NVLS
NVSwitch 网内规约如何打破 Ring 带宽下界及其适用边界
核心要点:
- NVLS 把规约从 GPU 软件层下沉到 NVSwitch 芯片内归约引擎
- 每 GPU 仅 1 次发 + 1 次收,总传输量 $M$ (Ring 是 $2 (N-1) M / N \approx 2 M$)
- 步数固定 2 步,延迟与 $N$ 无关
- H100 NVL72 实测 480 GB/s, 超 Ring 理论上限 ~8%
- 仅适用 NVSwitch 全连接域 (NVL8 / NVL72),多节点跨 IB 不行
- 当前只支 AllReduce,不支 RS / AG 独立加速
NVSwitch 硬件细节见 1.3 NVSwitch + NVLS,本文聚焦算法视角与建模影响,见 。
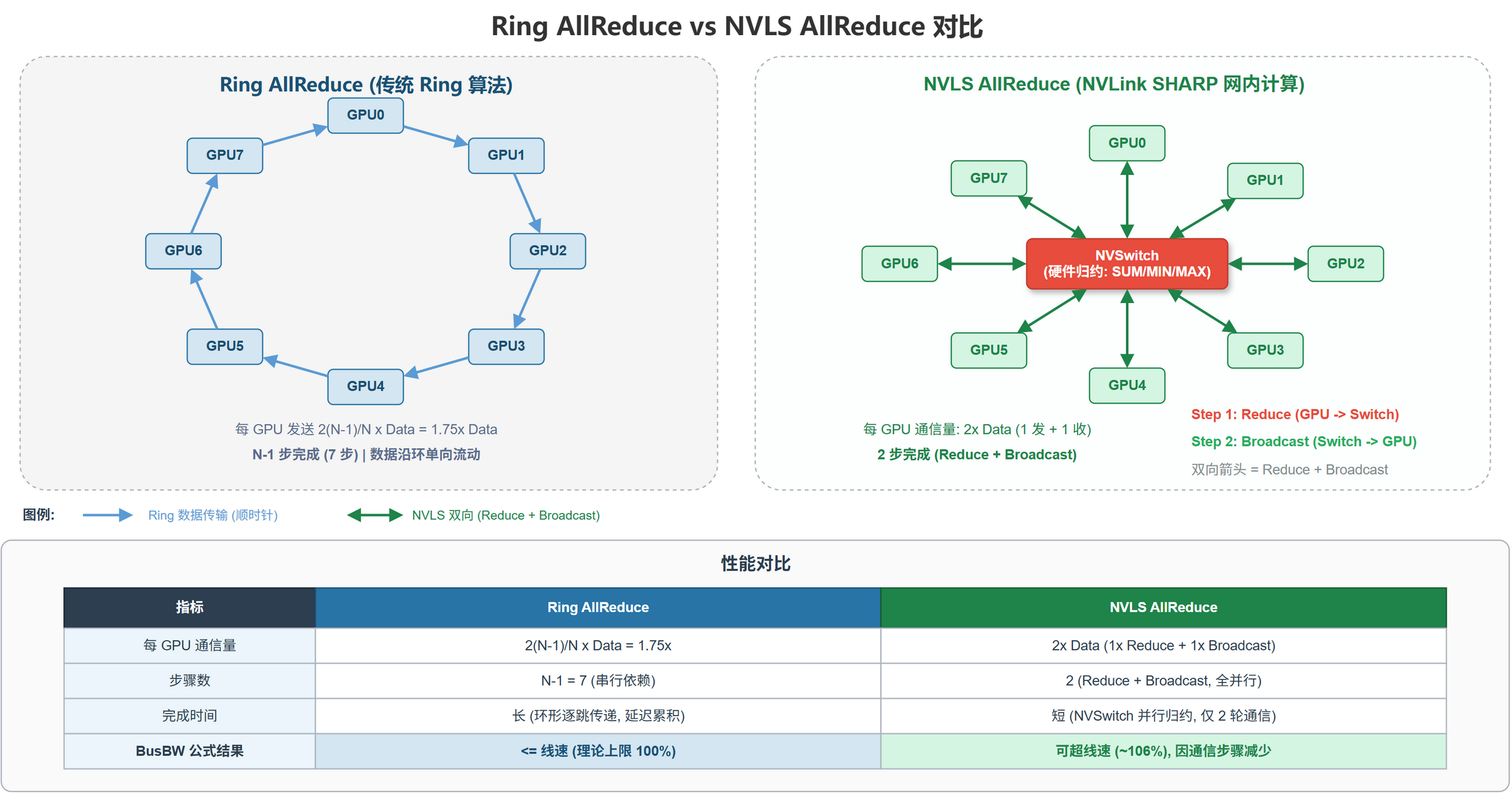
为什么 Ring 还不够
核心问题:Ring 是带宽最优,为什么还需要 NVLS?
