异构 Attention 下的 CP
注意力变稀疏、压缩或局部后,CP 的通信量和协议怎么随之变化?
核心要点:
- CP 默认假设 attention 是 dense all-pairs,稀疏/压缩/局部下失效
- SWA 只在 rank 边界需小规模通信,通信量降 2-3 个数量级
- 压缩/稀疏 attention 用 AllGather 替代 ring
- 生产路线(先传后选)和论文路线(先选后传)在通信量、复杂度、内存三轴上互为 tradeoff
- DSA AllGather-CP 每卡全量回写:只摊计算不摊内存,是设计决策
- MoBA 块级稀疏节约消息启动次数而非带宽;有负载均衡盲点
- 线性注意力传 $[B,H,d,d]$ 状态而非 KV,通信与 $S$ 无关
- LASP-2H 混合论文未给跨层时序、生产框架未实装
- 不能用统一 ring attention 一招通吃
名词定义
| 名词 | 定义 |
|---|---|
| SWA (Sliding Window Attention) | 每 query 只看最近 $n_{\text{win}}$ 个 token 的局部注意力 |
| CSA (Compressed Sparse Attention) | 序列压缩(轻压缩比) + lightning indexer top-k 稀疏选择的注意力层;机制见 09-序列压缩注意力 与 08-动态稀疏选择 |
| HCA (Heavily Compressed Attention) | 序列压缩(重压缩比) + dense 访问的注意力层,无 top-k;机制见 09-序列压缩注意力 |
| C4 / C128 | V4 对 CSA/HCA 的具体配置代号——C4 = CSA 取压缩比 4×、C128 = HCA 取压缩比 128×;本篇凡涉 V4 实例标 "CSA(C4)" / "HCA(C128)" 桥接 |
| Overlap transform | CSA 用双流投影让相邻压缩 entry 共享同段 token,分布式下使源 token 可能落在邻 rank |
| Distributed top-k | 跨 rank 选全局 top-k 索引的集合通信,详见 4.13 Distributed Top-K |
| 先传后选 | AllGather 全量 KV 到本地后再做全局 top-k 选择(生产路线) |
| 先选后传 | 先完成分布式 top-k 选择,再 sparse gather 对应 KV(论文路线) |
@tbl-par-cp-het-glossary 本篇名词定义
CP / Ring Attention / Ulysses 等共享名词见 7.1 总览。各 attention 的算子机制(SWA / 稀疏 / 压缩 / 线性是什么、怎么算)见注意力机制实现卷 06-11 章,V4 特定配置见 07-前沿模型追踪 / DeepSeek-V4。本篇聚焦这些 attention 在 CP 下的通信视角——机制不重写、只讲分布式怎么切。
CP 的 dense all-pairs 假设在稀疏 attention 下还成立吗?
CP 的 Ring / Ulysses 设计假设 attention 是 dense all-pairs;注意力变稀疏、压缩、局部时,CP 通信模式必须分别处理。dense attention 下每 query 看全序列,所以要么 K/V 环传 (Ring) 要么 head 转置 (Ulysses)。一旦每 query 只看部分 KV,跨 rank 通信量随之下降一到几个数量级,但通信原语也从 ring 换成 AllGather 或稀疏 gather。
SWA 下 CP 通信为什么几乎为 0?
SWA 每 query 只看最近 $n_{\text{win}}$ 个 token,绝大多数 KV 在本地 rank,仅 rank 边界处需要一次小规模 P2P 通信。代表:Longformer[1]、Mistral 7B[2]、DeepSeek V4 SWA 层($n_{\text{win}}=128$)[3]。
边界通信的几何
CP 把序列切成 $N$ 段,每段 $S/N$ 个连续 token。rank $r$ 持有位置 $[r \cdot S/N,\; (r+1) \cdot S/N)$ 的 Q/K/V。对于 rank $r$ 左边界附近的 query(位置 $p \approx r \cdot S/N$),其窗口 $[p - n_{\text{win}} + 1,\; p]$ 延伸到前一个 rank $r-1$ 的右端:
![SWA 边界通信几何。CP 把序列切成 N 段,每段 S/N 个连续 token,rank r 持位置 r·S/N, (r+1)·S/N) 的 Q/K/V。rank r 左边界附近的 query,其窗口 [p−n_win+1, p] 往左延伸跨过 rank 边界,落入相邻 rank r−1 的最右端。因此该 query 仅需相邻 rank 最右侧 min(n_win, S/N) 个 token 的 KV,经一次 P2P 传入;只有靠近左边界的 min(n_win, S/N) 个 query 需要跨 rank,当 n_win ≪ S/N 时通信量与序列长无关。@fig-par-cp-het-swa-boundary
只有靠近左边界的 $\min(n_{\text{win}},\; S/N)$ 个 query 需要跨 rank 的 KV,且所需 KV 仅来自相邻 rank 的最右侧 $\min(n_{\text{win}},\; S/N)$ 个 token。
通信量公式
每 rank 从左邻居接收一次 P2P 通信:
$$\begin{equation} M_{\text{SWA}}^{\text{per-rank}} = \min(n_{\text{win}},\; S/N) \cdot 2 d_{\text{kv}} \cdot s_{\text{dtype}} \label{eq:par-cp-het-swa-comm} \end{equation}$$- $d_{\text{kv}}$:每 token 的 K+V 表示维度(GQA 下为 $n_{\text{kv\_heads}} \cdot d_{\text{head}}$,MLA 下为 $d_c$)
- 系数 2 为 K + V
- 当 $n_{\text{win}} \ll S/N$(通常成立),通信量仅取决于窗口大小,与序列长无关
对比 dense ring 通信($\href{/interconnect/LLM并行通信/上下文并行/ring-attention}{\text{(7.2)}}$ 给出 $\approx S \cdot 2d \cdot s$),SWA 的通信比值:
$$\begin{equation} \frac{M_{\text{SWA}}}{M_{\text{ring}}} \approx \frac{n_{\text{win}}}{S} \ll 1 \label{eq:par-cp-het-swa-ratio} \end{equation}$$数值示例(Mistral-7B, $n_{\text{win}}=4096$, $S=128\text{K}$, $N=4$, $d_{\text{kv}}=1024$, BF16):
| 模式 | 每 rank 通信量 | 占 dense ring 比例 |
|---|---|---|
| Dense ring | 2.0 GB | 100% |
| SWA ($n_{\text{win}}=4096$) | 16 MB | 0.8% |
| SWA ($n_{\text{win}}=128$, V4) | 0.5 MB | 0.025% |
@tbl-par-cp-het-swa-example SWA 通信量 vs Dense Ring(Mistral-7B 参数, S=128K, N=4)
SWA 下 CP 通信近似为零的结论不是近似——它在定量上比 dense ring 小 2-3 个数量级。
DeepSeek V4 为什么用 round-robin token 分片而非 ring/Ulysses?
