并行切分的矩阵视角
核心要点:
- 每种并行切的是 transformer 张量的某一维,维度正交可叠加
- TP 切 hidden / head, CP 与 SP 切 seqlen, DP 切 batch, PP 切 layer, EP 切 expert
- 同一个权重矩阵在不同并行下被切的维度不冲突,可以同时切
- "为什么 CP 不切 batch" = batch 维已经被 DP 占住,CP 解决的是 DP 解决不了的单序列内问题
- 通信原语由"切的哪一维 + 算子需要哪一维完整"共同决定
并行策略本质上是在切 transformer 的张量——切权重矩阵、切激活张量,或切层。本文以张量为中心横向汇总:列出 transformer block 的所有权重和激活,给每种并行 (TP / SP / CP / DP / PP / EP) 在每个张量上切哪一维、需要什么通信原语。这是各并行策略文档 (TP / SP / PP / DP / CP / EP) 的横向汇总入口,也是回答"为什么 CP 不切 batch""为什么不同并行能叠加"这类跨维度问题的基础。
张量形状约定
全文用 [batch, seqlen, hidden] 约定激活张量,与已有文档及 knowledge/06-大模型解构 一致。
| 符号 | 含义 |
|---|---|
| $b$ | micro-batch size |
| $s$ | 序列长度 |
| $h$ | hidden dimension |
| $h_{\text{ffn}}$ | FFN intermediate dimension (双矩阵 FFN 典型 $\sim 4h$; SwiGLU 用 3 个矩阵,等参数量折算后 $\sim \frac{8}{3} h$) |
| $n_{\text{head}}$ | attention head 数 |
| $n_{\text{kv\_head}}$ | KV head 数 (GQA / MQA 下 $n_{\text{kv\_head}} \le n_{\text{head}}$) |
| $d_{\text{head}}$ | 单 head 维度,$h = n_{\text{head}} \cdot d_{\text{head}}$ |
| $h_{\text{kv}}$ | KV head 总维度,$h_{\text{kv}} = n_{\text{kv\_head}} \cdot d_{\text{head}}$ (GQA / MQA 下 $h_{\text{kv}} < h$) |
| $V$ | 词表大小 |
| $L$ | 模型层数 |
| $E$ | MoE expert 总数 |
@tbl-mat-symbols 张量形状约定符号表
Transformer block 有哪些张量?
权重矩阵(每层独立,嵌入与 LM head 跨所有层共用一份):
| 张量 | 形状 | 出现位置 |
|---|---|---|
| token embedding | $[V, h]$ | 输入层 (全模型 1 份) |
| LM head | $[h, V]$ | 输出层 (全模型 1 份,常与 embedding 共享) |
| $W_Q$ | $[h, h]$ | 每层 attention (GQA 下 $[h, h_{\text{kv}}]$ 用于 K/V) |
| $W_K$, $W_V$ | $[h, h_{\text{kv}}]$ | 每层 attention |
| $W_O$ | $[h, h]$ | 每层 attention output projection |
| $W_{\text{up}}$ ($W_1$) | $[h, h_{\text{ffn}}]$ | 每层 FFN 上投影 (SwiGLU 含 gate 共两份) |
| $W_{\text{down}}$ ($W_2$) | $[h_{\text{ffn}}, h]$ | 每层 FFN 下投影 |
| MoE expert $W_1^{(e)}, W_2^{(e)}$ | 每 expert 一组 FFN 权重 | MoE 层 (替代 FFN,共 $E$ 组) |
| LayerNorm / RMSNorm $\gamma$ | $[h]$ | 每层 2 次 (Attention 前、FFN 前) |
@tbl-mat-weights 单个 Transformer block 的权重矩阵清单
激活张量(单次前向中间值):
| 张量 | 形状 | 产生位置 |
|---|---|---|
| input hidden | $[b, s, h]$ | block 输入 |
| Q | $[b, n_{\text{head}}, s, d_{\text{head}}]$ | QKV projection 后 |
| K, V | $[b, n_{\text{kv\_head}}, s, d_{\text{head}}]$ | QKV projection 后 |
| attention scores | $[b, n_{\text{head}}, s, s]$ | $QK^\top$ 后 |
| attention output | $[b, s, h]$ | $\text{softmax} \cdot V$ 后 |
| FFN intermediate | $[b, s, h_{\text{ffn}}]$ | $W_{\text{up}}$ 后 |
| block output | $[b, s, h]$ | $W_{\text{down}}$ 后 |
| logits | $[b, s, V]$ | LM head 后 |
@tbl-mat-activations 单次前向的激活张量清单
每种并行切的是哪一维?
