MoE 路由
256 路由 + 1 共享专家,每 token top-8——sigmoid 独立打分 + bias EMA 做无辅助损失负载均衡
核心要点:
- MoE 规模:256 路由 + 1 共享专家,每 token 激活 8+1,激活比 ~5.4%
- sigmoid + bias EMA:每 expert 一个动态 bias $b_i$($\gamma=0.001$),bias 只影响 top-K 选谁,不进入权重
- 路由 4 步:sigmoid 独立打分 → +bias top-K → L1 归一化 → ×2.5 缩放
- GLM-5.2 vs DSV3:可见字段仅一处差异——取消 group routing(
n_group=topk_group=1)- 安全网:保留极小 sequence-wise aux loss($\alpha=0.0001$),"noaux" 指无 batch 级 aux loss 主导
- EP 通信:64 EP 下 929 MB / forward,仅 attention all-reduce 的 13%;TBO overlap 在 S 层失效
前置阅读
- GLM-5.2 完整配置 → 3.1 总览
- DeepSeek V4 MoE 对比 → ../02-DeepSeek-V4/04-moe
- EP 通信沿用 GLM-5 设计(80 层 + hierarchical all-to-all) → 06-inference § EP all-to-all
GLM-5.2 的 MoE 配置是什么?
GLM-5.2 的 MoE 设计直接来自 GLM-5 的架构基础[1],在 GLM-5.2 中延续使用。核心配置[2]:
| 参数(HF config 字段) | 数值 | 说明 |
|---|---|---|
n_routed_experts | 256 | 路由专家池 |
n_shared_experts | 1 | 共享专家,始终激活 |
num_experts_per_tok | 8 | 每 token 激活的路由专家数(top-K) |
moe_intermediate_size | 2048 | Expert FFN 中间维 |
intermediate_size | 12288 | Dense FFN 中间维(前 3 层) |
first_k_dense_replace | 3 | 前 3 层用 dense MLP,从第 4 层起 MoE |
scoring_func | sigmoid | 独立打分(非 softmax) |
topk_method | noaux_tc | 无辅助损失 + token choice |
norm_topk_prob | true | top-K 后做 L1 归一化 |
routed_scaling_factor | 2.5 | 归一化后再乘的缩放因子 |
