Hybrid Attention
三种注意力机制交错堆叠,将 1M 上下文 KV cache 压缩至 V3.2 的 10%
核心要点:
- 两个维度优化:压缩 (减少 KV entry 总数) + 稀疏 (top-k 选择),V4 把两者交错堆叠
- CSA: 4× 压缩 + top-k 稀疏,抓中距细粒度依赖,Pro top-k=1024 / Flash top-k=512
- HCA: 128× 压缩 dense,抓超长粗粒度依赖
- SWA:未压缩局部窗口 ($n_{\text{win}}=128$),作为分支或前 2 层独占
- Lightning Indexer:低秩 query + ReLU 加权 + 共享 latent,便宜的稀疏选择
- 效率结果:V4-Pro 1M 上下文 KV cache 约 V3.2 的 10% / 单 token FLOPs 27%
DeepSeek V4 把注意力层分成三种交错堆叠 — Compressed Sparse Attention (CSA) / Heavily Compressed Attention (HCA) / Sliding Window Attention (SWA)。这是 V4 把 KV cache 压缩到 V3.2 的 10% 以下、单 token 推理 FLOPs 压到 27% 的核心来源。
与 06 实现卷的分工:本篇是 V4 案例——讲 V4 怎么配置、堆叠这三类注意力、组织推理 KV 布局。通用算子机制的主词条(SSOT)在 06 注意力机制实现卷:compressor 序列压缩见 09-序列压缩注意力、lightning indexer + top-k 见 08-动态稀疏选择、MLA 维度压缩见 10-维度压缩 MLA。本篇涉及这些机制时聚焦 V4 特定实现(overlap transform、flash compressor、C4/C128 配置、层堆叠、推理布局)。
为什么需要混合注意力
核心问题:1M 上下文下 dense attention 不可承受,哪些优化路径互补?
1M token 上下文下,标准 dense attention 的 $O(S^2)$ 计算量和 $O(S)$ 累计 KV cache 都是不可承受的。优化路径有两个互补维度:
| 维度 | 含义 | V4 中的实现 |
|---|---|---|
| 压缩 (Compression) | 减少 KV entry 总数:把 $m$ 个连续 token 合并成 1 个 KV | CSA: $m=4$; HCA: $m'=128$ |
| 稀疏 (Sparsity) | 每个 query 只看部分 KV: top-k 选择 | CSA: top-$k=512/1024$; HCA 不稀疏 |
@tbl-dsv4-attn-compress-vs-sparse 注意力优化的两个维度:压缩与稀疏
V4 的设计选择:
- CSA:同时做压缩 (4×) + 稀疏 (top-k),保留更多局部细节,但单 entry 代价更高
- HCA:仅做激进压缩 (128×),不做稀疏 (所有压缩 entry 都参与 attention)
- SWA:完全不压缩,但只看最近 $n_{\text{win}}=128$ 个 token;以两种形态出现 — 作为 CSA / HCA 层内并联的"局部增强分支",或作为前 2 层独占的注意力层 (仅 V4-Flash)
- 前 2 层注意力类型:V4-Flash 用纯 SWA (保留 token 级 dense 局部信息);V4-Pro 用 HCA (不带 CSA / 不带 SWA 局部分支)。后续层两个变体一致 — CSA / HCA 交错
这种混合让网络能在不同 block 上选择合适的远近粒度:CSA 抓中等距离细粒度依赖,HCA 抓超长距离粗粒度依赖,SWA 抓最近精细依赖。
CSA 怎么把 KV 压缩并稀疏选择
核心问题:CSA 的 4 个步骤怎么从原始 hidden states 一路走到 attention 输出?
CSA 在论文中是核心创新,由四个步骤组成:Token-Level Compressor → Lightning Indexer → Top-k Selection → Shared KV MQA → Grouped Output Projection。
compressor 的 softmax 加权池化、lightning indexer 的 ReLU 打分等通用机制原理见 06 实现卷(09 序列压缩 / 08 动态稀疏);下面聚焦 V4 的具体实现(overlap / flash compressor / Pro-Flash 配置)。
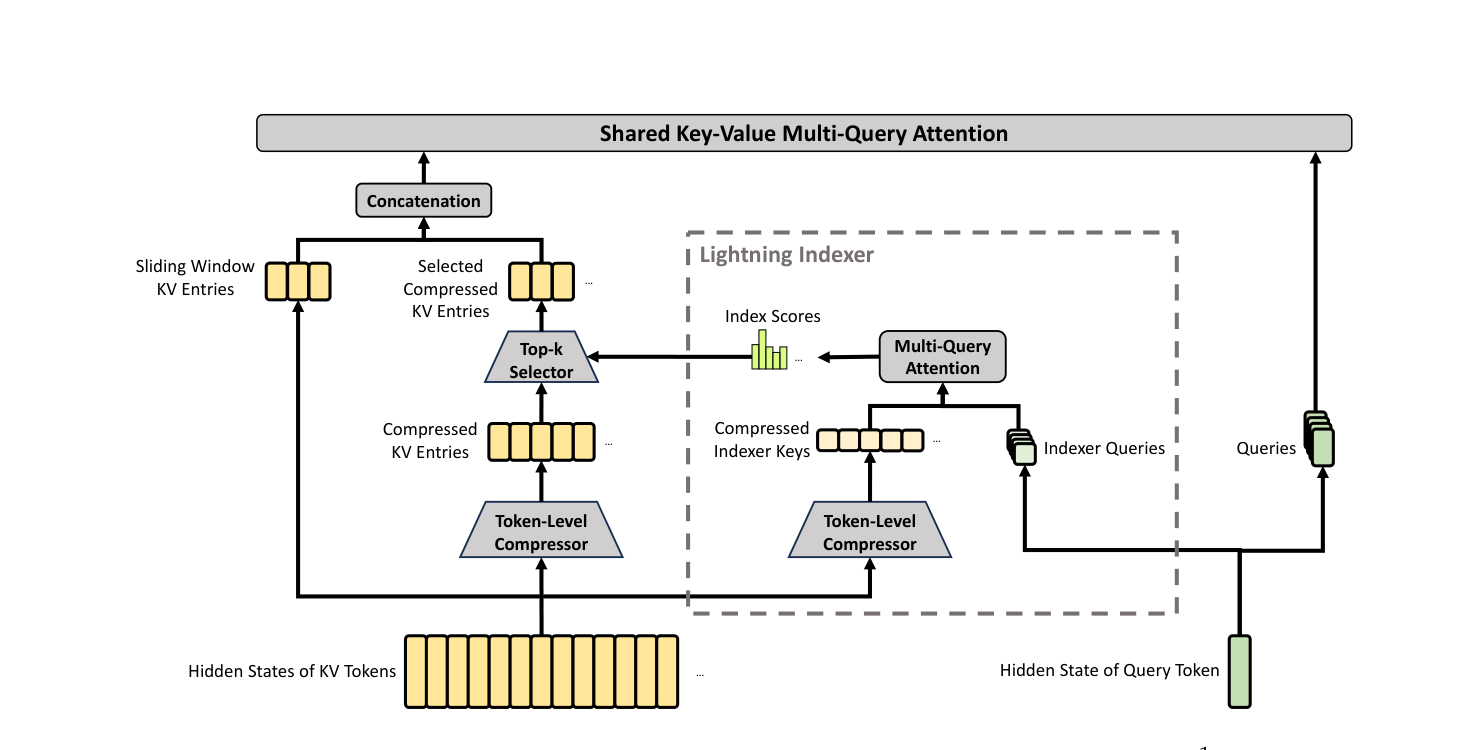
Step 1: Token-Level Compressor
输入 hidden states $H \in \mathbb{R}^{n \times d}$, CSA 先生成两组并行的 KV 投影与权重:
$$\begin{align} C^a &= H W^{aKV}, \quad C^b = H W^{bKV} \label{eq:dsv4-attn-csa-c} \\ Z^a &= H W^{aZ}, \quad Z^b = H W^{bZ} \label{eq:dsv4-attn-csa-z} \end{align}$$其中 $C^a, C^b \in \mathbb{R}^{n \times c}$ ($c$ 是 head dim), $Z^a, Z^b \in \mathbb{R}^{n \times c}$ 是动态权重。
接着定义 $2m$ 个 token 的滑动窗口压缩。第 $i$ 个 compressed entry $C_i^{\text{Comp}} \in \mathbb{R}^c$ 来自两段相邻 KV 区间 (a 区间 $[mi, m(i+1))$ 和 b 区间 $[m(i-1), mi)$),共 $2m$ 个原始 KV:
$B^a, B^b \in \mathbb{R}^{m \times c}$ 是学习的位置 bias, $\odot$ 是 Hadamard 乘法。
关键点:
- 每个 $C_i^{\text{Comp}}$ 是由 $2m$ 个原始 token 的 KV 加权得到
- 相邻 entry 共享同一段 $m$ 长 token 区间 — 例如 token 区间 $[m(i-1), mi-1]$ 在 $C_{i-1}$ 中以
a投影出现,在 $C_i$ 中以b投影出现。同一段原始 token 在两个相邻 compressed entry 中用两种不同投影各被表达一次,让局部信息在压缩后仍有连续性 - 整个序列压缩后长度变成 $n/m$ (每 $m$ 个原始 token 对应 1 个 compressed entry)
- 当 $i=0$ 时 $C^b$ 区间填 0、$Z^b$ 区间填 $-\infty$,保证 softmax 退化为只用
a区间
Step 2: Lightning Indexer
CSA 不让每个 query 看所有 $n/m$ 个 compressed entry,而是用 Lightning Indexer 选出最相关的 top-k 个。
为 query token $t$ 生成低秩 indexer queries:
$$\begin{align} \mathbf{c}_t^Q &= \mathbf{h}_t W^{DQ} \in \mathbb{R}^{d_c} \label{eq:dsv4-attn-csa-q-latent} \\ [\mathbf{q}_{t,1}^I; \ldots; \mathbf{q}_{t,n_h^I}^I] &= \mathbf{c}_t^Q W^{IUQ} \label{eq:dsv4-attn-csa-q-indexer} \end{align}$$$d_c$ 是 query 压缩维 (Flash 1024 / Pro 1536), $W^{DQ} \in \mathbb{R}^{d \times d_c}$ down-projection, $W^{IUQ} \in \mathbb{R}^{d_c \times c^I n_h^I}$ up-projection。Pro 和 Flash 都用 $n_h^I = 64$ 个 indexer head, head dim $c^I = 128$。
Indexer 的 key 直接复用 CSA 主路径的压缩操作得到 $K^{\text{IComp}} \in \mathbb{R}^{n/m \times c^I}$。
Index score 用 ReLU 加权和 计算 (不是 softmax):
$$\begin{equation} [w_{t,1}^I; \ldots; w_{t,n_h^I}^I] = \mathbf{h}_t W^w \label{eq:dsv4-attn-csa-indexer-weight} \end{equation}$$ $$\begin{equation} I_{t,s} = \sum_{h=1}^{n_h^I} w_{t,h}^I \cdot \mathrm{ReLU}(\mathbf{q}_{t,h}^I \cdot K_s^{\text{IComp}}) \label{eq:dsv4-attn-csa-index-score} \end{equation}$$ReLU 替代 softmax 的原因:
- softmax 会把所有分数归一到 $[0, 1]$ 总和为 1,对"挑选 top-k"反而模糊
- ReLU 保留绝对量级差异,让 top-k selector 选出真正最相关的 entry
- 计算更便宜,且配合 FP4 量化效率更高
Lightning Indexer 的 FP4 量化口径(论文 §2.3.4):
"Attention computation within the lightning indexer is performed in FP4 precision."
