Ring
最简直连环路的结构特性及其在 AllReduce 算法与节点内子结构中的作用
核心要点:
- 度数恒为 2,结构最简单成本最低
- 割集带宽 $2b$ 不随 $N$ 增长,独立用于集群级已淘汰
- 直径 $\lfloor N/2 \rfloor$ 线性增长
- 仍在两个层面关键:Ring AllReduce 算法 + 节点内子结构 (NVLink/PCIe/MI300X Die)
- Chordal Ring 加 $\sqrt{N}$ 弦可把直径降到 $O(\sqrt{N})$
- Hypercube 是 Ring + $\log_2 N$ 条 power-of-2 弦的极限
基本结构是什么?
$N$ 个节点构成双向环 $C_N$,每节点只连左右邻居,度数恒为 2。
Ring 作为独立集群拓扑已被淘汰,但仍在两层面关键:
- 算法层面:Ring AllReduce 达到带宽理论下界,是大消息集合通信标准实现 (详见 AllReduce)
- 子结构层面:现代 GPU 节点内 NVLink/PCIe、芯片封装内 Die 互联大量采用 Ring 或变体
单向环 vs 双向环 (@tbl-topo-ring-uni-bi):
| 单向环 | 双向环 | |
|---|---|---|
| 度数 | 1 (出度) | 2 |
| 直径 | $N-1$ | $\lfloor N/2 \rfloor$ |
| 割集带宽 | $b$ | $2b$ |
| 路由 | 只能单方向 | 选较短方向 |
| 实际使用 | 极少 (流水线场景) | 标准选择 |
@tbl-topo-ring-uni-bi 单向环 vs 双向环
以下讨论均指双向环。
关键参数和致命缺陷
核心问题:Ring 的割集带宽为什么是致命缺陷?度数、直径、链路数各是多少?
割集带宽恒为 $2b$ 不随规模增长,是 Ring 的致命缺陷。参数见 @tbl-topo-ring-params。
| 属性 | 值 |
|---|---|
| 度数 | 2 |
| 直径 | $\lfloor N/2 \rfloor$ |
| 链路数 | $N$ |
| 割集带宽 | $2b$ (与 $N$ 无关) |
| Vertex-Transitive | Yes (循环群 $\mathbb{Z}_N$ 对称) |
| 路径多样性 | 任意两节点恰好 2 条 (顺/逆时针) |
@tbl-topo-ring-params Ring 关键参数
将环从任意位置切开必须切断恰好 2 条链路。$N$ 从 8 增到 1024 时可用割集带宽不变,而直径从 4 增到 512 — 通信能力随规模急剧恶化。
Chordal Ring 怎么改善?
加 $\sqrt{N}$ 弦让度数 2 → 4,直径和割集都降到 $O(\sqrt{N})$,见 @fig-topo-ring-chordal。
