NVL72
NVIDIA Blackwell 72 GPU 单机架全互联域的结构、带宽与域内外断崖
核心要点:
- NVIDIA Blackwell 时代关键突破,全互联域从 DGX H100 的 8 GPU 扩到 72 GPU
- 单机架:18 Compute Tray (72 B200) + 9 NVLink Switch Tray (18 NVSwitch 4.0)
- 每 GPU 18 条 NVLink 5.0 = 1,800 GB/s 单向聚合
- 全域 AllReduce 聚合带宽 ~260 TB/s,割集 64.8 TB/s
- 网络直径 2 跳 (GPU → NVSwitch → GPU)
- 带宽断崖 36:1 (域内 1800 vs 对外 IB ~50 GB/s)
- 与华为 CloudMatrix 384 代表"带宽密度 vs 规模"不同权衡
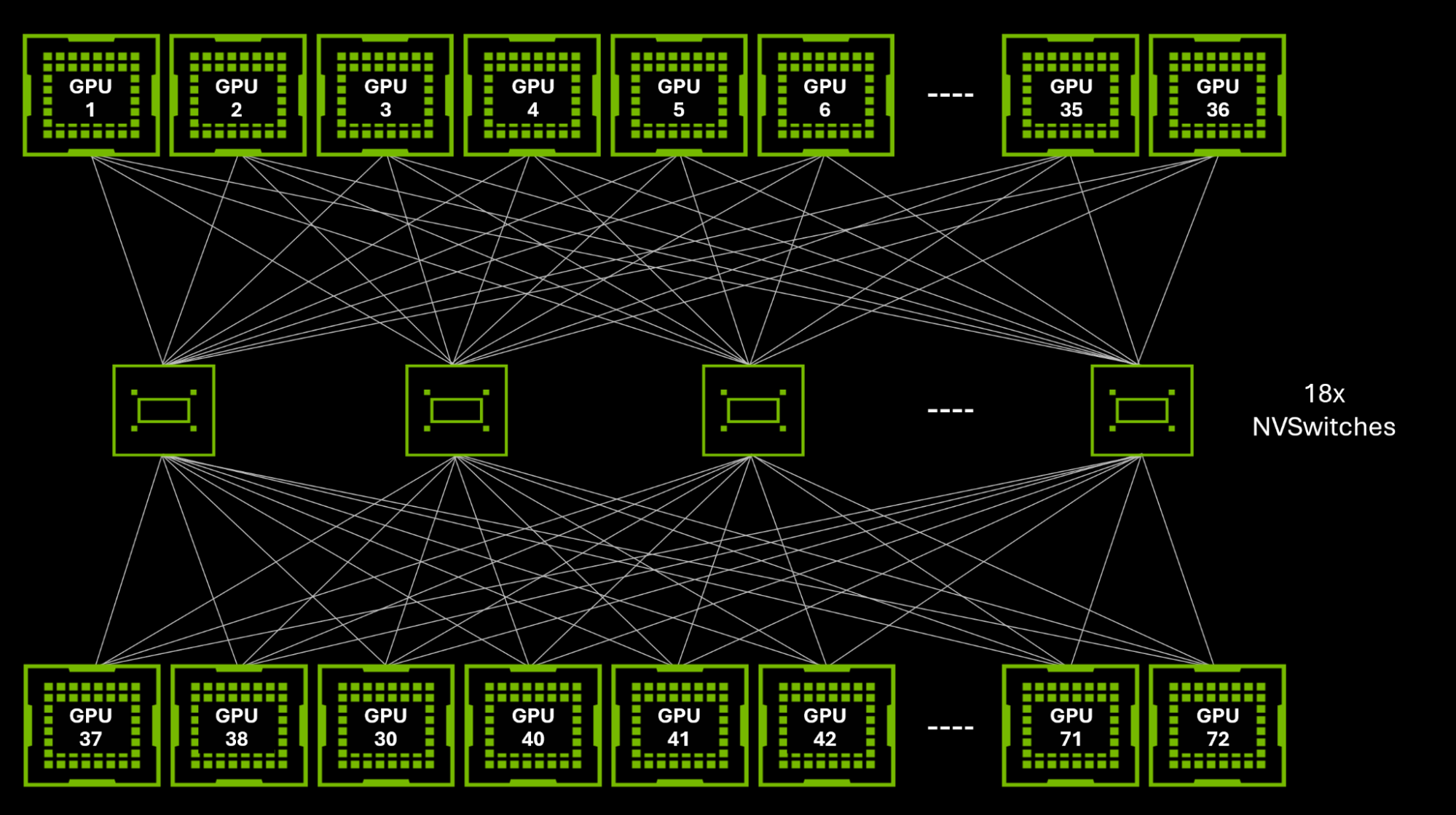
NVL72 物理结构是什么?