一句话总结:每种并行各占一个独立维度,维度间正交,可同时叠加。
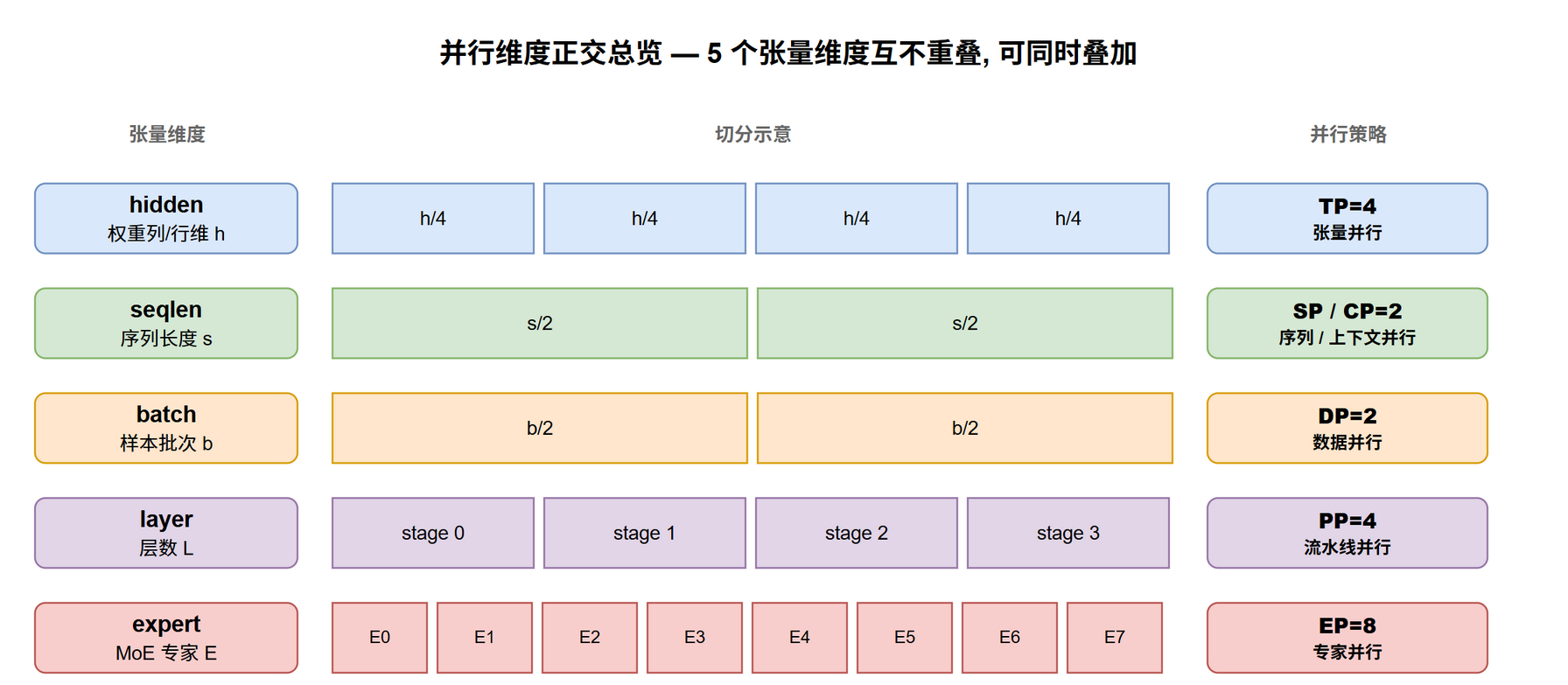
| 并行 | 主要切的维度 | 切的对象 | 一句话原理 |
|---|---|---|---|
| TP | $h$ (或 $n_{\text{head}}$) | 权重矩阵 | 单层权重列/行切,AllReduce 合并部分积 |
| SP | $s$ | 激活 (TP 协同) | 在 TP 不需要完整 $s$ 的位置切 seqlen, AG + RS 替 AllReduce |
| CP | $s$ | 激活 | 单条序列摊到多卡,attention 用 Ring/Ulysses 跨卡看 KV |
| DP | $b$ | 数据样本 | 每 worker 完整模型副本,反向 AllReduce 梯度 |
| PP | $L$ | 层 | 模型按层切 stage, P2P 在边界传激活 |
| EP | $E$ | MoE expert | 不同 expert 在不同设备,AllToAll 路由 token |
@tbl-mat-axis 并行策略对照:切哪一维 / 切什么对象
维度正交是叠加的根本理由:TP 切 $h$、CP 切 $s$、DP 切 $b$、PP 切 $L$、EP 切 $E$,五者切的维度互不重叠,因此
TP × CP × DP × PP × EP可以同时存在 — 典型大模型训练正是这样组合的。
权重矩阵 × 并行:谁切谁不切
TP 在权重上有两种切法 — 列切 (用于 $W_Q, W_K, W_V, W_{\text{up}}$) 与行切 (用于 $W_O, W_{\text{down}}$),二者的输出形状和通信结构截然不同:
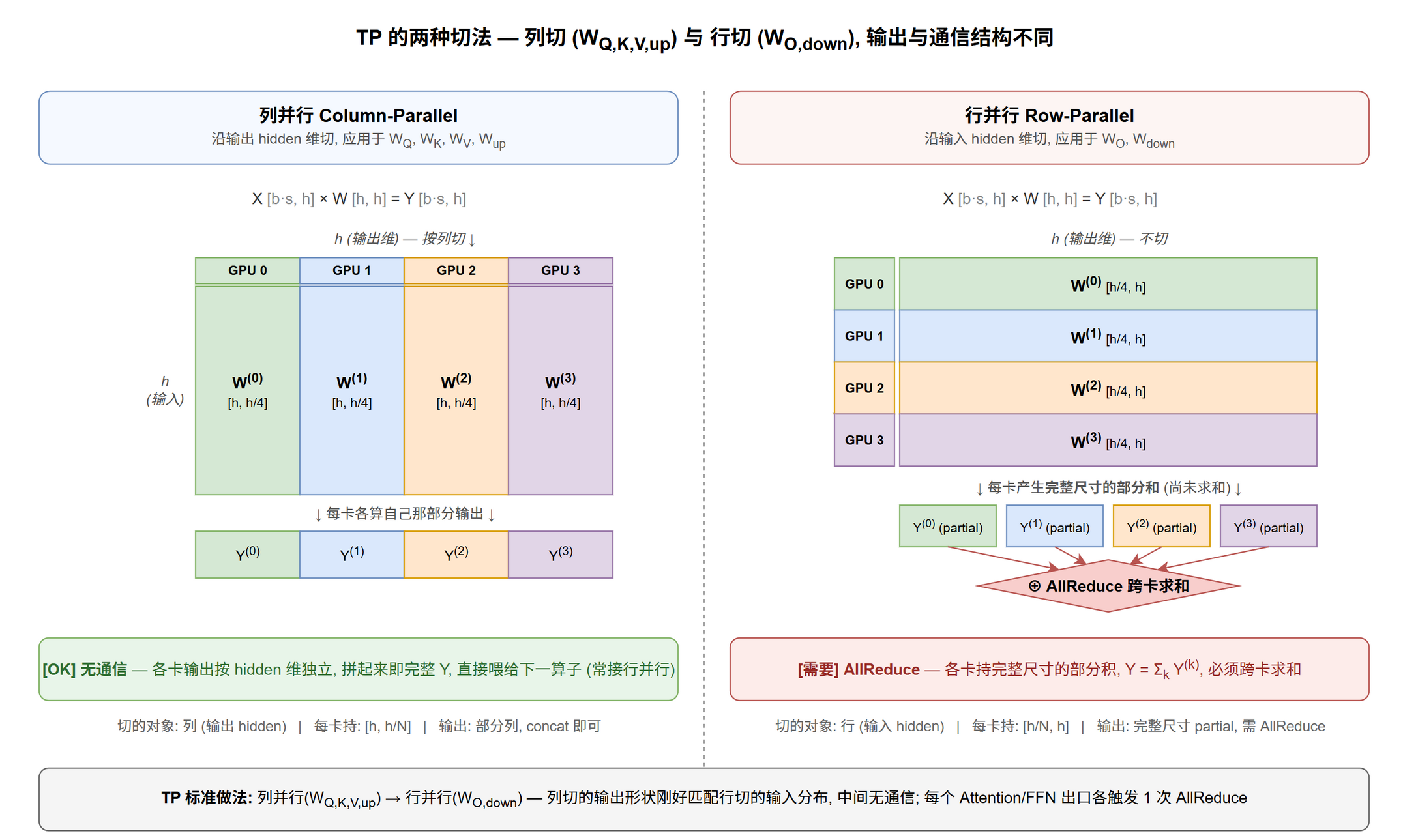
| 权重 | TP | SP | CP | DP | PP | EP |
|---|---|---|---|---|---|---|
| token embedding $[V, h]$ | 切 $V$ 或 $h$ (vocab parallel / TP) | 不切 | 不切 | 完整副本 | 在 stage 0 | 不切 |
