Torus
直连环面拓扑的结构与带宽特性及其在 Google TPU ICI 上的落地
核心要点:
- $k$-ary $n$-cube 带环绕链路版本,每维 $k$ 节点,$N = k^n$
- 直连网络无交换机,节点自身是路由器
- 度数 $2n$ 固定,链路数 $O(N)$,成本极低
- 割集带宽 $O(N^{(n-1)/n})$,3D Torus 大规模下仅 Fat-tree 21%
- AllReduce 在 Torus 上完美均匀;AllToAll (MoE) 拥塞严重
- 商用唯一大规模应用是 Google TPU;自研芯片集成 ICI 是前提
- TPU v4/v5p/v7 均用 3D Torus + OCS 重构
Torus 的基本结构是什么?
$k$-ary $n$-cube 带环绕链路:每维 $k$ 节点,$n$ 维总 $N = k^n$,每节点在每维与相邻节点相连,首尾相接形成环,见 @fig-topo-torus-2d-3d。
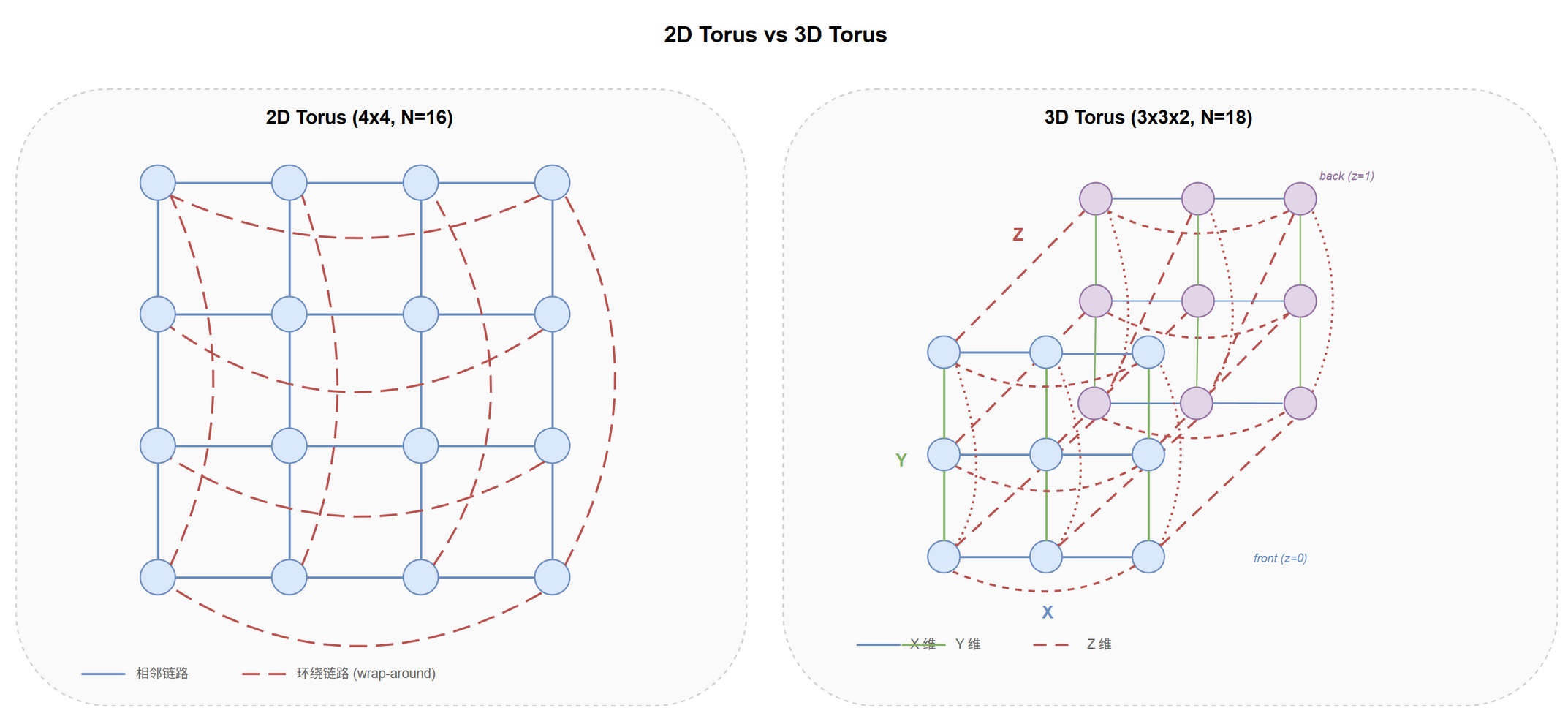
2D Torus 示例:节点排列在 $k \times k$ 网格,每节点与上下左右 4 邻居相连,最左列与最右列相连、最上行与最下行相连,构成"甜甜圈"。
3D Torus:增加第三维,每节点度数 6 (±X, ±Y, ±Z)。
Mesh 和 Torus 的关键差异?
