB 的 5 倍,华为以规模优势 (384 NPU vs 72 GPU) 补偿单芯片带宽差距[11][12]。
CloudMatrix 384 物理架构
16 机架,384 NPU + 192 鲲鹏 CPU:
| 组件 | 数量 | 说明 |
|---|---|---|
| 计算机架 | 12 | 每机架 32 NPU (4 节点 × 8 NPU/节点) |
| 通信机架 | 4 | 容纳 L2 UB 交换芯片 |
| 总机架数 | 16 | |
| 400G 光模块总量 | 6,912 | UB 平面 5,376 + RDMA/VPC |
@tbl-topo-vd-cm384 CloudMatrix 384 物理架构
两级非阻塞交换:每 NPU (14 个 400G 光口) → 本节点 L1 UB 交换机 (7 颗) → 通信机架 L2 UB (7 子平面 × 16 芯片/平面,每芯片 48 端口)。
关键性能 ([CloudMatrix LLM Serving][13]):
- 跨节点带宽衰减 <3% (相对节点内)
- 跨节点延迟增加 <1 μs
- 支持 EP320 (跨 320 颗 NPU 的 Expert Parallelism)
UB-Mesh 分层架构 (8K+ NPU)
| 维度 | 规模 | 互联介质 |
|---|---|---|
| 1D-2D (机架内) | 64 NPU (8×8 全互联) | 无源铜缆 (~1m) |
| 3D-4D (Pod 内) | 1,024 NPU/Pod (16 机架) | 有源铜缆/光纤 |
| 5D+ (跨 Pod) | 8K+ NPU | Clos 骨干 |
@tbl-topo-vd-ub-mesh UB-Mesh 分层架构
UB-Mesh vs Clos 声明优势 (论文 Table 2):少用 98% 高基数交换机 / 少用 93% 光模块 / 成本效率提升 2.04× / 训练吞吐达 Clos 93-96%。
推理性能基准
DeepSeek-R1 671B INT8 推理 (384 NPU 全系统):
| 指标 | 数值 |
|---|---|
| Prefill 速度 | 6,688 tokens/s/NPU |
| Decode 速度 | 1,943 tokens/s/NPU (TPOT <50 ms) |
| Expert Parallelism 规模 | EP320 |
@tbl-topo-vd-cm-bench CloudMatrix 推理基准
与 NVIDIA NVL72 对比
| 指标 | CloudMatrix 384 | GB200 NVL72 |
|---|---|---|
| 加速器数 | 384 NPU | 72 GPU |
| 每芯片互联带宽 | 2.8 Tbps | 14.4 Tbps (1.8 TB/s) |
| 全互联域规模 | 384 NPU | 72 GPU |
| 互联介质 | 全光 (400G LPO) | 电气 NVLink + 光 NVSwitch 背板 |
| 系统 BF16 算力 | 300 PFLOPS | 180 PFLOPS |
| 机架数 | 16 | 1 |
@tbl-topo-vd-cm-vs-nvl72 CloudMatrix 384 vs NVL72
厂商拓扑决策总结
核心问题:六大厂商在节点内/间拓扑选择上的共同规律和关键分化是什么?
