Rail-Optimized Fat-tree
以 Rail 分域的流量感知 Fat-tree 变体——NVIDIA GPU 集群的默认互联拓扑
核心要点:
- 同编号 GPU 的 NIC 连接同一台 Leaf 交换机(称为 Rail),DP AllReduce 在 Rail 内一跳闭合
- DGX H100 SuperPOD 采用 8-Rail 结构,GB200 NVL72 采用 4-Rail SLG 结构
- 与标准 Fat-tree 相比,Spine 交换机减少 50%,总交换机减少 25%(1,024 GPU 规模)
- Intra-Rail 通信始终 1:1 非阻塞,Cross-Rail 带宽可按需过订阅(2:1~3:1)
- 2-Tier 最大 8,192 GPU(8 Rail × 64-port),3-Tier 最大 524,288 GPU
- 主要失效场景:MoE EP > 8 时 AllToAll 洪泛 Spine、多租户流量不可预测
- 学术上属于 Multiplane Fat-tree 的工业实例(arxiv 2605.21187)
设计动机
核心问题:为什么需要 ROFT?它的核心洞察是什么?
Rail-Optimized Fat-tree (ROFT) 的核心洞察:在 TP-within-node + DP-across-node 的典型并行配置下,网络流量的 80-90% 发生在同编号 GPU 之间(DP AllReduce),将这些 GPU 连到同一台 Leaf 可消除 Spine 层竞争。
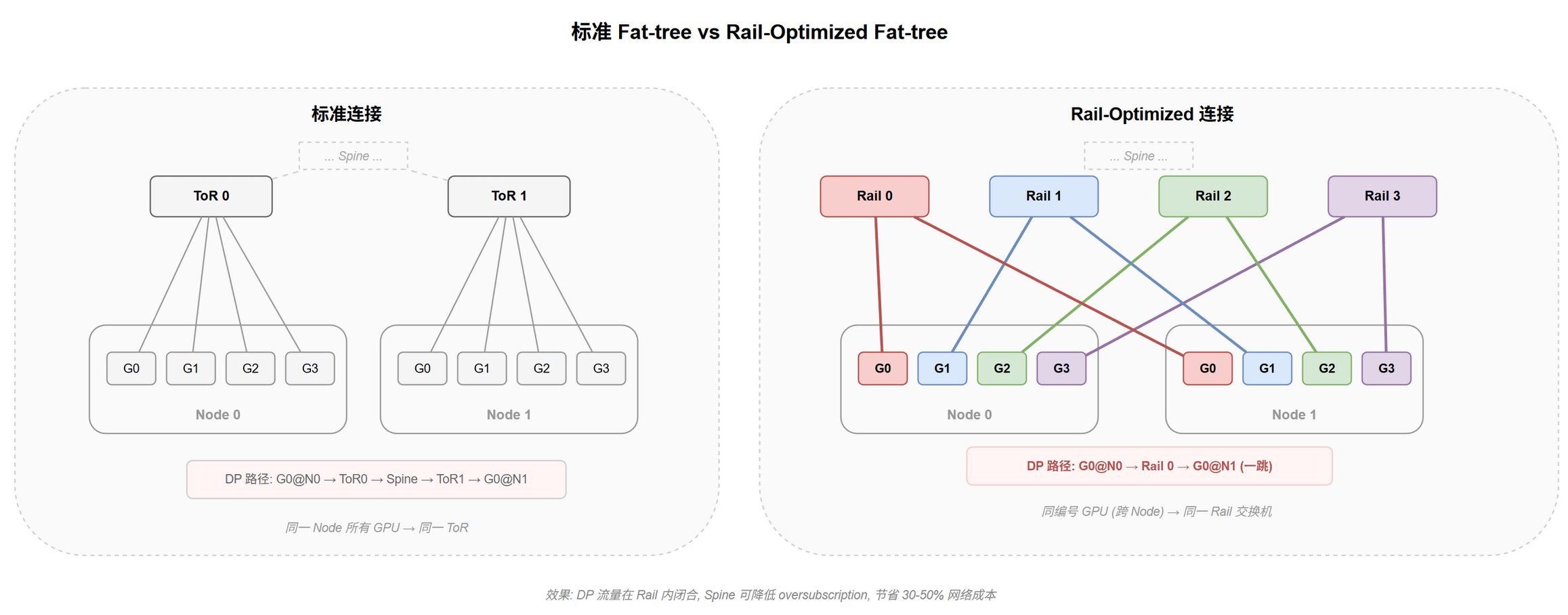
标准 Fat-tree[1] 按节点组织布线——一个节点的所有 GPU 连接同一台 ToR 交换机。DP AllReduce 的通信组由不同节点的同编号 GPU 组成,流量必须上行到 Spine 再下行到另一台 ToR,走 3 跳路径并与所有其他流量共享 Spine 带宽。
ROFT 改变接线方式——所有节点的 GPU[i] 连接到同一台 Rail Leaf[i]。DP AllReduce 流量在 Rail Leaf 交换机内部直接转发,1 跳完成,不占用 Spine 带宽。Spine 只承载跨 Rail 的少量 PP/EP 流量,可以降配。
物理上只需重新插线,交换机硬件不变。逻辑上将一棵 Fat-tree 拆成 $R$ 棵独立的 Rail-local Fat-tree + 一个共享 Spine 层。
前提条件
ROFT 依赖以下架构特征:
- 节点内全互联:NVSwitch 提供节点内 GPU 全连接,TP 通信不经网络
- 1 GPU : 1 NIC 对应关系:DGX H100 每 GPU 配一块 ConnectX-7 NIC,NIC 编号与 GPU 编号一一对应
- DP 是主要网络流量:TP 在节点内 NVLink 闭合后,DP AllReduce 是网络的主要负载
物理布线
核心问题:ROFT 的物理接线方式是什么?H100 和 GB200 有何不同?
DGX H100 SuperPOD (8-Rail)
DGX H100 每节点 8 GPU,每 GPU 对应 1 块 ConnectX-7 400 Gbps InfiniBand NIC。8 条 Rail 编号 Rail 07,分别连接所有节点的 GPU 07。
Scalable Unit (SU) = 32 节点 / 256 GPU,交换机配置见 @tbl-roft-su-switch。
| SU 数 | 节点数 | GPU 数 | Leaf | Spine | Core | 层级 |