DeepSeek V4 (2026-04) 的 CP 不是 Ring 也不是 Ulysses,而是与 CSA(C4) / HCA(C128) / SWA 混合注意力深度耦合的 round-robin token 分片[3]。
V4 的三类注意力层
每一层运行 SWA($n_{\text{win}}=128$ 的局部注意力)加上 CSA 或 HCA 其中之一[3]。CSA 与 HCA 的算子机制(compressor 双流 / overlap transform / softmax 加权)见 09-序列压缩注意力,indexer + top-k 机制见 08-动态稀疏选择;本节只关心 CP 视角。
| 层类型 | 压缩比 | overlap transform | 主注意力访问模式 | CP 需 AllGather? |
|---|---|---|---|---|
| CSA(C4) + SWA | 4× | 有 | 稀疏 top-512(lightning indexer 选) | 是 |
| HCA(C128) + SWA | 128× | 无 | dense(所有 compressed entry) | 否 |
@tbl-par-cp-het-dsv4-layers V4 三类注意力层在 CP 下的差异
Round-Robin token 分配
CP 按 token 轮询分配:rank $r$ 持有 token $\{i \mid i \bmod N_{\text{CP}} = r\}$。每 rank 拥有序列 $1/N_{\text{CP}}$ 的 token 及其 per-token 元数据(page 索引、top-k 长度等),本地重索引;compressor 输出写回时保持全局索引,KV 连续存储[3]。
CSA(C4) 层为什么需要 AllGather
两个原因叠加,驱动同一次 AllGather:
- overlap transform 跨 rank 边界:CSA 的相邻压缩 entry 共享同段 token(双流 $C^a/C^b$,见 09)。round-robin 分片后,$C^b$ 流回看的源 token 可能落在另一个 CP rank。
- Indexer top-k 需要全局视野:lightning indexer 要从所有 compressed position 中选全局 top-512,每 rank 只持有 $1/N_{\text{CP}}$ 的 compressed token,必须收集全量才能正确选择(top-k 的全局排序属性见 08)。
两个需求折合成单次 AllGather:全量 compressed tensor 跨 CP group 聚合[3]。
HCA(C128) 层为什么可以跳过 AllGather
HCA 无 overlap transform,且采用 dense 访问(所有 compressed entry 都参与 attention)——每 rank 只需本地的 compressed token,无跨 rank 需求。$S=128\text{K}$、$m'=128$ 下每 rank 持有 $\frac{S}{N \cdot m'}$ 个 compressed entry($N=4$ 时即 256 个),足够本地完成 dense attention[3]。
CP 通信量
CSA(C4) 层 AllGather per-rank 接收量(MLA $d_c = 512$, BF16):
$$\begin{equation} M_{\text{CSA}}^{\text{per-rank}} = \frac{N-1}{N} \cdot \frac{S}{4} \cdot 2 d_c \cdot s_{\text{dtype}} \label{eq:par-cp-het-csa-comm} \end{equation}$$$S = 1\text{M}$、$N=4$ 时:$3/4 \times 256\text{K} \times 2 \times 512 \times 2 \approx 384\text{ MB}$ per rank。
HCA(C128) 层:0(纯本地计算)。SWA 层:参考公式 $\eqref{eq:par-cp-het-swa-comm}$,$n_{\text{win}}=128$ → 约 0.25 MB,可忽略。
与 TP/EP 交互
- TP + MLA:FlashMLA head 数约束通过 SGLang padding 方案解决
- EP:DeepEP all-to-all 通信,与 CP 正交
- CP:仅用于 prefill——V4 的压缩使 decode 阶段有效 KV 体量极小(HCA 对 1M 序列约 $S/m'=8\text{K}$ entry,$d_c=512$、BF16 下约 8 MB),A100/H100 单卡可装,decode 靠本地完成
DSA 模型在 CP 下为什么走 AllGather 全量 KV 而非 ring?
