AllReduce
AllReduce 有哪些算法、如何按消息大小与拓扑分层选择
核心要点:
- AllReduce = ReduceScatter + AllGather (主流分解),带宽下界 $\frac{(N-1) M}{N \beta}$
- Ring 带宽最优 / 延迟 $O(N) \alpha$,大消息王者
- Butterfly 延迟最优 $\log_2 N \cdot \alpha$,小消息王者,带宽随 $N$ 退化
- Halving-Doubling 同时达延迟与带宽下界 (常数因子 2),中大规模通用
- Double Binary Tree NCCL 跨节点小消息默认,与 Ring 互补
- 多维分层把跨慢链路通信量缩 $L$ 倍,是大规模异构集群关键
语义与分解
核心问题:AllReduce 的语义是什么?为什么在数学上可分解为 ReduceScatter + AllGather?
语义
所有节点持 $A_i$ 大小 $M$, AllReduce 后所有节点持完整规约:
$$\begin{equation} \forall i \in [0, N): \quad B_i = \bigoplus_{j=0}^{N-1} A_j \label{eq:cc-ar-semantic} \end{equation}$$等价分解
两种等价分解:
$$\begin{equation} \text{AllReduce} = \text{Reduce}(\to \text{root}) + \text{Broadcast}(\text{from root}) \label{eq:cc-ar-decomp-rb} \end{equation}$$ $$\begin{equation} \text{AllReduce} = \text{ReduceScatter} + \text{AllGather} \label{eq:cc-ar-decomp-rs-ag} \end{equation}$$分解 2 通常更优:RS 与 AG 都可用 Ring 实现,链路全程满载。
理论下界
核心问题:AllReduce 的延迟和带宽下界各是多少,算法 / 拓扑如何影响?
延迟下界
信息扩散至少 $\lceil \log_2 N \rceil$ 步:
$$\begin{equation} T_{\alpha}^{\min} = \lceil \log_2 N \rceil \cdot \alpha \label{eq:cc-ar-delay-lb} \end{equation}$$Ring 拓扑直径 $\lfloor N / 2 \rfloor$, $N > 4$ 时拓扑约束更紧。
带宽下界
节点 $i$ 最终持 $M$ 字节的规约结果,每字节都需其他 $N-1$ 节点的贡献。按 Patarasuk & Yuan (JPDC 2009) 的切割论证,每节点至少收 / 发 $(N-1) M / N$ 字节:
$$\begin{equation} R_i \ge \frac{(N-1) M}{N}, \quad S_i \ge \frac{(N-1) M}{N} \label{eq:cc-ar-rs-budget} \end{equation}$$ $$\begin{equation} T_{\beta}^{\min} = \frac{(N-1) M}{N \beta} \label{eq:cc-ar-bw-lb} \end{equation}$$带宽下界通用推导见 4.2 理论下界。
综合下界
$$\begin{equation} T_{\text{AR}}^{\min} = \max\left( \lceil \log_2 N \rceil \cdot \alpha, \quad \frac{(N-1) M}{N \beta} \right) \label{eq:cc-ar-combined-lb} \end{equation}$$busbw 与算法带宽的换算
NCCL 性能测试用 busbw 把算法带宽 (algbw = $M / T$) 换算到单链路实际承载:
$$\begin{equation} \text{busbw} = \frac{M}{T} \times \frac{2 (N - 1)}{N} \label{eq:cc-ar-busbw} \end{equation}$$Ring 达带宽最优时 busbw → $\beta$。
