Fat-tree
基于 Clos 理论的等端口多级交换网络及 Rail-Optimized 降本变体
核心要点:
- AI 集群最广泛使用的多级交换网络,基于 Clos 理论
- 3 级结构 = Edge + Aggregation + Core,2 级简化为 Leaf-Spine
- 标准 Fat-tree ($r=1$) 提供全割集带宽 $\frac{N}{2}b$
- 天然无死锁 (上行-下行单调路径)
- Rail-Optimized 变体让 DP AllReduce 在 Rail 内闭合,省 30-50% Spine 成本
- Oversubscription 通过下/上行比 $r$ 调控成本 vs 带宽
- 3 级支持 $k^3/4$ 节点 (64 端口 = 65K),5 级可达 100K+ GPU
Clos 网络与 Fat-tree 是什么关系?
Clos 是数学框架,Fat-tree 是用等端口商用交换机的实现。
| Clos 网络 | Fat-tree | |
|---|---|---|
| 提出 | Clos 1953 (电话交换)[1] | Leiserson 1985 (并行计算)[2] |
| 本质 | 多级交换网络的非阻塞条件 ($m \geq n$) | 用等端口数商用交换机构建的折叠 Clos[3] |
| 描述角度 | 抽象 input/middle/output 三级 | 具体 Edge/Aggregation/Core + Pod |
@tbl-topo-ft-clos Clos vs Fat-tree
现代 Fat-tree 实质是折叠 Clos,两名词在数据中心语境可互换。
3 级 Fat-tree 长什么样?
统一 $k$-port 交换机构建三层:Edge / Aggregation / Core,按 Pod 分组,见 @fig-topo-ft-3level。
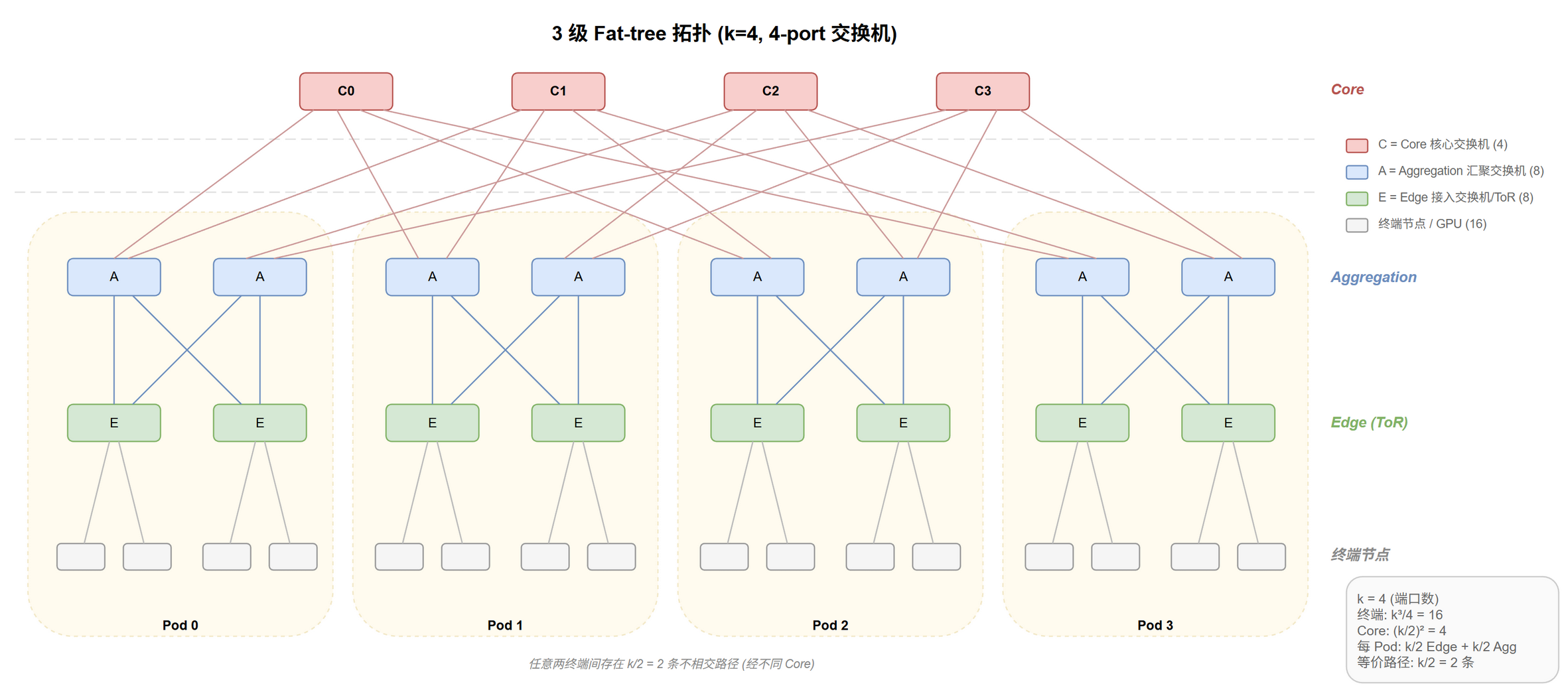
三层定义:
- Edge (接入层/ToR):下行 $k/2$ 端口连终端,上行 $k/2$ 端口连 Aggregation
- Aggregation (汇聚层):下行 $k/2$ 连本 Pod 内所有 Edge,上行 $k/2$ 连 Core
- Core (核心层):每台 Core 连接每个 Pod 中的一台 Aggregation
Pod 分组:$k$ 个 Pod,每个含 $k/2$ Edge + $k/2$ Aggregation。Pod 是 Fat-tree 的基本构建和扩展单位。
Pod 到 Core 的连接规则:Core 交换机按 $(k/2) \times (k/2)$ 矩阵编号 $C(j, i)$:
$$\begin{equation} C(j, i) \longleftrightarrow \text{每 Pod 的第 } j \text{ 台 Aggregation 的第 } i \text{ 个上行端口} \label{eq:topo-fat-tree-aggregation-port} \end{equation}$$这条规则保证任意两终端间存在 $k/2$ 条不相交路径 (经过不同 Core),这是 Fat-tree 非阻塞特性的结构基础。
Leaf-Spine 是什么简化?
现代数据中心和 AI 集群常用的 2 级 Clos,省去 Aggregation 层:
- Leaf = Edge/ToR,直接连终端