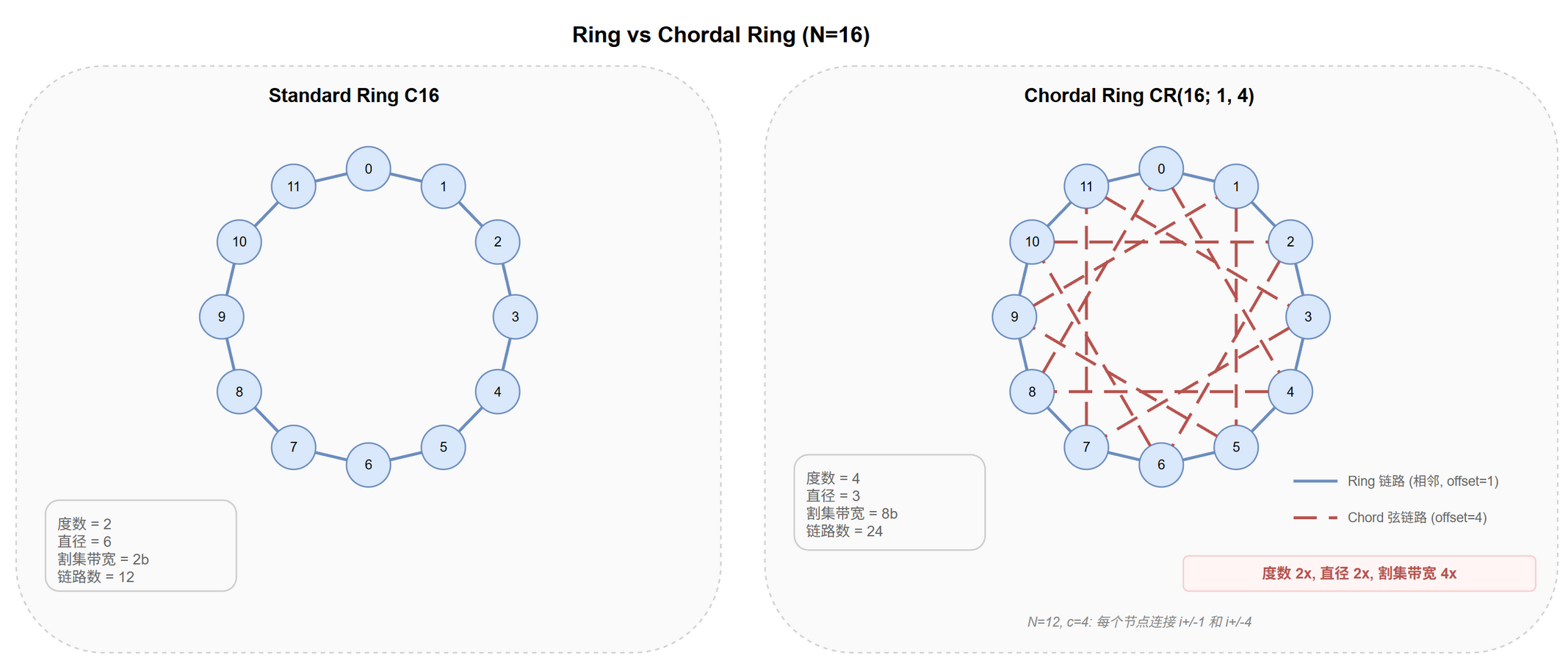
定义
$CR(N; 1, c)$: $N$ 节点环,每节点除连左右邻居外,还连偏移 $c$ 的节点。即节点 $i$ 连 $(i \pm 1) \bmod N$ 和 $(i \pm c) \bmod N$。度数 2 → 4。
参数改善
| 属性 | Ring $C_N$ | Chordal Ring $CR(N; 1, c_{\text{opt}})$ | 改善 |
|---|---|---|---|
| 度数 | 2 | 4 | 2× |
| 直径 | $\lfloor N/2 \rfloor$ | $O(\sqrt{N})$ | $O(\sqrt{N})$× |
| 割集带宽 | $2b$ | $O(\sqrt{N}) \cdot b$ | $O(\sqrt{N})$× |
| Vertex-Transitive | Yes | Yes | 保持 |
@tbl-topo-ring-chordal-improve Chordal Ring 参数改善
最优弦长 $c_{\text{opt}} \approx \lfloor\sqrt{N}\rfloor$:通过组合单位步和弦跳,任意目标可在 $\sim 2\sqrt{N}$ 步内到达。
多弦扩展揭示 Hypercube 的关系
| 弦数 $k$ | 度数 | 直径 | 例子 |
|---|---|---|---|
| 0 | 2 | $O(N)$ | 标准 Ring |
| 1 | 4 | $O(\sqrt{N})$ | $CR(N; 1, \sqrt{N})$ |
| 2 | 6 | $O(N^{1/3})$ | $CR(N; 1, c_2, c_3)$ |
| $\log_2 N$ | $2\log_2 N$ | $O(\log N)$ | Hypercube ($c_k = 2^k$) |
@tbl-topo-ring-chord-ext 多弦扩展
最后一行揭示重要联系:Hypercube 是 Ring 加 $\log_2 N$ 条 power-of-2 弦的极限。从 Ring → Chordal Ring → Hypercube 是连续的度数-直径权衡谱[1][2]。
与 Torus 的关系
$CR(N; 1, \sqrt{N})$ ($N$ 为完全平方数时) 数学上等价于 $\sqrt{N} \times \sqrt{N}$ 的 2D Torus。更一般地,$k$ 维 Torus (边长 $s$,$N = s^k$) 等价于 $CR(N; 1, s, s^2, \ldots, s^{k-1})$。
Torus 拓扑可理解为特定弦选择的 Chordal Ring,弦偏移取维度步长。
Ring 的其他特性
核心问题:Ring 除了基本参数外,在二分带宽、Vertex-Transitive 和路径多样性方面有什么特性?