算法一:Ring AllReduce
核心问题:Ring 上如何把每条链路打满,达带宽最优?见 。
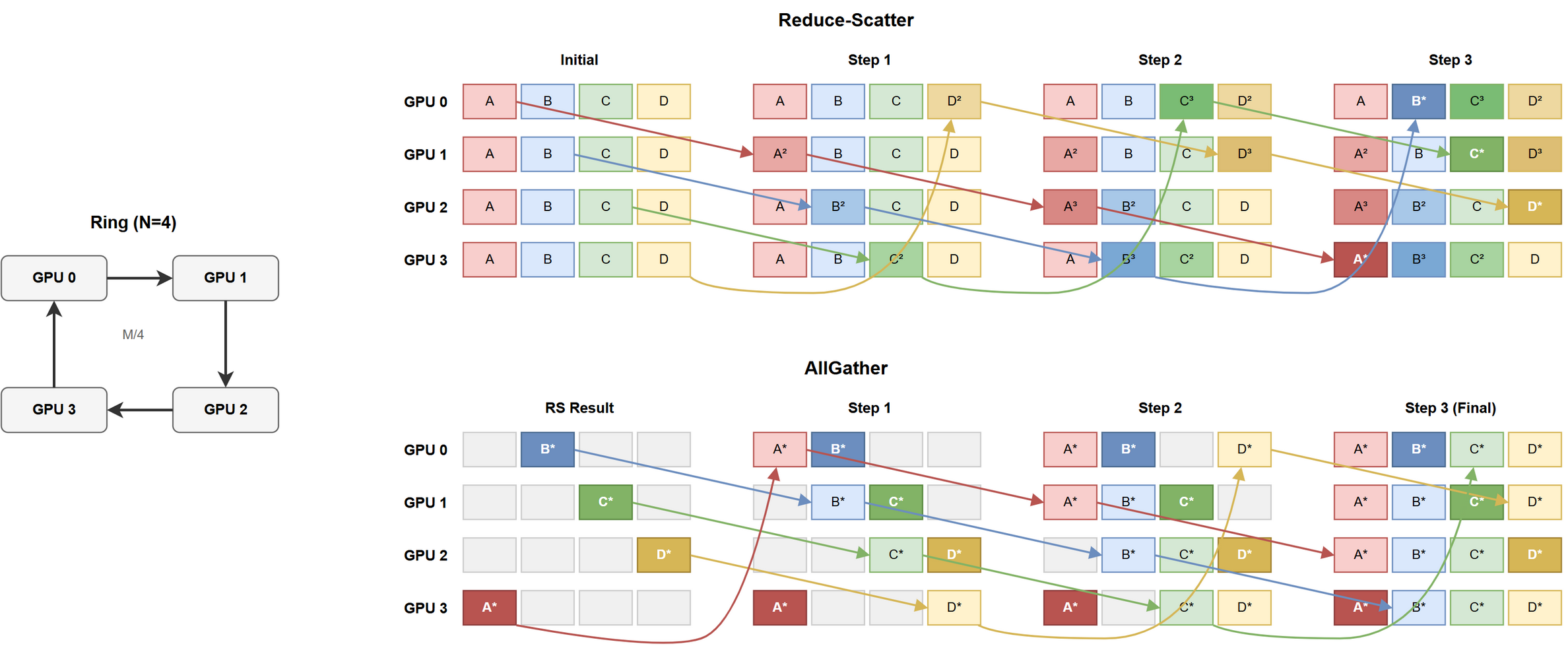
为什么要切 $N$ 份
不分片时任何时刻仅 1 条链路活跃,其余 $N - 1$ 条空闲,总传输量 $2 (N - 1) M$。
切 $N$ 片后所有链路同时工作:
N=4, 分片: [A][B][C][D]
Step 1: 0→1 送A 1→2 送B 2→3 送C 3→0 送D ← 4 条链路同时
Step 2: 0→1 送D' 1→2 送A' 2→3 送B' 3→0 送C'
Step 3: 0→1 送C'' 1→2 送D'' 2→3 送A'' 3→0 送B''
分片的本质不是减步数,而是让所有链路并行,把串行接力变成流水线。这是 Ring "带宽最优"的根本原因。
阶段 1: ReduceScatter
$N - 1$ 步后节点 $i$ 持有 chunk $(i + 1) \bmod N$ 的完全规约结果。第 $s$ 步:
- 发当前持有的 chunk $(i - s) \bmod N$ 给右邻
- 从左邻收 chunk $(i - 1 - s) \bmod N$
- 与本地对应 chunk 规约
阶段 2: AllGather
完全规约 chunk 沿 Ring 传播,$N - 1$ 步后所有节点持完整结果。
代价
RS 阶段:
$$\begin{equation} T_{\text{RS}} = (N - 1) \alpha + \frac{(N - 1) M}{N \beta} \label{eq:cc-ar-ring-rs} \end{equation}$$AG 阶段对称:
$$\begin{equation} T_{\text{AG}} = (N - 1) \alpha + \frac{(N - 1) M}{N \beta} \label{eq:cc-ar-ring-ag} \end{equation}$$合计:
$$\begin{equation} T_{\text{Ring}} = 2 (N - 1) \alpha + \frac{2 (N - 1) M}{N \beta} \label{eq:cc-ar-ring} \end{equation}$$带宽项达下界 2 倍 (RS + AG 各占一半),是"带宽最优"的精确含义。延迟项 $2 (N - 1) \alpha$ 远超下界,大 $N$ 小 $M$ 退化严重。
2-port Ring 优化
双 DMA 把 $N$ 个 chunk 分两半双向传,步数减半:
$$\begin{equation} T_{\text{2-port-Ring}} = 2 \lceil N / 2 \rceil \cdot \alpha + 2 \lceil N / 2 \rceil \cdot \frac{M / N}{\beta} \approx N \alpha + \frac{M}{\beta} \label{eq:cc-ar-2port-ring} \end{equation}$$SCCL 4 芯实测 (131072 FP16): RS 6.509 + AG 5.752 + 同步 3.496 = 15.757 $\mu s$。
| 指标 | 1-port Ring | 2-port Ring |
|---|---|---|
| RS 步数 | $N - 1$ | $\lceil N / 2 \rceil$ |
| AG 步数 | $N - 1$ | $\lceil N / 2 \rceil$ |
| 总步数 | $2 (N - 1)$ | $\approx N$ |
| 带宽项 | $\frac{2 (N-1)}{N} \cdot \frac{M}{\beta}$ | $\frac{M}{\beta}$ |
| 延迟项 | $2 (N - 1) \alpha$ | $N \alpha$ |
@tbl-cc-ar-ring-port-cmp 1-port vs 2-port Ring AllReduce
算法二:Recursive Halving-Doubling
核心问题:能否同时达延迟下界和带宽下界?