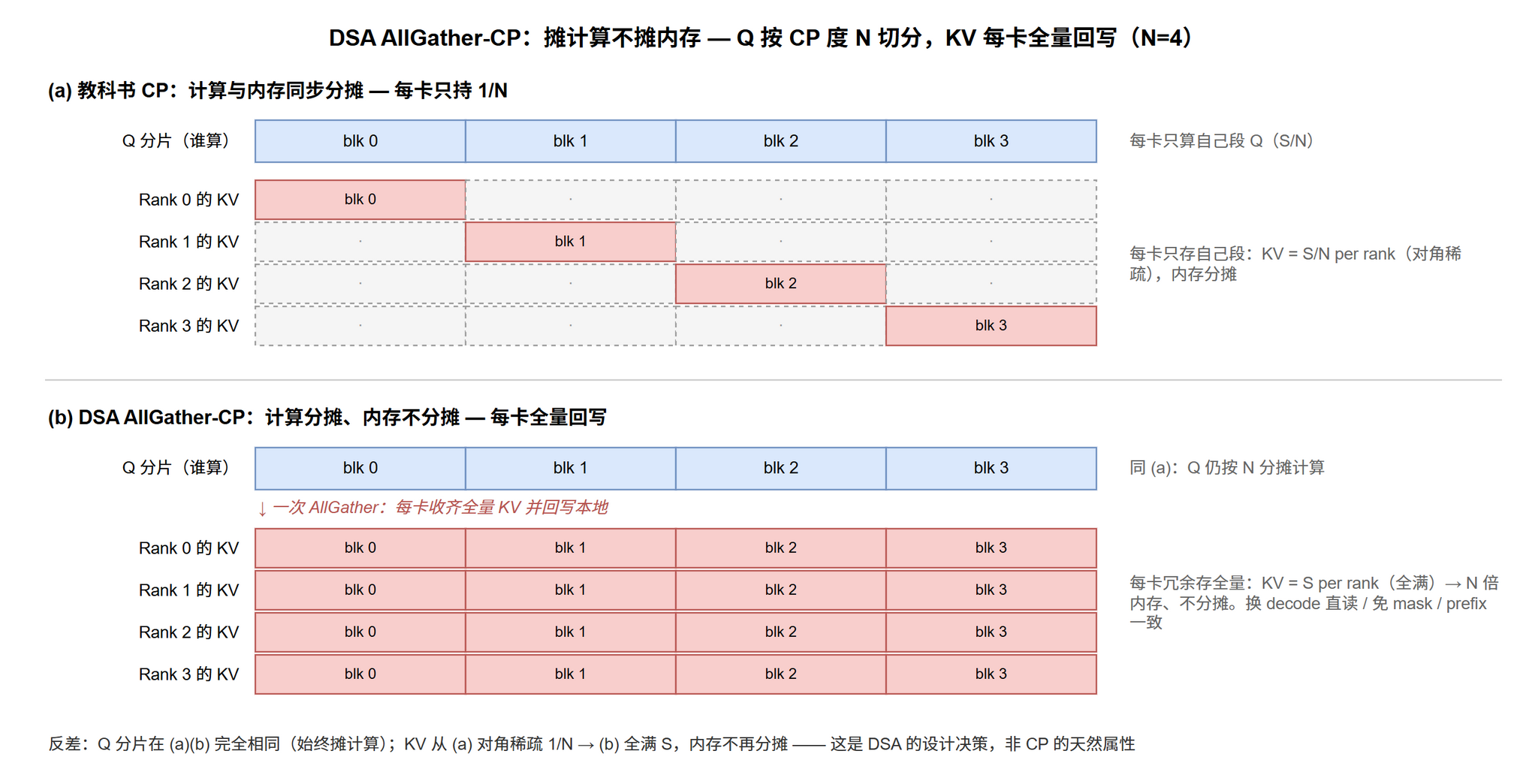
DSA (DeepSeek Sparse Attention) 模型的生产 CP 走第三条路线:zigzag 切 Q + 一次性 AllGather 全量 KV + 每卡全量回写,既不是 ring 也不是 Ulysses。SGLang 为 DeepSeek-V3.2 与 GLM-5 落地的 prefill CP(cp_utils.py)是公开实现[4][5]。
DSA 由 lightning indexer(轻量 FP8 scorer,对全量前缀 key 算相关性分数选 top-$k=2048$,计算量 $O(S^2)$ 但常数极小)与稀疏主注意力(在 indexer 选出的 $k$ 个位置上做 attention,复杂度 $O(S \cdot k)$)两个子模块组成;算子机制见 08-动态稀疏选择[6]。
为什么 ring attention 在 DSA 下结构性失效
两个原因叠加,缺一不可逆:
- indexer 需要全局视野:top-$k$ 是对全量前缀 key 的全局排序,ring 每步只持有 $1/N$ 的 KV 分片,无法在环传中间步骤产出全局 top-$k$;且 indexer 的 top-$k$ mask 需要聚合所有 head 的分数,也不能按 head 切[4]
- overlap 前提坍塌:ring 的设计前提是 $O(S^2)$ 的 dense attention 计算窗口足以掩盖 K/V 环传(见 7.2 Ring Attention 的 overlap 条件);主注意力稀疏化为 $O(S \cdot k)$ 后计算窗口大幅变薄,环传通信无处可藏
SGLang 实现:两种切分模式
SGLang 通过 --dsa-prefill-cp-mode 提供两种切分模式[4]:
| 模式 | Token 分配 | 支持多 batch | 兼容 Fused MoE / FP8 KV | 约束 |
|---|---|---|---|---|
in-seq-split (zigzag) | 序列分 $2N$ block,rank $r$ 持 block $r$ 与 block $2N{-}1{-}r$ | 否(batch=1) | 否 | 需 DP attention |
round-robin-split (默认) | token $i$ 归 rank $(i \bmod N)$ | 是 | 是 | $S \bmod N = 0$ |
@tbl-par-cp-het-sglang-modes SGLang DSA prefill CP 的两种切分模式
Per-Layer 通信流程(in-seq-split / zigzag)
各步关键细节:
- ① 序列切分:序列分 2N block,rank $r$ 持 block $r$(prev)+ block $2N{-}1{-}r$(next),每 rank 持 $S/N$ 个 token 的 Q
- ③ AllGather KV:一次集合通信拿到全量 $S$ 个 token 的 KV,按
cp_reverse_index排列恢复自然顺序 - ④ 全量回写:rerange 后写入本地 token-to-KV pool,每卡持全量有序 KV → decode 时零通信
- ⑤ Indexer:每 rank 用本地 Q 分片($S/N$)对全量 K 做 scoring,zigzag 下 prev/next 两段 Q 各跑一次 FlashAttention
- ⑥ 稀疏主 attention:prev 段 KV context = blocks $0..r$;next 段 = blocks $0..2N{-}r{-}1$
- ⑦ AllGather hidden states:每 rank 输出 $S/N$ 维 → AllGather → rerange 恢复全量
与 ring / Ulysses 的关键差异
| 维度 | Ring Attention | DSA AllGather-CP |
|---|---|---|
| KV 通信 | $N-1$ 步 P2P 环传 | 一次 AllGather 集合通信 |
| 跨块合并 | online softmax 增量合并 | 不需要——全量 KV 在手一次算完 |
| 每卡 KV 存储 | $S/N$ 分片(分布式) | 全量回写(每卡冗余存 $S$ 个 token) |
| 通信-计算重叠 | K/V 环传 × 本地 attention 天然重叠 | AllGather 必须先于 attention 完成,不可与 attention 重叠 |
| zigzag 的角色 | 配平环传中各 rank 的 causal 负载 | 仅配平 Q 切分的 causal 负载(K 反正全量) |
@tbl-par-cp-het-dsa-vs-ring DSA AllGather-CP 与 Ring Attention 的机制对比
「每卡全量 KV」是设计决策,不是 CP 的天然属性
CP 教科书式的收益是「KV 按 $N$ 分摊」,但 DSA AllGather-CP 刻意放弃这一项:AllGather 后不丢弃全量 KV,而是回写本地 cache。代价是每卡 KV 内存为 $N$ 倍冗余($N$ 卡各存 $S$ 个 token 的完整 KV);换来三点:
- 省重复通信:后续 chunked prefill / decode 直接读本地全量 cache,不必每次重做 AllGather
- 免外部 mask:cache 按自然顺序存储,算子内部用 position id 即可判断因果
- prefix cache 友好:全量有序 cache 与单卡语义一致,前缀命中逻辑不变
