AllToAll
全交换语义与算法对比,以及在 MoE Dispatch / Combine 中的建模
核心要点:
- 语义 = $N \times N$ 数据矩阵转置,每对节点交换独特数据
- 延迟下界 $(N-1) \alpha$,带宽下界 $(N-1) M / (N d \beta)$
- Bisection 下界 $N M / (4 B_{\text{bisection}})$, Ring / Torus 上常成主约束
- Pairwise / Ring 同时达延迟与带宽下界 (单端口);Bruck 延迟 $O(\log N)$ 但带宽劣
- 工业 NCCL 用 P2P Direct,硬件调度并发,全连接拓扑 1 步
- MoE Dispatch / Combine 是非均匀 AllToAll,由 max-load 节点钳制
语义
核心问题:AllToAll 的输入输出和数学语义是什么?为什么它是 MoE EP 通信的核心原语?
节点 $i$ 持 $[D_i^{(0)}, \ldots, D_i^{(N-1)}]$,其中 $D_i^{(j)}$ 发往 $j$:
$$\begin{equation} \forall j \in [0, N): \quad B_j = [D_0^{(j)}, D_1^{(j)}, \ldots, D_{N-1}^{(j)}] \label{eq:cc-a2a-semantic} \end{equation}$$直观:输入是 $N \times N$ 数据矩阵,AllToAll 执行矩阵转置 — 行分布变列分布。
与其他原语的区别
| 原语 | 每节点发送 | 每节点接收 |
|---|---|---|
| AllGather | 相同数据给所有人 | 所有人的不同数据 |
| AllReduce | 不同数据 (被规约) | 相同结果 |
| AllToAll | 不同数据给不同人 | 不同人的不同数据 |
@tbl-cc-a2a-vs-others AllToAll 与其他原语对比
AllToAll 是唯一每对节点交换独特数据的原语,也是通信量最大的原语。
理论下界
核心问题:AllToAll 三类下界 (延迟 / 节点带宽 / bisection) 哪个最紧?
延迟下界
每节点需与其他 $N-1$ 节点各换一次独特数据,不能通过中间节点合并:
$$\begin{equation} T_{\alpha}^{\min} = (N-1) \cdot \alpha \label{eq:cc-a2a-delay-lb} \end{equation}$$与 AllReduce 区别:AllReduce 下界 $\lceil \log_2 N \rceil \alpha$ 因为信息可中间合并;AllToAll 每对独特数据不能合并,下界 $O(N)$。
节点级带宽下界
设每对节点间 $m = M / N$ 字节,每节点共发 / 收 $(N-1) m$:
$$\begin{equation} S_i = R_i = \frac{(N-1) M}{N} \label{eq:cc-a2a-budget} \end{equation}$$ $$\begin{equation} T_{\beta}^{\min} = \frac{(N-1) M}{N \cdot d \beta} \label{eq:alltoall-bw-lower-bound} \end{equation}$$Bisection 下界 (低带宽拓扑常更紧)
对半切 $A / B$ 各 $N/2$ 节点,跨切线总数据量 $N^2 m / 4 = N M / 4$:
$$\begin{equation} T_{\text{bisection}} = \frac{N M}{4 B_{\text{bisection}}} \label{eq:cc-a2a-bisection-lb} \end{equation}$$Ring 上 $B_{\text{bisection}} = 2 \beta$,故 $T_{\text{bisection}} = N M / (8 \beta)$, $N$ 大时比节点级下界紧。
MoE Dispatch / Combine:非均匀 AllToAll
MoE 路由不均匀,由最重节点决定下界:
$$\begin{equation} T_{\beta}^{\min}(\text{Dispatch}) \ge \max_j \frac{R_j}{d \beta} \label{eq:cc-a2a-dispatch-lb} \end{equation}$$均匀路由下退化为标准 $(N-1) M / (N \beta)$。
Expert capacity 钳制:设 Capacity Factor $C$ ($C = 1.0$ 无冗余,$C = 1.25$ 25% 余量):
$$\begin{equation} \text{capacity}_j = C \cdot \frac{B K}{E} \label{eq:cc-a2a-expert-capacity} \end{equation}$$$B$ batch token 数,$K$ top-K, $E$ Expert 总数。严重不均时 $R_j \to C \cdot B K h \cdot \text{dtype} / E$,远高于均匀。
算法一:Pairwise Exchange
核心问题:最直观的 $N-1$ 轮配对能否达带宽下界?