精确解读 — 只有 indexer 内部的 attention 计算用 FP4(即 $q^I_{t,h} \cdot K^{\text{IComp}}_s$ 这个点积),不是整个 CSA / HCA 主路径用 FP4。主路径 KV cache 用 BF16(RoPE 维)+ FP8(其余维)混合存储。FP4 用在 indexer 是因为:
| 性质 | 原因 |
|---|---|
| Indexer 只需排序 top-k | 数值精度不影响排名稳定性 |
| Indexer key cache 同步压缩存 FP8 | 反量化到 FP4 再点积,开销可被 compute 单元吃下 |
| Indexer head dim $c^I=128$ | 短 reduction 长度对低精度更友好 |
最后用 top-k selector 取出 $k$ 个 compressed KV entry:
$$\begin{equation} C_t^{\text{SprsComp}} = \left\{ C_s^{\text{Comp}} \mid I_{t,s} \in \mathrm{Top-k}(I_{t,:}) \right\} \label{eq:dsv4-attn-csa-topk} \end{equation}$$Flash 取 $k=512$, Pro 取 $k=1024$。
Step 3: Shared KV MQA
被选出的 $k$ 个 compressed KV 进入 core attention。注意 V4 的 attention 同时作为 key 和 value — 每个 entry $C_s^{\text{Comp}}$ 既当 K 又当 V,这是 Shared KV MQA 的本质。
Query 用 indexer 中已经算好的 latent $\mathbf{c}_t^Q$ 上投影得到 $n_h$ 个 head:
$$\begin{equation} [\mathbf{q}_{t,1}; \ldots; \mathbf{q}_{t,n_h}] = \mathbf{c}_t^Q W^{UQ} \label{eq:dsv4-attn-csa-q-up} \end{equation}$$$W^{UQ} \in \mathbb{R}^{d_c \times c n_h}$。Core attention 输出:
$$\begin{equation} \mathbf{o}_{t,i} = \mathrm{CoreAttn}(\mathrm{query} = \mathbf{q}_{t,i},\ \mathrm{key} = C_t^{\text{SprsComp}},\ \mathrm{value} = C_t^{\text{SprsComp}}) \label{eq:dsv4-attn-csa-coreattn} \end{equation}$$三个关键事实:
- 同一个 latent $\mathbf{c}_t^Q$ 在 indexer queries 和 attention queries 间共享,省一次 down-projection
- K 和 V 是同一张 tensor $C_t^{\text{SprsComp}}$,省一半 KV cache
- 输出维度 $c$ 较大 (V4 中 $c = 512$,相对常见 MHA head dim 128 大 4 倍),单 entry 信息密度高
Step 4: Grouped Output Projection
$n_h$ 个 head 输出拼接后是 $cn_h$ 维 (Pro 是 $512 \times 128 = 65536$, Flash 是 $512 \times 64 = 32768$)。直接投影到 $d$ 维需要巨型矩阵,成本不可接受。
CSA 把输出按 group 拆分:先把 $n_h$ 个 head 分成 $g$ 组,每组 $n_h/g$ 个 head 的输出拼接,投到中间维 $d_g$:
$$\begin{equation} \mathbf{o}_{t,i}^{G'} = \mathbf{o}_{t,i}^{G} W^{O,G}, \quad \mathbf{o}_{t,i}^{G'} \in \mathbb{R}^{d_g} \label{eq:dsv4-attn-group-proj} \end{equation}$$$d_g < c n_h / g$ (V4 用 $d_g = 1024$),让每组的输出投影矩阵 $W^{O,G} \in \mathbb{R}^{(c n_h / g) \times d_g}$ 不太大。
最后把 $g$ 组中间输出拼接成 $d_g g$ 维并投到 $d$ 维:
$$\begin{equation} \hat{\mathbf{o}}_t = [\mathbf{o}_{t,1}^{G'}; \ldots; \mathbf{o}_{t,g}^{G'}] W^{O,\text{final}}, \quad W^{O,\text{final}} \in \mathbb{R}^{d_g g \times d} \label{eq:dsv4-attn-final-proj} \end{equation}$$Pro 用 $g=16$ ($d_g g = 16384$), Flash 用 $g=8$ ($d_g g = 8192$)。
HCA 跟 CSA 差在哪
核心问题:HCA 为什么不要 indexer / top-k?压缩率 128× 后还够用吗?