- Spine = Core,连接所有 Leaf
每台 Leaf 连所有 Spine,每台 Spine 连所有 Leaf。适合中等规模 (数百-数千节点)。大规模 (万卡+) 仍需 3 级或 5 级。
关键参数和 Oversubscription
核心问题:$r$ (下行/上行端口比) 如何调控 Fat-tree 的带宽与成本?$r=1,2,3$ 下的割集和 Core 数差异有多大?
$r$ (下行/上行端口比) 决定带宽 vs 成本权衡。每台交换机的 $k$ 个端口分为下行 $d$ 和上行 $u$:
$$\begin{equation} d = \left\lfloor \frac{k \cdot r}{r + 1} \right\rceil, \quad u = k - d \label{eq:topo-fat-tree-uplink-downlink-split} \end{equation}$$- $r = 1$ (1:1): $d = u = k/2$,全割集带宽 (标准 Fat-tree)
- $r = 2$ (2:1): $d \approx 2k/3$, $u \approx k/3$,割集带宽减半
- $r = 3$ (3:1): $d \approx 3k/4$, $u \approx k/4$,割集带宽 1/3
3 级 Fat-tree ($r=1$ 标准) 参数见 @tbl-topo-ft-3level。
| 属性 | 值 |
|---|---|
| 终端节点数 | $k^3 / 4$ |
| Pod 数 | $k$ |
| 每 Pod 交换机 | $k$ ($k/2$ Edge + $k/2$ Agg) |
| Core 交换机数 | $(k/2)^2$ |
| 交换机总数 | $5k^2/4$ |
| 链路数 | $3k^3/4$ |
| 直径 | 6 |
| 割集带宽 | $\frac{k^3}{8} b = \frac{N}{2} b$ (全割集) |
| 等价路径数 | $k/2$ |
@tbl-topo-ft-3level 3 级 Fat-tree 参数 ($r=1$)
一般 $r$ 下的变化 (@tbl-topo-ft-r-vary):
| 属性 | $r = 1$ | 一般 $r$ |
|---|---|---|
| 每 Edge 下行终端 | $k/2$ | $d$ |
| 每 Edge 上行端口 | $k/2$ | $u$ |
| 每 Pod 终端数 | $(k/2)^2$ | $d^2$ |
| 终端总数 (满配) | $k^3/4$ | $d^2 \cdot k$ |
| Core 交换机数 | $(k/2)^2$ | $u^2$ |
| 等价路径数 | $k/2$ | $u$ |
@tbl-topo-ft-r-vary $r$ 变化对参数的影响
2 级 Leaf-Spine 参数 (@tbl-topo-ft-ls):
| 属性 | 值 |
|---|---|
| Leaf 交换机数 | $L = N / d$ |
| Spine 交换机数 | $u$ (每台连 $L$ Leaf,需 $L$ 端口) |
| 终端节点数 | $L \cdot d$ |
| 直径 | 4 |
| 等价路径数 | $u$ |
| 全割集条件 | $r = 1$ (即 $u = d$) |
@tbl-topo-ft-ls Leaf-Spine 参数
规模能扩多大?