HD 在 $N = 2^k$ 时同时最优 (常数因子 2),见 。
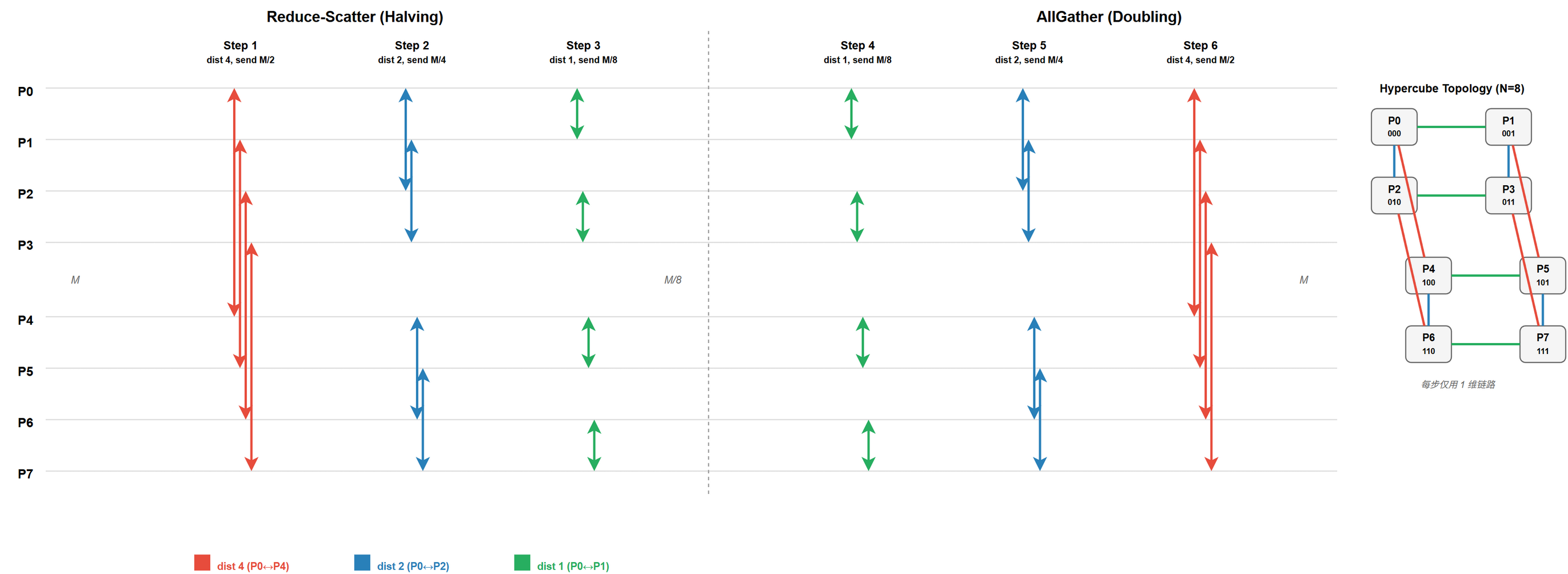
核心:两阶段,距离翻倍 / 减半
阶段 1 (Recursive Halving = ReduceScatter) 每步与翻转最高位的对手交换:
| 步 ($N=8$) | 通信对 | 交换量 |
|---|---|---|
| 1 | (0,4) (1,5) (2,6) (3,7) | $M / 2$ |
| 2 | (0,2) (1,3) (4,6) (5,7) | $M / 4$ |
| 3 | (0,1) (2,3) (4,5) (6,7) | $M / 8$ |
@tbl-cc-ar-hd-trace HD ReduceScatter 步骤 (N=8)
阶段 2 (Recursive Doubling = AllGather) 逆过程,数据量翻倍。
代价
RS 阶段第 $j$ 步交换 $M / 2^j$, $\sum 1 / 2^j = (N-1)/N$:
$$\begin{equation} T_{\text{RS}} = \log_2 N \cdot \alpha + \frac{(N - 1) M}{N \beta} \label{eq:cc-ar-hd-rs} \end{equation}$$AG 对称,合计:
$$\begin{equation} T_{\text{HD}} = 2 \log_2 N \cdot \alpha + \frac{2 (N - 1) M}{N \beta} \label{eq:cc-ar-hd} \end{equation}$$| 指标 | Ring | HD | 下界 |
|---|---|---|---|
| 延迟项 | $2 (N-1) \alpha$ | $2 \log_2 N \cdot \alpha$ | $\lceil \log_2 N \rceil \alpha$ |
| 带宽项 | $\frac{2 (N-1) M}{N \beta}$ | $\frac{2 (N-1) M}{N \beta}$ | $\frac{(N-1) M}{N \beta}$ |
@tbl-cc-ar-hd-vs-ring HD vs Ring 对比下界
两项都接近最优 (各 2× 下界),大规模集群首选。
拓扑要求与非 $2^k$ 处理
- 天然映射到 Hypercube, Ring 上某些步需多跳,性能退化
- $N \ne 2^k$:选 $r = N - 2^{\lfloor \log_2 N \rfloor}$ 多余节点先发数据给伙伴 + 后处理回传,额外开销 $2 \alpha + 2 M / \beta$
算法三:Double Binary Tree
核心问题:小消息 + 跨节点场景如何用 $O(\log N)$ 延迟?见 。
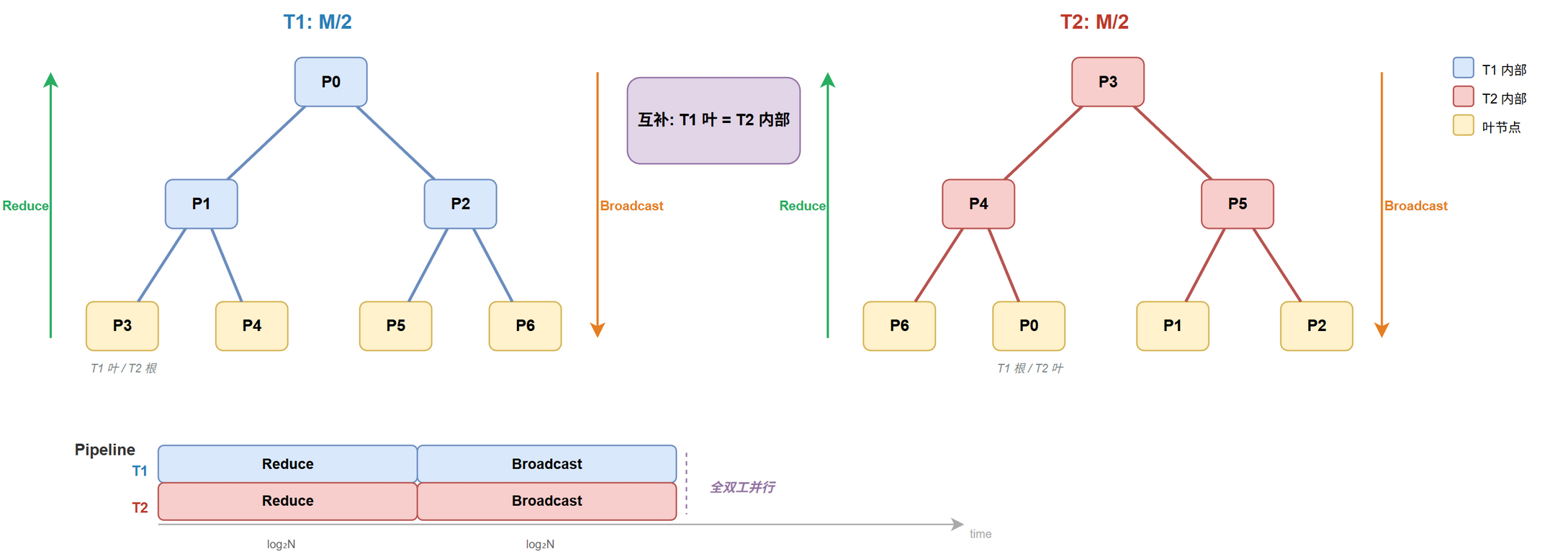
核心:两棵互补二叉树
