Tree Attention
归约拓扑改树形怎么把步数压到 O(log p)、只传三量为何与序列长度解耦
核心要点:
- 跨卡归约从环传改树形,步数 $O(\log p)$ 而非 $O(p)$
- 只传 online softmax 三量,通信量与序列长解耦
- 三量合并满足结合律,任意归约顺序结果等价
- exact 计算,非近似
- 主攻 decode,峰值内存约为 Ring 的一半
名词定义
| 名词 | 定义 |
|---|---|
| 树形归约 (Tree reduction) | 用 $\log p$ 层两两合并完成 $p$ 个元素的结合律归约,对应 AllReduce 的树形实现,替代 Ring 的 $p$ 步顺序环传 |
| 三量 (max / numerator / denominator) | online softmax 的可合并状态:running max $m$、分子 $\mathbf{n}=\mathbf{o}\cdot e^{\ell-m}$、分母 $d=e^{\ell-m}$;Tree 跨卡归约的就是这三个量 |
| 拓扑感知 (Topology-aware) | 通信原语能贴合「节点内高带宽 + 节点间低带宽」的两级网络;AllReduce 可分层实现,P2P 环传不能 |
CP / Ring Attention / online softmax / pass-Q 等共享名词见 7.1 总览 名词定义。
为什么 attention 的跨卡归约能从环改成树?
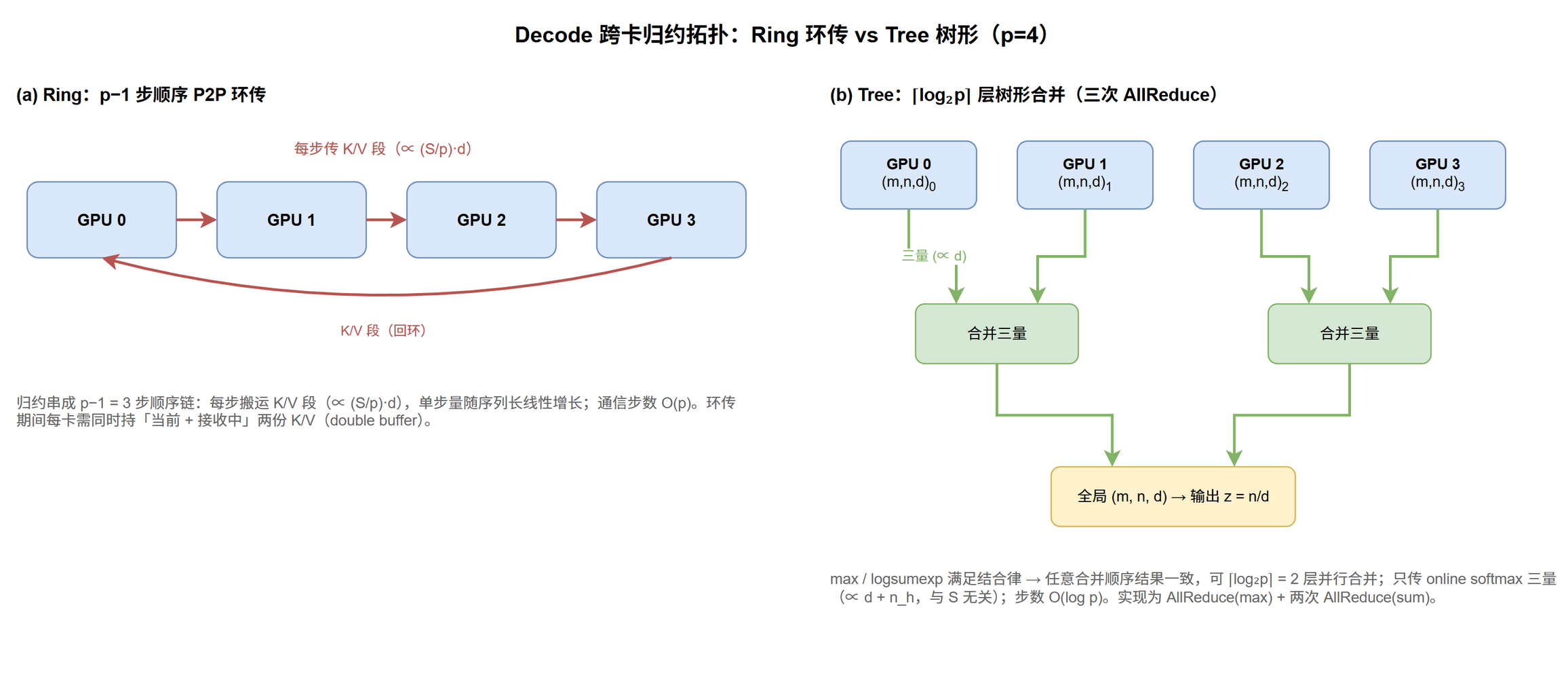
因为 online softmax 的三量合并满足结合律,归约顺序不影响结果,所以不必走 Ring 的线性环,可用树形拓扑并行合并[1]。
Ring Attention 让 K/V 顺序流过所有 rank,本质是把跨卡归约串成一条 $p$ 步的链(见 7.2 Ring Attention)。但这条链的串行不是 attention 语义要求的——它只是环传机制的副产物。
Tree Attention 的出发点是把 attention 写成一个能量函数 (energy function) 的梯度:
$$\begin{equation} F(\zeta) = \log \sum_{a=1}^{N} \exp\left(\mathbf{q} \cdot \mathbf{k}_a^\top + \zeta \cdot \mathbf{v}_a^\top\right), \qquad \text{Attn}(\mathbf{q}, K, V) = \left.\frac{\partial F}{\partial \zeta}\right|_{\zeta=0} \label{eq:par-cp-tree-energy} \end{equation}$$这把 attention 与 log-sum-exp 联系起来。关键性质是 max 与 log-sum-exp 都满足结合律:对任意两段 partition $A$、$B$,
$$\begin{equation} \operatorname{logsumexp}(A \cup B) = \log\left(e^{\ell_A} + e^{\ell_B}\right), \qquad \max(A \cup B) = \max(\max A, \max B) \label{eq:par-cp-tree-assoc} \end{equation}$$合并两段 partial attention 结果(各自的 max / numerator / denominator 三量)是一个结合律操作,合并顺序不影响最终输出。指数前减全局 max 的 safe softmax 不破坏结合律。结合律意味着归约可以任意树形并行:用 $p$ 个处理器对 $N$ 个元素做结合律归约,时间复杂度 $O(N/p + \log p)$,$p$ 维度上是对数而非线性。