|---|---|---|---|---|---|---|
| 1 | 32 | 256 | 8 | 4 | 0 | 2-Tier |
| 2 | 64 | 512 | 16 | 8 | 0 | 2-Tier |
| 4 | 128 | 1,024 | 32 | 16 | 0 | 2-Tier |
| 8 | 256 | 2,048 | 64 | 32 | 0 | 2-Tier |
| 16 | 512 | 4,096 | 128 | 128 | 64 | 3-Tier |
| 32 | 1,024 | 8,192 | 256 | 256 | 128 | 3-Tier |
@tbl-roft-su-switch DGX H100 SuperPOD 交换机配置(QM9700 64-port NDR 400 Gb/s)[2]
每条 Rail 是一棵独立的 2-Tier Fat-tree:
- 1 SU 内:每 Rail 有 1 台 Leaf(连 32 个同编号 GPU)+ 连接到共享 Spine
- 4 SU 时:每 Rail 有 4 台 Leaf(连 128 GPU),8 条 Rail 共享 16 台 Spine
布线规则:
$$\begin{equation} \text{GPU}[i]_{\text{node } n} \xrightarrow{\text{NIC}_i} \text{Rail Leaf}[i]_{\left\lfloor n / (k/2) \right\rfloor} \label{eq:roft-wiring-rule} \end{equation}$$其中 $k$ 为交换机端口数,$k/2$ 为每台 Leaf 的下行端口数(连接 GPU 的端口)。
GB200 NVL72 (4-Rail SLG)
GB200 NVL72 机柜内 72 GPU 通过 NVLink 5.0 + NVSwitch 4.0 全互联,构成单一 NVLink 域。对外通过 ConnectX-8 SuperNIC 连接到 InfiniBand 网络。
GB200 NVL72 的 Rail 结构与 H100 不同:
| 维度 | DGX H100 | GB200 NVL72 |
|---|---|---|
| Rail 数 | 8 | 4 |
| NIC/GPU 比 | 1:1 | 1:1(CX8 SuperNIC 18 块/机柜) |
| Rail 组织 | 按 GPU 编号 | 按 SLG(Spine-Leaf Group) |
| SU 组成 | 32 节点 (256 GPU) | 8 机柜 (576 GPU) |
@tbl-roft-h100-vs-gb200 DGX H100 vs GB200 NVL72 Rail 结构
**SLG(Spine-Leaf Group)**是 GB200 的 Rail 等价概念。每个 SU(8 机柜 / 576 GPU)内有 4 个 SLG,每个 SLG 连接每机柜中 18 个 NIC 到对应的 Leaf 组。4 个 SLG 对应 4 条 Rail[3]。
Rail 命名
NVIDIA 文档中 Rail 的等价术语:
| 术语 | 来源 | 含义 |
|---|---|---|
| Rail | DGX SuperPOD 文档 | 连接同编号 GPU 的 InfiniBand 平面 |
| Plane | NCCL topology XML | 同 Rail,NCCL 拓扑文件中的字段名 |