| LM head $[h, V]$ | 切 $V$ 或 $h$ | 不切 | 不切 | 完整副本 | 在 stage L-1 | 不切 |
| $W_Q, W_K, W_V$ | 列切,按 head 维 | 不切 | 不切 | 完整副本 | 按层归属 stage | 不切 |
| $W_O$ | 行切 | 不切 | 不切 | 完整副本 | 按层归属 stage | 不切 |
| $W_{\text{up}}$ | 列切 | 不切 | 不切 | 完整副本 | 按层归属 stage | 不切 (dense FFN) |
| $W_{\text{down}}$ | 行切 | 不切 | 不切 | 完整副本 | 按层归属 stage | 不切 (dense FFN) |
| MoE expert $W_1^{(e)}, W_2^{(e)}$ | (可选) 切 $h_{\text{ffn}}$,称 moe_tp | 不切 | 不切 | 完整副本 | 按层归属 stage | 切 $E$,不同 expert 在不同卡 |
| LayerNorm $\gamma$ | 完整副本 (轻量) | 不切 | 不切 | 完整副本 | 按层归属 stage | 不切 |
@tbl-mat-weight-cut 权重矩阵在各并行下的切法
关键观察:
- CP / DP 完全不切权重,它们只切激活或样本;因此 CP / DP 不增加权重显存压力,不缓解模型放不下的问题,只缓解 activation/KV 放不下与吞吐问题
- TP / EP 各切权重的不同维:TP 切 dense 算子的 hidden 维,EP 切 MoE 的 expert 维;两者可叠加 (EP 切 expert, TP 再在 expert 内切 $h_{\text{ffn}}$,称 moe_tp)
- PP 不"切"权重而是"分"权重:每层完整保留,不同层归不同 stage
- SP 列恒为"不切"不是遗漏:SP 切的是激活的 $s$ 维,不动任何权重 (见下表激活切分)
激活张量 × 并行:切完之后形状变成什么
