Ring Attention
K/V 怎么环传分块、online softmax 如何增量累计、通信能否被计算掩盖
核心要点:
- K/V 在卡间环形传递,每卡只持 $S/N$ 个 K/V
- online softmax 支持 K/V 分块增量计算
- per-rank 通信量 $O(S \cdot d)$,不随 $N$ 变
- 通信能否被计算掩盖取决于 $S/N$ 大小
- causal mask 下需 balanced split 配平负载
名词定义
| 名词 | 定义 |
|---|---|
| Running max / sum | online softmax 增量维护的当前最大 logit 与归一化分母,每收到一段新 K/V 更新一次 |
| Balanced chunk split | Megatron-CP 的 causal 配平法:序列分 $2N$ chunk,每 rank 持 chunk $i$ 与 $2N-1-i$,均衡负载 |
| Zigzag ring attention | balanced chunk split 的工业界叫法(flash-attn 社区):按 block 头尾配对,rank $r$ 持 block $r$ 与 block $2N-1-r$ |
| Striped Attention | 另一种 causal 配平:token $i$ 按 $i \bmod N = r$ 归 rank $r$,均衡但访存模式不同 |
| Ring Self-Attention (RSA) | Ring Attention 的前身(Colossal-AI, 2021):同样环形旋转,但无 online softmax,需物化完整 attention logits 再做 softmax,K/V 各转一圈共两轮通信,内存随 $S$ 平方增长,现仅作论文基线[1] |
CP / Ring Attention / online softmax 等共享名词见 7.1 总览 名词定义。
Ring Attention 怎么让每卡只持 S/N 个 KV 还能算全局 attention?
Ring Attention 通过 K/V 环形传递 + online softmax 增量计算,让每 rank 只持 $S/N$ 个 K/V,但 K/V 流过所有 rank[2]。
算法步骤:
初始化: 每 rank 用本地 Q 和本地 K/V 算 partial attention output
本地 softmax 保留 running max 和 running sum
循环 N-1 次:
- 每 rank 把当前持有的 K/V 发给下一 rank (同时从上一 rank 接收新 K/V)