$T_1$ 与 $T_2$ 结构互补 ($T_1$ 叶子是 $T_2$ 内部节点,反之亦然)。消息分两半,各在一棵树上做 Reduce + Broadcast,利用全双工 (两棵树占上下行)。
代价
每棵树 $\log_2 N$ 层,各处理 $M / 2$:
$$\begin{equation} T_{\text{DBT}} = 2 \log_2 N \cdot \alpha + \log_2 N \cdot \frac{M}{\beta} \label{eq:cc-ar-dbt} \end{equation}$$带宽项 $\log_2 N \cdot M / \beta$ 劣于 Ring。Tree 每步传完整 $M / 2$,不像 Ring 切 $M / N$ 流水。
NCCL 实际策略
NCCL 用 DBT 处理小消息跨节点 (延迟优先,$O(\log N)$ 步), Ring 处理节点内大消息 (带宽优先)。
算法四:Butterfly (Recursive Doubling)
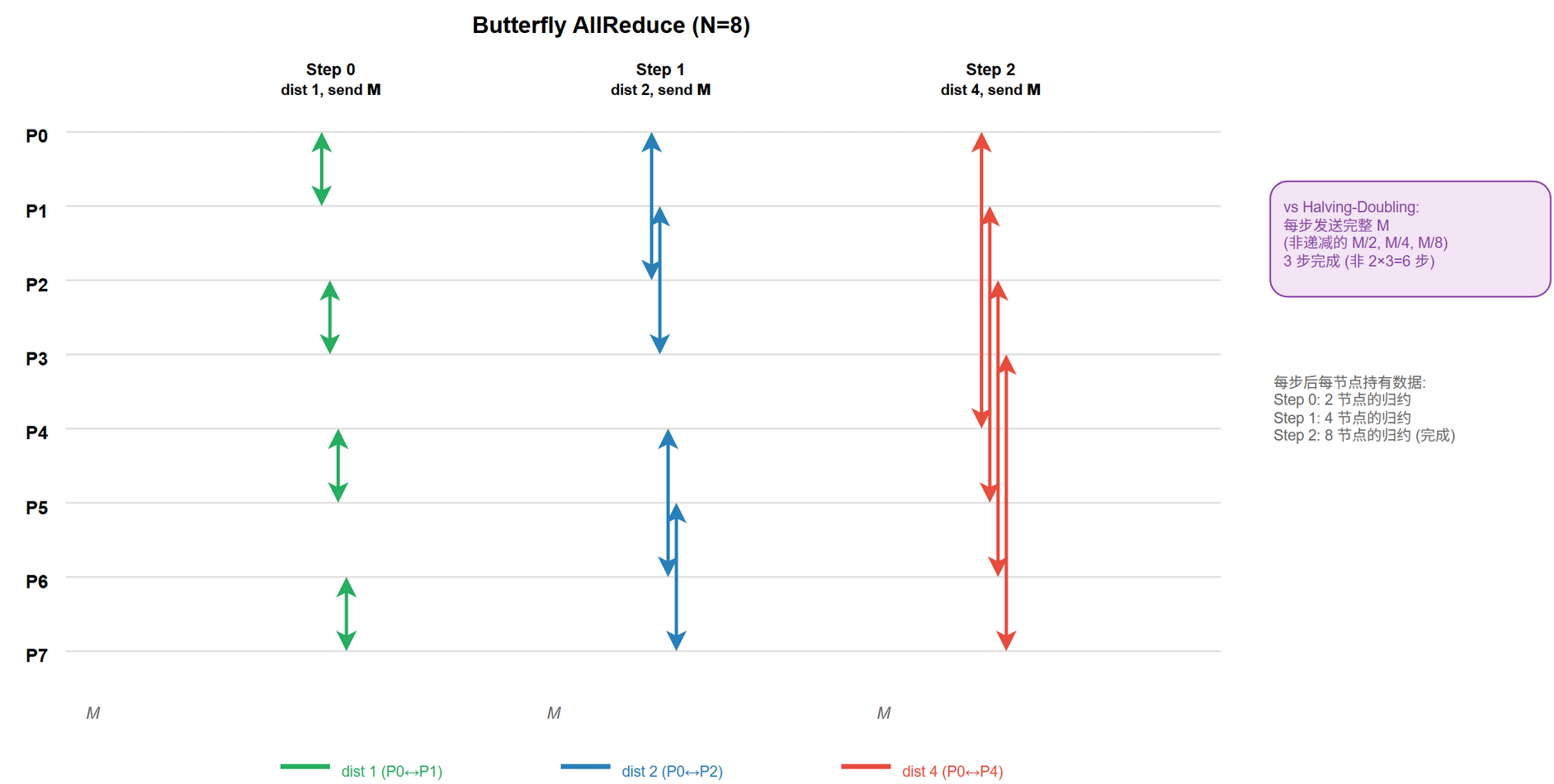
核心:不分阶段,$\log_2 N$ 步完整 $M$ 互换
第 $k$ 步节点 $i$ 与 $i \oplus 2^k$ (XOR) 配对,交换完整 $M$ 并规约。$N = 8$ 三步示例:
- Step 0 (距 1):(0,1) (2,3) (4,5) (6,7)
- Step 1 (距 2):(0,2) (1,3) (4,6) (5,7)
- Step 2 (距 4):(0,4) (1,5) (2,6) (3,7)
每对交换完整数据并规约,3 步后所有节点持完整结果。
代价
$$\begin{equation} T_{\text{Butterfly}} = \log_2 N \cdot \alpha + \log_2 N \cdot \frac{M}{\beta} \label{eq:cc-ar-butterfly} \end{equation}$$延迟项 $\log_2 N \cdot \alpha$ 达下界,带宽项含 $\log_2 N$ 因子,总传输量 $M \cdot \log_2 N$,远超下界。
带宽效率
$$\begin{equation} \eta_{\text{bw}} = \frac{2 (N - 1) / N}{\log_2 N} \label{eq:cc-ar-butterfly-eff} \end{equation}$$$N = 8$ 时 ~58%, $N = 64$ 时 ~32%, $N = 1024$ 时 ~20%。带宽随 $N$ 快速退化,不适合大消息。
Butterfly vs Halving-Doubling
经常被混淆 (OpenMPI 函数名 recursivedoubling 误导),关键区别:
| 维度 | Butterfly | Halving-Doubling |
|---|---|---|
| 每步数据量 | 完整 $M$ | 递减 / 递增 |
| 总步数 | $\log_2 N$ | $2 \log_2 N$ |