| 厂商 | 节点内 | 节点间 | 设计驱动力 |
|---|---|---|---|
| NVIDIA | Full Mesh (NVSwitch) | Fat-tree (IB) | 最大化 TP 带宽 |
| 无节点概念 | 3D Torus (ICI) | 自研芯片,消除带宽断崖 | |
| Meta | Full Mesh (NVSwitch) | 5-tier Clos (RoCE) | 供应商多样性,运维统一 |
| AMD | Ring (IF4) | Dragonfly (Slingshot) | 依赖 HPE 集成 |
| Intel | Full Mesh (RoCEv2, 21 端口) | Fat-tree (RoCEv2, 3 端口) | 统一协议,7:1 带宽比 |
| 华为 | HCCS (910B) / UB L1-L2 (CM384) | Spine-Leaf (RoCE) | CM384 光互联跨机架 |
@tbl-topo-vd-summary 厂商拓扑决策总结
核心洞察:
- 只有 Google 真正消除带宽断崖 — 自研芯片可集成 ICI,用同一互联贯穿全 Pod。Intel Gaudi 虽协议统一,但 21/3 端口分配仍造成 7:1 带宽比
- Fat-tree 是商用 GPU 集群的唯一选择 — NVIDIA/AMD GPU 网络端口是标准 PCIe/以太网/IB,不支持直连 Torus
- Dragonfly 只在 HPC 超算中出现 — El Capitan、Frontier 用 Dragonfly 是因 HPE Cray 集成商的 Slingshot,不代表 AI 行业趋势
- RoCE vs IB 是成本-性能权衡 — Meta 和华为选 RoCE 看重成本和生态多样性,NVIDIA 推 IB 看重性能 (SHARP、硬件流控)。长期趋势偏向以太网 (UEC 在标准化 AI 训练以太网优化)
- 全互联域规模竞赛加剧 — 从 NVL72 (72) 到 CloudMatrix 384 (384) 规模快速扩大。更大全互联域 = 更大 TP 组 = 容纳更大模型 TP 分片无需跨断崖
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 6 厂商分化 | NVIDIA 全互联+FT / Google 单 Torus / Meta RoCE / AMD Ring+Dragonfly / Intel 统一 RoCEv2 / 华为 HCCS→UB-Mesh |
| 唯一无断崖 | Google TPU (自研芯片集成 ICI) |
| Fat-tree 主流 | 商用 GPU 集群唯一选择 (端口标准化) |
| Dragonfly 边界 | 仅 HPC 超算 (HPE Cray 集成) |
| RoCE vs IB | Meta 和华为选 RoCE 重成本,NVIDIA 推 IB 重性能 (SHARP) |
| 全互联域规模 | NVL72 (72) → CloudMatrix 384 (384),竞赛加剧 |
| 带宽口径陷阱 | 华为 Tbps (bits),NVIDIA TB/s (bytes),需换算才能对比 |
参考资料
- NVIDIA, DGX SuperPOD Reference Architecture. https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/dgx-superpod-components.html
- NVIDIA, DGX H100 Whitepaper. https://resources.nvidia.com/en-us-dgx-systems/ai-enterprise-dgx
- NVIDIA, GB200 NVL72. https://www.nvidia.com/en-us/data-center/gb200-nvl72/
- NVIDIA, SHARP Documentation. https://docs.nvidia.com/networking/display/shaborev300
- Jouppi N. et al., TPU v4, ISCA 2023. https://arxiv.org/abs/2304.01433
- Meta Engineering, Grand Teton Open GPU Hardware Platform, 2023-12-04. https://engineering.fb.com/2023/12/04/open-source/grand-teton-open-gpu-hardware-platform/
- Meta, RoCE at Scale, SIGCOMM 2024. https://dl.acm.org/doi/10.1145/3651890.3672233
- Meta, The Llama 3 Herd of Models, 2024. https://arxiv.org/abs/2407.21783
- Chips and Cheese, MI300X Infinity Fabric Topology Analysis, 2024. https://chipsandcheese.com/2024/01/amd-mi300x-infinity-fabric-topology-analysis/
- Intel, Gaudi3 AI Accelerator White Paper. https://www.intel.com/content/www/us/en/content-details/817486/intel-gaudi-3-ai-accelerator-white-paper.html
- UB-Mesh: Unified Bus Mesh Architecture. https://arxiv.org/html/2503.20377v1
- SemiAnalysis, Huawei AI CloudMatrix 384, 2025-04-16. https://semianalysis.com/2025/04/16/huawei-ai-cloudmatrix-384-chinas-answer-to-nvidia-gb200-nvl72/
- Serving DeepSeek-R1 on Huawei CloudMatrix 384, 2025. https://arxiv.org/abs/2506.12708