- 用本地 Q 和新到的 K/V 算下一段 partial attention
- 用 online softmax 更新 running max / running sum / output
循环结束:
- 每 rank 把 running sum 归一化, 得到本地 Q 对应的最终 output
每 rank 始终只持有完整 query 的本地切片和一段 $S/N$ 的 K/V,内存与段大小线性,而非与 $S$ 线性。
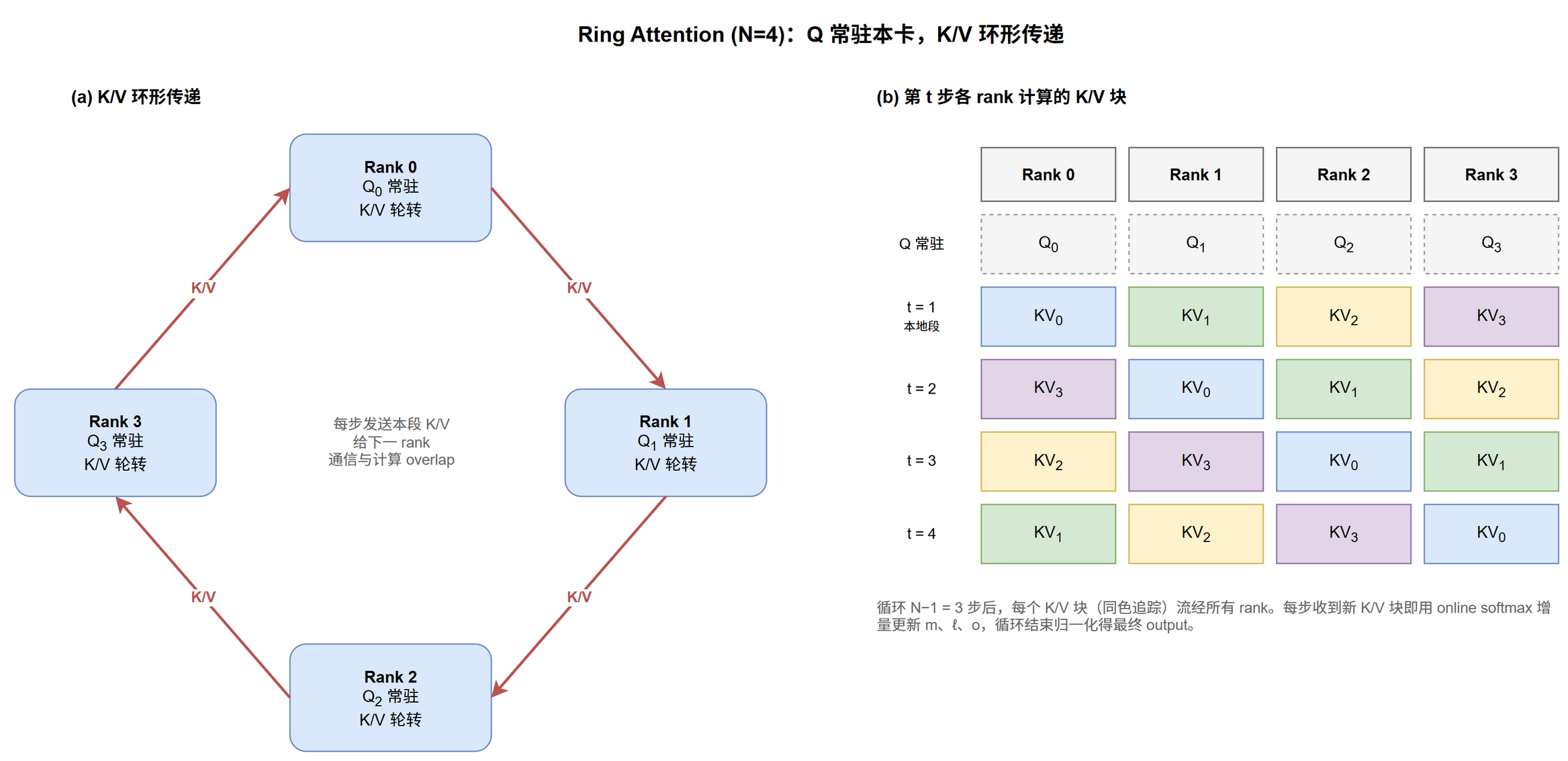
Online softmax 为什么是 Ring 的关键?
普通 softmax 必须看到所有 logits 才能算分母,Ring Attention 用 online softmax 支持增量更新,由 Milakov & Gimelshein 提出[3],被 FlashAttention 用于 tile 化 attention[4]:
$$\begin{equation} \begin{aligned} m^{(t)} &= \max(m^{(t-1)}, \max_i z_i^{(t)}) \\ \ell^{(t)} &= e^{m^{(t-1)} - m^{(t)}} \ell^{(t-1)} + \sum_i e^{z_i^{(t)} - m^{(t)}} \\ \mathbf{o}^{(t)} &= e^{m^{(t-1)} - m^{(t)}} \mathbf{o}^{(t-1)} + \sum_i e^{z_i^{(t)} - m^{(t)}} \mathbf{v}_i^{(t)} \end{aligned} \label{eq:par-cp-online-softmax} \end{equation}$$- $t$: K/V 段序号,$t=1$ 是本地段,$t=2,\ldots,N$ 是从 ring 上游依次接收的段
- $z_i^{(t)} = \mathbf{q} \cdot \mathbf{k}_i^{(t)} / \sqrt{d_{\text{head}}}$:本 rank query 与第 $t$ 段第 $i$ 个 key 的 scaled 内积
- $m^{(t)}, \ell^{(t)}, \mathbf{o}^{(t)}$: running max / normalizer / output,初值 $m^{(0)} = -\infty, \ell^{(0)} = 0, \mathbf{o}^{(0)} = \mathbf{0}$
- 最终 $\mathbf{o} = \mathbf{o}^{(N)} / \ell^{(N)}$
每收到一段新 K/V 增量更新一次,不保留中间 logits。
Ring 每卡通信多少?随 CP 度怎么变?
