Hypercube
维度递归结构的图论性质及其作为集合通信算法逻辑基础的价值
核心要点:
- $N = 2^n$ 节点,地址相差一位 (Hamming = 1) 即相连,度数 $\log_2 N$
- 递归构造:$n$D = 两个 $(n-1)$D + 对应节点互联
- 割集带宽 $\frac{N}{2}b$ 达理论上限,直径 $\log_2 N$
- 度数随规模对数增长 — 物理拓扑被淘汰的根本原因
- 但仍是 Recursive Halving-Doubling / Bruck AllGather 等算法的逻辑基础
- 1990s 后被 Fat-tree 取代 (固定端口、任意规模、增量扩展)
- 历史部署:Intel iPSC、nCUBE、Thinking Machines CM-2
Hypercube 的基本结构是什么?
$N = 2^n$ 节点,每节点用 $n$ 位二进制地址标识,相差一位即相连。
每节点恰好与 $n$ 个邻居相连。递归构造:$n$ 维 = 两个 $(n-1)$ 维副本 + 对应节点互联,见 @fig-topo-hc-recursive。
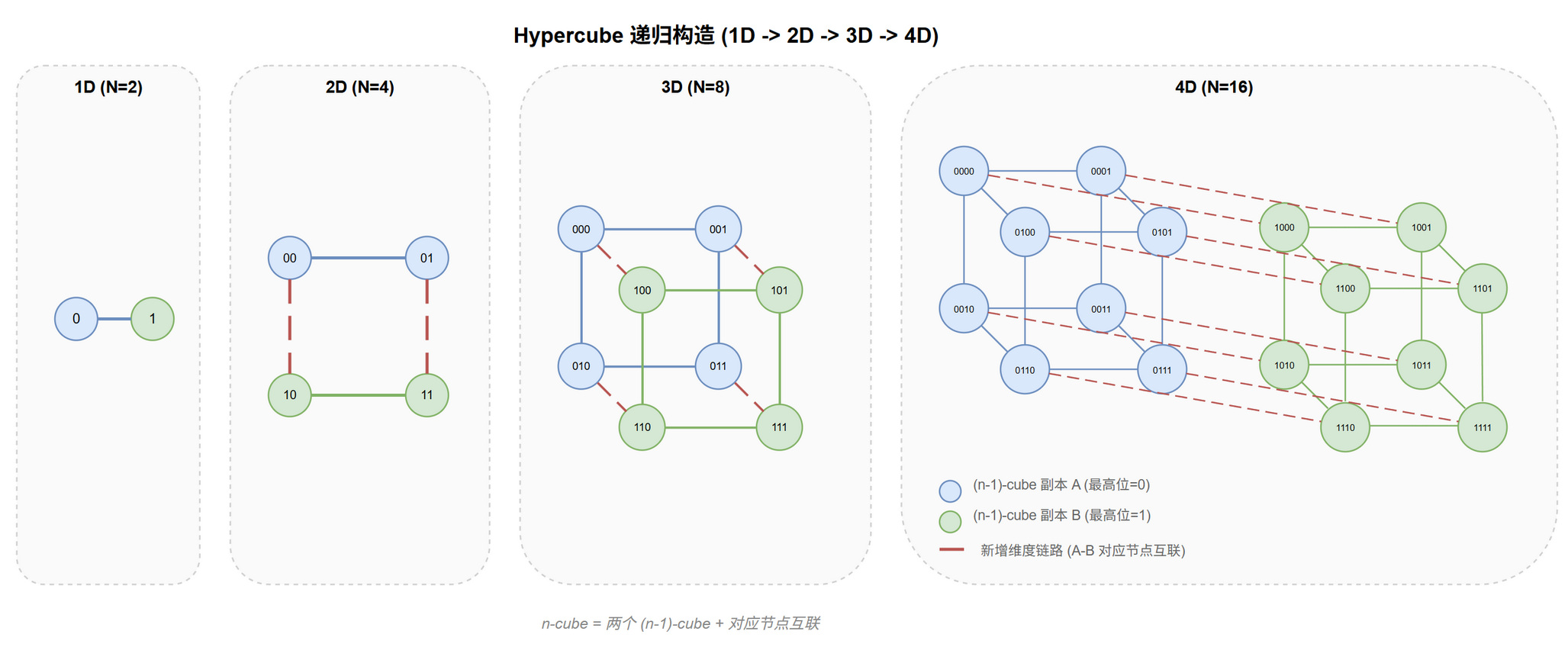
| 维度 | 节点数 | 构造方式 | 形状 |
|---|---|---|---|
| 0D | 1 | 单节点 | 点 |
| 1D | 2 | 两个 0D 互联 | 线段 |
| 2D | 4 | 两个 1D 对应节点互联 | 正方形 |
| 3D | 8 | 两个 2D 对应节点互联 | 立方体 |
| 4D | 16 | 两个 3D 对应节点互联 | 超立方体 |
| $n$D | $2^n$ | 两个 $(n-1)$D 对应节点互联 | $n$-cube |
@tbl-topo-hc-construct Hypercube 递归构造
递归结构直接决定 Hypercube 上集合通信算法的设计 — 按维度逐层折叠/展开恰好对应 Recursive Halving-Doubling 算法。
与其他拓扑是什么关系?