| 激活 | TP | SP | CP | DP | PP | EP |
|---|---|---|---|---|---|---|
| input hidden $[b, s, h]$ | 切 $h \to [b, s, h/N_{\text{TP}}]$ | 切 $s \to [b, s/N_{\text{TP}}, h]$ (TP 不需完整 $s$ 的区段) | 切 $s \to [b, s/N_{\text{CP}}, h]$ | 切 $b \to [b/N_{\text{DP}}, s, h]$ | 不切,在某个 stage 上 | 不切 |
| Q $[b, n_h, s, d_h]$ | 切 $n_{\text{head}}$ → 每卡 $n_h/N_{\text{TP}}$ 个 head | (与 input hidden 同 $s$) | 切 $s$ → 每卡 $s/N_{\text{CP}}$ 个 token | 切 $b$ | 不切 | 不切 |
| K, V | 切 $n_{\text{kv\_head}}$ | (同上) | 切 $s$, attention 时需跨卡看全部 KV | 切 $b$ | 不切 | 不切 |
| attention scores $[b, n_h, s, s]$ | 切 $n_{\text{head}}$ | 不出现完整 (TP 内独立算) | 不显式持有 (Ring 增量算) | 切 $b$ | 不切 | 不切 |
| FFN intermediate $[b, s, h_{\text{ffn}}]$ | 切 $h_{\text{ffn}}$ → 每卡 $h_{\text{ffn}}/N_{\text{TP}}$ | 切 $s$ (TP 协同) | 切 $s$ | 切 $b$ | 不切 | (MoE) 不同 token 在不同 expert 卡 |
| logits $[b, s, V]$ | (可选) vocab parallel 切 $V$ | 不切 | 切 $s$ | 切 $b$ | 在 stage L-1 | 不切 |
@tbl-mat-act-cut 激活张量在各并行下的形状变化
通信原语从何而来?