调度
Round-robin 配对,第 $r$ 轮节点 $i$ 与 $(i + r) \bmod N$ 换数据:
| 轮 ($N=4$) | Node 0 | Node 1 | Node 2 | Node 3 |
|---|---|---|---|---|
| 1 | 1 | 0 | 3 | 2 |
| 2 | 2 | 3 | 0 | 1 |
| 3 | 3 | 2 | 1 | 0 |
@tbl-cc-a2a-pairwise-trace Pairwise 调度 (N=4)
代价
$N-1$ 轮,每轮换 $M / N$:
$$\begin{equation} T_{\text{pairwise}} = (N - 1) \alpha + \frac{(N - 1) M}{N \beta} \label{eq:cc-a2a-pairwise} \end{equation}$$单端口模型下同时达延迟与带宽下界。完全图无冲突;Ring 上远距离配对需多跳,可能竞争。
算法二:Ring AllToAll
核心问题:Ring 拓扑上 AllToAll 怎么避免远距离冲突?
$N-1$ 步,每步所有节点同时向右邻发 + 左邻收,相当于 $N$ 个 Scatter 并行。
步骤 ($N = 4$)
| 步 | Node 0 发 | Node 0 收 |
|---|---|---|
| 1 | $D_0^{(1)}$ → 1 | $D_3^{(0)}$ from 3 |
| 2 | $D_0^{(2)}$ → 1 (转发) | $D_2^{(0)}$ (3 转发) |
| 3 | $D_0^{(3)}$ → 1 (转发) | $D_1^{(0)}$ (两跳) |
@tbl-cc-a2a-ring-trace Ring AllToAll 步骤 (N=4)
代价
$$\begin{equation} T_{\text{Ring-A2A}} = (N - 1) \alpha + \frac{(N - 1) M}{N \beta} \label{eq:cc-a2a-ring} \end{equation}$$与 Pairwise 同,但只用相邻链路无冲突。SCCL 实现把 AllToAll 用 $N$ 个并行 Scatter 表达。
算法三:Bruck (小消息延迟优先)
核心问题:$N-1$ 步对小消息太慢,能否压到 $O(\log N)$?
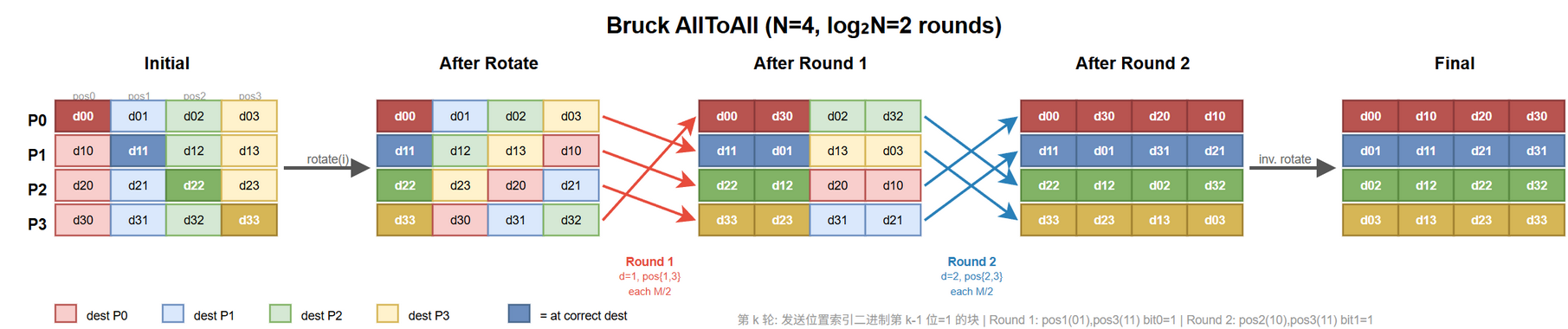
算法
$\lceil \log_2 N \rceil$ 步,第 $j$ 步:
- 节点 $i$ 向 $(i + 2^j) \bmod N$ 发尚未到达目标的所有 chunk
- 从 $(i - 2^j) \bmod N$ 收
- 本地重排
代价
$$\begin{equation} T_{\text{Bruck}} = \lceil \log_2 N \rceil \cdot \alpha + \lceil \log_2 N \rceil \cdot \frac{(N - 1) m}{2 \beta} + (N - 1) t_{\text{copy}} \label{eq:cc-a2a-bruck} \end{equation}$$延迟最优 ($O(\log N)$),带宽项 $\lceil \log_2 N \rceil \cdot (N-1) m / (2 \beta)$,总带宽是 Pairwise 的 $\lceil \log_2 N \rceil / 2$ 倍,非最优。
切换点
$$\begin{equation} m^* \approx \frac{(N - 1) \alpha \beta}{\lceil \log_2 N \rceil - 1} \label{eq:cc-a2a-bruck-crossover} \end{equation}$$$m < m^*$ 用 Bruck,否则 Pairwise。
算法四:NCCL P2P Direct (工业默认)
核心问题:现代 GPU 集群硬件已有 NVSwitch 全连接 + 多 NIC,软件何必算法精细调度?