Hypercube 是多种拓扑家族的交汇点:
| 关系 | 说明 |
|---|---|
| Chordal Ring 极限 | Hypercube = $CR(N; 1, 2, 4, 8, \ldots, N/2)$,即 Ring 加 $\log_2 N$ 条 power-of-2 弦 |
| $k$-ary $n$-cube 特例 | Hypercube 是 $k=2$ 的 Torus。Torus 放大 $k$ ($k > 2$) 用更低度数容纳更多节点 |
| HyperX 特例 | HyperX 把 Hypercube 每维从 2 推广到 $k$ (全互联),固定交换机端口下最大化割集 |
| Fat-tree 可模拟 | Fat-tree 可模拟 Hypercube 任意通信模式 (全割集带宽),但用交换机而非直连 |
@tbl-topo-hc-relations Hypercube 与其他拓扑关系
关键参数和对比
核心问题:Hypercube 的度数、直径、割集、链路数随维度如何变化?全割集 $\frac{N}{2}b$ 意味着什么?
全割集 + $\log_2 N$ 直径,但度数也是 $\log_2 N$:
| 属性 | 值 |
|---|---|
| 节点数 | $N = 2^n$ |
| 度数 | $d = n = \log_2 N$ |
| 直径 | $n = \log_2 N$ |
| 割集带宽 | $\frac{N}{2} \cdot b$ |
| 总链路数 | $\frac{N \log_2 N}{2}$ |
| Vertex-Transitive | Yes |
@tbl-topo-hc-params Hypercube 关键参数
与其他拓扑对比 (@tbl-topo-hc-vs):
| 拓扑 | 割集带宽 | 度数 | 直径 |
|---|---|---|---|
| Hypercube ($2^n$) | $\frac{N}{2} b$ | $\log_2 N$ (随 $N$ 增长) | $\log_2 N$ |
| Fat-tree ($N$) | $\frac{N}{2} b$ | 固定 (交换机决定) | $2\log_r N$ (固定级数) |
| 3D Torus ($k^3$) | $2k^2 b$ | 6 (固定) | $\frac{3k}{2}$ |
| Ring ($N$) | $2b$ | 2 (固定) | $N/2$ |
@tbl-topo-hc-vs Hypercube vs 其他拓扑
Hypercube 的割集与 Fat-tree 相当,直径仅 $\log_2 N$。但代价是度数随规模对数增长 — 这是 Hypercube 作为物理拓扑被淘汰的根本原因。
Hypercube 的全割集为什么是 $\frac{N}{2}b$?
沿任意一个维度对半划分,恰好切断 $N/2$ 条链路:每个节点在该维度上的一条链路被切断。
Hypercube 的嵌入性有什么用?
可高效嵌入 Ring / Mesh / Tree 等常见拓扑作为子图:
| 被嵌入拓扑 | 嵌入方式 | 扩张比 |
|---|---|---|
| Ring ($2^n$ 节点) | Gray Code 遍历 | 1 (最优) |
| 2D Mesh ($2^a \times 2^b$) | 每维独立 Gray Code | 1 (最优) |
| Complete Binary Tree | 递归嵌入 | 1 (最优) |
| Butterfly 网络 | 维度对应 | 同构 |
@tbl-topo-hc-embed Hypercube 嵌入性
Hypercube 上的算法可自然运行 Ring / Mesh / Tree 等拓扑上设计的通信模式。这是 Hypercube 成为集合通信算法设计基础的结构原因。
E-cube 路由怎么避免死锁?