HCA 结构上是 CSA 的简化:保留压缩,去掉稀疏选择,但压缩率激进得多且不 overlap。
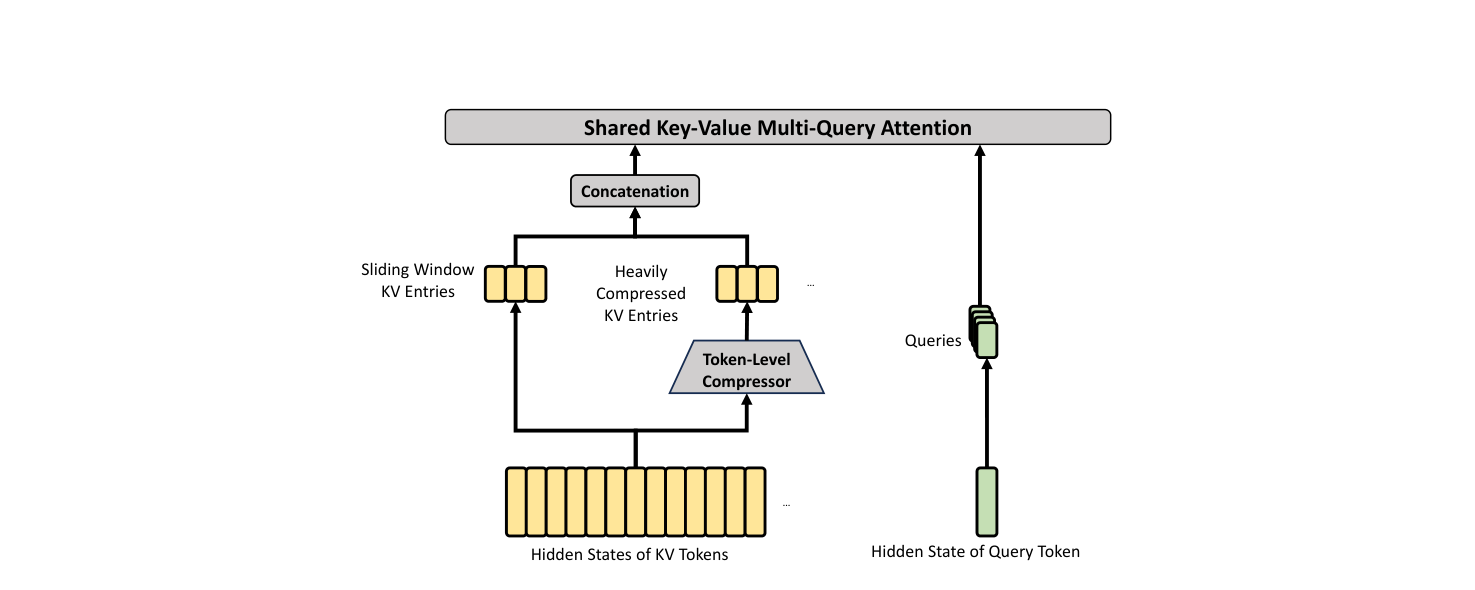
输入仍是 $H \in \mathbb{R}^{n \times d}$,先算 KV 与权重:
$$\begin{equation} C = H W^{KV}, \quad Z = H W^Z \label{eq:dsv4-attn-hca-kv} \end{equation}$$只有一组 (CSA 是 $a$ / $b$ 两组)。然后每 $m'$ 个 token 压成 1 个:
$$\begin{equation} S_{m'i:m'(i+1)-1} = \mathrm{Softmax}_{\text{row}}(Z_{m'i:m'(i+1)-1} + B) \label{eq:dsv4-attn-hca-softmax} \end{equation}$$ $$\begin{equation} C_i^{\text{Comp}} = \sum_{j=m'i}^{m'(i+1)-1} S_j \odot C_j \label{eq:dsv4-attn-hca-comp} \end{equation}$$V4 取 $m' = 128$。没有 overlap — 相邻 $C_i^{\text{Comp}}$ / $C_{i+1}^{\text{Comp}}$ 用的原始 KV 区间互不相交。序列长度被压成 $n/m'$。
后续步骤与 CSA 一致:query 用 indexer 中的同一 latent 上投影 (HCA 不需要 indexer 因为不做 top-k,但仍复用 latent 结构) → Shared KV MQA 对所有 $n/m'$ 个 compressed entry 做 dense attention → Grouped Output Projection。
HCA 与 CSA 对比
| 维度 | CSA | HCA |
|---|---|---|
| 压缩率 | $m = 4$ | $m' = 128$ |
| Overlap | 有 (每 entry 覆盖 $2m$ 原始 token) | 无 |
| 稀疏选择 | 有 (top-k 选 512 / 1024) | 无 (所有 compressed entry 都参与) |
| KV 路径分组 | 两组 $a$ / $b$ 并行 | 单组 |
| Lightning Indexer 选择 | 需要做 top-k 选择 | 不需要 top-k (但 query latent 投影结构相同) |
| 适用场景 | 中等距离细粒度依赖 | 超长距离粗粒度依赖 |
@tbl-dsv4-attn-csa-vs-hca CSA 与 HCA 的对比
CSA 和 HCA 在网络中交错堆叠 — 具体顺序论文未公开,但每个 block 二选一。直觉上:CSA 抓 KB 级远距离依赖,HCA 抓 MB 级超远距离依赖,两者互补。
CSA / HCA 共享哪些细节
核心问题:SWA 分支 / 前 2 层特殊配置 / Partial RoPE / Attention Sink / Q-KV RMSNorm 各自解决什么问题?