实现
$N (N-1)$ 对 P2P send / recv 全部入队,硬件并发调度:
ncclGroupStart()
for j in range(N):
if j != rank:
ncclSend(sendbuf[j], count, peer=j)
ncclRecv(recvbuf[j], count, peer=j)
ncclGroupEnd()
没有"轮次"概念 — 硬件有多少并发就用多少。NVSwitch 内所有 send / recv 同时执行,跨节点受 NIC + IB 钳制,引擎自动排队。
PXN 优化
NCCL 2.12 引入 PXN (PCIe × NVLink):GPU 需远端 NIC 时先经 NVLink 送到直连 NIC 的 GPU 再发,避开 PCIe 瓶颈,实测 AllToAll 跨节点性能 > 2× 提升。
代价
全连接 (NVSwitch) 下:
$$\begin{equation} T_{\text{P2P-Direct}} = \alpha + \frac{(N - 1) M}{N \cdot d \beta} \label{eq:cc-a2a-p2p-direct} \end{equation}$$仅 1 步启动延迟,带宽达下界。非全连接拓扑上多跳与竞争会退化。
与结构化算法对比
| 维度 | 结构化 (Pairwise / Bruck) | P2P Direct |
|---|---|---|
| 调度 | 算法定义严格配对 | 硬件引擎自由调度 |
| 链路冲突 | 算法保证无冲突 (Ring) | 硬件仲裁,大 $N$ 可能拥塞 |
| 延迟 | $O(N)$ 或 $O(\log N)$ 步 | 理论 1 步 |
| 适用 | 特定拓扑最优 | 全连接最优 |
@tbl-cc-a2a-structured-vs-p2p 结构化算法 vs P2P Direct
算法对比
核心问题:Pairwise/Ring/Bruck/NCCL P2P Direct 四种 AllToAll 算法在延迟、带宽、适用场景上如何对比?
| 算法 | 步数 | 延迟项 | 带宽项 | 适用 |
|---|---|---|---|---|
| Pairwise | $N-1$ | $(N-1) \alpha$ | $(N-1) M / (N \beta)$ | 大消息,完全图 |
| Ring | $N-1$ | $(N-1) \alpha$ | $(N-1) M / (N \beta)$ | 大消息,Ring |
| Bruck | $\lceil \log_2 N \rceil$ | $\lceil \log_2 N \rceil \alpha$ | $\lceil \log_2 N \rceil (N-1) m / (2 \beta)$ | 小消息 |
| P2P Direct | 1 (并发) | $\alpha$ | $(N-1) M / (N d \beta)$ | 全连接 (NVSwitch) |
@tbl-cc-a2a-algo-cmp AllToAll 算法对比
MoE 场景下的 AllToAll
核心问题:MoE Dispatch / Combine 为何不能直接复用标准算法?