| SLG (Spine-Leaf Group) | GB200 NVL72 文档 | GB200 中的 Rail 等价概念 |
| Network Plane | 学术文献 (arxiv 2605.21187) | Multiplane Fat-tree 中的单个平面 |
@tbl-roft-naming Rail 命名对照
流量工程
核心问题:ROFT 中不同类型流量如何分类和路由?对 NCCL 通信库有何影响?
Rail-Local 与 Cross-Rail 流量分类
ROFT 将网络流量分为两类,走不同路径:
| 流量类型 | 并行策略 | 路径 | 跳数 |
|---|---|---|---|
| Rail-Local | DP AllReduce / ZeRO ReduceScatter+AllGather | GPU → NIC → Rail Leaf → NIC → GPU | 1 |
| Cross-Rail | PP P2P / EP AllToAll / CP AllGather | Rail Leaf → Spine → Rail Leaf | 3 |
@tbl-roft-traffic 流量分类与路径
DP AllReduce 在 Rail 内闭合的条件:通信组由同编号 GPU 组成(标准 DP 配置天然满足)。ZeRO 将 AllReduce 拆为 ReduceScatter + AllGather,通信组不变,同样 Rail-Local。
Cross-Rail 流量产生条件:通信组跨越不同编号 GPU。PP 的相邻 stage 若不在同一 Rail,P2P 走 Spine;EP 的 AllToAll 组跨所有 Rail;CP 的 KV 传输跨 Rail。
典型流量比例
| 并行配置 | DP AllReduce(Rail-Local) | TP AllReduce(NVLink) | PP P2P(Cross-Rail) | EP AllToAll(Cross-Rail) |
|---|---|---|---|---|
| 纯 DP | 95-100% | 0% | 0% | 0% |
| DP + TP(TP 节点内) | 60-70% | 30-40% | 0% | 0% |
| 3D (DP+TP+PP) | 30-50% | 30-50% | 10-20% | 0% |
| MoE (DP+EP) | 30-40% | 0% | 0% | 60-70% |
@tbl-roft-traffic-ratio 典型流量比例(网络流量不含 NVLink)
TP 通信在节点内 NVLink/NVSwitch 完成,不占网络带宽。网络视角下,DP AllReduce 是 Dense Transformer 训练的主要流量,在 ROFT 中完全 Rail-Local。
NCCL 与 Rail 结构的交互
NCCL 通过以下机制感知和利用 ROFT 拓扑(详见 集合通信/NCCL):
NCCL_CROSS_NIC:控制跨 NIC 行为。=0强制 Rail-Local;=2(默认)自动优先同 Rail- PXN(PCIe Cross-NIC):NCCL 2.12+ 允许 GPU 经 NVLink 转到目标 Rail 的 NIC 发送,保持 Rail-Local 通信路径
- NCCL_TOPO_FILE:自定义拓扑 XML 的
<rail>/<plane>字段显式标注 Rail 身份,指导 Ring/Tree 通道构建
Oversubscription 语义
核心问题:ROFT 的过订阅与标准 Fat-tree 有何不同?Spine 带宽如何配置?