Ring 的 per-rank 总通信量 $\sim S \cdot d_{\text{model}}$,与 token 数线性,不随 $N$ 变。每 rank 每轮发送 $S/N$ 个 K/V,共 $N-1$ 轮 ($d \equiv d_{\text{model}} = h \cdot d_{\text{head}}$):
$$\begin{equation} M_{\text{ring}}^{\text{per-rank}} = (N-1) \cdot \frac{S}{N} \cdot 2 d_{\text{model}} \cdot s_{\text{dtype}} \approx S \cdot 2 d_{\text{model}} \cdot s_{\text{dtype}} \label{eq:par-cp-ring-comm} \end{equation}$$系数 2 是 K + V 两份。典型量级 (1M context, $d_{\text{model}} = 7168$, BF16, $N=8$):每 rank 每 ring 步约 3.6 GiB, 7 步累计约 25 GiB,渐近上界 28 GiB ($N \to \infty$)。
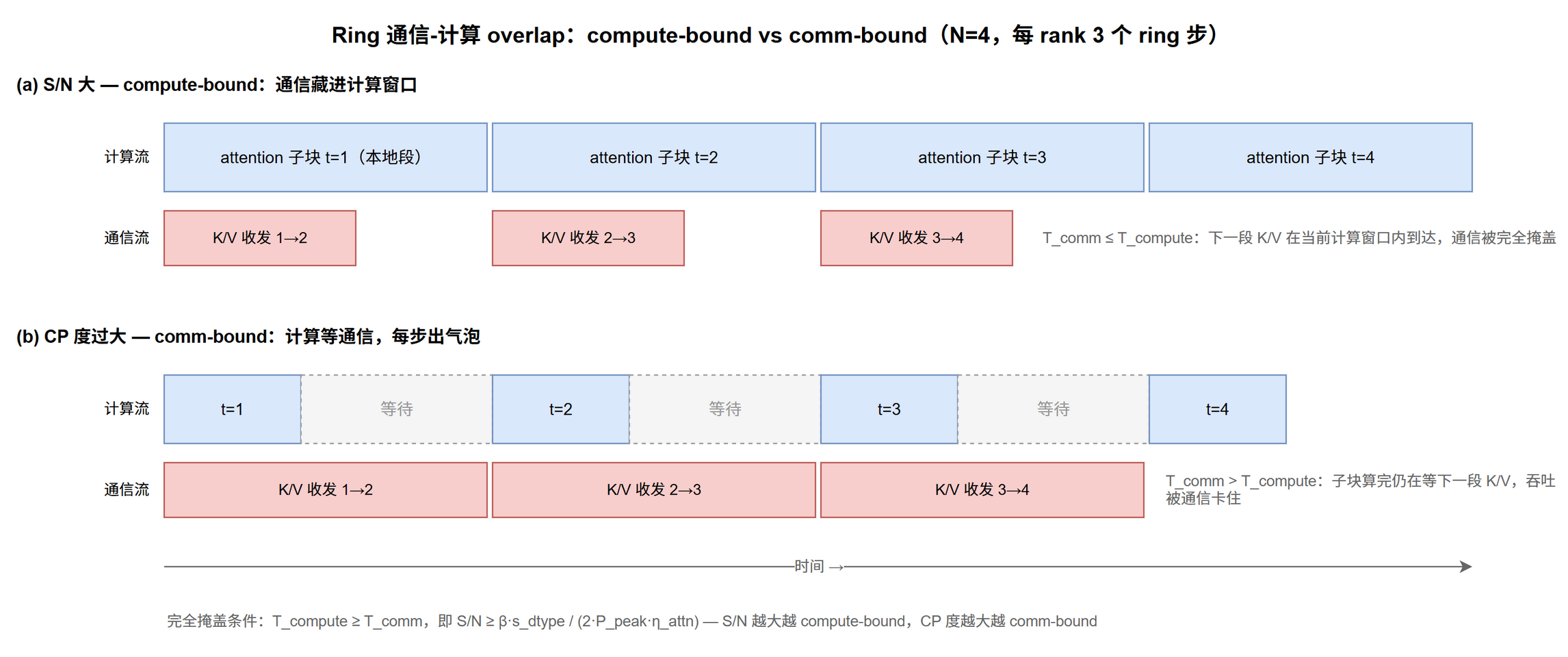
Ring 的通信能被计算掩盖吗?