Ring 在 Ring 拓扑下带宽最优,但有两个固有限制:
- 步数 $O(N)$: $2 (N-1)$ 步,每步引入 $\alpha$,大规模延迟项不可忽略
- 总传输量 $\approx 2 M$: $\frac{2 (N-1)}{N} M$, RS 一次 + AG 一次,每份数据走两遍
Ring 的"带宽最优"是相对 Ring 拓扑约束的结论。NVSwitch 全连接 + 硬件归约改变了约束。
NVLS 机制
核心问题:如何让 GPU 只发收一次,把规约扔给交换机?
两阶段
- 发送:每 GPU 把本地 $A_i$ ($M$ 字节) 发给 NVSwitch, NVSwitch 流水线累加所有输入
- 接收:NVSwitch 多播规约结果 $\bigoplus A_i$ 同时分发给所有 GPU
整个过程对每 GPU 而言只 1 发 + 1 收,数据不经过任何 GPU 中转。
角色变化
| 模型 | GPU 角色 |
|---|---|
| Ring | 数据源 + 中继节点 (转发 + 规约) |
| NVLS | 数据源 + 接收方 (无中继) |
@tbl-cc-nvls-role NVLS 中 GPU 角色变化
本质:把 Reduction 从软件层下沉到网络硬件层,与 InfiniBand SHARP 同设计哲学,实现在 NVLink 专有硬件上,延迟更低 / 带宽更高。
与 Ring 的代价对比
核心问题:NVLS 与 Ring AllReduce 在延迟、带宽、GPU 开销三个维度的代价差异有多大?
公式
Ring AllReduce:
$$\begin{equation} T_{\text{Ring}} = 2 (N - 1) \alpha + \frac{2 (N - 1)}{N} \cdot \frac{M}{\beta} \label{eq:cc-nvls-ring-cost} \end{equation}$$NVLS AllReduce ($\alpha_{\text{sw}}$ = NVSwitch 归约引擎处理延迟,~100–200 ns):
$$\begin{equation} T_{\text{NVLS}} = 2 \alpha_{\text{sw}} + \frac{M}{\beta_{\text{NVLink}}} \label{eq:cc-nvls-cost} \end{equation}$$NVLS 带宽项系数 1, Ring 是 $2 (N-1) / N \approx 2$,相同链路带宽下 NVLS 有效吞吐量约 Ring 2×。
算法指标对比
| 指标 | Ring AllReduce | NVLS AllReduce |
|---|---|---|
| 每 GPU 发送量 | $\frac{2 (N-1)}{N} M$ | $M$ |
| 每 GPU 接收量 | $\frac{2 (N-1)}{N} M$ | $M$ (多播) |
| 步数 | $2 (N - 1)$ | 2 (与 $N$ 无关) |
| 延迟项 | $2 (N-1) \alpha$ | $2 \alpha_{\text{sw}}$ ≈ 常数 |
| 带宽利用率 | $(N-1) / N$ < 100% | ≈ 100% |
| 规模扩展性 | 延迟随 $N$ 线性恶化 | 延迟与 $N$ 无关 |
@tbl-cc-nvls-vs-ring Ring vs NVLS 算法指标
H100 NVL72 实测 (1 GB 消息)
| 算法 | 实测带宽 | 说明 |
|---|---|---|
| Ring | ~394 GB/s | 理论上限 $71/72 \times 450 \approx 443$,软件开销下偏 |
| NVLS | ~480 GB/s | 超 Ring 理论上限 ~8% |
@tbl-cc-nvls-h100-bench H100 NVL72 实测对比
NVLS 实测超过 Ring 的理论上限,证明突破的不是工程实现,而是算法层面的带宽约束。
适用规模与限制
核心问题:NVLS 什么时候能用、什么时候 fallback?