Sliding Window 分支
每个 query 除了看 compressed entry,还额外看最近 $n_{\text{win}} = 128$ 个未压缩 token 的 KV:
- 因果性问题:query 不能访问自己当前 compressed block 内的 token (块内 KV 还未生成 entry)
- 局部依赖问题:语言建模中最近 token 通常最相关,靠压缩后的 entry 表达粒度太粗
Sliding window 分支的 KV 直接用未压缩的 $H W^{KV}$ (一份独立的投影),与 compressed entry 一起送入 core attention。
V4-Flash 与 V4-Pro 的层堆叠模式
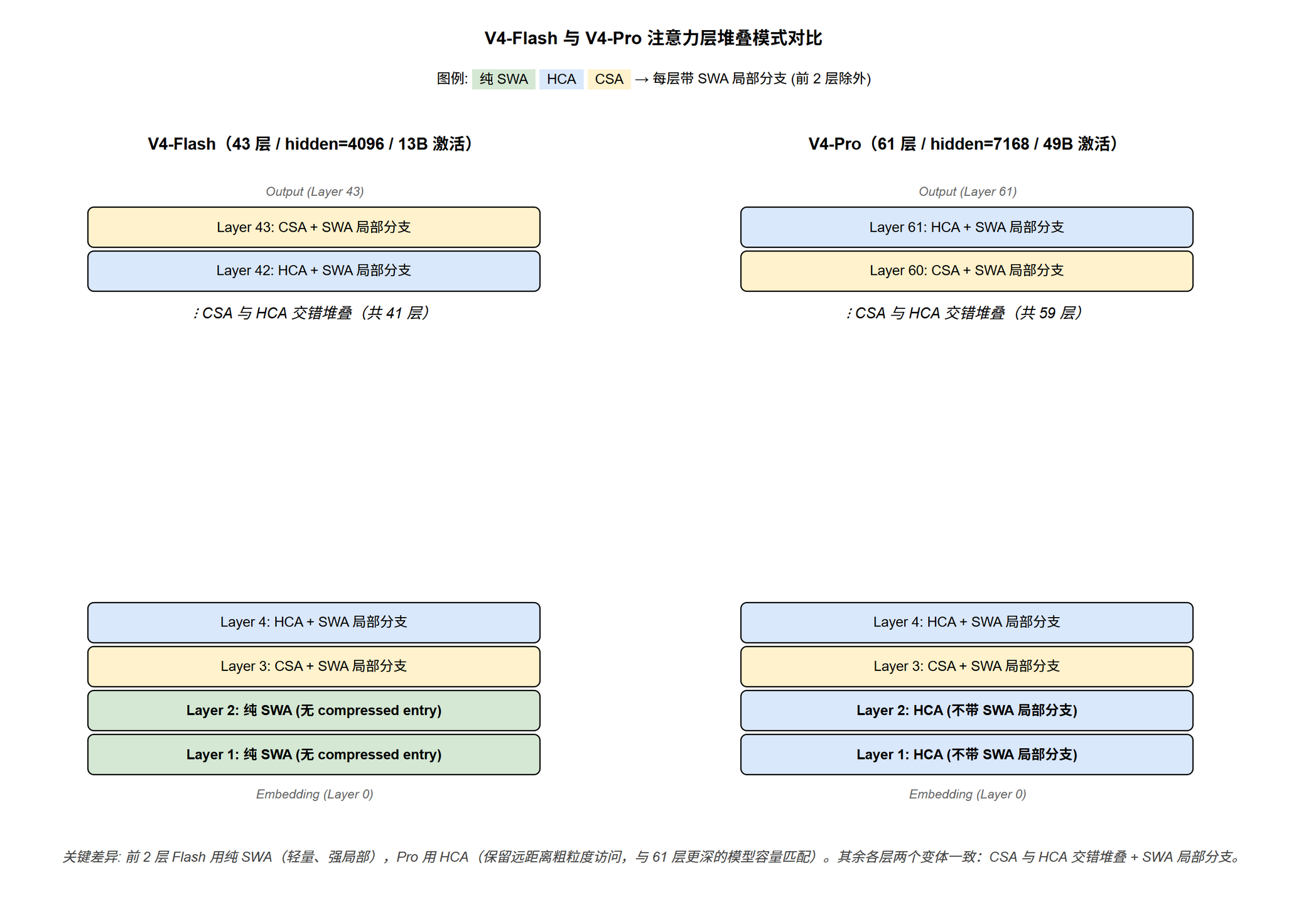
前 2 层的特殊配置 (Pro / Flash 不同):
- V4-Flash:前 2 层用纯 sliding window attention (window size 128,无 compressed entry 分支)
- V4-Pro:前 2 层用 HCA (带压缩,但不带 CSA 的 top-k 稀疏选择)
设计动机推测 (论文 §4.2.1 未明确解释):
- 浅层 token 表征还在形成中,全局信息聚合意义不大
- Pro 模型更深 (61 层 vs Flash 43 层),即便浅层也希望保留远距离 KV 的粗粒度访问能力,所以选 HCA (128× 压缩后仍覆盖整个上下文)
- Flash 更轻量,省去 HCA 的 compressor / 投影矩阵开销更划算
- 共同点:前 2 层都不用 CSA,省去 indexer / top-k 选择等开销,加快训练初期收敛
Partial RoPE
CSA / HCA 都只对 query / KV 的最后 64 维应用 RoPE(论文 §2.3.3 verbatim:"we apply RoPE to its last 64 dimensions")。head dim $c=512$,所以 RoPE 占比 64/512 = 12.5%,其余 87.5% 为 NoPE。
- query / KV entry 的最后 64 维:标准 RoPE 旋转位置 $i$
- Core attention 输出的最后 64 维:inverse RoPE 旋转位置 $-i$
为什么 output 要 inverse RoPE?因为在 V4 的 Shared KV MQA 设定下 K 与 V 是同一张 tensor(论文 Eq. 19),attention 输出 $\sum_j s_{ij} V_j$ 相当于把 $V_j$ 的 RoPE 编码"加权累加"过来,让输出携带了 $V_j$ 的绝对位置编码。Inverse RoPE 旋转位置 $-i$(query 位置)把绝对编码减去,让输出仅保留相对位置(query 与 KV 的距离差)。这是 K=V 共享导致的特殊 trick,标准 MHA 因 K/V 分离不需要。
为什么 NoPE 占 87.5%:12.5% 维度已足够编码 1M 上下文的相对位置信息(理论上 RoPE 旋转矩阵不限定上下文长度,长度通过 base frequency 调),多余维度留给纯语义内容反而更紧凑。
Attention Sink
Core attention 用学习的 sink logits $\{z_1', \ldots, z_{n_h}'\}$ 增强 softmax 分母 (OpenAI 2025, Xiao et al. 2024 提出):