Ring 设计的关键是 K/V 通信与本地 attention 计算重叠,能否充分 overlap 取决于两个延迟分量的相对大小[2]。
单步通信延迟:
$$\begin{equation} T_{\text{step}}^{\text{comm}} = \alpha + \frac{2 \cdot (S/N) \cdot d \cdot s_{\text{dtype}}}{\beta} \label{eq:par-cp-ring-step-comm} \end{equation}$$- $\alpha$:相邻 rank 一跳通信基础延迟
- $\beta$: CP 通信链路单向带宽
- 系数 2 来自 K + V
单步计算延迟 ($(S/N) \times (S/N)$ 子块 dense attention):
$$\begin{equation} T_{\text{step}}^{\text{compute}} \approx \frac{4 \cdot (S/N)^2 \cdot d}{P_{\text{peak}} \cdot \eta_{\text{attn}}} \label{eq:par-cp-ring-step-compute} \end{equation}$$- $P_{\text{peak}}$:单 GPU 在所用 dtype 下的峰值算力
- $\eta_{\text{attn}}$: FlashAttention kernel 实际利用率 (典型 0.4 ~ 0.6)
- 系数 4 来自 $QK^\top$ + $\text{softmax}(\cdot) \cdot V$
通信被计算完全掩盖的条件:
$$\begin{equation} T_{\text{step}}^{\text{compute}} \geq T_{\text{step}}^{\text{comm}} \label{eq:par-cp-ring-overlap-condition} \end{equation}$$代入并忽略 $\alpha$,得 compute-bound 阈值:
$$\begin{equation} \frac{S}{N} \geq \frac{\beta \cdot s_{\text{dtype}}}{2 \cdot P_{\text{peak}} \cdot \eta_{\text{attn}}} \label{eq:par-cp-ring-compute-bound-threshold} \end{equation}$$每 rank 持 token 数 $S/N$ 越大越 compute-bound; CP 度 $N$ 越大或单 GPU 算力越高越 comm-bound。CP 度过大时 ring overlap 失效,因为单 rank 的 attention 子块算得太快,通信跟不上。
实测验证:Meta 在 H100/CP4/Llama3-405B 上测得 pass-KV 的 SendRecv 在低 miss rate (2.5%) 时 627 μs > attention 计算 414 μs,通信暴露;高 miss rate (10%) 时计算 1608 μs >> SendRecv 631 μs,通信被完全掩盖[^meta-cp]。overlap 效率不是静态比值,取决于新 token 数与 CP 度的关系。
Causal mask 下 Ring 怎么配平负载?
Decoder 是 causal attention: query token $t$ 只能看 token $\le t$ 的 KV。Ring 旋转 K/V 时部分接收到的 KV 是未来 token,必须 mask 掉,不处理会让带宽利用率只有 50%。
两种优化:
- Mask off:照常通信,本地用 causal mask 屏蔽未来 KV — 带宽利用率仅 50%
- Balanced chunk split (Megatron-CP)[5]:把序列分成 $2N$ 个 chunk,每 rank 同时持 chunk $i$ 和 chunk $2N-1-i$,让每 rank 都拥有「靠前的轻 causal 负载 + 靠后的重 causal 负载」
$N=4$ 时的 chunk 配对:
| Rank | 持有的 chunk | 靠前 chunk (causal 轻) | 靠后 chunk (causal 重) |
|---|---|---|---|
| 0 | 0, 7 | 0 | 7 |
| 1 | 1, 6 | 1 | 6 |
| 2 | 2, 5 | 2 | 5 |
| 3 | 3, 4 | 3 | 4 |
@tbl-par-cp-ring-balanced N=4 时 balanced chunk split 的 rank ↔ chunk 配对