| 延迟项 | $\log_2 N \cdot \alpha$ | $2 \log_2 N \cdot \alpha$ |
| 带宽项 | $\log_2 N \cdot M / \beta$ | $\frac{2(N-1) M}{N \beta}$ |
| 带宽最优 | 否 | 是 |
@tbl-cc-ar-butterfly-vs-hd Butterfly vs HD
非 $2^k$ 处理
与 HD 相同:前 $2 r$ 节点两两配对预 / 后处理,中间 $m = 2^{\lfloor \log_2 N \rfloor}$ 节点跑标准 Butterfly,额外 $2 \alpha + 2 M / \beta$。
适用场景
小消息 ($\le 2$ KB) 延迟最优, MPICH 默认选择:
- $M \le 2$ KB: Butterfly
- $M > 2$ KB 且 $N = 2^k$: Halving-Doubling
- $M > 2$ KB 且 $N \ne 2^k$: Reduce + Broadcast
算法五:多维分层 AllReduce
核心问题:实际集群跨芯片 / 节点 / 机架带宽差异 10–100×,如何最小化慢链路传输?见 。
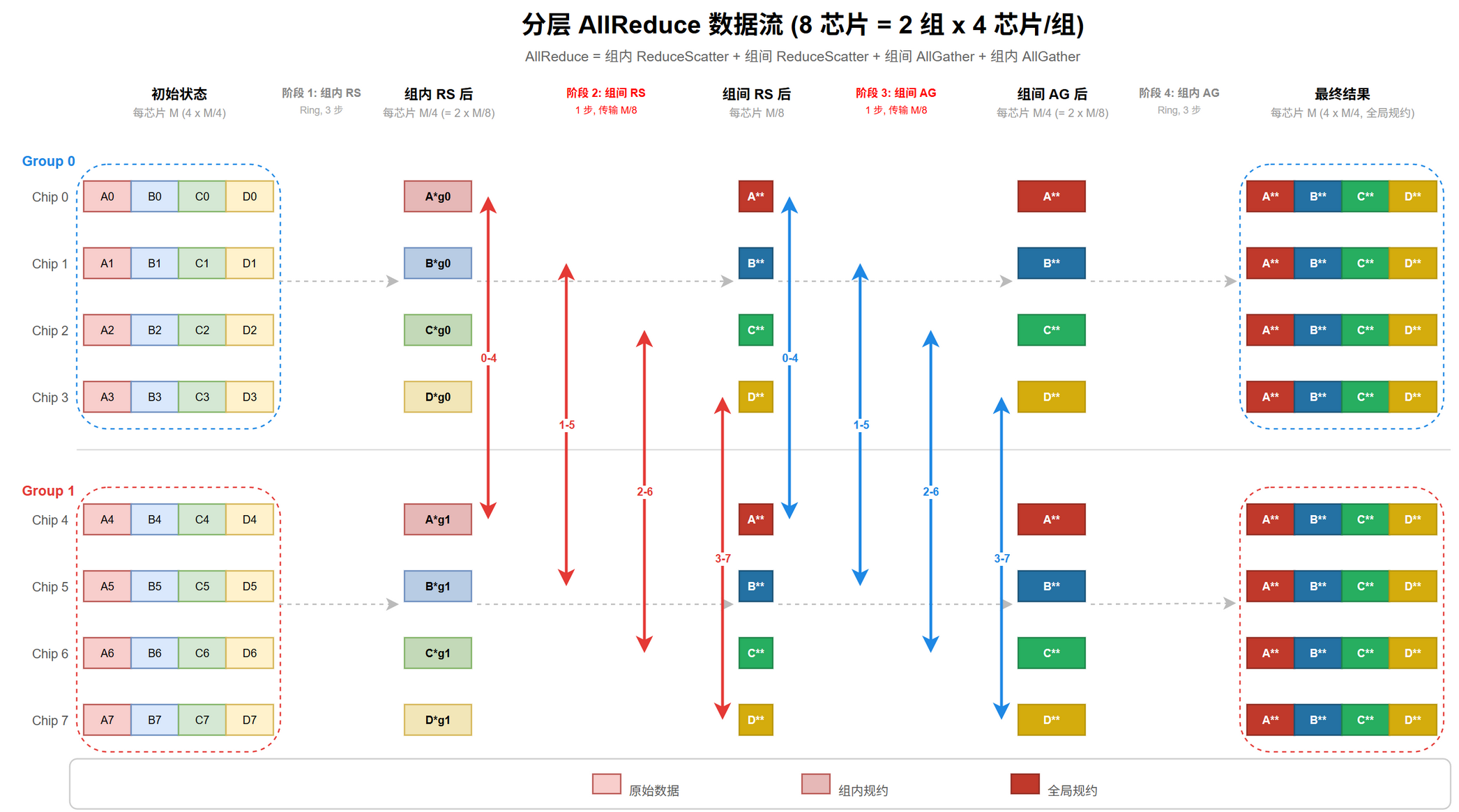
拓扑背景与数值见 4.11 拓扑对集合通信的影响。
核心:沿网络维度分解
$N = \prod p_i$,每维度对应一层网络 ($\beta_i, \alpha_i$),分解为逐维 RS + 逆序 AG:
$$\begin{equation} \text{AR}(N) = \underbrace{\text{RS}_0 \to \text{RS}_1 \to \cdots \to \text{RS}_{d-1}}_{\text{内层 → 外层}} \to \underbrace{\text{AG}_{d-1} \to \cdots \to \text{AG}_1 \to \text{AG}_0}_{\text{外层 → 内层 (逆序)}} \label{eq:cc-ar-hier-decomp} \end{equation}$$每级 RS 数据量缩 $p_i$ 倍,外层只处理压缩后的数据。
通用代价公式 (BlueConnect)
$P_i = \prod_{j=0}^{i} p_j$, $P_{-1} = 1$:
$$\begin{equation} T_{\text{multi-dim}} = \sum_{i=0}^{d-1} \left[ 2 (p_i - 1) \alpha_i + \frac{2 (p_i - 1)}{p_i} \cdot \frac{M}{P_{i-1} \beta_i} \right] \label{eq:cc-ar-multidim} \end{equation}$$下面所有分层算法都是它的实例化。
二层分层 (基础版)
$d = 2$, $G$ 组 × $L$ 节点 / 组 ($N = G L$),组内带宽 $\beta_{\text{intra}} \gg \beta_{\text{inter}}$。三阶段:
| 阶段 | 操作 | 范围 | 数据量 | 链路 |
|---|---|---|---|---|
| 1 | ReduceScatter | 组内 $L$ 节点 | $M \to M / L$ | $\beta_{\text{intra}}$ |
| 2 | AllReduce | 组间 $G$ 个代表 | $M / L$ | $\beta_{\text{inter}}$ |
| 3 | AllGather | 组内 $L$ 节点 | $M / L \to M$ | $\beta_{\text{intra}}$ |
@tbl-cc-ar-2level-flow 二层分层三阶段
$$\begin{equation} T_{\text{2-level}} = 2 (L - 1) \alpha_{\text{intra}} + \frac{2 (L - 1) M}{L \beta_{\text{intra}}} + 2 (G - 1) \alpha_{\text{inter}} + \frac{2 (G - 1) M}{G L \beta_{\text{inter}}} \label{eq:cc-ar-2level} \end{equation}$$跨组通信量从 $2 M$ 缩到 $\approx 2 M / L$,减 $L$ 倍。$\beta_{\text{intra}} / \beta_{\text{inter}} > L$ 时分层总时间由组内主导,组间瓶颈消除。
数值对比 ($G = 4, L = 8, N = 32, M = 100$ MB, $\beta_{\text{intra}} = 450$, $\beta_{\text{inter}} = 25$ GB/s): Flat Ring ≈ 8060 $\mu s$,分层 ≈ 1586 $\mu s$,加速 ≈ 5.1×。
2D-Torus 变体 (Sony, 2018)
$X \times Y$ Torus,行 = 组内,列 = 组间:
- 水平 RS:行 $X$ 节点 Ring RS, $M \to M / X$
- 垂直 AR:列 $Y$ 节点对 $M / X$ 数据 Ring AR
- 水平 AG:行 $X$ 节点 Ring AG, $M / X \to M$
Sony ABCI 2176 V100 训 ResNet-50 122 秒,扩展效率 91.62%。
2D-Mesh 并行 (Google TPU, 2018)
双维并行 (而非串行),利用 TPU ICI 每方向独立物理链路:
- Phase 1: tensor 分两半,前半垂直 Ring AR,后半同时水平 Ring AR
- Phase 2:维度翻转,完成剩余 AR
时间由较慢维度决定:
$$\begin{equation} T_{\text{2D-Mesh}} \approx 2 \cdot \max\!\left( (m - 1) \left( \alpha + \frac{M / 2}{m \beta} \right), \; (n - 1) \left( \alpha + \frac{M / 2}{n \beta} \right) \right) \label{eq:cc-ar-2d-mesh} \end{equation}$$硬件要求:每节点两方向各有独立物理链路。单 NIC GPU 集群无法用,退化为 2D-Torus。Google 报告吞吐为 1D Ring 2×, 1024-chip TPU v3 Pod 训 ResNet-50 2.2 分钟。
BlueConnect $d$ 维通用框架 (IBM, 2019)
12 GPU $p_0 = 3, p_1 = 2, p_2 = 2$ 三层网络示例:
| 阶段 | 级 | 网络层 | 操作 | 数据量 | 并行度 |
|---|---|---|---|---|---|
| 1 | 0 | 节内 $w_0$ | RS | $M \to M / 3$ | 4 组 |
| 2 | 1 | 机内 $w_1$ | RS | $M / 3 \to M / 6$ | 6 组 |
| 3 | 2 | 跨机 $w_2$ | RS | $M / 6 \to M / 12$ | 6 组 |
| 4 | 2 | 跨机 $w_2$ | AG | $M / 12 \to M / 6$ | 6 组 |
| 5 | 1 | 机内 $w_1$ | AG | $M / 6 \to M / 3$ | 6 组 |
| 6 | 0 | 节内 $w_0$ | AG | $M / 3 \to M$ | 4 组 |
@tbl-cc-ar-blueconnect-flow BlueConnect 12 GPU 三层分层流程
跨机 (最慢) 仅传 $M / 6$,经两级压缩 6×。IBM 192 GPU 报告通信开销减 87%。
各变体关系
| 算法 | 维度 $d$ | 分解 | 维度间 | 硬件要求 |
|---|---|---|---|---|
| 二层分层 | 2 | RS → AR → AG | 串行 | 无 |
| 2D-Torus (Sony) | 2 | RS_h → AR_v → AG_h | 串行 | Torus 环绕 |
| 2D-Mesh (Google) | 2 | 双维并行 Ring | 并行 | 多端口独立链路 |
| BlueConnect (IBM) | $d$ | $d$ 级 RS + AG | 级内并行 / 级间串行 | 无 |
@tbl-cc-ar-hier-variants 分层 AR 各变体关系
NCCL 实际策略
- 小消息 ($< 256$ KB): Double Binary Tree (延迟优先)
- 大消息 ($\ge 256$ KB): Hierarchical Ring (节内 RS → 节间 AR → 节内 AG)
- 阈值
NCCL_TREE_THRESHOLD控制切换 - 自动检测 NVLink / PCIe / IB 拓扑构建分层
算法综合对比与选型
核心问题:Ring/HD/DBT/Butterfly/Hierarchical 五种 AllReduce 算法在延迟、带宽、拓扑匹配上如何综合选型?