两次 AllToAll 的位置
$$\begin{equation} \text{MoE Forward} = \text{Router} \to \text{Dispatch A2A} \to \text{Expert Compute} \to \text{Combine A2A} \label{eq:cc-a2a-moe-forward} \end{equation}$$- Dispatch:每芯片把本地 token 按路由发往持目标 Expert 的芯片
- Combine: Expert 计算后结果按原 token 归属返回源芯片
Dispatch / Compute / Combine 数据流
EP=4 (4 芯,8 Expert, top-2) 见 。
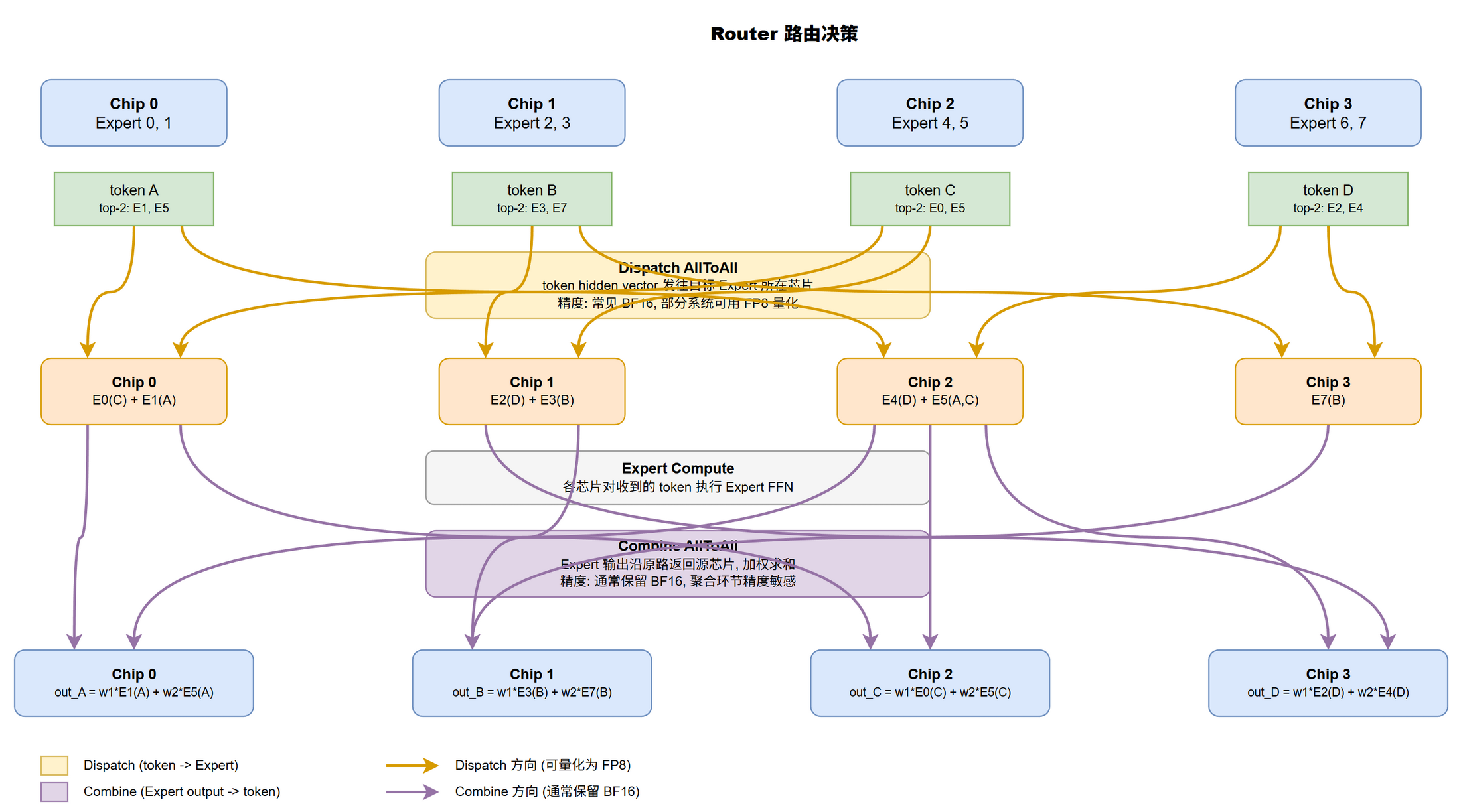
- Dispatch: Router 本地算路由分数,token A 在 Chip 0, Router 选 Expert 1 (Chip 0 本地) 与 Expert 5 (Chip 2),故 Chip 0 → Chip 2 发 token A 的 hidden vector
- Compute:每芯片对收到 token 跑对应 Expert FFN,纯本地无通信。负载不均:Chip 2 收 3 token (A, C, D), Chip 3 仅收 1 (B)
- Combine:沿原路返回,通信矩阵是 Dispatch 的转置 $C^T[j][i]$。源芯片按 gate 权重加权求和:$\text{output}_A = w_1 E_1(A) + w_2 E_5(A)$
Dispatch vs Combine 对比
| 维度 | Dispatch | Combine |
|---|---|---|
| 方向 | token → Expert 芯片 | Expert 输出 → 源芯片 |
| 通信矩阵 | $C[i][j]$ | $C^T[j][i]$ |
| 数据内容 | token hidden vector | Expert FFN 输出 |
| 不均匀性 | 由路由决定 | 同 Dispatch |
| 可重叠性 | 可与上层 Combine 流水 | MoE 层尾,对尾延迟敏感 |
@tbl-cc-a2a-dispatch-vs-combine MoE Dispatch / Combine 对比
精度差异:对称 vs 非对称
对称精度 (GShard, Switch Transformer, Megatron-LM): Dispatch / Combine 同 BF16 / FP16, FP8 只用于 Expert GEMM。
非对称精度 (DeepSeek-V3): Dispatch FP8 (E4M3), Combine BF16。DeepEP use_fp8_dispatch 参数控制此设计。
非对称背后:
- Dispatch 可量化:发的是 Expert 输入 activation, Expert 本就支 FP8 GEMM,通信前提前量化,通信量减半且无额外开销
- Combine 需高精度:加权求和 $\sum w_i E_i(x)$ 误差叠加,且直入 residual stream 累积传播