双层 Oversubscription
ROFT 中 Oversubscription 有两层含义,与标准 Fat-tree 的单一全局 Oversubscription 不同:
| 维度 | ROFT | 标准 Fat-tree |
|---|---|---|
| 定义 | 分层:Intra-Rail + Cross-Rail 独立配置 | 全局:下行总带宽 / 上行总带宽 |
| Intra-Rail | 始终 1:1 非阻塞 | N/A(无 Rail 概念) |
| Cross-Rail | 取决于 Spine provisioning,1:1~3:1 可调 | N/A |
| 影响范围 | 只有 Cross-Rail 流量受 Spine 限制 | 所有流量统一受限 |
@tbl-roft-oversub Oversubscription 对比
Spine 带宽配置
NVIDIA DGX SuperPOD H100 官方参考架构采用 1:1 非阻塞(每层线缆数相等)[4]。但生产部署可选择降低 Spine 带宽:
| Cross-Rail Oversubscription | Spine 带宽占比 | 适用场景 | 成本节省 |
|---|---|---|---|
| 1:1 | 100% | MoE EP 密集型 / 全割集需求 | 基准 |
| 2:1 | 50% | 通用训练(DP + 少量 EP/PP) | ~30% Spine |
| 3:1 | 33% | DP 为主 / 推理 | ~50% Spine |
@tbl-roft-spine-provision Spine 过订阅配置
设计合理性:DP 流量不经 Spine(Rail 内闭合),Spine 只承载 Cross-Rail 流量(PP P2P + EP AllToAll)。Dense Transformer 训练中 Cross-Rail 流量仅占网络总流量 10-20%,Spine 2:1 过订阅对性能影响有限。
多层扩展
核心问题:ROFT 如何扩展到万卡/十万卡集群?2-Tier 与 3-Tier 的最大 GPU 数是多少?
2-Tier 与 3-Tier ROFT
每条 Rail 是独立的 Fat-tree。2-Tier 时为 Leaf-Spine 结构;超过 $k^2/4$ 节点/Rail 时需要 3-Tier(Leaf-Spine-Core):
$$\begin{equation} N_{\max}^{\text{2-Tier ROFT}} = R \times \frac{k^2}{4} \label{eq:roft-2tier-max} \end{equation}$$ $$\begin{equation} N_{\max}^{\text{3-Tier ROFT}} = R \times \frac{k^3}{4} \label{eq:roft-3tier-max} \end{equation}$$其中 $R$ 为 Rail 数,$k$ 为交换机端口数。
| 配置 | 公式 | QM9700 (64-port, R=8) |
|---|---|---|
| 2-Tier 单平面 | $R \times k^2/4$ | 8,192 GPU |
| 3-Tier 单平面 | $R \times k^3/4$ | 524,288 GPU |
| 2-Tier 4-Plane | $4R \times k^2/4$ | 32,768 GPU |
| 3-Tier 4-Plane | $4R \times k^3/4$ | 2,097,152 GPU |
@tbl-roft-scale-max ROFT 最大集群规模
层级阈值
DGX H100 SuperPOD(8 Rail, 64-port QM9700, 32 nodes/SU):
- 2-Tier 上限:8 SU = 256 节点 / 2,048 GPU。每 Rail 有 $256/8 = 32$ 个 GPU,使用 1 台 Leaf(32 下行端口 + 32 上行端口 = 64 端口满配)
- 3-Tier 起点:超过 8 SU 时,每 Rail 的 Leaf 数超过 $k/2 = 32$,单层 Spine 无法全互联所有 Leaf,引入 Core 层
Multiplane 架构
arxiv 2605.21187 将 ROFT 学术化为 Multiplane Fat-tree:每个平面(Plane)是一棵独立 Fat-tree,主机通过多块 NIC 同时接入多个平面[5]。