3 级 + 64 端口交换机 = 65,536 终端,规模表见 @tbl-topo-ft-scale。
| 交换机端口数 $k$ | 终端节点 $k^3/4$ | 交换机总数 $5k^2/4$ | 链路数 $3k^3/4$ |
|---|---|---|---|
| 8 | 128 | 80 | 384 |
| 16 | 1,024 | 320 | 3,072 |
| 32 | 8,192 | 1,280 | 24,576 |
| 48 | 27,648 | 2,880 | 82,944 |
| 64 | 65,536 | 5,120 | 196,608 |
@tbl-topo-ft-scale Fat-tree 规模扩展 ($r=1$)
现代 IB 交换机 (如 Quantum-2 NDR) 有 64 端口,单组 3 级 Fat-tree 支持 65,536 终端。5 级可进一步扩到 100K+ GPU。
非阻塞特性的三层含义
核心问题:Fat-tree 的 RNB (可重排无阻塞)、天然无死锁、全割集带宽三层含义各自的技术价值是什么?
RNB + 天然无死锁 + 全割集。
Rearrangeably Non-Blocking (RNB): Clos 定理 — 3 级 Clos 在中间级数 $m \geq n$ 时为 RNB。RNB 意味着对任意一对一排列模式总存在一种路由方案使所有流同时通过不冲突。但找到这种方案需要全局信息 — 这是路由算法要解决的问题。
天然无死锁:上行-下行结构天然无环。数据包先沿树上行到 Core (或最低公共祖先),再沿树下行到目的地。单调路径不形成环路,无需额外虚通道机制。这是 Fat-tree 相比 Torus 等的重要工程优势。