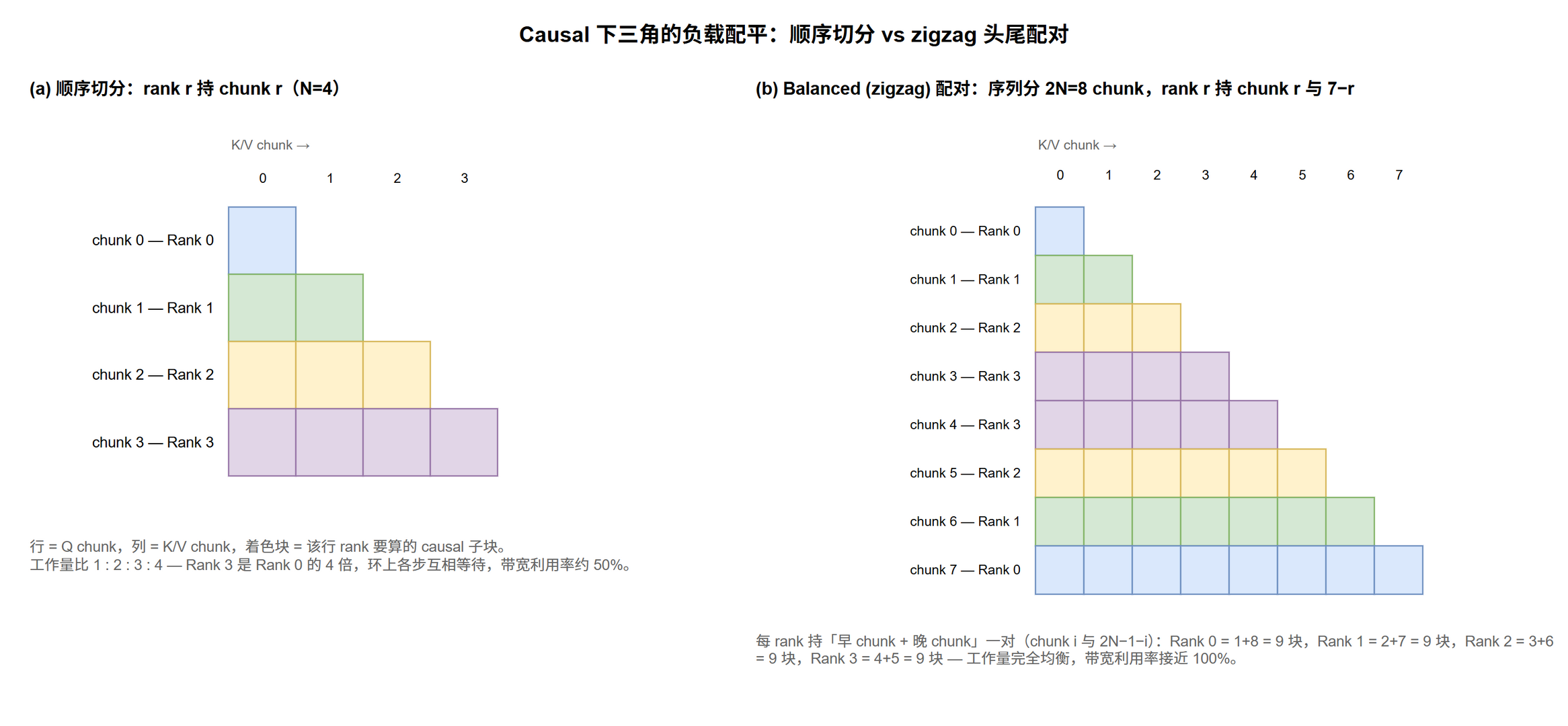
每 rank 工作量近似均衡,通信带宽利用率接近 100%。另一种思路 Striped Attention 按 stride 分配(token $i$ 满足 $i \bmod N = r$ 归 rank $r$)[6],也实现均衡但访存模式不同。工业实现(flash-attn 社区)把这类「头尾配对 / 交错分配」称为 zigzag ring attention,与 striped 同解 causal 三角不均衡,区别在粒度:zigzag 按 block 头尾配对(rank $r$ 持 block $r$ 与 block $2N-1-r$),striped 按 token 交错。
工业界已收敛到 zigzag,根因是它与 FlashAttention 的 tile 计算模型对齐。FlashAttention 按 tile 遍历 KV,causal 性质让整块被 mask 的 tile 直接跳过、不进 kernel。两种配平方案与这条快路径的契合度不同:
- zigzag(block 连续):每 rank 持有两段连续 token,非自身 block 的步里每个 tile 要么整块在 causal 范围内、要么整块被 mask——整块算或整块跳;$N$ 步中只有自身 block 那一步含对角边界,现成 FlashAttention kernel 几乎不用改。
- striped(token 交错):rank 持有的 token 物理离散,每一步的 mask 都是带 $\pm 1$ 偏移的严格三角(可见条件 $i > j$ 而非原生 causal 的 $i \ge j$)——含 mask 边界的 tile 每步都出现且需逐元素判断,还需定制 kernel 处理偏移。
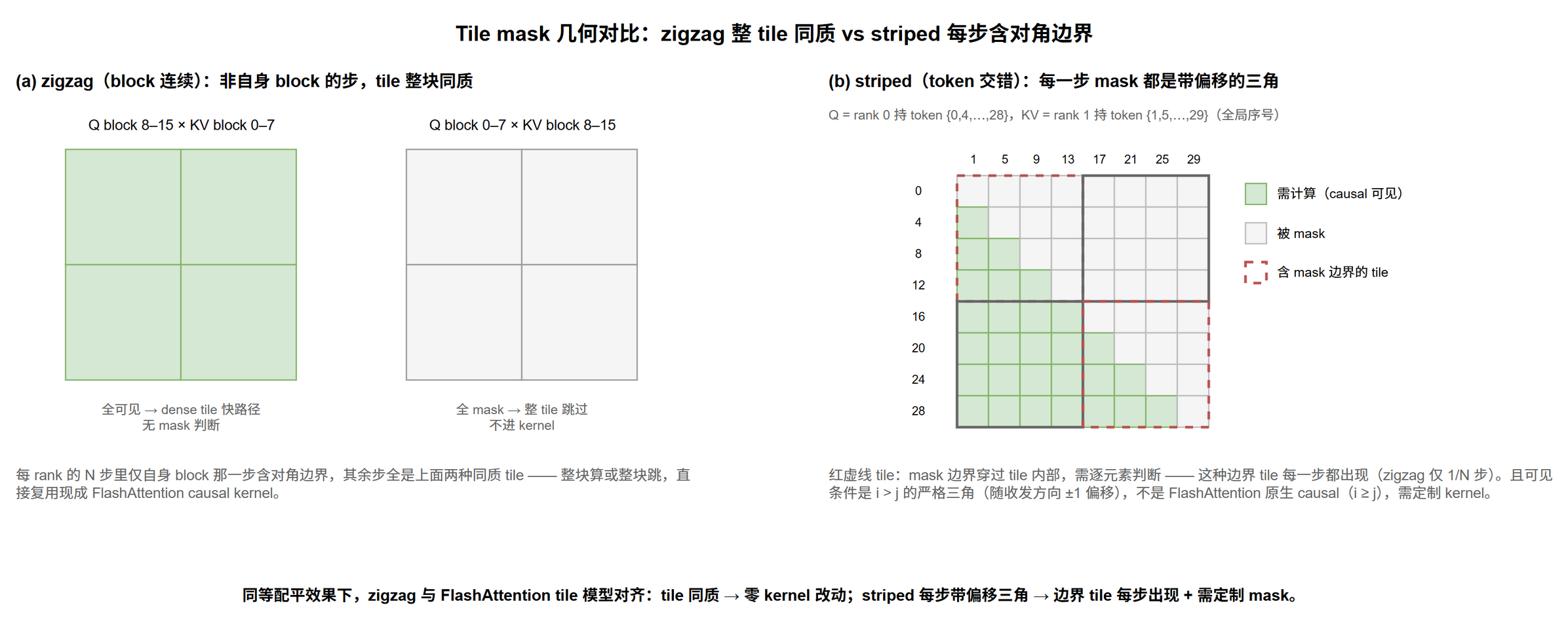
两者配平效果等价,但 zigzag 在「效率持平甚至更高 + 零 kernel 改动」下胜出:它能零成本复用现成 kernel,striped 缺少同等成熟的开源实现。这是算法被底层 kernel 约束反向选择的例子——理论上更均匀的 striped,输给了工程上更省事的 zigzag。变长序列下的 zigzag 见下文。
静态配平之外,怎么动态调度 causal 负载?