算法对照
| 算法 | 延迟项 | 带宽项 | 延迟最优 | 带宽最优 | 适用 |
|---|---|---|---|---|---|
| Ring | $2 (N-1) \alpha$ | $\frac{2 (N-1) M}{N \beta}$ | 否 ($O(N)$) | 是 | 小规模大消息 |
| Butterfly | $\log_2 N \cdot \alpha$ | $\log_2 N \cdot M / \beta$ | 是 | 否 | 小消息 ($\le 2$ KB) |
| Halving-Doubling | $2 \log_2 N \cdot \alpha$ | $\frac{2 (N-1) M}{N \beta}$ | 接近 (2×) | 是 | 中大规模通用 |
| Double Binary Tree | $2 \log_2 N \cdot \alpha$ | $\log_2 N \cdot M / \beta$ | 接近 | 否 | 跨节点中消息 |
| 多维分层 | $\sum 2 (p_i - 1) \alpha_i$ | 见 $\eqref{eq:cc-ar-multidim}$ | 视维度 | 视拓扑 | 大规模异构 |
@tbl-cc-ar-algo-overall AllReduce 算法综合对比
消息大小驱动选型
| 消息大小 | 主导 | 推荐 |
|---|---|---|
| $M \le 2$ KB | 延迟 | Butterfly |
| $2$ KB $< M \le 256$ KB | 混合 | HD / DBT |
| $M > 256$ KB | 带宽 | Ring / HD |
| 任意 ($N > 64$) | 延迟 + 拓扑 | 多维分层 |
@tbl-cc-ar-msg-size-routing 按消息大小选算法
OpenMPI 决策树
源码 ompi/mca/coll/tuned/coll_tuned_decision_fixed.c:
- $M < 10000$ Byte → Butterfly
- 元素数 $<$ 节点数 → Reduce + Broadcast
- 可交换 + segment 合适 → Ring 或 Segmented Ring
- 其他 → Reduce + Broadcast
Takeaway
| 知识点 | 核心结论 |
|---|---|
| AllReduce 主分解 | RS + AG,用 Ring 实现两段都带宽最优 |
| 带宽下界 | $(N-1) M / (N \beta)$ |
| 延迟下界 | $\lceil \log_2 N \rceil \cdot \alpha$ |
| Ring AR | 带宽最优,延迟 $O(N)$ |
| Butterfly | 延迟最优 $\log_2 N \alpha$,带宽随 $N$ 退化 |
| Halving-Doubling | 同时近最优 (2× 下界),中大规模通用 |
| Double Binary Tree | NCCL 跨节点小消息默认 |
| 多维分层 | BlueConnect 通用框架,跨慢链路通信缩 $\prod p_j$ 倍 |
| 选型主轴 | 消息大小 (小延迟 / 大带宽) + 拓扑层级 |
| busbw | $M / T \cdot 2 (N-1) / N$,链路实际承载带宽 |
@tbl-cc-ar-takeaway AllReduce 要点
参考资料
- Patarasuk & Yuan, "Bandwidth Optimal All-reduce Algorithms", JPDC 2009 — Ring AR 带宽最优性证明
- Thakur et al., "Optimization of Collective Communication Operations in MPICH", IJHPCA 2005 — Butterfly / HD 算法分析
- Rabenseifner, "Optimization of Collective Reduction Operations", ICCS 2004 — Halving-Doubling
- NCCL 2.4+: Massively Scale Deep Learning Training, NVIDIA — Double Binary Tree
- Mikami et al., "Massively Distributed SGD", Sony 2018 — 2D-Torus AR
- Ying et al., "Image Classification at Supercomputer Scale", Google 2018 — 2D-Mesh AR on TPU Pod
- Cho et al., "BlueConnect", IBM MLSys 2019 — 多维分解框架
- SCCL Documentation v1.0 (SOPHGO) — 4 芯 Ring AR 实测