DeepSeek-V3 ($h = 7168$, BF16=2B, FP8=1B) 每 token: Dispatch 7168 B, Combine 14336 B, Combine 是 Dispatch 2×。
通信量估算
EP 组内总通信量:
$$\begin{equation} M_{\text{total}} = B \cdot K \cdot h \cdot \text{dtype\_size} \label{eq:cc-a2a-moe-total} \end{equation}$$均匀路由下每对芯片:
$$\begin{equation} m_{\text{pair}} = \frac{B K h \cdot \text{dtype\_size}}{N^2} \label{eq:cc-a2a-moe-pair} \end{equation}$$| 配置 | $B$ | $K$ | $h$ | $N$ | 每芯片发送 | 每对 (均匀) | 规模 |
|---|---|---|---|---|---|---|---|
| DeepSeek-V3, EP=64 | 4096 | 8 | 7168 | 64 | 7.3 MB | 117 KB | 中 |
| DeepSeek-V3, EP=8 | 4096 | 8 | 7168 | 8 | 58.7 MB | 7.3 MB | 大 |
@tbl-cc-a2a-moe-traffic MoE AllToAll 通信量估算
EP 大 → 每对小 → Bruck 占优;EP 小 → 每对大 → Pairwise 占优。非对称精度时 Combine $\text{dtype\_size}$ 翻倍。
与标准 AllToAll 的区别
- 通信量不均匀:标准假设 $M / N$ 均匀,MoE 由 top-K 路由钳制
- 并发 dispatch:标准按步骤有序;MoE 所有芯片同时发往多目标,产生链路竞争
MoE 路由 / 通信矩阵 / 负载均衡详见 专家并行 (EP)。
AllToAllv:变长 AllToAll
核心问题:MoE 路由产生不均匀通信,标准 AllToAll 不适用,如何描述?
用 $N \times N$ 通信矩阵 $C[i][j]$ 完整描述,$C[i][j]$ 表节点 $i$ 向 $j$ 发字节数。标准 AllToAll 是 $C[i][j] = M / N$ ($i \ne j$) 的特例。
稀疏跳过
$C[i][j] = 0$ 时该对直接跳过。Pairwise 天然支持:零通信对在该轮跳过,节省带宽 + 延迟。EP=64 + 小 batch 下矩阵可能 30–60% 稀疏。
代价下界
$$\begin{equation} T_{\text{AllToAllv}} \ge \max_i \frac{\sum_{j \ne i} C[i][j]}{d \beta} \label{eq:cc-a2a-v-lb} \end{equation}$$均匀退化到 $\eqref{eq:alltoall-bw-lower-bound}$。
拓扑感知优化
核心问题:如何利用 AllToAll 的拓扑感知优化(如 NCCL 的 PXN/NVLS)减少跨节点带宽瓶颈?