通信原语由"切的哪一维"和"算子需要哪一维完整"共同决定。算子如果需要完整的某一维,而那一维已被切了,就必须在算子前后插通信:
| 触发场景 | 通信原语 | 出现在 |
|---|---|---|
| 算子内部需要完整 $h$ (TP 行并行求和 partial sum) | AllReduce | TP 每层 2 次 |
| 算子前需要完整 $s$ (LayerNorm) | AllGather | SP |
| 算子后归约 + 重切 $s$ | ReduceScatter | SP |
| Attention 需要全局 KV,但 KV 沿 $s$ 切 | Ring 传 KV / All-to-All (Ulysses) | CP |
| 多副本梯度需要平均 | AllReduce ($\lvert\theta\rvert$ 量级) | DP 每 step 末梯度同步 |
| 相邻 stage 边界传激活 | P2P Send/Recv | PP |
| MoE token 按 top-K 路由到 expert 所在卡 | All-to-All (Dispatch + Combine) | EP |
@tbl-mat-primitives 通信原语 = 切的维度 × 算子需要完整的维度
把"切哪一维 + 算子要什么"映射到具体并行后,得到下表 — 每种并行的通信原语、触发时机、消息大小公式与典型量级:
| 并行 | 通信原语 | 触发时机 | 单次消息公式 | 典型量级 |
|---|---|---|---|---|
| TP | AllReduce | 每层 Attention 出口 + MLP 出口 (训练时反向再各 1 次) | $b \cdot s \cdot h \cdot \text{dtype}$ | 10 ~ 100 MB |
| SP | AllGather + ReduceScatter | 每层 LayerNorm 前后 (替换 TP 的 AllReduce) | $b \cdot s \cdot h \cdot \text{dtype}$ | 10 ~ 100 MB (合计与 TP 相同) |
| PP | P2P Send/Recv | 每 micro-batch 在 stage 边界 | $b \cdot s \cdot h \cdot \text{dtype}$ | 10 ~ 100 MB |
| DP | AllReduce | 每 training step 反向末梯度同步 | $\lvert\theta\rvert \cdot \text{grad\_dtype}$ | 全参数量级,强依赖模型规模 (70B×2B ≈ 140 GB) |