即 DSA AllGather-CP 只分摊计算(indexer scoring 与稀疏 attention 各按 $S/N_{\text{CP}}$ 切 Q),不分摊 KV 内存——容量压力靠 MLA 压缩($d_c=512$ 把 per-token KV 从 GQA 的几 KB 压到 1-2 KB)与 PP 切层共同承担。SGLang 的 CP roadmap 中「sharded KV cache between CP ranks」仍是开放方向,探索按层/按序列维/按扁平化维度分片[7]。
通信量
Per-layer per-rank 接收量(MLA, $d_c = 512$, BF16, in-seq-split):
$$\begin{equation} M_{\text{DSA}}^{\text{per-layer}} = \frac{N-1}{N} \cdot S \cdot (2 d_c + d_{\text{model}}) \cdot s_{\text{dtype}} \label{eq:par-cp-het-dsa-comm} \end{equation}$$- $2 d_c$:K + V latent 的 AllGather
- $d_{\text{model}}$:hidden state 的 AllGather(用于 MoE/FFN 层输入)
- $S = 64\text{K}$, $N = 4$, $d_c = 512$, $d_{\text{model}} = 7168$:$(3/4) \times 65536 \times 8192 \times 2 \approx 768\text{ MB/layer}$
稀疏化把计算瓶颈移向 indexer
主注意力从 $O(S^2)$ 降到 $O(S \cdot k)$ 后,indexer 的 $O(S^2)$ 全量扫描(尽管常数小)成为长序列下增长最快的项,这正是 CP 切分收益最大的部分。SGLang 的 TTFT 实测(8×H20, round-robin)显示 CP 使 1K-64K prefill 延迟下降 9-32%[5]。
稀疏 attention CP 为什么有"先选后传"和"先传后选"两条对立路线?
同一个问题(跨 rank 做全局 top-k 选择 + 拉取对应 KV)有两条对立的工程路线,在通信量、实现复杂度、内存三轴上互为 tradeoff。
先传后选(AllGather-then-Select)——生产路线
SGLang/V3.2/GLM-5 采用:
- 通信量:$S \cdot 2 d_c \cdot s$(全量 KV latent),与稀疏度无关
- 优势:一次 AllGather + 纯本地计算,无分布式协调;top-k 结果精确(看到全量 K)
- 劣势:通信量等同于 dense CP(未利用稀疏性减通信);每卡存全量 KV($N$ 倍冗余)
先选后传(Select-then-Gather)——论文路线
- 通信量:merge 阶段 $N \cdot k \cdot (\text{index} + \text{score}) \approx$ 几十 KB(可忽略)+ 稀疏 KV gather $k \cdot 2 d_c \cdot s$
- 优势:通信量仅 $O(k)$,不随 $S$ 增长;KV 分布式存储,内存 $S/N$ per rank
- 劣势:local top-k 在 partial keys 上计算 → 不保证找到全局最优 top-k(indexer 需全量 K 才能正确排序);需要分布式 top-k 协议,实现复杂;decode 阶段每次重做
为什么生产选了通信量更大的路线
核心矛盾:DSA indexer 的 scoring 必须看全量 K 才能产出正确的全局 top-k[4]。这使得「先选」不可能在精确语义下完成——local scoring on partial keys 给出的 top-k 与 global scoring on full keys 的结果不同。
如果接受近似(如 locality-sensitive hashing 或 block-level gating),可以走「先选后传」,但会牺牲注意力质量。生产系统选择精确性 > 通信效率。
Tradeoff 总览
| 决策轴 | 先传后选(生产) | 先选后传(论文) |
|---|---|---|
| Per-layer KV 通信 | $O(S \cdot d_c)$(全量) | $O(k \cdot d_c)$(稀疏,$k \ll S$) |
| Top-k 精确性 | 精确(全量 K 可见) | 近似(partial keys) |
| 实现复杂度 | 低(1× AllGather + 本地计算) | 高(分布式 top-k 协议 + sparse gather) |
| 每卡 KV 内存 | $S$ tokens($N$ 倍冗余) | $S/N$ tokens(分布式) |
| Decode 通信 | 0(全量已本地) | 每次 decode 需 sparse gather |
| 适用条件 | MLA 压缩使 $d_c$ 小 → 全量通信可接受 | dense KV($d_c$ 大)时通信节省显著 |
@tbl-par-cp-het-tradeoff 先传后选 vs 先选后传的 tradeoff
选择时机:当 MLA 将 $d_c$ 压到 512(V3 系列),全量 AllGather 成本控制在 256 MB / layer 量级($S=128\text{K}$、$N=4$、BF16),换来实现简单 + decode 零通信。若模型用标准 GQA($d_{\text{kv}} \approx 4096$),全量 AllGather 膨胀到约 2 GB / layer,先选后传的通信优势(缩到几 MB)才值得承担分布式 top-k 协议复杂度。
HCA 模式下 AllGather 与 local dense 的通信量差多少?