适用场景
- NVL8:单节点 8 GPU 全连接 NVSwitch
- NVL72: 72 H100 + 9 NVSwitch 单域,NVLS 效果最显著 (规模大 → Ring $O(N)$ 延迟最劣)
必要条件:所有参与 GPU 到任意 NVSwitch 都 1 跳,保证 NVSwitch 能收到所有数据一次性归约。
不适用场景
- 多节点跨 IB / Ethernet:跨节点流量不经 NVSwitch, NCCL 自动回退 Ring 或 DBT
- 异构拓扑:部分 GPU 在 NVSwitch 域、部分 PCIe,整组无法启 NVLS
原语限制
当前 NVLS 仅支 AllReduce, RS / AG 独立加速尚未在 NVSwitch 3.0 实现:
- TP AllReduce (梯度同步) 可受益
- SP 的 AG / RS 暂时无法用 NVLS
消息大小阈值:NCCL 2.17+ 在 $M > 256$ KB 时启 NVLS,小消息 ($< 64$ KB) 软件启动开销主导,差异不显著。
对通信建模的影响
核心问题:沿用 Ring 的 $\alpha$-$\beta$ 模型会出什么错?
传统模型失效
标准 $\alpha$-$\beta$ 把 AllReduce 建模为:
$$\begin{equation} T = \alpha_{\text{steps}} + \frac{M}{\beta_{\text{eff}}} \label{eq:cc-nvls-alpha-beta} \end{equation}$$Ring 下 $\beta_{\text{eff}} = N / (2 (N - 1)) \cdot \beta_{\text{link}}$。
NVLS 下必须去掉 $N / (2 (N-1))$ 系数:
$$\begin{equation} \beta_{\text{eff}}^{\text{NVLS}} \approx \beta_{\text{NVLink}} \label{eq:cc-nvls-eff-bw} \end{equation}$$沿用 Ring 模型将系统性低估 NVLS 带宽约 2× (大规模时),通信时间预测偏保守,MFU 估算偏低。
区域划分建模
| 通信域 | 判断条件 | AllReduce 模型 |
|---|---|---|
| NVLS 域内 | 同 NVSwitch 全连接域 + $M > 256$ KB | $T = 2 \alpha_{\text{sw}} + M / \beta_{\text{NVLink}}$ |
| 跨域 (Ring 回退) | 多节点 / PCIe / 消息过小 | $T = 2 (N-1) \alpha + 2 (N-1) / N \cdot M / \beta$ |
@tbl-cc-nvls-modeling-split 通信建模分域
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 机制 | 规约下沉到 NVSwitch 内,GPU 仅 1 发 + 1 收 |
| 带宽项系数 | 1 (Ring 是 $\approx 2$),总传输量 $M$ |
| 步数 | 固定 2,与 $N$ 无关 |
| 实测 | H100 NVL72 480 GB/s,超 Ring 理论上限 |
| 必要条件 | NVSwitch 全连接 1 跳 |
| 原语支持 | 仅 AllReduce, RS / AG 暂未支持 |
| 建模分域 | 域内用 NVLS 公式,域外回退 Ring |
| 沿用 Ring 模型的代价 | 系统性低估 NVLS 域 2× |
@tbl-cc-nvls-takeaway NVLS 要点
参考资料
- NCCL Documentation: NVLS Algorithm, NVIDIA
- NVIDIA H100 NVL72 Performance Analysis, NVIDIA Developer Blog
- In-Network Computing: A Survey, ACM Computing Surveys 2021 — SHARP / NVLS 综述
- NVSwitch 3.0 Architecture Brief, NVIDIA 2022
- 4.8 AllReduce — Ring / HD / DBT 算法详解