Mesh 无环绕,Torus 有环绕带来割集/直径/均匀性的全面提升:
| Mesh (无环绕) | Torus (有环绕) | |
|---|---|---|
| 边界节点度数 | 低于内部节点 | 与内部一致 |
| Vertex-Transitive | No | Yes |
| 直径 | $n(k-1)$ | $n \cdot \lfloor k/2 \rfloor$ (减半) |
| 割集带宽 | $k^{n-1} \cdot b$ | $2k^{n-1} \cdot b$ (翻倍) |
| 流量分布 | 中心链路承载更多 | 均匀 |
| 布线 | 简单 | 需要长程环绕链路 |
@tbl-topo-torus-mesh Mesh vs Torus
Torus 环绕链路带来三个优势:割集翻倍、直径减半、消除边界效应。代价是环绕链路需要长线缆。
与 Chordal Ring 的关系:2D Torus ($\sqrt{N} \times \sqrt{N}$) 数学上等价于 $CR(N; 1, \sqrt{N})$ — 标准 Ring 加偏移 $\sqrt{N}$ 的弦。$k$ 维 Torus 等价于 $CR(N; 1, s, s^2, \ldots, s^{k-1})$,弦偏移取各维度步长。
关键参数和维度对比
核心问题:Torus 在 1D/2D/3D 下的度数、直径、割集带宽、链路数随维度如何变化?
度数和直径都随维度 $n$ 线性变化 (@tbl-topo-torus-params):
| 属性 | 值 |
|---|---|
| 度数 | $2n$ (所有节点一致) |
| 直径 | $n \cdot \lfloor k/2 \rfloor$ |
| 链路数 | $n \cdot k^n = n \cdot N$ |
| 割集带宽 | $2k^{n-1} \cdot b$ |
| Vertex-Transitive | Yes |
@tbl-topo-torus-params Torus 关键参数
维度对比 (@tbl-topo-torus-dim):
| 维度 | 节点度 | 割集带宽 | 直径 | 链路/节点 |
|---|---|---|---|---|
| 1D (Ring) | 2 | $2b$ | $k/2$ | 1 |
| 2D ($k \times k$) | 4 | $2k \cdot b = 2\sqrt{N} \cdot b$ | $\sqrt{N}$ | 2 |
| 3D ($k^3$) | 6 | $2k^2 \cdot b = 2N^{2/3} \cdot b$ | $\frac{3}{2}N^{1/3}$ | 3 |
@tbl-topo-torus-dim Torus 维度对比
割集带宽随维度提升 $O(N^{(n-1)/n})$,但每增一维节点度数增加 2 (需更多端口)。
Torus vs Fat-tree 带宽-成本权衡?