ROFT 是 Multiplane 的工业特例:
- Plane 数 = Rail 数 = GPU/node
- 每块 NIC 只连一个 Plane(Rail)
- Plane 间通过 Spine 互联
通用 Multiplane 可以有任意 Plane 数和连接策略。Spectrum-X 论文报告 4-Plane 2-Tier 配置最大 128K endpoints,4-Plane 3-Tier 最大 16M endpoints。
定量对比
核心问题:ROFT 相比标准 Fat-tree 在交换机数量、Spine 减少、Bisection Bandwidth 上具体差多少?
1,024 GPU 规模(8 Rail, 64-port 交换机)
| 指标 | 标准 Fat-tree (2-Tier) | ROFT (2-Tier) | 差异 |
|---|---|---|---|
| Leaf 交换机 | 32 | 32 | 相同 |
| Spine 交换机 | 32 | 16 | -50% |
| Core 交换机 | 0 | 0 | 相同 |
| 总交换机 | 64 | 48 | -25% |
| Node-Leaf 线缆 | 1,024 | 1,024 | 相同 |
| Leaf-Spine 线缆 | 1,024 | 1,024 | 相同 |
@tbl-roft-vs-standard 1,024 GPU 规模 ROFT vs 标准 Fat-tree[2]
Spine 减少的来源
标准 Fat-tree 的 Spine 必须全互联所有 Leaf。ROFT 的每条 Rail 有独立 Spine,只需连接同 Rail 内的 Leaf 子集:
$$\begin{equation} \text{Spine}_{\text{standard}} = \frac{N_{\text{Leaf}} \times (k/2)}{k} = \frac{N_{\text{Leaf}}}{2} \label{eq:roft-spine-standard} \end{equation}$$ $$\begin{equation} \text{Spine}_{\text{ROFT}} = R \times \frac{N_{\text{Leaf}}/R}{2} = \frac{N_{\text{Leaf}}}{2} \times \text{oversubscription\_factor} \label{eq:roft-spine-roft} \end{equation}$$实际 Spine 减少幅度取决于配置:
| 配置 | ROFT Spine | 标准 Spine | 减少比例 |
|---|---|---|---|
| 1 SU (256 GPU) | 4 | 8 | 50% |
| 3 SU (760 GPU) | 16 | 24 | 33% |
| 4 SU (1,024 GPU) | 16 | 32 | 50% |
| 8 SU (2,048 GPU) | 32 | 64 | 50% |
@tbl-roft-spine-reduction Spine 减少幅度(DGX H100 SuperPOD)[2]
Bisection Bandwidth
| 维度 | ROFT | 标准 Fat-tree |
|---|---|---|
| Intra-Rail Bisection | $\frac{N}{2R} \cdot b$(每 Rail 全割集) | N/A |
| Cross-Rail Bisection | 取决于 Spine provisioning | N/A |
| 总 Bisection(1:1 provisioning) | $\frac{N}{2} \cdot b$(与标准相同) | $\frac{N}{2} \cdot b$ |
| 路径多样性 | Cross-Rail 路径受 Spine 限制 | 全部路径等价 |
@tbl-roft-bisection Bisection Bandwidth 对比
关键区别:1:1 provisioning 时总 Bisection Bandwidth 相等。差异在路径多样性——标准 Fat-tree 有 $k/2$ 条等价路径供 ECMP 选择;ROFT 的 Cross-Rail 流量路径受限于 Spine 容量。
仿真建模影响
核心问题:仿真器需要哪些参数和逻辑变更来准确建模 ROFT?