$$\begin{equation} s_{h, i, j} = \frac{\exp(z_{h, i, j})}{\sum_k \exp(z_{h, i, k}) + \exp(z_h')} \label{eq:dsv4-attn-sink} \end{equation}$$直观理解:sink 为每个 head 提供一个"空 attention 出口" — 当 head 找不到合适的 KV 关注时,可以把权重投入 sink,让真实的 attention 总和趋近 0 (甚至完全 0)。这避免了"必须关注一些 token"的强制行为,提升模型对噪声输入的鲁棒性。
Query / KV RMSNorm
论文 §2.3.3 + §2.4 verbatim:
"For both CSA and HCA, we perform an additional RMSNorm operation on each head of the queries and the only head of the compressed KV entries, just before the core attention operation. This normalization avoids exploding attention logits and may improve training stability." "Consequently, we do not employ the QK-Clip technique in our Muon optimizer."
QK-Clip 是 Muon 早期方案中的核心稳定技巧(Liu et al. 2025),强制 Q·K logit 范围。V4 用 Q-KV RMSNorm 直接归一化输入幅度,从源头解决 logit 爆炸,让 Muon 不再受 QK-Clip 制约 — 这是 V4 注意力与 Muon 优化器互锁设计的一个体现(详见 05-training)。
Two-stage Contextual Parallelism
论文 §3.4.3 报告 V4 用 two-stage CP 处理超长 context attention,专为压缩注意力设计:
| 阶段 | 操作 | 通信 |
|---|---|---|
| Stage 1 | 各 CP rank 本地压缩自己 shard 的 KV,产出固定长度 $s/m + 1$ 的 compressed entry(含 padding) | 无 |
| Stage 2 | All-gather 跨 CP rank 收集所有压缩 entry → fused select-and-pad operator 重排成全局 cp_size·$s/m$ 长度 | 一次 all-gather |
@tbl-dsv4-attn-cp-two-stage Two-stage CP 阶段划分
关键 invariant:对 HCA 与 CSA 的 indexer,每个 query 可见的 compressed KV index 是规则可预计算的(按位置区间)。对 CSA 的 sparse core attention,top-k selector 显式给出可见 index 列表。两条路径都不需要在 CP 间动态交换索引,只在 stage 2 做一次全收集。
V4 推理 KV cache 怎么组织
核心问题:三种 attention 类型 + 1M 上下文下 KV cache 怎么排布?内存占多少?