割集对比 (@tbl-topo-ring-bb)
| 拓扑 | 割集带宽 | $N=1024$ 时 |
|---|---|---|
| Ring | $2b$ | $2b$ |
| Chordal Ring ($c=\sqrt{N}$) | $\sim 2\sqrt{N} \cdot b$ | $\sim 64b$ |
| 3D Torus | $2N^{2/3} \cdot b$ | $\sim 204b$ |
| Fat-tree | $\frac{N}{2} \cdot b$ | $512b$ |
@tbl-topo-ring-bb Ring 割集对比
死锁避免
单方向路由天然无死锁。双向路由 (最短路径选方向) 可用 dateline 机制 — 在环上指定一条链路为"日期线",跨越时切换虚通道,打破潜在环路依赖[3]。
故障脆弱性
- 单链路故障:环分裂为链,割集带宽降至 $b$ (减半),但仍连通
- 双链路故障 (不同位置):网络分裂为两个不连通子图
对比 Fat-tree 任意单链路故障后仍有 $k/2 - 1$ 条替代路径,Torus 有多维冗余。Ring 故障容忍最差。
Ring 在现代系统的子结构应用
核心问题:Ring 作为独立集群拓扑已淘汰,但作为子结构在哪些现代系统中仍广泛使用?
作为独立集群拓扑已淘汰,但在子拓扑层面广泛存在。
NVLink Ring (节点内 GPU)
| 系统 | 节点内拓扑 | Ring 角色 |
|---|---|---|
| DGX-1 P100 (2016) | 8 GPU NVLink 混合 cube-mesh | 物理环 |
| DGX-1 V100 (2017) | 8 GPU NVLink 混合 | 物理环 |
| DGX A100 (2020) | NVSwitch 全互联 | Ring 作为逻辑映射 |
| DGX H100 (2022) | NVSwitch 3.0 全互联 | Ring 作为逻辑映射 |
@tbl-topo-ring-nvlink NVLink Ring 演进
NVSwitch 引入后节点内拓扑升级为全互联,但 Ring AllReduce 算法仍在全互联拓扑上使用 (利用逻辑环映射到物理全互联)[4]。
AMD MI300X 封装内环
MI300X 的 8 个 XCD (计算 Die) 通过 Infinity Fabric 4 (IF4) 环形连接。相邻 XCD 带宽 ~200 GB/s,非相邻必须经中间转发,带宽衰减到 ~50-70 GB/s[5]。
这是 Ring 缺陷在真实硬件的典型体现:直径 $\lfloor N/2 \rfloor = 4$ 跳导致最远 Die 对带宽只有相邻 Die 的 25-35%。对比 NVSwitch 全互联的"任意两 GPU 等带宽",Ring 在节点内互联层面也劣势。
PCIe Ring
多路 CPU 服务器中 PCIe 设备通过 QPI/UPI 形成环。跨 NUMA GPU 通信需经多跳,延迟和带宽劣于同 NUMA 直连。
适用场景与局限
核心问题:Ring 作为独立拓扑已淘汰,但在哪些子结构场景仍有价值、有哪些不可逾越的局限?
适用:
- Ring AllReduce 算法 (大消息 $M > 100$ MB,带宽利用率理论最优)
- 小规模同质集群 ($N \leq 8$)
- 芯片封装内互联 (Die-to-Die 端口有限,度数约束)
局限:
- 割集带宽不随规模增长 ($2b$ 恒定)
- 直径 $O(N)$ 线性增长
- 故障脆弱 (单链路减半,双链路分裂)
- 非均匀通信效率 (只有相邻节点高效)
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 结构 | 双向环 $C_N$,度数 2,链路 $N$ |
| 致命缺陷 | 割集 $2b$ 不随 $N$ 增长 |
| Chordal Ring | 加 $\sqrt{N}$ 弦使直径/割集 → $O(\sqrt{N})$ |
| Hypercube 联系 | Ring + $\log_2 N$ 条 power-of-2 弦 = Hypercube |
| Torus 联系 | $k$ 维 Torus = Chordal Ring 弦取维度步长 |
| 现代角色 | 独立集群已淘汰,仍是 AllReduce 算法基底 + 节点内子结构 |
| 工程教训 | MI300X Die Ring 远端带宽仅 25-35% 邻居带宽 |
参考资料
- Arden B. and Lee H., Analysis of Chordal Ring Network, IEEE TC 1981. https://ieeexplore.ieee.org/document/1675629
- Bermond J.-C. et al., Distributed Loop Computer Networks: A Survey, JPDC 1995. https://doi.org/10.1006/jpdc.1995.1025
- Dally W. and Seitz C., Deadlock-Free Message Routing in Multiprocessor Interconnection Networks, IEEE TC 1987. https://doi.org/10.1109/TC.1987.1676939
- NVIDIA, DGX-1 with V100 System Architecture Whitepaper. https://images.nvidia.com/content/pdf/dgx1-v100-system-architecture-whitepaper.pdf
- Chips and Cheese, MI300X Infinity Fabric Topology Analysis, 2024. https://chipsandcheese.com/2024/01/amd-mi300x-infinity-fabric-topology-analysis/