| CP | Ring 传 KV 或 All-to-All (Ulysses) | attention 内部,每 $N_{\text{CP}}$ 步 | KV 块大小,形态依算法 | 取决于 $s$ 与 KV 头数 |
| EP | All-to-All (Dispatch + Combine) | 每 MoE 层 2 次 | $B \cdot K \cdot h \cdot \text{dtype}$ | 0.1 ~ 60 MB |
@tbl-mat-primitives-detail 各并行的通信原语、公式与量级
符号:$b$ = micro-batch, $s$ = 序列长度,$h$ = hidden, $\lvert\theta\rvert$ = 模型参数量,$B$ = token 总数,$K$ = top-K expert 数,$N_{\text{CP}}$ = CP 并行度。各原语的详细分析见对应分论 (TP / SP / PP / DP / CP / EP)。
维度叠加:同一个矩阵能被多种并行同时切
因为每种并行切的维度正交,同一个权重 / 激活可以被多个并行同时切,而不冲突。
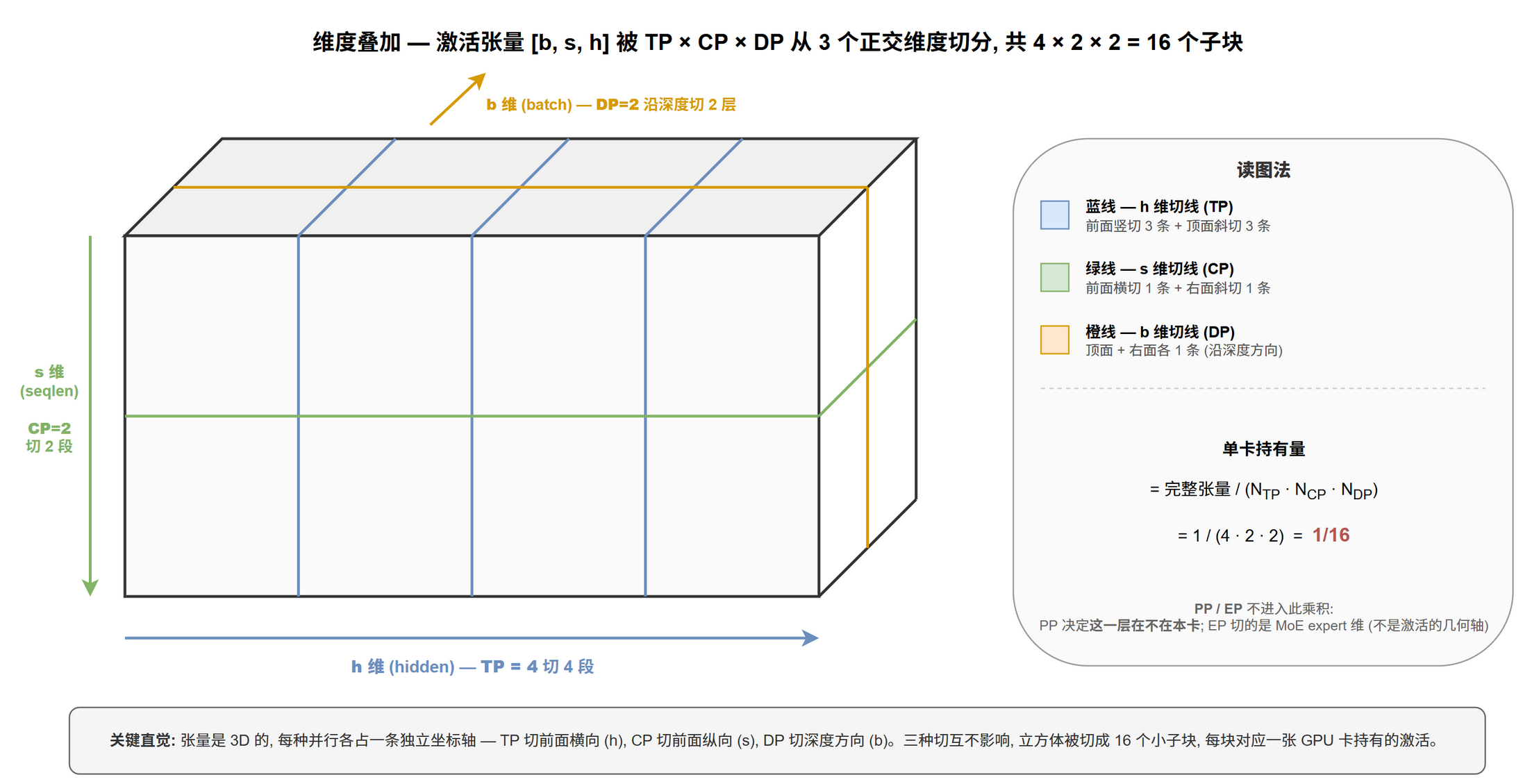
以 FFN intermediate 激活 $[b, s, h_{\text{ffn}}]$ 为例,在 TP=4, CP=2, DP=2 下:
| 起始形状 | 应用 TP=4 切 $h_{\text{ffn}}$ | 应用 CP=2 切 $s$ | 应用 DP=2 切 $b$ | 单卡持有 |
|---|---|---|---|---|
| $[b, s, h_{\text{ffn}}]$ | $[b, s, h_{\text{ffn}}/4]$ | $[b, s/2, h_{\text{ffn}}/4]$ | $[b/2, s/2, h_{\text{ffn}}/4]$ | $\frac{1}{16}$ 原激活 |
PP 再叠 → 这一层只存在 $L/N_{\text{PP}}$ 个 stage 之一上,其余 stage 没有这块激活。EP 叠 → 若该层是 MoE,不同 expert 进一步分到不同卡。
叠加倍率:单卡激活显存 = $\frac{\text{完整激活}}{N_{\text{TP}} \cdot N_{\text{CP}} \cdot N_{\text{DP}}}$ (PP 与 EP 不直接进入此乘式,影响的是"这一层在不在本卡")。
几个常见问题用矩阵视角回答
为什么 CP 不切 batch?
