AllGather
与 ReduceScatter 对偶的两类聚合算法及 Ring / Recursive Doubling 的适用边界
核心要点:
- 输入:每节点持 $M / N$ 分片;输出:每节点持完整 $M$
- ReduceScatter 对偶 (反转数据流),AllReduce 的后半段
- 延迟下界 $\lceil \log_2 N \rceil \cdot \alpha$,带宽下界 $(N-1) M / (N d \beta)$
- Ring AG 带宽最优 / 延迟 $O(N) \alpha$ 非最优
- Recursive Doubling 同时最优,需 $N = 2^k$ + Hypercube
- LLM 中 SP 前向 / ZeRO-3 权重收集 / TP 是核心用户
语义
核心问题:AllGather 的输入输出和数学语义是什么?与 ReduceScatter 为什么是对偶关系?
节点 $i$ 持 $A_i$ 大小 $M / N$, AllGather 后所有节点持完整拼接:
$$\begin{equation} \forall i \in [0, N): \quad B_i = [A_0, A_1, \ldots, A_{N-1}], \quad |B_i| = M \label{eq:cc-ag-semantic} \end{equation}$$ReduceScatter ↔ AllGather 对偶
| 维度 | AllGather | ReduceScatter |
|---|---|---|
| 输入 / 节点 | $M / N$ | $M$ |
| 输出 / 节点 | $M$ | $M / N$ |
| 数据流 | 分散 → 聚合 | 聚合 → 分散 |
| 操作 | 拼接 | 规约 + 分片 |
@tbl-cc-ag-rs-duality AllGather ↔ ReduceScatter 对偶
反转 AllGather 数据流并加规约即得 ReduceScatter。
AllReduce 分解
$$\begin{equation} \text{AllReduce} = \text{ReduceScatter} + \text{AllGather} \label{eq:cc-ag-ar-decomp} \end{equation}$$Ring AllReduce 正是按此分解实现。独立用 AllGather 通信量是 AllReduce 一半。
理论下界
核心问题:AllGather 延迟与带宽下界?
延迟下界:信息扩散需 $\lceil \log_2 N \rceil$ 步:
$$\begin{equation} T_{\alpha}^{\min} = \lceil \log_2 N \rceil \cdot \alpha \label{eq:cc-ag-delay-lb} \end{equation}$$带宽下界:节点 $i$ 初始 $M / N$,终持 $M$,缺失 $(N-1) M / N$ 必须传入:
$$\begin{equation} R_i = \frac{(N-1) M}{N} \label{eq:cc-ag-recv-budget} \end{equation}$$ $$\begin{equation} T_{\beta}^{\min} = \frac{(N-1) M}{N \cdot d \beta} \label{eq:cc-ag-bw-lb} \end{equation}$$Ring AllGather
核心问题:Ring 上如何达带宽最优,延迟 $O(N) \alpha$ 是否可接受?
每步每节点把上步收到的 chunk 转给下游,同时从上游收一新 chunk,见 。
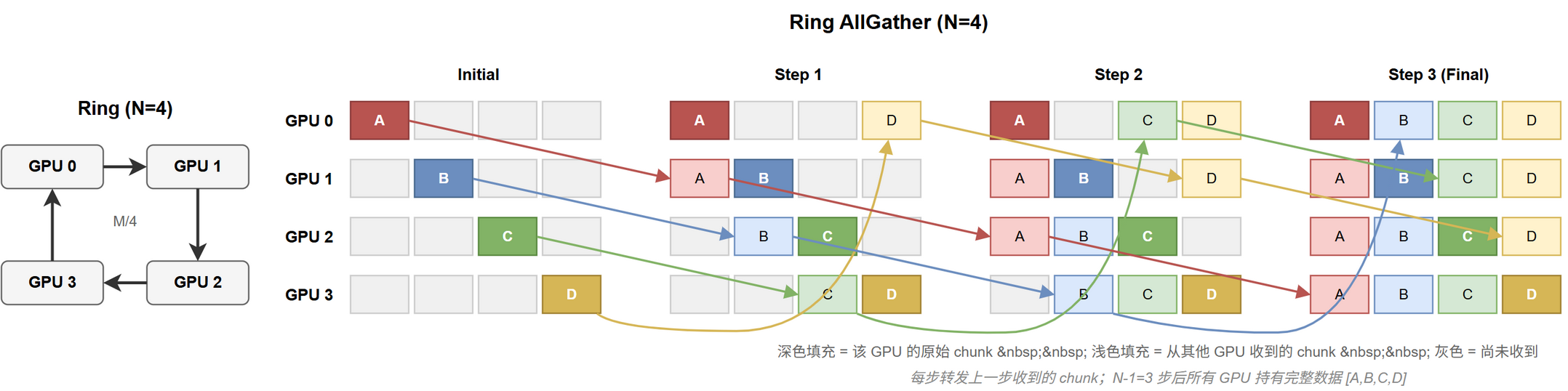
步骤 ($N = 4$)
初始:节点 $i$ 持 chunk $i$。
| 步骤 | Node 0 | Node 1 | Node 2 | Node 3 |
|---|---|---|---|---|
| 初始 | $[A]$ | $[B]$ | $[C]$ | $[D]$ |
| 1 | $[A, D]$ | $[B, A]$ | $[C, B]$ | $[D, C]$ |
| 2 | $[A, D, C]$ | $[B, A, D]$ | $[C, B, A]$ | $[D, C, B]$ |
| 3 | $[A, D, C, B]$ | $[B, A, D, C]$ | $[C, B, A, D]$ | $[D, C, B, A]$ |