72 个 B200 + 18 个 NVSwitch 4.0 在单机架内构成全互联域:
NVL72 机架
├── 18 Compute Tray (每 Tray: 4 颗 B200 = 2 Grace-Blackwell Superchip)
│ 总 72 颗 B200 GPU
└── 9 NVLink Switch Tray (每 Tray: 2 颗 NVSwitch 4.0)
总 18 颗 NVSwitch 4.0
每颗 B200 通过 18 条 NVLink 5.0 连接到 18 颗 NVSwitch 4.0 (每 NVSwitch 1 条),NVSwitch 内部完成全交叉交换。逻辑上任意两 GPU 可通过任意 NVSwitch 进行 1 跳通信。
关键参数
核心问题:NVL72 的 GPU 数、每 GPU NVLink 带宽、NVSwitch 数量、总交换带宽、机架功耗等关键参数是多少?
| 参数 | 值 |
|---|---|
| GPU 数 | 72 (36 Superchip × 2 B200) |
| NVSwitch 数 | 18 (NVSwitch 4.0,每颗 72 端口) |
| 每 GPU NVLink 链路数 | 18 (NVLink 5.0) |
| 每条 NVLink 5.0 带宽 | 200 GB/s 双向 (单向 100) |
| 每 GPU NVLink 带宽 | 1,800 GB/s 单向聚合 (双向 3,600) |
| 全域 AllReduce 聚合带宽 | ~260 TB/s |
| 网络直径 | 2 跳 |
| 割集带宽 | $\frac{72}{2} \times 1800 = 64.8$ TB/s |
@tbl-topo-nvl72-params NVL72 关键参数
为什么是 72 GPU 而不是 64 或 128?
- 72 = 36 Superchip × 2 GPU,受 Grace-Blackwell Superchip 的 D2D 链路和机架物理空间限制
- NVSwitch 4.0 有 72 个 NVLink 端口 (比 3.0 的 64 端口增 12.5%),18 颗提供 1296 端口,恰好连接 72 GPU × 18 links/GPU
- 128 GPU 需更多 NVSwitch,功耗散热超出单 rack 承受能力[1]
通信性能怎么样?
AllReduce
Full Mesh 语义下 Recursive Halving-Doubling 是最优 AllReduce:
$$\begin{equation} T_{\text{AllReduce}} = 2\lceil \log_2 72 \rceil \cdot \alpha + \frac{2(72-1)}{72} \cdot \frac{M}{\beta} \label{eq:topo-nvl72-allreduce-time} \end{equation}$$- 延迟项:$\alpha$ = NVSwitch 交换延迟,实测 <300 ns
- 带宽项:$\beta = 1,800$ GB/s/GPU,实测 bus bandwidth ~839 GB/s[2]
AllGather
实测 bus bandwidth ~1,600 GB/s。无需 Reduce,带宽利用率更高。
AllToAll
72 GPU 全互联域内单跳 (通过 NVSwitch),理论效率接近 100%。实际受限于每 GPU 18 条 NVLink 并发注入带宽。
与 DGX H100 怎么对比?
| 指标 | DGX H100 | GB200 NVL72 |
|---|---|---|
| 全互联域规模 | 8 GPU | 72 GPU |
| 每 GPU 双向带宽 | 900 GB/s | 1,800 GB/s |
| NVSwitch 代 | 3.0 (64 端口) | 4.0 (72 端口) |
| 带宽断崖 vs 网络 | 18:1 | 36:1 |
| AllReduce 延迟 (1 GB) | 基准 | 更低 (带宽 2×) |
@tbl-topo-nvl72-vs-h100 NVL72 vs DGX H100
适用场景与局限
核心问题:NVL72 适合和不适合哪些并行策略和部署场景?