HCA 的 compressed entry 总数已经远小于原序列,若选择 AllGather 比 ring 旋转便宜,但 V4 进一步选择跳过 AllGather 让每 rank 直接 local dense。这一节算 AllGather 通信量上界,对比"完全跳过"路径的零成本。
以 $m'=128$、$S=128\text{K}$、$N=4$ 为例:
- 每 rank 持 $S/N$ 个 token → compressor 产出 $S/(N \cdot m') = 256$ 个 compressed entry
- 若 AllGather:各 rank 贡献 256 entries → 每 rank 拿到全量 $S/m' = 1024$ entries,做标准 attention,复杂度 $O(S/N \times S/m')$,比 dense $O(S/N \times S)$ 小 $m'$ 倍
- V4 实际路径:直接 local dense,每 rank 用本地 256 entries 做 attention,零跨 rank 通信
AllGather 通信量上界(HCA dense 模式可选):
$$\begin{equation} M_{\text{HCA}}^{\text{per-rank}} = \frac{N-1}{N} \cdot \frac{S}{m'} \cdot 2 d_c \cdot s_{\text{dtype}} \label{eq:par-cp-het-hca-comm} \end{equation}$$$S=128\text{K}$、$m'=128$、$N=4$、$d_c=512$、BF16:$(3/4) \times 1024 \times 1024 \times 2 = 1.5\text{ MB}$ per rank。与 dense ring 的 2 GB 相比,压缩 128× 后通信量降 1000×——这个降幅让 "AllGather 是否还值得做" 成为可选项,V4 选择更激进的"完全跳过",把跨 rank 通信压到 0。
MoBA 块级稀疏在 CP 下怎么编排?
MoBA 把选择粒度从 token 放粗到块,对应的 CP 路径是「块亲和分 AllGather + 稀疏块 gather」两阶段——粒度变粗主要节约启动开销,带宽节约要看稀疏率[9]。MoBA 算子机制(mean-pool gating、块选择数学)见 08-动态稀疏选择,本节只讲 CP 通信编排。
论文原文是否给出 CP?
MoBA 原论文未涉及 sequence/context parallel,仅讨论 head-level tensor parallel(按头切的 KV 广播)[9]。本节描述的两阶段编排是从通用 block-sparse CP 模式推断;2025 年的 MTraining 工作首次正式处理 MoBA 在 CP 下的负载均衡问题,提出 balanced sparse ring attention[10]。生产框架(SGLang / vLLM / Megatron)尚无 MoBA CP 公开实装。
阶段 1:块亲和分 AllGather
MoBA 的 gating 是每 query 对全部 $n/B$ 个块算亲和分(与块内 key 均值的内积),分布式下必须先聚合全局 block centroids。两步走:
- 各 rank 对本地 KV 分片内每个块算 mean-pool centroid(维度 $d_{\text{kv}}$)
- AllGather 所有 rank 的 centroid,每 rank 拿到全量 $n/B$ 个 centroid,本地算 affinity → 全局 top-$k_{\text{block}}$ 选块
centroid AllGather 通信量:
$$\begin{equation} M_{\text{MoBA-gate}}^{\text{per-rank}} = \frac{N-1}{N} \cdot \frac{S}{B} \cdot d_{\text{kv}} \cdot s_{\text{dtype}} \label{eq:par-cp-het-moba-gate} \end{equation}$$$S=128\text{K}$、$B=512$、$d_{\text{kv}}=1024$、BF16、$N=4$:$(3/4) \times 256 \times 1024 \times 2 \approx 0.4 \text{ MB}$。比 lightning indexer 的全量 K AllGather 小 $B$ 倍——这是 MoBA 选择粒度粗的第一个收益(gating 视野的聚合便宜)。
阶段 2:稀疏块 gather
选中 $k_{\text{block}}$ 个块的 KV 跨 rank 拉到 query rank,块连续使 gather 是 contiguous read 而非散列 scatter:
$$\begin{equation} M_{\text{MoBA-kv}}^{\text{per-rank}} = k_{\text{block}} \cdot B \cdot 2 d_{\text{kv}} \cdot s_{\text{dtype}} \label{eq:par-cp-het-moba-kv} \end{equation}$$$S=128\text{K}$、$B=512$、$k_{\text{block}}=8$(4096 token 等效稀疏率 3%)、$d_{\text{kv}}=1024$、BF16:$8 \times 512 \times 2 \times 1024 \times 2 \approx 16 \text{ MB}$ per rank。
与 token-level 稀疏的实质差异
等价稀疏率下(token 数相同),块级与 token 级总带宽相同;块级真正节约的是消息启动次数:
| 维度 | Token-level 稀疏 gather(NSA / V4 CSA) | Block-level 稀疏 gather(MoBA) |
|---|---|---|
| 启动次数 | $k_{\text{token}}$(每 token 一次散列读) | $k_{\text{block}}$(= $k_{\text{token}}/B$,少 $B$ 倍) |
| 总带宽 | $k_{\text{token}} \cdot 2 d_{\text{kv}} \cdot s$ | $k_{\text{block}} \cdot B \cdot 2 d_{\text{kv}} \cdot s$(等价稀疏率下与左列相同) |
| 内存访问 | 散列 scatter | 连续段 contiguous read,FlashAttention tile 可复用 |
| 表达力代价 | 单 token 可精选 | 块内 token 全入选或全丢弃,含块内冗余 |
@tbl-par-cp-het-moba-vs-token MoBA 块级与 token 级稀疏 gather 的 CP 对比
短消息启动成本主导小 message size 通信(NCCL 启动开销约几十微秒、对 64-512 token 的 KV 块不可忽略),块级的少 $B$ 倍启动正是 MoBA 在分布式下值得粗化粒度的核心理由[10]。
负载均衡盲点
MoBA + zigzag ring 在 CP 下存在 worker-level 不均衡:选中的块按全局 top-$k$ 分布不均,某些 rank 持有的本地块被选中频次远高于其他 rank,gather 阶段产生热点[10]。MTraining 提出 balanced sparse ring 通过工作单元重排在 worker 间打平负载——这是 MoBA 在生产 CP 部署的已知开放问题。
线性注意力 / SSM 的 CP 为什么传状态而非 KV?