落到 decode(单 query、跨卡 KV)上,算法是「本地算 + 三次 AllReduce」:
| 步骤 | 操作 |
|---|---|
| 1 | KV cache 分片到 $p$ 卡,每卡持本地 KV 段与 query $\mathbf{q}$ |
| 2 | 各卡用 FlashAttention 算本地 output $\mathbf{o}_i$ 与 log-sum-exp $\ell_i$ |
| 3 | AllReduce(max) 求全局 $m$ |
| 4 | 各卡算分子 $\mathbf{n}_i = \mathbf{o}_i \cdot e^{\ell_i - m}$、分母 $d_i = e^{\ell_i - m}$ |
| 5 | AllReduce(sum) 分别求 $\mathbf{n}_g$、$d_g$ |
| 6 | 输出 $\mathbf{z} = \mathbf{n}_g / d_g$ |
@tbl-par-cp-tree-algo Tree Attention 的 decode 归约六步(三次 AllReduce)
与 Ring 的对照:Ring 用 $p$ 次 P2P 把 KV 环传一圈,Tree 用三次 AllReduce 把三量树形归约。两者都是 exact,差别只在归约拓扑。
Tree 比 Ring 少传多少?通信量为什么与序列长无关?
Tree 每卡只传 online softmax 三量(尺寸正比于 hidden dim),与序列长度无关;Ring 每步传完整 K/V 段(正比于 $S/p \cdot d$),通常比 Tree 多两到三个数量级。
Ring 的总通信量随 $p$ 线性增长,每步搬运完整 K/V:
$$\begin{equation} V_{\text{ring}} = 2 b \cdot \frac{S}{p} \cdot d \cdot p = 2 b S d \label{eq:par-cp-tree-ring-vol} \end{equation}$$Tree 只搬运三量,尺寸与 $S$ 无关,仅与 hidden dim $d$ 和 head 数 $n_h$ 相关:
$$\begin{equation} V_{\text{tree}} = 2 \cdot \frac{p-1}{p} \cdot \left(b d + 2 b n_h\right) \label{eq:par-cp-tree-vol} \end{equation}$$差距量级:Llama 3.1-8B ($n_h = 32$, $d = 4096$),32K 序列切 8 卡时每卡持 $S/p = 4096$ token,Ring 单步搬运量约是 Tree 等效单步的 $\frac{(S/p) \cdot d}{d + 2 n_h} \approx 4000$ 倍(Ring 单步 $2(S/p)d$ 与 Tree 三量 $2(d+2n_h)$ 的系数 2 约掉)[1]。Tree 把跨卡通信量从「正比于序列长」压到「正比于 hidden dim」,这是它在长序列 decode 上拉开差距的根因。
通信步数同样有数量级差:
| 方案 | 通信步数 | 通信原语 | 单步/总量随序列长 |
|---|---|---|---|
| Ring Attention | $O(p)$ | P2P 环传 | 正比于 $S$ |
| Tree Attention | $O(\log p)$ | AllReduce 树形 | 与 $S$ 无关 |
@tbl-par-cp-tree-vs-ring-comm Tree 与 Ring 的通信复杂度对比
为什么峰值内存只要 Ring 的一半?