V4 推理时的 KV cache 被组织成两个独立结构:每 request 一个固定大小的 State Cache (存 SWA + 未压缩 tail token),共享池化的 KV Cache 按 block 存 CSA / HCA 压缩 entry。这种异构布局让 PagedAttention 框架仍能高效管理混合注意力。
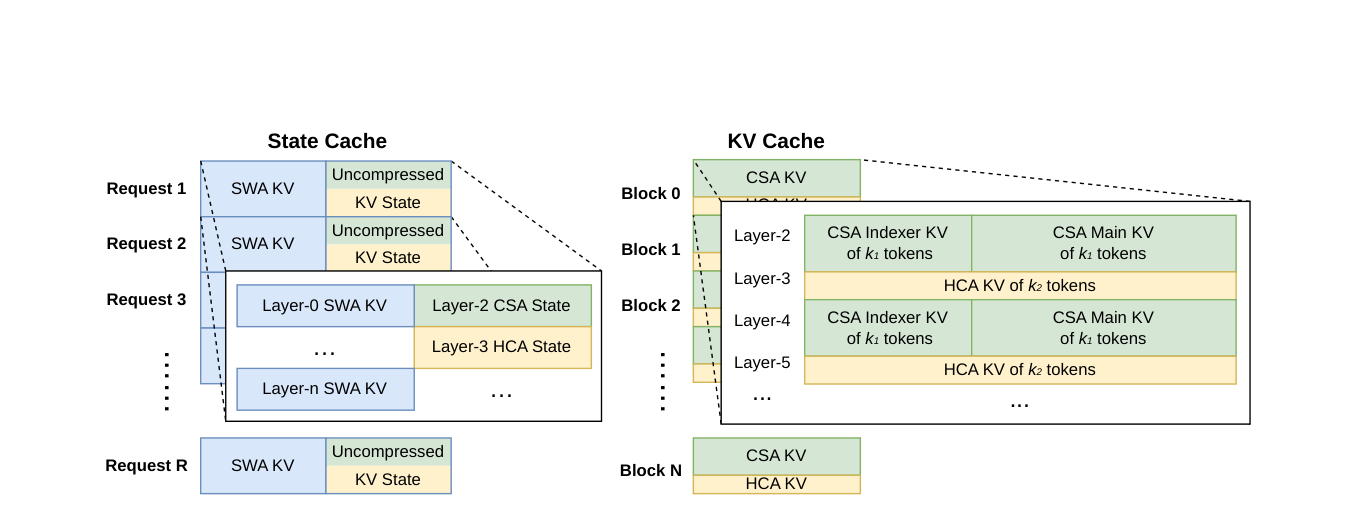
KV cache 按层分布:
- SWA 层 / 局部分支:每 token 存 $n_{\text{win}} = 128$ 个未压缩 KV,对 1M token 序列固定开销 128 × layer 数
- CSA 层:存 $n/m$ 个 compressed KV entry (每个 entry 综合 $a$ / $b$ 两组投影得到的单一 $C_i^{\text{Comp}}$)。同时还需要存 indexer key cache (同样 $n/m$ 个 entry,但维度 $c^I=128 < c=512$)
- HCA 层:存 $n/m'$ 个 compressed KV entry
混合精度策略:
- KV entry: RoPE 维 BF16 / 其余 FP8 → 减半
- Indexer key cache (CSA 专属):FP8
- Indexer 内部 attention 计算:FP4(仅 indexer 点积,主路径不参与)
最终 V4-Pro 在 1M 上下文下 KV cache 约 V3.2 的 10%,V4-Flash 7%,相对 BF16 GQA8 (head dim 128) baseline 约 2%。
KV Cache Block 的 lcm 设计
论文 §3.5.1 给出具体块大小公式 — 每个 cache block 覆盖 $\mathrm{lcm}(m, m')$ 个原始 token,每 block 产出:
$$\begin{equation} k_1 = \frac{\mathrm{lcm}(m, m')}{m},\quad k_2 = \frac{\mathrm{lcm}(m, m')}{m'} \label{eq:dsv4-attn-kvblock-lcm} \end{equation}$$代入 V4 配置 $m=4, m'=128$:$\mathrm{lcm}=128$,得 $k_1=32$ 个 CSA 压缩 entry / $k_2=1$ 个 HCA 压缩 entry / 每 block。这个 lcm 对齐让 CSA / HCA / 配套 sparse attention kernel 共用同一套 page table,绕过 PagedAttention 不支持异构 KV 的限制。
State Cache vs KV Cache 异构
| 池子 | 内容 | 分配单位 | 大小 |
|---|---|---|---|
| State Cache | (a) SWA KV(每 layer 最近 $n_{\text{win}}=128$ token)+ (b) 未到压缩阈值的 CSA / HCA tail token | 每 request 固定 block | 与 request 数线性,与 context 长度无关 |
| KV Cache | CSA Main KV + CSA Indexer KV + HCA KV | 每 request N 个 block | 与 context 长度线性,但被 $m$ / $m'$ 压缩 |
@tbl-dsv4-attn-cache-pools V4 KV cache 异构双池
State cache 把 SWA + tail 视为一个 state-space model — KV 仅依赖当前位置,可固定分配。这是 PagedAttention 在 V4 上能延续使用的关键技巧。
解决 PagedAttention 不兼容的两个障碍
论文 §3.5.1 明确点出两个对 PagedAttention 的根本挑战 + V4 解法:
| 障碍 | 来源 | V4 解法 |
|---|---|---|
| 多种 cache 驱逐策略(SWA 滚窗 vs CSA/HCA append-only) | 不同层 KV 生命周期不同 | State cache pool 隔离 SWA + tail token,与共享 KV cache 解耦 |
| Attention kernel 的对齐要求(block size $B$ 固定) | 高性能 sparse kernel 假设 $B \cdot m$ 原始 token 整除 | lcm 块大小 + sparse kernel co-design,padding 对齐 cache line |
@tbl-dsv4-attn-paged-fixes V4 突破 PagedAttention 限制的两个 co-design
On-Disk KV Cache 三策略
shared-prefix 复用时 KV cache 落盘。CSA / HCA 压缩 KV 直接落盘,但 SWA KV 体量约是压缩 KV 的 8×(每层都要保留 128 token,跨所有层),三种策略权衡存储与重算:
| 策略 | 存储成本 | 重算成本 | 适用场景 |
|---|---|---|---|
| Full SWA Caching | 全量 SWA KV 落盘 | 零重算 | 计算受限场景;但 SSD 写放大严重 |
| Periodic Checkpointing | 每 $p$ 个 token 存一次最近 $n_{\text{win}}$ KV | 加载最近 checkpoint + 重算 tail | 默认策略,$p$ 可调 |
| Zero SWA Caching | 不存 SWA | 利用已存 CSA/HCA KV 重算最后 $n_{\text{win}} \cdot L$ token 的 SWA | 存储极受限 |
@tbl-dsv4-attn-disk-strategies V4 on-disk SWA KV 存储三策略
Zero SWA Caching 的精妙处:每层 SWA KV 只依赖上一层最近 $n_{\text{win}}$ 个 token 的 SWA KV。$L$ 层模型从 CSA/HCA 压缩 KV 出发,逐层重算最后 $n_{\text{win}}\cdot L$ token 即可恢复,重算量仅 $O(n_{\text{win}}L)$ 与 context 长度无关。
计算 FLOPs 为什么不爆炸
核心问题:CSA 各子模块 FLOPs 怎么随上下文长度增长?为什么不随 $n$ 爆炸?