线性注意力和 SSM 把序列写成固定大小的前缀状态递推,CP 只需在 chunk 边界传一个 $d \times d$ 状态矩阵,通信量与序列长无关——这是代数结构上的根本区别,不是工程优化。算子属性(核函数 + 右积优先把序列压成状态矩阵 $M_s \in \mathbb{R}^{d \times d}$)见 11-线性注意力与SSM,本节只讲 CP 通信编排。
LASP-1 → LASP-2:环传压成一次 AllGather
LASP-1 用 ring P2P 顺序传状态,前向需 $W-1$ 轮串行等待[11]。状态矩阵虽小,但环上串行依赖让长序列、多 rank 时累积延迟显著。
LASP-2 利用「右积优先」让各 rank 独立算本地状态增量 $M_t = K_t^\top V_t$(chunk 内完全本地、无通信),再用整层 1 次 AllGather 同步所有 rank 的 $M_t$[12]。AllGather 后每 rank 本地做前缀累加 $M_{1:t-1} = \sum_{i<t} M_i$(纯本地,无通信),最终输出:
$$\begin{equation} O_t = Q_t \cdot M_{1:t-1} + \text{IntraChunkAttn}(Q_t, K_t, V_t) \label{eq:par-cp-het-lasp2-out} \end{equation}$$跨 chunk 历史走聚合后的 $M_{1:t-1}$,chunk 内走标准 attention。AllGather 可与 intra-chunk 计算 overlap。
状态张量与通信量
LASP-2 的 AllGather 张量形状为 $[B, H, d, d]$(batch / 头数 / 头维 / 头维)[13],per-rank 发送量:
$$\begin{equation} M_{\text{LASP2}}^{\text{per-rank-per-layer}} = \frac{N-1}{N} \cdot B \cdot H \cdot d^2 \cdot s_{\text{dtype}} \label{eq:par-cp-het-lasp2-comm} \end{equation}$$$B=1$、$H=32$、$d=128$、BF16、$N=4$:$(3/4) \times 32 \times 128^2 \times 2 \approx 0.75 \text{ MB/layer}$,与序列长 $S$ 完全无关。2048K 序列、64 GPU 实测 LASP-2 比 LASP-1 快 15.2%、比 Ring Attention 快 36.6%[12]。
反向 backward 同样 1 次 AllGather(对梯度),整迭代共 2 次集合通信[12]。
LASP-2H:与标准 softmax 注意力混合
LASP-2H 处理混合架构(部分层线性、部分层 softmax),关键设计是 softmax 层不走 ring,而是直接 AllGather 全量 KV[12]——和 DSA 的「先传后选」(见前文)同思路:
| 层类型 | 通信原语 | per-rank 通信量 |
|---|---|---|
| 线性注意力层 | AllGather 状态 $[B,H,d,d]$ | $O(BHd^2)$ |
| Softmax 注意力层 | AllGather 全量 K/V | $O(S \cdot d_{\text{kv}})$ |
@tbl-par-cp-het-lasp2h LASP-2H 混合层在 CP 下的通信原语统一
两类层共用同一 AllGather 接口便于框架统一,但论文未给出跨层时序图、也未明确两类 AllGather 是否 overlap[12]。
生产框架实装现状
LASP-2/LASP-2H 仅在研究代码库 OpenSparseLLMs/Linear-MoE 发布[13],SGLang / vLLM / Megatron-LM 等生产框架均无集成。原始 OpenNLPLab/LASP 仓库未更新到 LASP-2。这是混合架构 CP 落地的开放方向,不是已验证的生产路径。
与 Mamba/SSM 的关系
SSM 的状态更新 $h_t = \bar A h_{t-1} + \bar B x_t$ 也是固定大小前缀递推,CP 同样在 chunk 边界传隐藏状态。Mamba-2 的 SSD 框架(见 11)证明 SSM 与结构掩码注意力对偶,线性注意力是其特例——因此 LASP-2 的 chunk + AllGather 范式可直接迁移到 SSM 的序列并行[14]。Mamba 自身的 parallel scan 是单 device 内的并行化(chunk 内 $O(\log L)$ 深度),跨 device CP 仍走 LASP-2 同款的传状态路径。
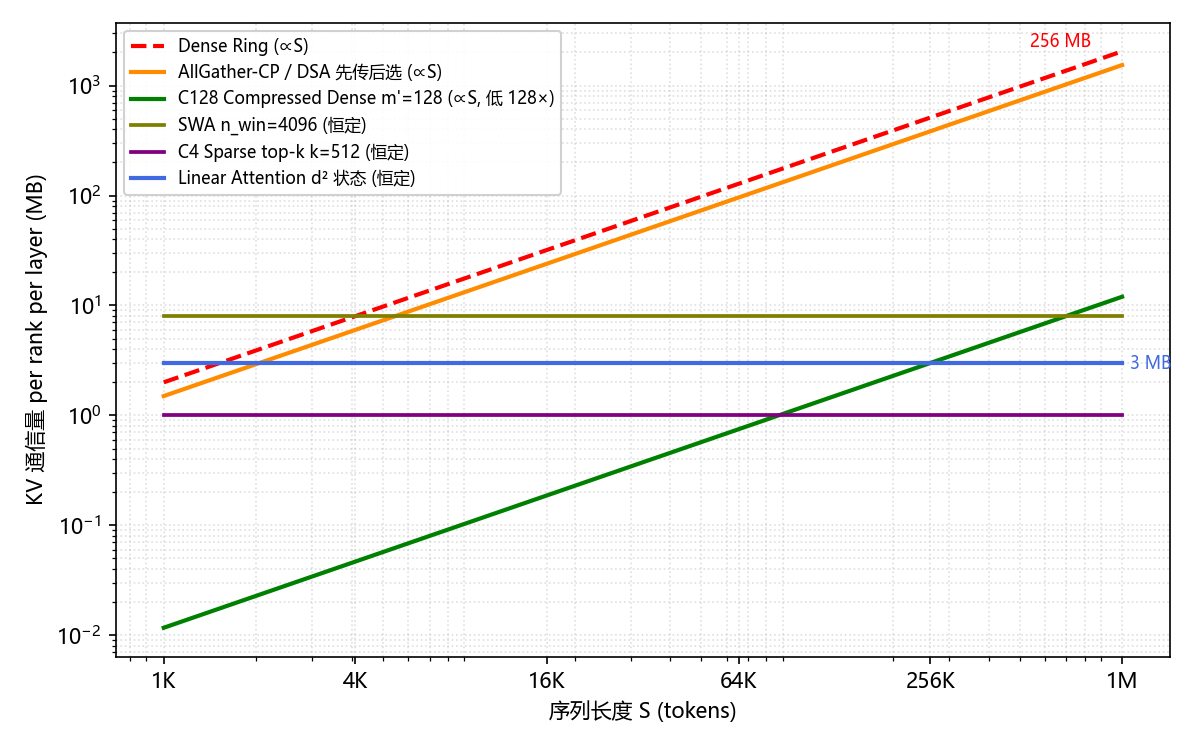
定量对比:各模式通信量实测量级
统一参数:$S = 128\text{K}$ tokens, $N = 4$ CP ranks, MLA $d_c = 512$, $d_{\text{model}} = 7168$, $n_h = 128$ heads, $d_{\text{head}} = 128$, $B_{\text{batch}} = 1$, BF16 (2B)。
口径声明(summary 表为 order-of-magnitude 对比):
- 所有行统一用 MLA $d_c=512$ 算 $c_{\text{kv}}$(与 V3/V4 系列一致),SWA 行也按 MLA 算——与前文 §SWA 节 Mistral-7B 实例(GQA $d_{\text{kv}}=1024$)参数不同、数值不可直接对比,前文公式以各节为准
- AllGather 类(HCA / DSA / MoBA-gate)的 $(N-1)/N$ 系数已折入数值但未写在公式列里,故 summary 数值与正文公式(如 $\eqref{eq:par-cp-het-hca-comm}$)对齐
- LASP-2 的 $H$ 在 summary 中取 $H = n_h = 128$;前文 §线性节示例用 $H=32$ 是一种较小模型的代入,两套数值同公式不同 $H$,summary 取统一参数