Ring 在通信期间必须同时持有「当前」和「接收中」两份 K/V 段,Tree 只接收三量小向量,省掉一份 K/V 的 double buffer。
两者峰值内存:
$$\begin{equation} \text{Mem}_{\text{ring}} = 4 b \frac{S}{p} d + 2 b d, \qquad \text{Mem}_{\text{tree}} = 2 b \frac{S}{p} d + 2 b d + 2 b n_h \label{eq:par-cp-tree-mem} \end{equation}$$Ring 的 $4 b (S/p) d$ 含两份 K/V(当前 + incoming),Tree 只有一份本地 K/V 加上三量($2 b n_h \ll b (S/p) d$)。只要序列长不短于 head 数(几乎恒成立),Tree 峰值内存约为 Ring 的一半[1]。
Tree decode 实测快多少?
Llama 3.1-8B / 8×H100 上 32K-64K 序列 decode 比 Ring 快 4×;128 GPU、5.12M token 的渐近场景接近 8×。论文在 bfloat16、10 次取均值下的实测[1]:
| 序列长度 | 8×H100 Tree (s) | 8×H100 Ring (s) | 加速 | 4×MI300x 加速 |
|---|---|---|---|---|
| 32K | 0.60 | 2.57 | 4× | 3× |
| 64K | 1.08 | 4.42 | 4× | 3× |
| 128K | 2.68 | 6.38 | 2× | 3× |
| 256K | 2.89 | 8.19 | 3× | 2× |
@tbl-par-cp-tree-bench Tree vs Ring decode 实测(Llama 3.1-8B,节点内互联)
表中 128K-256K 的加速比非单调(128K 为 2×、256K 回到 3×),源于 decode 实测的运行间方差(原文标准误达 ±0.6~1.1 s),非笔误。
两个边界数据点:
- 小规模也赢:2×RTX 4090(PCIe 互联)跑 Llama 3.2-1B,8K-32K 序列达 4×-5×,说明优势不依赖大集群。
- 大规模渐近:16 节点 × 8×H100(节点间 InfiniBand NDR 400 Gbps),5.12M token 序列接近 8×。注意「8×」是这个渐近点的测量,不是 Llama 3.1-8B 的实测值。
为什么收益集中在 decode? prefill 与训练为何不适用?
Tree Attention 的算法假设是「单 query、多 KV」,这正是 decode 形态;prefill 的 query 是全序列、训练要反向传播,都超出它的范围。
- decode 收益最大:decode 是内存带宽与跨卡通信瓶颈,计算量极少(单 token)。Ring 仍按序列长搬 K/V,Tree 只搬 $O(d)$ 三量,通信时间与序列长解耦,收益随序列长和卡数放大。
- prefill 不适用:prefill 的 query 长度等于全序列,是批 query 场景,Tree 的单 query 归约假设不成立,这一段仍用 Ring 或 Ulysses(见 7.3 DeepSpeed-Ulysses)。
- 训练不适用:论文不讨论反向传播,Tree 的设计只覆盖前向 decode。
这把 Tree Attention 定位为 7.4 Decode 阶段 CP 里 pass-Q 的同类竞品——都解 decode 跨卡 attention,但 pass-Q 仍是环传 query,Tree 改成三量树形归约。
Tree 对拓扑有什么要求和局限?
Tree 的核心原语是 AllReduce 而非 P2P,因此天然拓扑感知,但单卡场景无意义,且只覆盖 decode。
- 拓扑感知是主要优势:AllReduce 在「节点内 NVLink + 节点间 InfiniBand」两级网络上可分层实现(节点内 ring-reduce + 节点间 tree),NCCL 自动选最优策略。Ring 的 P2P 环传对带宽异构不敏感,跨节点时浪费低带宽链路[1]。
- 单卡无效:单 GPU 内 SM 经共享显存通信,不存在 P2P 语义,对数优势无从体现。
- 只覆盖 decode:prefill / 训练仍需 Ring / Ulysses,Tree 不是 CP 的通用替代,而是 decode 这一段的专用优化。
- 节点间带宽仍是绝对瓶颈:跨节点 InfiniBand(约 50 GB/s)远低于 NVLink(900 GB/s),但 Tree 通信量绝对值小,跨节点代价相对可控。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 归约拓扑 | 三量合并满足结合律,环传可改树形,步数 $O(\log p)$ |
| 通信量 | 只传 online softmax 三量,与序列长解耦,比 Ring 少约 3 个数量级 |
| 峰值内存 | 省掉 incoming K/V 的 double buffer,约为 Ring 一半 |
| 实测 | 8×H100/Llama3.1-8B decode 4×,128 卡 5.12M token 渐近 8× |
| 适用边界 | 仅 decode(单 query),prefill/训练仍用 Ring/Ulysses |
@tbl-par-cp-tree-takeaway Tree Attention 核心知识点
参考资料
- Zyphra, Tree Attention: Topology-aware Decoding for Long-Context Attention on GPU Clusters, arXiv:2408.04093, 2024. https://arxiv.org/abs/2408.04093
延伸阅读
- Zyphra 官方博客:Tree Attention. https://www.zyphra.com/post/tree-attention-topology-aware-decoding-for-long-context-attention-on-gpu-clusters
- GitHub 实现 (JAX + flash-attn-jax). https://github.com/Zyphra/tree_attention