按维度从低位到高位严格递增 (Dimension-Ordered)。
源 $s$ 到目标 $t$,计算 $s \oplus t$ (XOR),按从低位到高位顺序,依次沿差异位对应的维度转发。路径长度 = Hamming 距离,严格按维度递增,天然无死锁。
对称性:Vertex-Transitive 保证所有节点结构地位等价。均匀流量下每条链路负载相同。非均匀流量可通过 Valiant 随机路由均衡化 (详见 路由算法)。
Hypercube 对现代集合通信的结构贡献
核心问题:物理 Hypercube 时代已终结,但其递归二分结构如何在现代 AllReduce 算法(Halving-Doubling、Butterfly)中延续?
1980s-90s 物理 Hypercube 时代的算法仍在现代 Fat-tree/Torus 集群上以逻辑层面运行。
| 算法 | Hypercube 结构基础 | 现代应用 | 详见 |
|---|---|---|---|
| Recursive Halving-Doubling | 按维度逐层折半/倍增 | AllReduce (MPI 默认) | AllReduce |
| Bruck AllGather | 维度步进,$\log N$ 步 | AllGather (小消息最优) | AllGather |
| Recursive Doubling | 维度倍增 | AllReduce (小消息 $O(\log N)$ 步) | AllReduce |
| Bitonic Sort | 蝶形比较网络 | AllToAll 排序阶段 | — |
@tbl-topo-hc-algos 算法对集合通信的贡献
Hypercube 作为物理拓扑已退出历史舞台,但其维度结构定义了集合通信算法的设计范式[1][2][3]。
适用场景与局限
核心问题:Hypercube 适合和不适合哪些场景?为什么物理 Hypercube 已被淘汰?
适用:
- 逻辑通信拓扑 (MPI 集合通信在任意物理拓扑上构建 Hypercube 逻辑图)
- 小规模直连 ($N \leq 16$ 即 4D 时度数仅 4,与 Torus 相当,且割集最优)
- 算法设计基础 (任何新集合通信算法的理论分析仍以 Hypercube 为起点)
局限:
- 度数 $\log_2 N$ 随规模增长 ($N = 65536$ 时 16 端口/节点)
- 节点数必须 $2^n$,增量扩展需要全网重布线
- 线缆复杂度 $\frac{N \log_2 N}{2}$ ($N = 65536$ 时 524,288 条)
- 被 Fat-tree 替代 (固定端口 + 任意规模 + 增量扩展)
历史部署
核心问题:Hypercube 在历史上有哪些著名系统、规模多大、后来为什么被取代?
| 系统 | 年份 | 规模 | 维度 | 备注 |
|---|---|---|---|---|
| Intel iPSC/1 | 1985 | 128 节点 | 7D | 首批商用超立方体并行机 |
| nCUBE/ten | 1985 | 1,024 节点 | 10D | 自研处理器,每节点 10 通信端口 |
| Thinking Machines CM-2 | 1987 | 65,536 PE | 12D | 最大规模 Hypercube,Connection Machine[4] |
@tbl-topo-hc-deploy Hypercube 历史部署
1990s 后高端口数交换机和 Fat-tree 普及,Hypercube 作为物理拓扑退出历史。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 结构 | $N = 2^n$,地址相差一位即相连,递归构造 |
| 参数 | 全割集 $\frac{N}{2}b$ + 直径 $\log_2 N$ + 度数 $\log_2 N$ |
| 与其他拓扑 | Chordal Ring 极限 / Torus $k=2$ 特例 / HyperX 特例 |
| 路由 | E-cube 维度递增,天然无死锁 |
| 嵌入性 | Ring / Mesh / Tree 均可嵌入,扩张比 1 |
| 历史角色 | 1980-90s 物理拓扑 (iPSC / nCUBE / CM-2),1990s 后退出 |
| 现代价值 | 算法基底 — RHD / Bruck 等仍在 Fat-tree/Torus 上以逻辑层运行 |
| 被淘汰原因 | 度数 $\log_2 N$ 增长,规模扩展受限 |
参考资料
- Leighton T., Introduction to Parallel Algorithms and Architectures, 1992. https://dl.acm.org/doi/book/10.5555/562706
- Thakur R. et al., Optimization of Collective Communication Operations in MPICH, IJHPCA 2005. https://doi.org/10.1177/1094342005051521
- Bruck J. et al., Efficient Algorithms for All-to-All Communications in Multiport Message-Passing Systems, IEEE TPDS 1997. https://doi.org/10.1109/71.642949
- Hillis W. D., The Connection Machine, MIT Press 1985. https://dl.acm.org/doi/book/10.5555/4417