| Attention 模式 | 通信公式 | 数值 (per rank per layer) | 占 dense ring 比例 |
|---|---|---|---|
| Dense ring | $S \cdot c_{\text{kv}}$(per-rank 总传输量) | 256 MB | 100% |
| AllGather-CP (DSA 先传后选) | $\frac{N-1}{N} \cdot S \cdot c_{\text{kv}}$ + $\frac{N-1}{N} \cdot S \cdot d_{\text{model}} \cdot s$ (hidden) | 192 MB (KV) + 1344 MB (hidden) | 75% (KV) |
| SWA ($n_{\text{win}}=4096$) | $n_{\text{win}} \cdot c_{\text{kv}}$ | 8 MB | 3.1% |
| SWA ($n_{\text{win}}=128$, V4) | $n_{\text{win}} \cdot c_{\text{kv}}$ | 256 KB | 0.1% |
| HCA(C128) compressed dense ($m'=128$) | $\frac{N-1}{N} \cdot (S/m') \cdot c_{\text{kv}}$ | 1.5 MB | 0.6% |
| CSA(C4) sparse 先选后传 ($k=512$) | $k \cdot c_{\text{kv}}$ | 1 MB | 0.4% |
| DSA sparse 先选后传 ($k=2048$) | $k \cdot c_{\text{kv}}$ | 4 MB | 1.6% |
| MoBA block sparse ($B=512$, $k_{\text{block}}=8$) | $k_{\text{block}} \cdot B \cdot c_{\text{kv}}$ + $\frac{N-1}{N} \cdot (S/B) \cdot d_{\text{kv}} \cdot s$ | 8 MB + ~0.4 MB | 3.2% |
| Linear attention 状态 (LASP-2, $H=n_h=128$) | $\frac{N-1}{N} \cdot B_{\text{batch}} \cdot H \cdot d_{\text{head}}^2 \cdot s$ | 3 MB (固定) | 1.2% |
@tbl-par-cp-het-quant 统一参数下各 CP 模式通信量定量对比(口径声明见上)
关键观察:
- 所有非 dense 模式的 KV 通信都在 1-8 MB/layer 量级——比 dense ring 的 256 MB 小 30-250×
- SWA/compressed/sparse 之间量级相近(都是 MB 级),差异在通信模式(P2P vs AllGather vs sparse gather)
- 线性注意力 LASP-2 通信量固定约 3 MB(统一参数下含 $(N-1)/N$ 系数),不随 $S$ 增长——$S$ 从 128K 到 1M 都是同一量级
- MoBA 的两阶段通信中,centroid AllGather 小到几乎可忽略(~0.4 MB),主要带宽在选中块的 KV gather;与 token-level 稀疏带宽量级相当,节约的是消息启动次数
- DSA「先传后选」的 KV 通信量等于 dense ring(未利用稀疏性),额外还有 hidden state AllGather;其收益在于计算切分,不在于通信节省
- 通信量降幅 ≠ CP 价值:DSA AllGather-CP 的 KV 通信几乎等同 dense ring,CP 价值不在通信节省而在 indexer 与稀疏 attention 的计算切分。读 summary 表不能只看 "MB 数字" 判断哪种 CP 更优
- 稀疏化让 CP 的受益结构转变:从 dense 时代的"分摊 KV 通信",转为稀疏时代的"分摊 attention 计算"——KV 内存常常不分摊(DSA 每卡全量回写、MoBA 选中块跨 rank gather),容量压力被推回给 MLA 压缩与 PP 切层
异构 attention 的 CP 通信模式总览
| Attention 类型 | 代表工作 | CP 通信原语 | 通信量量级 |
|---|---|---|---|
| Dense full attention | 经典 Transformer | Ring K/V | $O(S \cdot d)$ per rank |
| SWA | Longformer / Mistral / V4 SWA | 边界 P2P(仅左邻居) | $O(n_{\text{win}} \cdot d)$ |
| Compressed dense | V4 HCA(C128) 层 | AllGather compressed KV(或跳过走 local) | $O((S/m') \cdot d)$ |
| Sparse top-k(先选后传) | NSA / V4 CSA(C4) 层 / MoBA | Distributed top-k + 稀疏 AllGather | $O(k \cdot d)$ |
| Sparse top-k(先传后选) | DeepSeek-V3.2 / GLM-5 DSA | AllGather 全量 KV + 本地 top-k + 全量回写 | $O(S \cdot d)$ per rank |
| Block-level sparse | MoBA | Gating + 块级稀疏 AllGather | $O(k_{\text{block}} \cdot B \cdot d)$ |
| Linear attention / SSM | LASP-2 / Mamba | AllGather 状态矩阵 | $O(d^2)$ 与 $S$ 无关 |
@tbl-par-cp-het-modes 异构 attention 下 CP 的通信模式
Takeaway
| 知识点 | 核心结论 |
|---|---|
| dense 假设 | Ring/Ulysses 假设 dense all-pairs,稀疏下失效 |
