Dragonfly+
以组内 Fat-tree 替换全互联、增加多条组间链路来改进 Dragonfly 的路径多样性
核心要点:
- Mellanox (现 NVIDIA Networking) 提出,针对 Dragonfly 两个瓶颈改进
- 组内拓扑从全互联 $O(a^2)$ 改为 2 级 Fat-tree $O(a)$
- 每对 Group 全局链路从 1 改为 $s$ (子组数)
- 路径多样性提升 $s$ 倍,对 UGAL 依赖度降低
- 直径从 3 跳增至 5-7 跳
- 组间带宽接近 Fat-tree,但全局链路总数仍低
- 商用部署边界模糊 (Slingshot 有 DF+ 特征但官方称 Dragonfly)
Dragonfly+ 改了什么?
两项结构改进[1]:
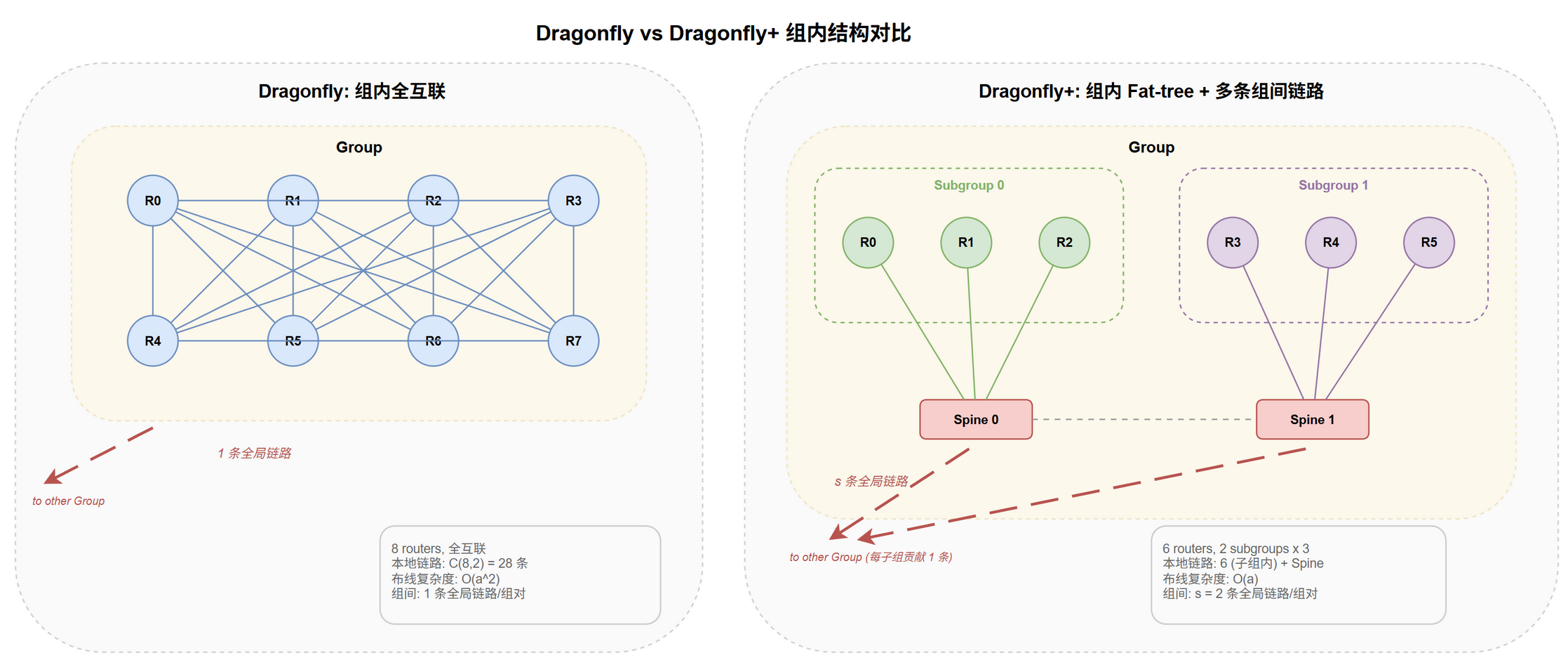
改进一:组内拓扑从全互联改为 2 级 Fat-tree。
- 原始 Dragonfly:组内 $a$ 个路由器全互联,布线复杂度 $O(a^2)$
- 痛点:$a > 32$ 时全互联线缆密度极高,工程难实现
- Dragonfly+:组内路由器划分为 $s$ 个子组 (Subgroup),通过 Spine 互联形成 2 级 Fat-tree,布线复杂度降至 $O(a)$
改进二:组间全局链路从 1 条改为 $s$ 条。
- 原始 Dragonfly:每对 Group 仅 1 条全局链路 — 对抗性流量的主要瓶颈,必须依赖 UGAL
- Dragonfly+:每对 Group 有 $s$ 条全局链路 (每子组贡献一条),路径多样性 $s$ 倍
结构对比见 @fig-topo-dfplus-cmp。
关键参数和子组结构
核心问题:Dragonfly+ 在子组划分下的度数、直径、路径多样性等关键参数相比 Dragonfly 有什么变化?