CSA 的计算分布:
| 模块 | FLOPs 大致占比 |
|---|---|
| Token-Level Compressor | 与 $n/m$ 成正比,小 |
| Lightning Indexer (dense matmul) | 与 $n/m \times n_h^I$ 成正比 |
| Top-k Selection | $O(n/m)$ |
| Core Attention (only over $k$ entries) | 与 $k$ 成正比,不随 $n$ 增长 |
| Grouped Output Projection | 固定 |
@tbl-dsv4-attn-csa-flops CSA 各子模块 FLOPs 占比
随上下文长度 $n$ 增长,CSA 的 FLOPs 主要由 indexer 主导 (与 $n$ 线性), core attention 与 $n$ 无关 (恒定 $k$)。这是 V4 单 token 推理 FLOPs 不随上下文爆炸的根本原因。
V4-Pro 在 1M 上下文下单 token FLOPs 仅为 V3.2 的 27%, V4-Flash 进一步降到 10%。
CSA 跟前代 DeepSeek 工作什么关系
核心问题:MLA / DSA / NSA 跟 CSA 各自的关系?(这些机制的算子细节见 06 实现卷:DSA/NSA → 07 滑窗与固定稀疏 / 08 动态稀疏选择,MLA → 10 维度压缩 MLA;本节只讲它们与 CSA 的谱系关系。)
DSA (DeepSeek V3.2 提出)
DSA = DeepSeek Sparse Attention:对 dense KV 做 top-k 选择,每个 query 只关注被选中的 token。CSA = DSA 的扩展:先把 KV 压缩到 $1/m$,再对压缩后的 entry 做 DSA 选择。压缩是 V4 比 V3.2 多出的一层抽象。
MLA (DeepSeek V2 / V3 提出)
MLA = Multi-head Latent Attention:把 KV 压缩到 latent 维度 $d_c$ 存储,attention 时再上投影回 head dim。MLA 是维度方向的压缩 (每个 token 仍有独立 KV,但单 token 的 KV 维度被压缩到 latent),CSA 是序列方向的压缩 (多个 token 合并成一个 KV)。两者主要作用维度不同,CSA 不再继承 MLA 的 latent 压缩思路。V4 没有继续用 MLA — 直接用 single-head shared KV (MQA 风格) + Compressor 把序列方向压缩。
NSA (Yuan et al., arXiv 2502.11089)
NSA = Native Sparse Attention: DeepSeek 同期更早提出的稀疏注意力,分层做粗粒度 token 压缩 + 细粒度 token 选择 + 滑窗。NSA 与 CSA 的思路一脉相承,但 NSA 是"训练时也用稀疏"的整体设计,CSA / HCA 进一步把"压缩"作为一等公民提到 dense 操作前。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 两个优化维度 | 压缩 (减少 entry 总数) + 稀疏 (top-k 选择),V4 把两者交错堆叠 |
| CSA | 4× overlap 压缩 + top-k 稀疏,抓中距细粒度,Pro k=1024 / Flash k=512 |
| HCA | 128× 压缩 dense 无 overlap,抓超长粗粒度 |
| SWA | 未压缩窗口 128,既做局部分支也做 V4-Flash 前 2 层 |
| Lightning Indexer | 低秩 query + ReLU 加权 + 共享 latent,仅 indexer 内部点积用 FP4 |
| Partial RoPE | 仅最后 64 维(占 12.5%)应用 RoPE,输出 inverse RoPE 撤回绝对位置 |
| Q-KV RMSNorm | core attention 前归一化 Q 每 head + K=V 唯一 head,从源头解决 logit 爆炸 → 不需要 QK-Clip |
| Attention Sink | 学习的 sink logit 加进 softmax 分母,允许某 head 总 attention 趋近 0 |
| KV Cache 异构布局 | State Cache(SWA + tail token)+ KV Cache(block = $\mathrm{lcm}(m,m')=128$ 原始 token → $k_1=32$ CSA + $k_2=1$ HCA) |
| On-disk 三策略 | Full SWA / Periodic Checkpoint $p$ / Zero SWA(重算最后 $n_{\text{win}}\cdot L$ token) |
| Two-stage CP | 本地压缩 + all-gather + fused select-and-pad,可见 index 规则预算 |
| FLOPs 不爆炸 | Core attention 只看 $k$ 个 entry 不随 $n$ 增长,indexer 与 $n$ 线性主导 |
| 效率 | V4-Pro 1M 上下文 KV cache 约 V3.2 的 10% / 相对 BF16 GQA8 baseline 约 2% / 单 token FLOPs 27% |