适用:
- 大 TP 组:TP=72 可在单 NVL72 内完成,无带宽断崖
- 超大单体模型:张量并行的激活和权重通信均在高速 NVLink 上
- MoE 节点内 EP:72 GPU 内分配 Expert,AllToAll 单跳完成
- 混合精度推理:高频小消息在全互联域内零争用
局限:
- 带宽断崖 36:1:域内 1,800 GB/s vs IB ~50 GB/s。跨 NVL72 通信骤降 36×,并行策略必须严格约束 TP 在内部
- 规模固定 72:不可灵活配置 (不像 Torus 可调维度)
- 成本极高:NVSwitch 4.0 + 18 条 NVLink/GPU 的 SerDes 资源
- 功耗散热:72 GPU + 18 NVSwitch 单 rack 内功耗超 100 kW,需液冷
- 对外依赖 IB:NVL72 无跨 rack 互联能力,需 IB 网络
与华为 CloudMatrix 384 怎么对比?
NVIDIA 选带宽密度,华为选规模。两者代表不同工程权衡 (@tbl-topo-nvl72-vs-cm)。
| 指标 | NVIDIA NVL72 | 华为 CloudMatrix 384 |
|---|---|---|
| 加速器数 | 72 GPU | 384 NPU |
| 每芯片互联带宽 | 14.4 Tbps (1.8 TB/s) | 2.8 Tbps |
| 全互联域规模 | 72 GPU | 384 NPU (L1/L2 两级交换,非物理直连) |
| 互联介质 | 电气 NVLink + 光 NVSwitch 背板 | 全光 (400G LPO) |
| 交换架构 | 单级 NVSwitch (18 颗) | L1/L2 两级 UB 交换 |
| 系统 BF16 算力 | 180 PFLOPS | 300 PFLOPS |
| 机架数 | 1 | 16 |
@tbl-topo-nvl72-vs-cm NVL72 vs CloudMatrix 384
关键差异:NVIDIA 以更高单芯片带宽 (5× UB) 换单机架集成;华为以更大全互联域规模 (5.3× GPU 数) 和全光互联换跨机架扩展能力。
CloudMatrix 384 的"全互联域"是通过 L1/L2 两级交换实现的逻辑全互联,跨节点延迟增加 <1 μs,带宽衰减 <3% — 并非物理直连全互联[3][4]。
集群中的实际应用
核心问题:NVL72 在真实 AI 集群中如何与 IB Fat-tree 配合部署?有哪些代表性集群案例?
NVL72 作为单 rack 全互联域,与集群级 IB Fat-tree 配合:
| 集群 | 规模 | NVL72 数 | 节点间网络 |
|---|---|---|---|
| CoreWeave (首批) | 1,440 B200 | 20 个 NVL72 | IB XDR + SHARP |
@tbl-topo-nvl72-cluster NVL72 集群部署
集群级拓扑:多个 NVL72 通过 IB XDR (800 Gbps) 互联组成更大 Fat-tree。每 NVL72 是集群的"超节点",内部全互联,对外单个 IB 上行链路。
并行策略映射:
- TP:单 NVL72 内 1,800 GB/s,TP 组可达 72
- PP:跨 NVL72 通过 IB 400 Gbps,需 micro-batch 流水线掩盖延迟
- DP:跨 NVL72,每步 DP AllReduce 通过 IB
- EP:理想是 EP 组在 NVL72 内;跨 NVL72 走 IB 带宽骤降
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 规模突破 | 全互联域从 8 GPU 扩到 72 GPU |
| 物理构成 | 18 Compute Tray + 9 Switch Tray |
| 关键带宽 | 每 GPU 1,800 GB/s 单向,全域 ~260 TB/s |
| 直径 | 2 跳 (GPU → NVSwitch → GPU) |
| 为什么 72 | NVSwitch 4.0 端口数 + 散热/功耗约束 |
| vs DGX H100 | 域规模 9×,单 GPU 带宽 2×,断崖 36:1 (vs 18:1) |
| vs CloudMatrix 384 | NVIDIA 选带宽密度,华为选规模 |
| 并行映射 | TP 严格限内部,PP/DP/EP 跨 NVL72 走 IB |
参考资料
- NVIDIA, GB200 NVL72. https://www.nvidia.com/en-us/data-center/gb200-nvl72/
- CoreWeave, nccl-tests Repository. https://github.com/coreweave/nccl-tests
- SemiAnalysis, Huawei AI CloudMatrix 384 — China's Answer to NVIDIA GB200 NVL72, 2025-04-16. https://semianalysis.com/2025/04/16/huawei-ai-cloudmatrix-384-chinas-answer-to-nvidia-gb200-nvl72/
- UB-Mesh: Unified Bus Mesh Architecture. https://arxiv.org/html/2503.20377v1