拓扑参数化
仿真器区分 ROFT 与标准 Fat-tree 的核心差异:
- 接线模式:ROFT 的 Leaf 按 Rail 组织(同编号 GPU → 同 Leaf),标准 Fat-tree 按节点组织(同节点 GPU → 同 Leaf)
- 流量路由:根据并行策略判断 Rail-Local(1 跳)或 Cross-Rail(3 跳)
- Spine 负载:ROFT Spine 只承载 Cross-Rail 流量,标准 Fat-tree Spine 承载所有跨 Leaf 流量
跳数与延迟差异
| 通信类型 | ROFT 跳数 | 标准 Fat-tree 跳数 | 延迟差异 |
|---|---|---|---|
| DP AllReduce | 1 | 3 | ROFT 延迟降约 2/3 |
| EP AllToAll (EP>8) | 3 | 3 | 相同 |
| PP P2P (跨 Rail) | 3 | 3 | 相同 |
@tbl-roft-hops 跳数对比
拥塞模型差异
| 场景 | ROFT Spine 拥塞 | 标准 Fat-tree Spine 拥塞 |
|---|---|---|
| 纯 DP AllReduce | 无(Spine 空闲) | 中等(DP 流量经 Spine) |
| EP AllToAll (EP>8) | 高(Spine 设计容量不足) | 低(全割集) |
| DP + EP 混合 | 中等(仅 EP 占 Spine) | 中等(DP + EP 共享 Spine) |
| 多租户 | 高(不可预测流量) | 低(全割集适应任意模式) |
@tbl-roft-congestion 拥塞概率对比
建模建议
仿真器建模 ROFT 需要的参数:
rail_count: int:Rail 数(H100 = 8, GB200 = 4)spine_oversubscription: float:Spine 过订阅比(1.0 = 1:1 非阻塞)- 流量分类函数:根据通信原语和并行策略标记
rail_local/cross_rail - Rail Leaf 内部带宽:始终 1:1 非阻塞
- Spine 带宽:按
spine_oversubscription缩放
局限与适用边界
主要失效场景
MoE EP > 8 时 AllToAll 洪泛 Spine。EP 组跨越多条 Rail,AllToAll 全连接流量涌入 Spine。以 DeepSeek-V3 为例:EP=64,256 路由 expert 分布在 64 GPU 上,AllToAll 跨 8 条 Rail,Spine 承载 $64 \times 64$ 全连接流量矩阵。
DeepSeek-V3 的缓解策略:
- Node-limited routing:每 token 最多路由到 4 个节点
- DualPipe:AllToAll 与 expert 计算重叠
- FP8 量化:通信量减半
推理服务。请求路由到任意 GPU,流量模式不可预测,Rail-Local 优化无效。
多租户集群。不同 job 流量模式多样,与 Rail 对齐概率低。标准 Fat-tree 全割集更适合。
Rail Leaf 单点故障域放大。一台 Rail Leaf 故障导致所有节点的同编号 GPU 失联。标准 Fat-tree 中一台 Leaf 故障仅影响连到它的节点。
决策矩阵
| 决策因素 | 选 ROFT | 选标准 Fat-tree |
|---|---|---|
| 模型类型 | Dense Transformer(GPT/Llama) | MoE Transformer(DeepSeek/Mixtral) |
| EP 度 | ≤ 8(节点内闭合) | > 8(跨节点 AllToAll) |
| 集群用途 | 单租户专用训练 | 多租户通用集群 / 推理 |
| 流量 Rail-Local 比例 | > 80% | < 50% |
| 故障域容忍 | 可接受 Rail 粒度 | 需要节点粒度 |
| 成本权重 | 高(省 30-50% Spine) | 低(性能优先) |
@tbl-roft-decision 选型决策矩阵
实际部署案例
| 集群 | 规模 | Rail 数 | 互联 | 特点 |
|---|---|---|---|---|
| NVIDIA Eos | 4,608 H100 | 8 | IB NDR 3-Tier | SuperPOD 参考架构 |
| xAI Colossus | 100,000 H100 | 8 | IB NDR | 已知最大 GPU 集群 |
| Meta RSC Phase 2 | 16,000 A100 | 8 | IB HDR | Rail-Optimized |