全割集带宽:终端节点从任意位置对半划分,横跨链路总带宽恒等于 $\frac{N}{2} \cdot b$。Fat-tree 在任何通信模式下都不会因拓扑产生带宽瓶颈。
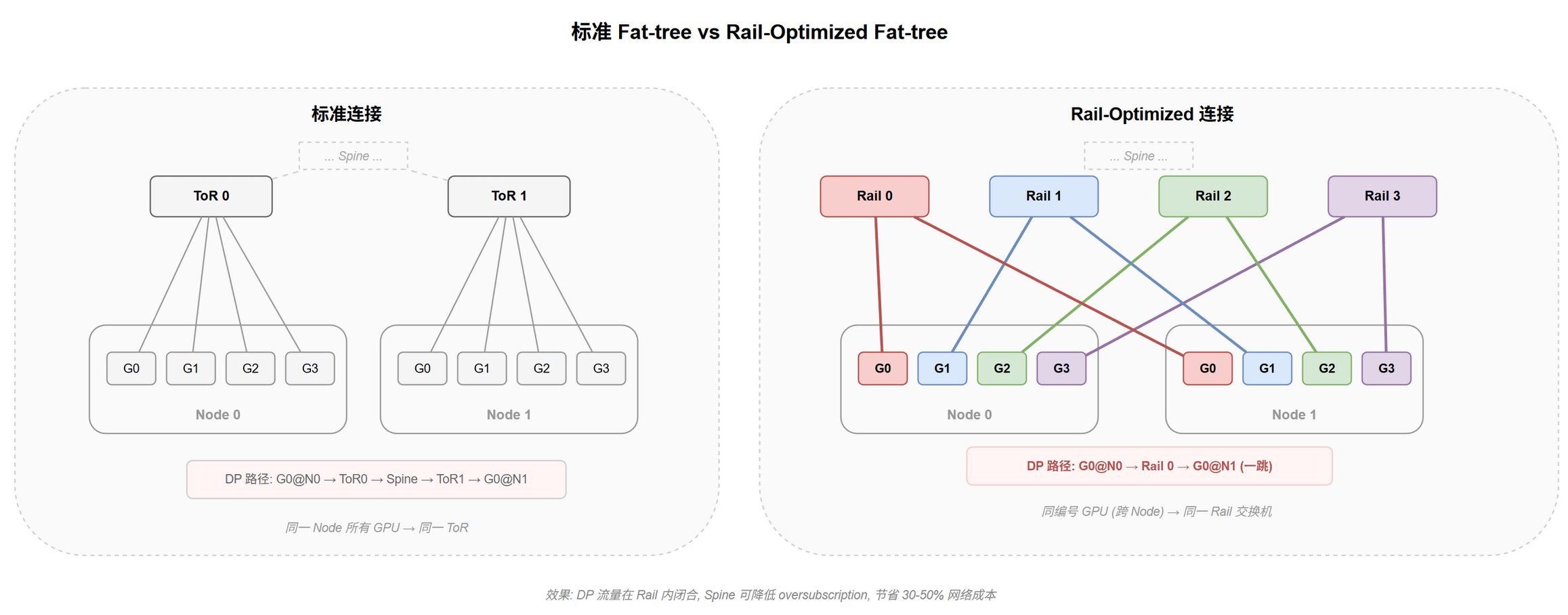
Rail-Optimized Fat-tree 怎么做?
同一 GPU 编号的 NIC 连到同一台 Leaf (称为 Rail),让 DP AllReduce 在 Rail 内闭合[4]。
标准方式:一台服务器节点的所有 GPU 通过各自 NIC 连到同一台 ToR 交换机。 Rail-Optimized:改变接线 — 同一 GPU 编号 (如所有节点的 GPU 0) 的 NIC 连到同一台 Leaf。
物理上只是重新插线,不需要更换交换机硬件,见 @fig-topo-ft-rail。
节点内部互联 (DGX H100 为例)
每节点内 8 块 GPU + 4 个 NVSwitch 芯片,每块 GPU 连全部 4 个 NVSwitch,形成 non-blocking 全互联。NVSwitch 处理节点内 (TP),NIC 处理节点间 (DP),见 @fig-topo-ft-node。
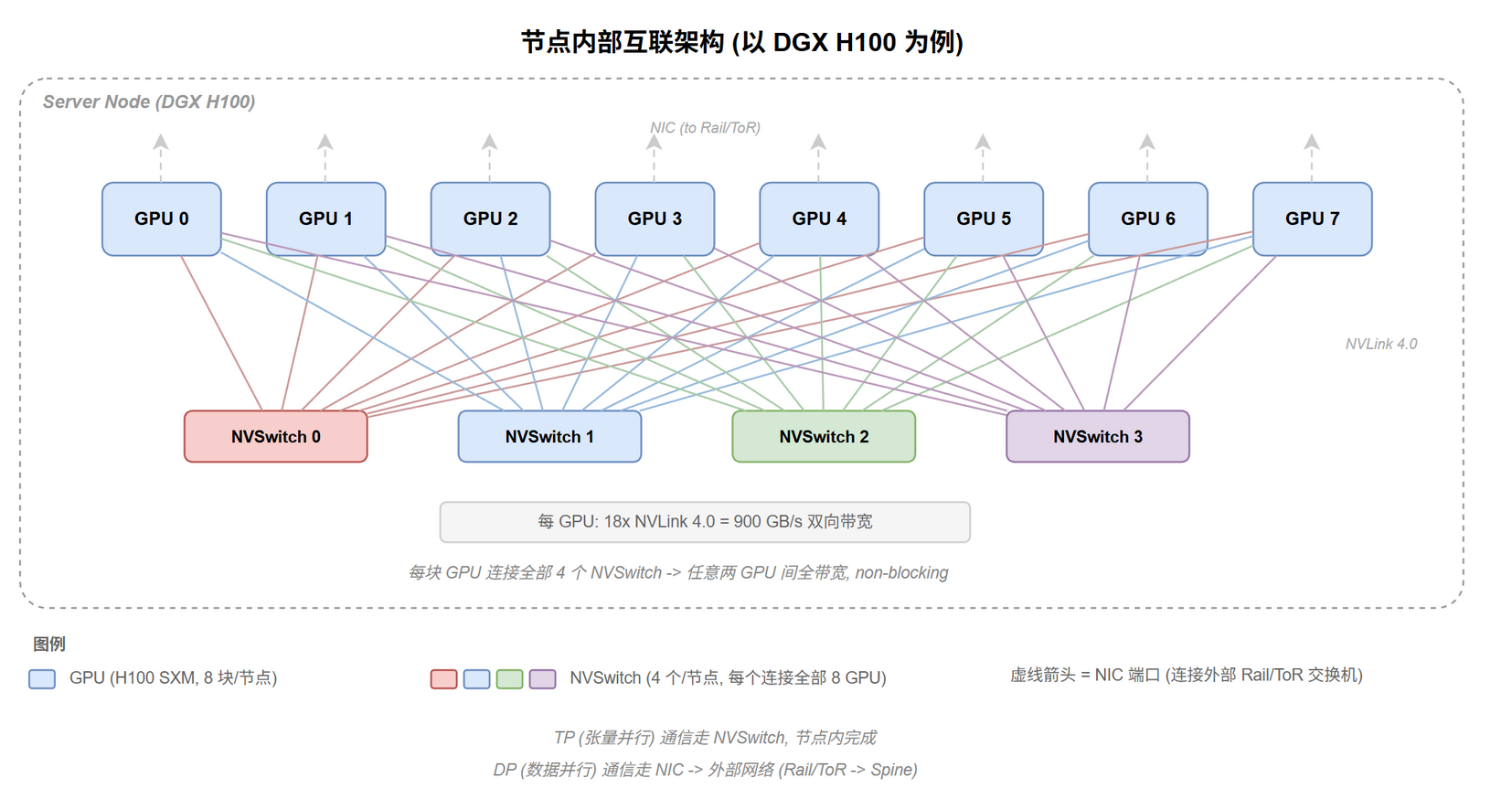
每 GPU 有两套独立通信通道 (@tbl-topo-ft-channel):
| 通道 | 连接方式 | 协议 | 带宽 (H100) | 用途 |
|---|---|---|---|---|
| NVSwitch | GPU → NVSwitch (节点内) | NVLink 4.0 | 900 GB/s per GPU | TP |