balanced split / striped 是按几何位置预分配负载的静态法;DistFlashAttn (LightSeq) 改成运行时让空闲 rank 偷取繁忙 rank 的 attention 计算[7]。
causal mask 下早 token 的 rank 计算量远小于晚 token 的 rank(计算量正比于前缀长度),静态重排只能近似配平。DistFlashAttn 的做法是运行时调度:把繁忙 rank 上 query 与远端 K/V 的子块计算 $\text{attn}(\mathbf{q}_{r_2}, \mathbf{k}_{r_1}, \mathbf{v}_{r_1})$ 派给空闲 rank,再用 online softmax 的 rescale 把 partial 结果合并回原 rank。8 卡时均衡后理论加速比从非均衡的 4.5× 提到 7.5×,相对提升约 1.67×。
与 striped 的区别是调度对象:striped 静态重排序列块(动几何位置),DistFlashAttn 动态调度计算单元(运行时 work-stealing)。
DistFlashAttn 还把 CP 与梯度重算(activation checkpointing)的交互纳入设计——这是长序列训练绕不开的内存维度:
- 重算感知的 checkpoint:标准 gradient checkpointing 在层边界 checkpoint,反向时重跑 FlashAttention 前向,而 FlashAttention 反向本身又要重算一次 softmax,形成双重重算。DistFlashAttn 把 checkpoint 边界移到 FlashAttention kernel 的输出 tensor,该 tensor 同时服务后续模块恢复与当前 attention 反向,消除一次 attention 重算(32K token/卡 时约 1.31× 加速)[7]。
- 通信 overlap:双 stream 异步 prefetch 下一轮 K/V,把通信开销从占计算的 105% 压到 44%。
整体实测:
| 对比基线 | 加速 | 备注 |
|---|---|---|
| Ring Self-Attention | 4.45-5.64× | 同时支持 8× 更长序列 |
| Ring Attention | 1.67× | 负载均衡贡献 |
| DeepSpeed-Ulysses | 1.26-1.88× | head 数不规则模型收益更大(Ulysses 受 $N\le h$ 约束) |
@tbl-par-cp-ring-distflashattn DistFlashAttn 相对各基线的实测加速[7]
变长序列打包后 Ring 怎么不浪费?
真实训练里序列不等长,打包成 batch 后 padding 浪费与 causal 不均衡叠加;varlen ring 直接在打包序列上做头尾 block 配对来均衡。
等长 causal 配平假设一个 batch 是单条定长序列。实际语料里序列长度差异大,按最长序列 padding 会浪费 20-50% 计算,跨 rank 的 causal 计算量也不均。变长(varlen)ring attention 用 cu_seqlens 描述打包边界,在打包后的整条序列上套 zigzag 头尾配对(rank $r$ 持 block $r$ 与 block $2P-1-r$),让每 rank 都拿到「早 + 晚」token 对,避免按最长序列 padding 的计算浪费[8]。
后训练框架(如 360-LLaMA-Factory)把这套 varlen 序列并行做成即插即用,让长序列 SFT / DPO 不必为不等长样本付 padding 税[8]。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 环传机制 | K/V 环形流过所有 rank,每 rank 只持 $S/N$ 个 K/V |
| online softmax | 增量维护 running max/sum,不保留中间 logits |
| 通信量 | per-rank $O(S \cdot d)$,不随 $N$ 变 |
| overlap 条件 | $S/N$ 大 → compute-bound;CP 度过大 → comm-bound |
| causal 配平 | zigzag(block 头尾配对)与 striped(token 交错)同把带宽利用率从 50% 拉到 ~100%;工业界因 FlashAttention tile-skip 收敛到 zigzag |
| 动态调度 | DistFlashAttn work-stealing + 重算感知 checkpoint,vs Ring 1.67× |
| 变长序列 | varlen zigzag 头尾配对,打包序列免 padding 税 |
@tbl-par-cp-ring-takeaway Ring Attention 核心知识点
参考资料
- Li et al., Sequence Parallelism: Long Sequence Training from System Perspective, arXiv:2105.13120, 2021. https://arxiv.org/abs/2105.13120
- Liu et al., Ring Attention with Blockwise Transformers for Near-Infinite Context, arXiv:2310.01889, 2023. https://arxiv.org/abs/2310.01889
- Milakov & Gimelshein, Online normalizer calculation for softmax, arXiv:1805.02867, 2018. https://arxiv.org/abs/1805.02867
- Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, arXiv:2205.14135, 2022. https://arxiv.org/abs/2205.14135
- NVIDIA, Megatron-Core Context Parallelism. https://docs.nvidia.com/megatron-core/developer-guide/latest/user-guide/features/context_parallel.html
- Brandon et al., Striped Attention: Faster Ring Attention for Causal Transformers, arXiv:2311.09431, 2023. https://arxiv.org/abs/2311.09431
- Li et al., DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs Training, arXiv:2310.03294, 2023. https://arxiv.org/abs/2310.03294
- 360-LLaMA-Factory: Plug & Play Sequence Parallelism for Long Post-Training, arXiv:2505.22296, 2025. https://arxiv.org/abs/2505.22296