| Microsoft Azure ND H100 v5 | 数千 H100 | 8 | IB NDR | 云服务商部署 |
| Alibaba HPN | 100K+ GPU | 8 | RoCE 400GbE | Dual-ToR + Rail-Optimized[6] |
| Tencent Astral | 500K GPU | — | — | Same-Rail Tier-2[7] |
@tbl-roft-deploy 实际部署案例
NVIDIA DGX SuperPOD 是 ROFT 的参考实现。所有 DGX 集群默认采用 Rail-Optimized 布线[2]。
Meta 是大规模 AI 集群中主动选 RoCE(而非 IB)的厂商,35,000+ H100 集群采用 5-Tier Clos(RoCE 400GbE)。动机:供应商多样性、运维一致性、以太网交换机比 IB 便宜 30-50%。
Alibaba HPN(SIGCOMM 2024)在 Rail-Optimized 基础上增加 Dual-ToR 容灾,同时保持 Rail 结构。
与 Fat-tree 章节的关系
本文档是 2.3 Fat-tree 中 Rail-Optimized 节(约 30 行概述)的完整独立扩展。03-fat-tree.md 覆盖标准 Fat-tree 的结构与公式,本文聚焦 ROFT 的布线、流量工程、扩展公式和适用边界。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 本质 | 按 GPU 编号重新接线的 Fat-tree,1 Rail = 1 独立非阻塞子树 |
| 设计前提 | DP AllReduce 是网络主要流量 + 节点内 NVSwitch 处理 TP |
| 交换机节省 | Spine 减少 33-50%,总交换机减少 ~25% |
| 扩展上限 | 2-Tier 8,192 GPU / 3-Tier 524,288 GPU(8 Rail, 64-port) |
| 主要优势 | DP 延迟从 3 跳降为 1 跳,Spine 零负载 |
| 主要风险 | MoE EP>8 AllToAll 洪泛 Spine / Rail Leaf 故障域放大 |
| 学术定位 | Multiplane Fat-tree 的工业实例 |
| 仿真关键 | 按并行策略分类流量为 Rail-Local vs Cross-Rail |
参考资料
- Al-Fares M. et al., A Scalable, Commodity Data Center Network Architecture, SIGCOMM 2008. https://dl.acm.org/doi/10.1145/1402958.1402967
- NVIDIA, DGX SuperPOD Reference Architecture: Scalable Infrastructure for H100. https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/dgx-superpod-architecture.html
- NVIDIA, DGX SuperPOD Reference Architecture: GB200 NVL72. https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-gb200-nvl72/latest/
- NVIDIA, DGX SuperPOD H100 Network Fabrics. https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/network-fabrics.html
- Katta N. et al., High-speed Networking for Giga-Scale AI Factories, arXiv:2605.21187, 2025. https://arxiv.org/abs/2605.21187
- Alibaba, HPN: A Data Center Network for Large Language Model Training, SIGCOMM 2024. https://dl.acm.org/doi/10.1145/3651898
- Tencent, Astral: Autonomous, Scalable, and Topology-Aware Scheduling for Large-Scale AI Training, SIGCOMM 2025. https://dl.acm.org/doi/10.1145/3721877