Dragonfly
分层全局链路结构及其对 UGAL 自适应路由的强依赖
核心要点:
- Kim et al. ISCA 2008 提出,用少量长距全局链路连接多个高带宽本地域
- 三级层次:终端 / 组内全互联 / 组间 1 条全局链路
- 平衡设计 $a = 2p = 2h$,直径 3 跳
- 全局链路数 $O(N^{2/3})$,是 Fat-tree Core 链路的 1/5-1/7
- 割集带宽约 Fat-tree 70%
- 必须配 UGAL 自适应路由,否则对抗性流量吞吐仅 10%
- 商用生态仅 HPE Cray Slingshot;AI 训练 MoE AllToAll 表现差
Dragonfly 基本结构是什么?
三级层次:终端 → 组内全互联 ($a$ 个路由器) → 组间全局链路 ($g$ 个 Group)[1],见 @fig-topo-df。
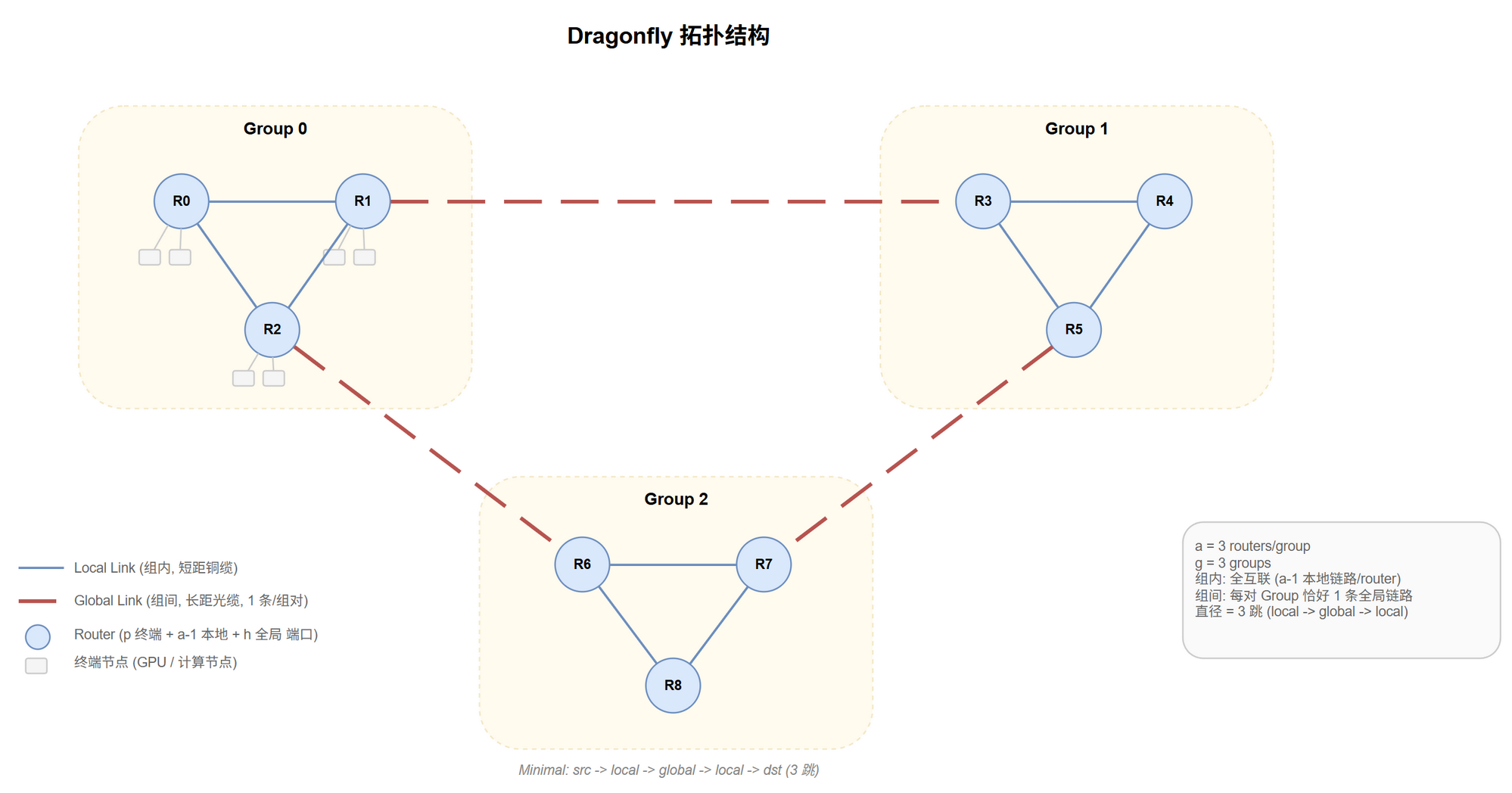
| 层级 | 组成 | 连接方式 |
|---|---|---|
| 终端节点 | GPU / 计算节点 | 通过终端端口连路由器 |
| 组内 (Group) | $a$ 个路由器 | 路由器间全互联 (Local Links) |
| 组间 (Inter-Group) | $g$ 个 Group | 通过全局链路 (Global Links) 互联 |
@tbl-topo-df-layers Dragonfly 三级层次
路由器端口分配 (总度数 = $p + (a-1) + h$):
| 端口类型 | 数量 | 连接目标 | 链路特性 |
|---|---|---|---|
| 终端端口 | $p$ | 计算节点 | 短距铜缆,成本低 |
| 本地端口 | $a-1$ | 同组其他路由器 | 短距铜缆,成本低 |
| 全局端口 | $h$ | 其他组的路由器 | 长距光缆,成本高 |
@tbl-topo-df-ports Dragonfly 路由器端口分配
为什么用平衡设计 $a = 2p = 2h$?