@tbl-cc-ag-ring-trace Ring AllGather 步骤 (N=4)
最终各节点持有 chunk 顺序可能不同,但内容相同。
代价
$N - 1$ 步,每步发 / 收 $M / N$:
$$\begin{equation} T_{\text{Ring-AG}} = (N - 1) \cdot \left( \alpha + \frac{M / N}{\beta} \right) = (N-1) \alpha + \frac{(N-1) M}{N \beta} \label{eq:cc-ag-ring} \end{equation}$$带宽项达下界 (单链路 100%),延迟 $O(N) \alpha$ 非最优。
2-port Ring AllGather
双 DMA 同时向两侧推,步数减半:
$$\begin{equation} T_{\text{2-port-Ring-AG}} = \left\lceil \frac{N-1}{2} \right\rceil \cdot \left( \alpha + \frac{M / N}{\beta} \right) \label{eq:cc-ag-2port-ring} \end{equation}$$SCCL 4 芯 Ring 实现
SCCL 把数据按 0 维拆 bulk,流水化 2 次迭代完成 AllGather,单次迭代链路利用率更高。
Recursive Doubling AllGather
核心问题:能否同时达延迟和带宽下界?
每步与距离 $2^{j-1}$ 的对手互换当前持有的全部数据,数据量翻倍。
步骤 ($N = 8$)
| 步骤 | 通信对 | 交换量 | 持有量 / 节点 |
|---|---|---|---|
| 1 | (0,1) (2,3) (4,5) (6,7) | $M / 8$ | $M / 4$ |
| 2 | (0,2) (1,3) (4,6) (5,7) | $M / 4$ | $M / 2$ |
| 3 | (0,4) (1,5) (2,6) (3,7) | $M / 2$ | $M$ |
@tbl-cc-ag-rd-trace Recursive Doubling AG 步骤 (N=8)
第 $j$ 步交换 $2^{j-1} M / N$。
代价
$$\begin{equation} T_{\text{RD-AG}} = \sum_{j=1}^{\log_2 N} \left( \alpha + \frac{2^{j-1} M}{N \beta} \right) \label{eq:cc-ag-rd-full} \end{equation}$$$\sum 2^{j-1} = N - 1$:
$$\begin{equation} T_{\text{RD-AG}} = \log_2 N \cdot \alpha + \frac{(N-1) M}{N \beta} \label{eq:cc-ag-rd} \end{equation}$$同时达延迟与带宽下界。要求 $N = 2^k$,拓扑近似 Hypercube。
Ring 拓扑下退化
Ring 上 Recursive Doubling 的非直连通信对需多跳路由,实际性能可能退化,Ring AG 反而更优。
算法对比
核心问题:Ring、Recursive Doubling、Brucks 三种 AllGather 算法在延迟、带宽、适用场景上如何对比?
| 算法 | 延迟项 | 带宽项 | 延迟最优 | 带宽最优 | 拓扑 |
|---|---|---|---|---|---|
| Ring | $(N-1) \alpha$ | $(N-1) M / (N \beta)$ | 否 | 是 (单链路 100%) | Ring |
| 2-port Ring | $\lceil (N-1) / 2 \rceil \alpha$ | $\lceil (N-1)/2 \rceil M / (N \beta)$ | 否 | 是 (双链路) | 2-port Ring |
| Recursive Doubling | $\log_2 N \cdot \alpha$ | $(N-1) M / (N \beta)$ | 是 | 是 | Hypercube |
@tbl-cc-ag-algo-cmp AllGather 算法对比
多维分层 AllGather
核心问题:实际集群带宽分层,如何减少慢链路通信?