2D Torus 分层 AllToAll
行内 → 本地 transpose → 列内:
$$\begin{equation} T_{\text{2D-A2A}} = T_{\text{row-A2A}} + T_{\text{transpose}} + T_{\text{col-A2A}} \label{eq:cc-a2a-2d-torus} \end{equation}$$拓扑感知 Expert 放置
核心思路:频繁互访的 Expert 放在物理邻近芯片,大流量走高带宽本地链路,少流量走慢链路。
2D / 3D Torus 上 AllToAll 拥塞比 $O(\sqrt{N})$,远高于全连接的 $O(1)$。将热门 Expert 集中放置在 Torus 同行 / 列,大部分流量限本地链路。
Google TPU v4 OCS:用光电路交换动态重配 3D Torus 物理连接,让物理拓扑适应通信而非反过来。
DeepEP:节点限制路由
DeepSeek 开源 DeepEP (2025),核心:每 token 最多 $M = 4$ 节点 (每节点 8 GPU)。两层分级:
- 跨节点段:走 IB (低带宽),每 token 最多 $M$ 目标节点,流量受限
- 节点内段:走 NVLink (远高于 IB),转发开销极小
把 $N$ rank 问题缩为 $N / G$ 节点问题 ($G$ = 每节点 GPU 数),大幅减 IB 流量。
双模式:
| 模式 | 机制 | 适用 |
|---|---|---|
| 低延迟 | NVSHMEM GPU 直接内存访问,绕 CPU | Prefill,小 batch,延迟敏感 |
| 高吞吐 | 分块传输 + Expert 计算重叠 | Decode,大 batch,吞吐优先 |
@tbl-cc-a2a-deepep-modes DeepEP 双模式
详细路由约束见 专家并行 (EP)。
计算 / 通信重叠 (Chunked Overlap)
核心问题:AllToAll 在 MoE 关键路径上难重叠,怎么办?
分块流水:Dispatch 切 $K$ chunk,第 1 个到达就开始 Expert 计算,后续 chunk 继续传:
时间 →
Chip A: [dispatch c1] [dispatch c2] [dispatch c3]
Chip B: [recv c1][expert c1] [recv c2][expert c2] [recv c3][expert c3]
[combine c1] ...
理想端到端:
$$\begin{equation} T_{\text{overlap}} \approx \max(T_{\text{dispatch}}, T_{\text{compute}}) + T_{\text{combine-tail}} \label{eq:cc-a2a-chunked-overlap} \end{equation}$$权衡:每 chunk 一次 $\alpha$,太小启动主导 / 太大重叠效果差。最优 chunk 数取决于 $\alpha / \beta$ 与 Expert 计算时间。DeepEP 高吞吐模式即此。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 语义 | $N \times N$ 矩阵转置 |
| 延迟下界 | $(N-1) \alpha$,不能中间合并 |
| 带宽下界 | $(N-1) M / (N d \beta)$ |
| Bisection 下界 | $N M / (4 B_{\text{bisection}})$,低割集拓扑常更紧 |
| Pairwise / Ring | 同时达延迟与带宽下界 |
| Bruck | 延迟 $O(\log N)$,带宽劣 |
| NCCL P2P Direct | 工业默认,硬件并发调度,全连接 1 步 |
| MoE 非均匀 | 由 max-load 节点钳制,非平均 |
| Dispatch / Combine 精度 | 可非对称,FP8 Dispatch + BF16 Combine |
| AllToAllv | 用 $C[i][j]$ 描述,稀疏可跳过 |
| 拓扑优化 | 分层 / Expert 放置 / OCS / DeepEP 节点限制 |
| Chunked overlap | 把 Dispatch / Expert / Combine 流水化 |
@tbl-cc-a2a-takeaway AllToAll 要点
参考资料
- Bruck et al., "Efficient Algorithms for All-to-All Communications", TPDS 1997 — Bruck $O(\log N)$
- Thakur et al., "Optimization of Collective Communication Operations in MPICH", IJHPCA 2005
- NCCL Source Code — P2P Direct, PXN
- Fedus et al., "Switch Transformers", JMLR 2022 — MoE AllToAll 用法
- Lepikhin et al., "GShard", ICLR 2021 — Expert Capacity / Token Drop
- DeepSeek-V3 Technical Report, DeepSeek 2024 — 节点限制路由
- DeepEP, DeepSeek 2025 — 低延迟 / 高吞吐双模式
- Jouppi et al., "TPU v4", ISCA 2023 — OCS 3D Torus AllToAll
- SCCL Documentation v1.0 (SOPHGO)