与 Dragonfly 对比 (@tbl-topo-dfplus-vs):
| 属性 | Dragonfly | Dragonfly+ |
|---|---|---|
| 组内拓扑 | 全互联 | 2 级 Fat-tree/Clos |
| 组内布线复杂度 | $O(a^2)$ | $O(a)$ |
| 每对组全局链路数 | 1 | $s$ (子组数) |
| 网络直径 (跳数) | 3 | 5-7 (组内 Fat-tree 增加跳数) |
| 路径多样性 | 低 (组间 1 条) | 高 (组间 $s$ 条独立) |
@tbl-topo-dfplus-vs Dragonfly+ vs Dragonfly
子组结构:
- 每 Group $a$ 路由器,划分为 $s$ 子组,每子组 $k = a/s$ 路由器
- 子组内:$k$ 路由器通过 Leaf 端口连终端,上行连子组 Spine
- 子组间:Spine 互联不同子组,形成组内 2 级 Clos
- 组间:每子组贡献 1 条全局链路到每个目标 Group,共 $s$ 条/组对
规模公式:$N = p \cdot a \cdot g$,$s = a/k$ 为子组数。
$s$ 倍带宽如何降低自适应路由依赖?
对抗性流量下 Minimal 吞吐从 ~10% (Dragonfly) 提升到 ~30-40% (Dragonfly+)。
- 每对 Group 之间有 $s$ 条全局链路 → 即使静态 Minimal 路由对抗性流量也能分散
- 组间带宽是原始 Dragonfly 的 $s$ 倍,典型配置 $s = 4 \sim 8$ 下接近 Fat-tree 水平
- 显著降低对自适应路由的依赖 (详见 UGAL)
代价是什么?
直径增加 + 组内硬件成本增加。
- 直径:组内 Fat-tree 把 Minimal 路径从 3 跳增至 5-7 跳 (子组内 → Spine → 全局 → Spine → 子组内)
- 大消息影响小:带宽主导场景下延迟权重低
- 小消息 AllReduce:延迟敏感场景受影响
各并行策略表现如何?
与原始 Dragonfly 类似,但组间带宽 $s$ 倍提升带来:
- DP AllReduce:跨组性能显著改善,$s$ 条链路并行传输
- EP AllToAll:仍受限于全局链路总量 (低于 Fat-tree),但比原 Dragonfly 好 $s$ 倍
详细策略适配见 2.4 Dragonfly。
成本介于 Dragonfly 和 Fat-tree 之间
核心问题:Dragonfly+ 的成本为什么落在 Dragonfly 与 Fat-tree 之间、具体差距多大?
| 成本项 | Dragonfly | Dragonfly+ | Fat-tree |
|---|---|---|---|
| 组内布线 | $O(a^2)$ (全互联) | $O(a)$ (Fat-tree) | N/A |
| 全局链路数 | $\frac{g(g-1)}{2}$ | $\frac{s \cdot g(g-1)}{2}$ | $O(N)$ Spine 链路 |
| 组内额外交换机 | 无 | 需 Spine 层 | N/A |
| 总成本趋势 | 最低 (万节点+) | 中等 | 最高 |
@tbl-topo-dfplus-cost Dragonfly+ 成本对比
核心权衡:用组内 Spine 交换机的额外成本换 $s$ 倍组间带宽提升 + 更低组内布线复杂度。
适用场景与局限
核心问题:Dragonfly+ 适合和不适合哪些并行策略和部署场景?
适用:
- 大规模集群 ($a > 32$),需要降低组内布线复杂度
- 需要比 Dragonfly 更高组间带宽 (DP AllReduce 显著)
- 希望降低对自适应路由的依赖
局限:
- 直径增加 (5-7 vs 3),延迟敏感小消息 AllReduce 受影响
- 组内硬件成本增加 (Spine 交换机)
- AllToAll 全局链路总量仍低于 Fat-tree
- 商用部署边界模糊
商用部署现状
核心问题:Dragonfly+ 在商用集群中有哪些已知部署、与 Dragonfly 的边界为什么模糊?
没有以 Dragonfly+ 名义公开部署的大规模 AI 集群。
主因:
- HPE Cray Slingshot (Frontier / Aurora 等超算) 的拓扑具有 Dragonfly+ 特征 (组间多条光链路),但 HPE 官方沿用"Dragonfly"名词
- NVIDIA 网络 (IB/Spectrum) 主推 Fat-tree 和 Rail-Optimized
- Dragonfly+ 论文来自 Mellanox (2017),NVIDIA 收购后未以独立品牌商用化
Dragonfly+ 的设计思想 (多路径全局链路、Fat-tree 子结构) 影响后续网络设计,但作为独立拓扑尚未形成商用生态。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 两项改进 | 组内 Fat-tree (布线 $O(a) →$) + 每对组 $s$ 条全局链路 |
| 路径多样性 | $s$ 倍提升,Minimal 吞吐 10% → 30-40% |
| 直径代价 | 3 跳 → 5-7 跳 |
| 组内规模 | 支持 $a > 32$,全互联难以实现的规模 |
| 商用现状 | 无独立品牌,Slingshot 具有 DF+ 特征但仍称 Dragonfly |
| 设计影响 | 多路径全局链路 + Fat-tree 子结构成为后续网络的参考 |
参考资料
- Shpiner A. et al., Dragonfly+: Low Cost Topology for Scaling Datacenters, HiPINEB 2017. https://ieeexplore.ieee.org/document/7885210