| NIC | GPU → NIC → Rail/ToR (节点间) | IB / RoCE | 400 Gbps per NIC | DP |
@tbl-topo-ft-channel 节点内通道分工
Rail-Optimized 的效果
- DP AllReduce 在 Rail 内闭合:同编号 GPU 都连在同一 Rail 交换机,DP 通信一跳直达不经 Spine
- Spine 层降低 oversubscription:DP 流量不经 Spine,Spine 只处理 TP/PP 等跨 Rail 通信,负载大幅降低
- 网络成本节省 30-50%:Spine 交换机和线缆数量可减[5]
Oversubscription 怎么调成本?
$r$ 从 1 增到 3,Core 数从 36 降至 9 (省 75%),代价是割集降到 1/3。以 $k = 12$ 端口为例 (@tbl-topo-ft-oversub):
| 超订比 $r$ | 下行 $d$ | 上行 $u$ | 割集带宽比 | Core 交换机 (3 级) | 适用场景 |
|---|---|---|---|---|---|
| 1:1 | 6 | 6 | 100% | 36 | MoE AllToAll 密集型 |
| 2:1 | 8 | 4 | 50% | 16 | 通用训练 |
| 3:1 | 9 | 3 | 33% | 9 | 推理、DP 为主 |
@tbl-topo-ft-oversub Oversubscription 对比
跨 Pod 等价路径数从 6 (1:1) 降至 3 (3:1)。
成本结构
核心问题:3 级 Fat-tree 的交换机、链路、布线各项成本占比如何?与其他拓扑的成本对比?