避免任何一类链路成为瓶颈:
- 全局链路带宽 < 本地链路带宽 → 跨组通信瓶颈
- 终端带宽 > 网络注入带宽 → 网络消化不了终端流量
平衡条件确保在均匀随机流量下,本地链路、全局链路和终端端口的利用率大致相等。
全局链路连接规则是什么?
$g = ah + 1$ 个 Group,每对 Group 恰好 1 条直连全局链路。
每 Group 有 $a$ 个路由器、每路由器有 $h$ 个全局端口,总共 $ah$ 个全局端口分配到 $g-1 = ah$ 个目标 Group — 恰好每个目标 Group 分 1 条。
这条规则意味着:
- 任意两 Group 间恰好 1 条直连
- 跨组最短路径:本组 local → 全局 → 目标组 local,共 3 跳
- 这 1 条全局链路是该 Group 对之间所有流量的唯一直连通道 — 对抗性流量下极易饱和
关键参数和规模
核心问题:Dragonfly 在平衡设计 $a = 2p = 2h$ 下的度数、直径、割集、全局链路数等关键参数的值和物理含义是什么?
平衡设计参数 (@tbl-topo-df-params):
| 属性 | 值 |
|---|---|
| 每组路由器数 | $a$ |
| 组数 | $g = ah + 1$ |
| 路由器总数 | $a \cdot g$ |
| 终端总数 | $N = p \cdot a \cdot g$ |
| 路由器度数 | $p + (a-1) + h$ |
| 网络直径 | 3 跳 (local → global → local) |
| 全局链路总数 | $\frac{g \cdot a \cdot h}{2}$ |
| 割集带宽 | $\sim 0.7 \cdot \frac{N}{2} \cdot b$ |
@tbl-topo-df-params Dragonfly 关键参数
规模示例 (@tbl-topo-df-scale):
| 配置 $(a, p, h)$ | 组数 $g$ | 终端数 $N$ | 全局链路数 | 对应规模 |
|---|---|---|---|---|
| (8, 4, 4) | 33 | 1,056 | 528 | 千卡 |
| (16, 8, 8) | 129 | 16,512 | 8,256 | 万卡 |
| (24, 12, 12) | 289 | 83,232 | 41,616 | 十万卡 |
@tbl-topo-df-scale Dragonfly 规模示例
路径分析 (@tbl-topo-df-path):
| 路由方式 | 跳数 | 路径 |
|---|---|---|
| Minimal (最短路) | 3 | src → local → global → local → dst |
| Valiant (经随机中间 Group) | 5 | src → local → global → local → global → local → dst |
@tbl-topo-df-path Dragonfly 路径分析
Minimal 经过恰好 1 条全局链路。Valiant 经过 2 条全局链路,但将流量均匀分散到所有 Group 间链路。
为什么必须配 UGAL 自适应路由?
对抗性流量下静态最短路吞吐仅 10%。
每对 Group 仅 1 条全局链路 → 某组所有节点同时向另一组发送时,该链路饱和而其他全局链路空闲。
Dragonfly 必须配 UGAL 在 Minimal 和 Valiant 之间动态切换才能有效利用全局链路。详见 UGAL 路由算法。
无死锁:Minimal 路径严格遵循 local → global → local 单调结构无回头路,天然无死锁。Valiant 的非最短路径引入环依赖,需要 2-3 个虚通道 (VC) 打破。
与 Fat-tree 相比,割集和路径多样性差距多大?
割集约 70%;每对 Group 路径数 1 vs Fat-tree 每对 Pod $k/2$。
| 规模 $N$ | Fat-tree 割集 | Dragonfly 割集 | 比值 |
|---|---|---|---|
| 1,000 | $500b$ | ~$350b$ | 70% |
| 10,000 | $5,000b$ | ~$3,500b$ | 70% |
| 100,000 | $50,000b$ | ~$35,000b$ | 70% |
@tbl-topo-df-bb Dragonfly vs Fat-tree 割集带宽
各并行策略在 Dragonfly 上表现如何?
TP 限组内,EP AllToAll 最差 (@tbl-topo-df-parallel)。
| 并行策略 | 在 Dragonfly 上表现 | 原因 |
|---|---|---|
| TP | 应限组内 | 组内全互联,带宽高、延迟低 |
| DP AllReduce | 可跨组,UGAL 有效均衡 | 流量模式相对均匀 |
| PP | 跨组可接受 | 点对点流量,不拥塞全局链路 |
| EP AllToAll | 最差场景 | many-to-many 流量压满全局链路 |
@tbl-topo-df-parallel Dragonfly 与并行策略适配
成本结构与节省
核心问题:Dragonfly 的全局链路 $O(N^{2/3})$ vs Fat-tree Core $O(N)$,成本节省来自哪、带宽代价是什么?