分层框架通用推导见 4.8 AllReduce, AllGather 是其后半段。
分解
$N = \prod p_i$,逐维 AllGather:
$$\begin{equation} \text{Hier-AG}(N) = \text{AG}_0 \to \text{AG}_1 \to \cdots \to \text{AG}_{d-1} \label{eq:cc-ag-hier-decomp} \end{equation}$$每级数据量扩 $p_i$ 倍。设 $P_i = \prod_{j=0}^{i} p_j$:
| 级别 | 输入 / 节点 | 输出 / 节点 |
|---|---|---|
| 0 | $M / N$ | $M p_0 / N$ |
| 1 | $M p_0 / N$ | $M p_0 p_1 / N$ |
| ... | ... | ... |
| $d-1$ | $M / p_{d-1}$ | $M$ |
@tbl-cc-ag-hier-flow 多维分层 AG 各级数据量
代价
$$\begin{equation} T_{\text{multi-dim-AG}} = \sum_{i=0}^{d-1} \left[ (p_i - 1) \alpha_i + \frac{p_i - 1}{p_i} \cdot \frac{M P_i}{N \beta_i} \right] \label{eq:cc-ag-multidim} \end{equation}$$与分层 AllReduce 的关系
分层 AllReduce 完整分解:
$$\begin{equation} \text{AllReduce}(N) = \underbrace{\text{RS}_0 \to \cdots \to \text{RS}_{d-1}}_{\text{分层 ReduceScatter}} \to \underbrace{\text{AG}_{d-1} \to \cdots \to \text{AG}_0}_{\text{分层 AllGather (逆序)}} \label{eq:cc-ag-ar-hier-decomp} \end{equation}$$注意:AllReduce 后半段 AG 是逆序 (外层 → 内层),每级数据量与对应 RS 级相同 $M / P_{i-1}$;独立的分层 AG 是正序。
LLM 中的应用
核心问题:AllGather 在 LLM 训练的 SP/DP 等场景下有哪些典型使用、通信量和规模特征?
Sequence Parallelism (SP)
Transformer 层边界 AG + RS 配对:
- LayerNorm 前:AllGather 收集完整序列
- 执行 LayerNorm / Attention / MLP
- LayerNorm 后:ReduceScatter 重新分片
SP 总通信量与 TP 相当 ($b s h$ 每层),但分两段允许更好的计算 / 通信重叠。
ZeRO Stage 3
权重按节点分片,前 / 反向计算时:
- AllGather 收集完整权重 (前 1 + 反 1 次)
- 计算后丢弃非本节点权重
- ReduceScatter 规约梯度并分片
推理场景 (无反向):每层仅 1 次 AG,通信量为 ZeRO-1 的 $1/3$。
通信量对比
| 并行策略 | 原语 | 每层通信量 |
|---|---|---|
| TP | AllReduce | $b s h$ |
| SP | AG + RS | $b s h$ (各一半) |
| ZeRO-3 | AG + RS | layer_params |
@tbl-cc-ag-llm-traffic LLM 中 AllGather 通信量
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 语义 | 每节点贡献 $M / N$,终持完整 $M$ 拼接 |
| ReduceScatter 对偶 | 反转数据流,不含规约 |
| 延迟下界 | $\lceil \log_2 N \rceil \cdot \alpha$ |
| 带宽下界 | $(N-1) M / (N d \beta)$ |
| Ring AG 性质 | 带宽最优,延迟 $O(N) \alpha$ 非最优 |
| Recursive Doubling | 同时最优,需 $N = 2^k$ + Hypercube |
| Ring 上 RD 退化 | 非直连通信对多跳,性能反不如 Ring |
| LLM 用户 | SP 前向 / ZeRO-3 权重收集 / TP |
@tbl-cc-ag-takeaway AllGather 要点
参考资料
- Korthikanti et al., "Reducing Activation Recomputation in Large Transformer Models", MLSys 2023 — Sequence Parallelism
- Rajbhandari et al., "ZeRO: Memory Optimizations Toward Training Trillion Parameter Models", SC 2020 — ZeRO AllGather 使用
- Chan et al., "Collective Communication: Theory, Practice, and Experience", CCPE 2007
- SCCL Documentation v1.0 (SOPHGO) — AllGather 流水线 bulk 实现