3 级 Fat-tree,$N = k^3/4$ 终端节点的成本组件 (@tbl-topo-ft-cost):
| 组件 | 数量 | 单价参考 (2024) |
|---|---|---|
| Edge 交换机 | $k^2/4$ | ~$940-1,170/port (IB NDR) |
| Aggregation 交换机 | $k^2/4$ | 同上 |
| Core 交换机 | $k^2/4$ | 同上 |
| 链路/线缆 | $3k^3/4$ | $300-600/pair (400G AOC 50m) |
@tbl-topo-ft-cost Fat-tree 成本组件
万卡集群的网络成本 (交换机 + 光模块 + 线缆) 占总 TCO 的 30-40%。
与其他拓扑成本对比 (@tbl-topo-ft-vs):
| 拓扑 | 链路数量级 | 相对成本 | 割集带宽 |
|---|---|---|---|
| Fat-tree | $O(N \log N)$ | 高 (基准) | 全割集 $\frac{N}{2}b$ |
| 3D Torus | $O(N)$ | 低 (FT 的 20-30%) | $2N^{2/3}b$ (FT 的 20-60%) |
| Dragonfly | $O(N)$ | 中 (FT 的 40-60%) | $\sim 0.7 \cdot \frac{N}{2}b$ |
@tbl-topo-ft-vs Fat-tree vs 其他拓扑
Fat-tree 用更高成本换全割集带宽和工程简单性 (无死锁、标准路由)。
适用场景与局限
核心问题:Fat-tree 最适合和不适合哪些并行策略和部署场景?
适用:通用 AI 训练集群首选。
- 全并行策略组合 (TP + PP + DP + EP)
- MoE 模型 (AllToAll 对全割集要求最高)
- 大规模扩展 (3 级 65K,5 级 100K+)
- 多租户集群 (路由自然隔离)
局限:
- 成本高 (交换机 $5k^2/4$,链路 $O(N \log N)$),是 Torus 3-5×
- 非 Vertex-Transitive (Edge/Agg/Core 角色不同)
- 增量扩展按 Pod
- 布线复杂 (Core-Agg 跨 Pod 线缆密集,大规模工程挑战)
实际部署案例
核心问题:Fat-tree 在真实 AI 集群中有哪些代表性大规模部署(NVIDIA Eos/xAI Colossus/Meta RSC 等)?
| 集群 | 规模 | 节点内拓扑 | 节点间网络 | 特点 |
|---|---|---|---|---|
| NVIDIA Eos | 10,752 H100 | NVSwitch 3.0 全互联 | IB NDR Fat-tree | SuperPOD 参考 |
| xAI Colossus | 100,000 H100 | NVSwitch 全互联 | IB Fat-tree | 已知最大 GPU 集群 |
| Meta RSC | 16,384 A100 | NVSwitch 全互联 | IB HDR Fat-tree | Rail-Optimized |
| CoreWeave | 1,440 B200 | NVL72 全互联 | IB XDR | NVL72 首批部署 |
| Oracle OCI | ~16,000 H100 | NVSwitch 全互联 | IB NDR Fat-tree | 云服务商 |
@tbl-topo-ft-deploy Fat-tree 实际部署案例
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 与 Clos 关系 | Clos 是数学框架,Fat-tree 是等端口商用交换机的折叠 Clos 实现 |
| 3 级结构 | Edge + Aggregation + Core,按 Pod 分组 |
| 关键属性 | 全割集 $\frac{N}{2}b$ ($r=1$)、天然无死锁、$k/2$ 等价路径 |
| 规模 | 3 级 64 端口 = 65K 节点,5 级 100K+ |
| Rail-Optimized | DP 在 Rail 内闭合,省 30-50% Spine 成本 |
| Oversubscription | $r$ 调成本 vs 带宽,$r=3$ 省 75% Core 但割集降到 1/3 |
| 适用 | 通用 AI 训练首选,MoE AllToAll 必备 |
| 主要短板 | 成本高 (Torus 的 3-5×)、布线复杂 |
参考资料
- Clos C., A Study of Non-Blocking Switching Networks, Bell System Technical Journal 1953. https://doi.org/10.1002/j.1538-7305.1953.tb01433.x
- Leiserson C., Fat-Trees: Universal Networks for Hardware-Efficient Supercomputing, IEEE TC 1985. https://doi.org/10.1109/TC.1985.6312192
- Al-Fares M. et al., A Scalable, Commodity Data Center Network Architecture, SIGCOMM 2008. https://dl.acm.org/doi/10.1145/1402958.1402967
- NVIDIA, DGX SuperPOD Reference Architecture. https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/dgx-superpod-components.html
- Mudigere D. et al., Software-Hardware Co-design for Fast and Scalable Training of Deep Learning Recommendation Models, ISCA 2022. https://dl.acm.org/doi/10.1145/3470496.3533727