全局链路 $O(N^{2/3})$ vs Fat-tree Core $O(N)$,万节点+ 才有优势。
| 链路类型 | 数量 | 增长阶 | 成本 |
|---|---|---|---|
| 本地链路 | $g \cdot \frac{a(a-1)}{2}$ | $O(N)$ | 短距铜缆,低 |
| 全局链路 | $\frac{g \cdot a \cdot h}{2}$ | $O(N^{2/3})$ (平衡设计) | 长距光缆,高 |
@tbl-topo-df-cost Dragonfly 链路成本
全局链路数量对比 (@tbl-topo-df-vs-ft):
| 规模 $N$ | Fat-tree Core 链路 | Dragonfly 全局链路 | 节省倍数 |
|---|---|---|---|
| 10,000 | ~60,000 | ~12,000 | 5× |
| 100,000 | ~800,000 | ~120,000 | 6.7× |
@tbl-topo-df-vs-ft 全局链路数量对比
千节点规模下 Dragonfly 的组开销 (每组全互联布线) 反而可能高于 Fat-tree,只在万节点以上优势显著。
与 Dragonfly+ 的关键区别
核心问题:Dragonfly+ 把组内全互联改为 2 级 Fat-tree、每对 Group 全局链路从 1 升到 s,这两项改动解决了 Dragonfly 的什么瓶颈?
Dragonfly+ 把组内全互联改成 2 级 Fat-tree,让每对组多条全局链路[2]。详见 2.5 Dragonfly+。
| Dragonfly | Dragonfly+ | |
|---|---|---|
| 组内拓扑 | 全互联 ($O(a^2)$ 布线) | 2 级 Fat-tree ($O(a)$ 布线) |
| 每对组全局链路 | 1 条 | $s$ 条 (子组数) |
| 路径多样性 | 低 | 高 ($s$ 倍) |
| 直径 | 3 跳 | 5-7 跳 |
| UGAL 依赖度 | 高 | 降低 (Minimal 已可接受) |
@tbl-topo-df-vs-dfplus Dragonfly vs Dragonfly+
核心权衡:用更多组间链路和更高直径换更好负载均衡和更低自适应路由依赖。
适用场景与局限
核心问题:Dragonfly 适合和不适合哪些并行策略和部署场景?
适用:
- HPC 超算 (HPE Cray Slingshot 生态)
- 大规模 DP 密集型训练 (AllReduce 流量均匀)
- PP + DP 为主,AllToAll 不是瓶颈
- 万节点以上规模
局限:
- 割集 70%,MoE AllToAll 效率受限
- 每对 Group 1 条全局链路是单点瓶颈
- 必须依赖 UGAL,否则吞吐仅 10%
- 商用生态仅 HPE Cray Slingshot,NVIDIA IB/Spectrum 不支持
- AI 训练 MoE AllToAll 拥塞严重 — 是 AI 集群不选 Dragonfly 的主因
实际部署案例
核心问题:Dragonfly 在真实 AI/HPC 集群中有哪些代表性部署?
全部为 HPE Cray Slingshot 实现 (@tbl-topo-df-deploy):
| 系统 | 规模 | GPU | 互联 | 用途 |
|---|---|---|---|---|
| Frontier (ORNL) | 37,888 | MI250X | Slingshot-11 | HPC + AI |
| Aurora (ANL) | 63,744 | Intel GPU Max | Slingshot-11 | HPC |
| El Capitan (LLNL) | 44,544 | MI300A | Slingshot-11 | HPC |
| Perlmutter (NERSC) | 6,159 | A100 | Slingshot-11 | HPC + AI |
@tbl-topo-df-deploy Dragonfly 实际部署
以 HPC 工作负载为主 (CFD、气候、分子动力学)。承载 LLM 训练时 MoE AllToAll 效率低于 Fat-tree。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 结构 | 三级 (终端/组内/组间),每对 Group 1 条全局链路 |
| 平衡设计 | $a=2p=2h$,直径 3 跳 |
| 全局链路 | $O(N^{2/3})$,万节点+ 比 Fat-tree 省 5-7× |
| 割集 | ~70% Fat-tree |
| 路由依赖 | 必须配 UGAL,否则对抗性流量吞吐 10% |
| 商用生态 | 仅 HPE Cray Slingshot |
| AI 适配 | TP 限组内,MoE AllToAll 最差 |
| 不选 Dragonfly 主因 | MoE AllToAll 拥塞,AI 集群仍选 Fat-tree |
参考资料
- Kim J. et al., Technology-Driven, Highly-Scalable Dragonfly Topology, ISCA 2008. https://doi.org/10.1109/ISCA.2008.19
- Shpiner A. et al., Dragonfly+: Low Cost Topology for Scaling Datacenters, HiPINEB 2017. https://ieeexplore.ieee.org/document/7885210