切 batch 这件事已经被 DP 占住,自成一种并行。如果一个并行切 $b$,它就是 DP — 不是 CP。CP 之所以单独存在,是因为长上下文场景下 $s$ 大到单卡装不下激活/KV,这时:
- 即使 batch = 1,单条序列内部就放不下,此时 DP 无可切,只能切 $s$
- batch > 1 时也一样,DP 把 $b$ 摊到头仍解决不了"单条序列内激活随 $s$ 线性涨"的问题
切 $b$ 是 DP 的疆域,切 $s$ 是 CP 与 SP 的疆域,两者解决的是显存张量的不同维。
为什么 TP 与 CP 的通信开销量级不同?
| 并行 | 每层通信原语 | 通信量级 | 是否在关键路径 |
|---|---|---|---|
| TP | AllReduce $\times 2$ | $b \cdot s \cdot h \cdot \text{dtype}$ | 是 (前向无 overlap) |
| CP | Ring 传 KV $\times N_{\text{CP}}$ 步 (仅 attention 内) | 与 KV 总量同量级,但分多步可与计算 overlap | 部分 (Ring 步可 overlap) |
差别根源:
- TP 在 dense FFN 与 attention output 两处都触发 AllReduce,每层 2 次,每次必须完整等完
- CP 只在 attention 内部触发通信 (FFN / LayerNorm 在 $s$ 维上无依赖,完全不通信),且 Ring 把通信切成 $N$ 个小步穿插在 $N$ 个计算块之间
详见 03-张量并行 与 07-上下文并行/02-ring-attention。
为什么 SP 必须搭 TP, CP 却可独立?
SP 切的是 TP 不需要完整 $s$ 的区段 (LayerNorm 之类),它的作用是把 TP 的 AllReduce 拆成 AG + RS — 没有 TP 就没有 AllReduce 可拆,SP 就失去存在意义。
CP 切的也是 $s$,但解决的是 attention 跨 rank 的全局性,与 TP 是否存在无关。CP 可以独立存在,也可以与 TP 叠加 (SP × CP 又是另一回事,见 07-上下文并行/01-总览)。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 切的维度 | TP→$h$, SP/CP→$s$, DP→$b$, PP→$L$, EP→$E$,五维正交 |
| 权重谁切谁不切 | TP / EP 切权重,DP / CP / SP 不切权重,PP 按层分权重 |
| 激活叠加 | 单卡激活 = 完整激活 / ($N_{\text{TP}} \cdot N_{\text{CP}} \cdot N_{\text{DP}}$) |
| 通信原语来源 | 切的维度 + 算子需要完整的维度 共同决定 |
| CP vs DP | 切 $b$ 就是 DP, CP 解决的是 DP 解决不了的"单序列内放不下" |
| CP vs TP 开销 | TP 每层 AllReduce 在关键路径;CP 只在 attention 内通信,多步可与计算 overlap |
| SP vs CP | SP 必须搭 TP, CP 可独立;两者都切 $s$ 但目的不同 |
@tbl-mat-takeaway 并行切分矩阵视角核心知识点
文档导航
基础并行策略:
- 3 张量并行 (TP) — TP 列/行切分、AllReduce
- 4.1 总览 — SP 切 $s$、AG + RS
- 5 流水并行 (PP) — PP stage 切分、P2P、bubble
- 6 数据并行 (DP) — DP 梯度 AllReduce、ZeRO
- 7.1 总览 — CP Ring/Ulysses、decode CP
- 8.1 总览 — EP MoE 路由、AllToAll
横向相关 (09-跨策略横向):
- 9.1 总览 — 跨策略横向章范围
- 9.2 计算通信 Overlap — 各策略 overlap 潜力
- 9.3 推理部署模式 — Prefill/Decode 不对称、PD 分离
外部接缝:
- knowledge/06-大模型解构 — 张量形状与矩阵计算的基础知识 (本文形状约定的源头)