Torus 用 20-30% 链路换 21-63% 带宽 (@tbl-topo-torus-vs-ft)。
| $N$ | Fat-tree 割集 | 3D Torus 割集 | Torus/FT 比 | Torus/FT 链路比 |
|---|---|---|---|---|
| 256 | $128b$ | $80b$ | 63% | ~30% |
| 1,024 | $512b$ | $204b$ | 40% | ~25% |
| 4,096 | $2,048b$ | $512b$ | 25% | ~20% |
| 8,960 | $4,480b$ | $920b$ | 21% | ~18% |
@tbl-topo-torus-vs-ft Torus vs Fat-tree 带宽-成本权衡
Torus 是"带宽换成本"的工程权衡:割集更低,但链路数仅 Fat-tree 20-30%。
直连网络 vs 间接网络的本质差异
核心问题:Torus 节点自身就是路由器(直连网络),这与 Fat-tree/Dragonfly 等间接网络在成本、多跳、割集扩展上有何根本不同?
Torus 的节点自身就是路由器,无外部交换机。这是与 Fat-tree/Dragonfly 等间接网络的根本区别。
直连优势:
- 无交换机成本 (网络成本可低至 Fat-tree 的 8-20%)
- 节点端口数固定,不随规模变化
- 适合芯片集成 (芯片上内置 ICI 端口)
直连劣势:
- 非邻居通信需多跳转发,每个中间节点都参与转发
- 割集带宽受限于节点度数,无法通过增加交换机扩展
割集随规模为什么衰减?
3D Torus $O(N^{2/3})$ vs Fat-tree $O(N)$。规模越大,差距越大。
$N = 8960$ 时 Torus 割集仅 Fat-tree 21%。这决定了 Torus 在大规模集群上 AllToAll (MoE) 效率远低于 Fat-tree。
路由和死锁怎么处理?
Dimension-Ordered Routing (DOR) + 虚通道破环依赖。
Torus 上标准路由是 DOR,按固定维度顺序逐维修正坐标。Mesh 上 DOR 天然无死锁,但 Torus 环绕链路会形成环依赖,需虚通道或 bubble flow control 打破。详见 DOR 路由。
AllReduce 和 AllToAll 在 Torus 上表现如何?
AllReduce 完美均匀,AllToAll 严重拥塞。
- AllReduce: Dimension-Decomposition 算法将全局 AllReduce 分解为各维 1D Ring AllReduce,每步每条链路恰好一条流,零争用 (详见 AllReduce)
- AllToAll (MoE):流量不规则,Torus 有限割集导致严重拥塞。Google TPU v4 论文报告此瓶颈,通过 Expert 放置策略和 OCS 动态调整部分缓解[1]
- Mesh vs Torus: Mesh 中心链路承载 $O(k)$ 倍流量;Torus 环绕消除不对称
Google TPU 怎么用 Torus?
自研芯片集成 ICI 端口,无外部交换机,全 Pod 同一 Torus (@tbl-topo-torus-tpu)。
| 系统 | 拓扑 | 规模 | 维度配置 | 每芯片 ICI 带宽 |
|---|---|---|---|---|
| TPU v2 | 2D Torus | 256 | 16×16 | 4×500 Gbps |
| TPU v3 | 2D Torus | 1,024 | 32×32 | 4×800 Gbps |
| TPU v4 | 3D Torus | 4,096 | 4×4×4 cube + OCS | ~2.4 Tbps |
| TPU v5p | 3D Torus | 8,960 | 16×20×28 | ~4.8 Tbps |
| Trillium (v6e) | 2D Torus | 256 | 16×16 | ~6.4 Tbps |
| Ironwood (v7) | 3D Torus | 9,216 | 多维 | ~9.6 Tbps |
@tbl-topo-torus-tpu TPU 代际配置[1][2]
代际演进:
- v2/v3: 2D Torus,每芯片 4 个 ICI 端口,适合中等规模 Pod
- v4/v5p: 3D Torus (6 端口),割集从 $O(\sqrt{N})$ 提升到 $O(N^{2/3})$,支撑 4K-9K chips