| SWA | 仅边界 P2P,通信 $\sim n_{\text{win}} \cdot d$,比 dense 小 2-3 个数量级 |
| V4 混合注意力 | CSA(C4) 需 AllGather(overlap transform + indexer 全局 top-k);HCA(C128) 零通信 |
| 压缩 dense | AllGather compressed KV,通信降 $m'$ 倍 |
| 稀疏 top-k | 生产路线先传后选(精确、简单、内存冗余);论文路线先选后传(通信省但近似) |
| DSA AllGather-CP | indexer 全局视野排除 ring;每卡全量回写——只摊计算不摊内存,是设计决策 |
| MoBA 块级 | 两阶段(centroid AllGather + 块 gather),节约启动开销而非带宽;有负载均衡盲点 |
| 动态 CP 调度 | per-request CP 度 + MoE/KV 解耦(NanoCP),详见 09-推理部署模式 |
| 线性注意力 LASP-2 | 传 $[B,H,d,d]$ 状态而非 K/V,整层 1 次 AllGather,通信量与序列长无关 |
| LASP-2H 混合 | 软注意力层走 AllGather KV,与线性层统一接口;论文未给跨层时序,生产框架未实装 |
| 通用原则 | 不同 attention 通信模式不同,不能统一处理 |
@tbl-par-cp-het-takeaway 异构 attention CP 核心知识点
开放问题
- DeepSeek V4 中 CSA(C4) vs HCA(C128) 层的分配比例(多少层走哪种)未公开
- SGLang 的 sharded KV cache CP(分布式存储 + decode CP)仍在开发中,尚无性能数据
- 先选后传路线在大规模集群上是否有近似 top-k 方案能在精度和通信间取得可接受的 tradeoff
- 动态 CP 调度的 bucket 函数能否泛化到不同硬件/模型(机制详见 09-推理部署模式)
- MoBA 在 CP 下的负载均衡:MTraining 提出 balanced sparse ring,但生产框架尚无集成
- LASP-2H 在 SGLang/vLLM/Megatron 等生产框架的实装:论文给出算法但未实测,混合层跨 AllGather 的时序与 overlap 策略仍开放
参考资料
- Beltagy et al., Longformer: The Long-Document Transformer, arXiv:2004.05150, 2020. https://arxiv.org/abs/2004.05150
- Jiang et al., Mistral 7B, arXiv:2310.06825, 2023. https://arxiv.org/abs/2310.06825
- LMSYS, DeepSeek V4 Day-0 Deployment, 2026-04-25. https://lmsys.org/blog/2026-04-25-deepseek-v4/
- SGLang, DeepSeek V3.2/GLM-5 Usage. https://docs.sglang.io/basic_usage/deepseek_v32.html
- sgl-project/sglang,
python/sglang/srt/layers/utils/cp_utils.py. https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/layers/utils/cp_utils.py - DeepSeek-AI, DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, arXiv:2512.02556, 2025. https://arxiv.org/abs/2512.02556
- sgl-project/sglang, [Roadmap] Context Parallelism (2026 Q2), Issue #21788. https://github.com/sgl-project/sglang/issues/21788
- DeepSeek-AI, Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, arXiv:2502.11089, 2025. https://arxiv.org/abs/2502.11089
- Lu et al., MoBA: Mixture of Block Attention for Long-Context LLMs, arXiv:2502.13189, 2025. https://arxiv.org/abs/2502.13189
- Wang et al., MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training, arXiv:2510.18830, 2025. https://arxiv.org/abs/2510.18830
- Sun et al., Linear Attention Sequence Parallelism, arXiv:2404.02882, 2024. https://arxiv.org/abs/2404.02882
- Ye et al., LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid, arXiv:2502.07563, 2025. https://arxiv.org/abs/2502.07563
- Sun et al., Linear-MoE: Linear Sequence Modeling Meets Mixture-of-Experts, arXiv:2503.05447, 2025. https://arxiv.org/abs/2503.05447
- Dao & Gu, Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv:2405.21060, 2024. https://arxiv.org/abs/2405.21060