- Trillium (v6e):回退 2D Torus (256 chips/pod),ICI 带宽大幅提升,大规模扩展交跨 Pod OCS
- Ironwood (v7): 3D Torus,9216 chips,ICI 带宽 ~9.6 Tbps/chip
TPU v4 OCS 层
TPU v4 基本构建块是 4×4×4 cube (64 chips)。Cube 之间通过 OCS 灵活组合,可将 4096 芯片组合为不同形状 Torus (如 4×4×256, 8×8×64, 4×16×64)。
OCS 价值:
- 一物理 SuperPod 可同时服务多个不同形状的逻辑集群
- 可根据工作负载动态调整拓扑 (MoE 用扁平、PP 用长形)
- 故障芯片可通过重配绕开
Google 选 Torus 的理由
- 自研芯片集成 ICI 端口,无需外部交换机,网络成本 <10% TCO
- 所有芯片等地位 (Vertex-Transitive),同一 Torus 贯穿全 Pod,无带宽断崖
- AllReduce 带宽最优 (Dimension-Decomposition 完美均匀)
- AllToAll 瓶颈可部分缓解 (Expert 放置 + OCS)
适用场景与局限
核心问题:Torus 适合和不适合哪些并行策略和部署场景?
适用:
- 自研芯片生态 (集成 ICI 端口构建无交换机直连 Torus)
- PP + DP 为主的并行策略 (AllReduce 最优、PP 维度天然匹配)
- AllToAll 需求低的工作负载 (密集 Transformer 非 MoE)
- 成本极敏感场景 (网络成本约 Fat-tree 8-20%)
局限:
- MoE 全局 AllToAll 在 3D Torus 产生 $O(\sqrt{N})$ 拥塞比
- 割集带宽随规模快速下降 ($N=8960$ 仅 Fat-tree 21%)
- 增量扩展困难 (改维度大小需重新布线)
- 环绕链路长线缆 (跨维度全长,光缆成本和延迟)
- 死锁需虚通道或 bubble flow control
- 商用生态仅 Google TPU,需自研芯片集成 ICI
成本对比
核心问题:Torus 与 Fat-tree 在交换机、链路、端口上的成本差异有多大、带宽/$ 性价比如何?
| 成本项 | Torus | Fat-tree |
|---|---|---|
| 交换机 | 无 (直连) | $5k^2/4$ 台 |
| 链路数 | $n \cdot N$ (线性) | $O(N \log N)$ |
| 每节点端口 | $2n$ (固定) | 取决于交换机 |
@tbl-topo-torus-cost Torus vs Fat-tree 成本
$N = 1024$, 400G 链路:
- Fat-tree 网络成本:~$7.2M
- 3D Torus 网络成本:~$0.6M (无交换机,仅链路)
3D Torus 带宽/$ 性价比是 Fat-tree 的 ~5×,但前提是 AllToAll 需求低且可自研芯片集成 ICI。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 结构 | $k$-ary $n$-cube 带环绕,度数 $2n$,无外部交换机 |
| 割集 | $O(N^{(n-1)/n})$,3D 大规模下仅 Fat-tree 21% |
| 网络成本 | Fat-tree 的 8-20% |
| AllReduce | 完美均匀,零争用 |
| AllToAll (MoE) | 严重拥塞,需 Expert 放置 + OCS 缓解 |
| 路由 | DOR + 虚通道破环依赖 |
| Google TPU | 唯一大规模商用,自研芯片集成 ICI |
| TPU v4 OCS | 让 3D Torus 可重构,多形状逻辑集群 |
| 不可扩展性 | 增量扩展难,改维度需重布线 |
参考资料
- Jouppi N. et al., TPU v4: An Optically Reconfigurable Supercomputer for ML, ISCA 2023. https://arxiv.org/abs/2304.01433
- Google Cloud, TPU v5p Architecture. https://cloud.google.com/tpu/docs/tpu-v5p