n_group / topk_group | 1 / 1 | 无组间路由(与 DSV3 取消 8 组取 4 不同) |
@tbl-glm52-moe-config GLM-5.2 MoE 核心配置(含 HF config 字段名)
DeepSeekMoE 的整体结构如 右上半所示——router + top-K 路由专家 + shared expert 的并联结构是 GLM-5.2 / DSV3 同族的共同模板,区别只在 expert 数 / top-K / 中间维等具体数值。
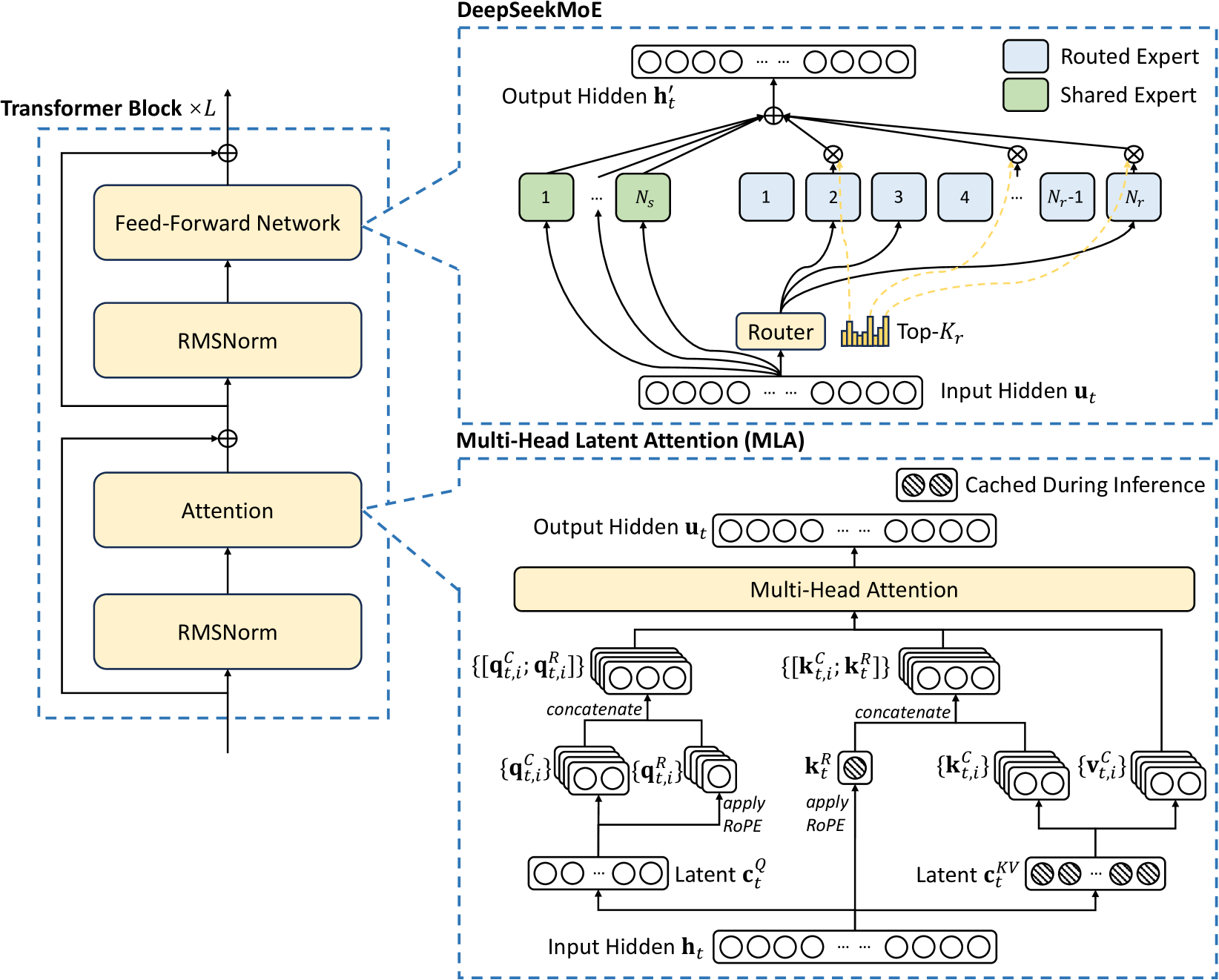
激活参数账:单 expert SwiGLU 参数量 $= 3 \times 6144 \times 2048 \approx 37.7$M(见后节算子分解);激活 8 路由 + 1 共享 $\approx 339$M / token / layer;总 expert 池 $\approx 256 \times 37.7$M $\approx 9.66$B / layer;75 MoE 层共 $\approx 725$B expert 参数。加上 attention + dense + embeddings ≈ 总参 744B,激活 ~40B 与公开 5.4% 激活比吻合[3]。
层类型分布:GLM-5.2 总层数 78(与 GLM-5 的 80 层不同——GLM-5.2 在 GLM-5 基础上又减了 2 层)。前 3 层 dense MLP(first_k_dense_replace=3),intermediate=12288;第 4-78 层(共 75 层)为 sparse MoE。dense 层不参与 IndexShare 周期,indexer_types 均为 full[2]。后续 EP 通信计算以 75 MoE 层为基础。
路由打分到 top-K 的完整数学
GLM-5.2 沿用 DeepSeek-V3 的 noaux_tc 路由[4]。路由从 hidden state 到最终权重要经过 4 步——每步都有明确语义,必须按顺序写:
Step 1:sigmoid 独立打分
每个 expert 的原始亲和分独立计算:
$$\begin{equation} s_{i,t} = \sigma(u_t^\top e_i), \quad i = 1, \ldots, 256 \label{eq:moe-sigmoid-score} \end{equation}$$$e_i \in \mathbb{R}^{6144}$ 是 expert $i$ 的 router embedding;$u_t$ 是 token $t$ 的 hidden state。sigmoid 输出独立——不像 softmax 那样在 expert 间归一化、彼此竞争。
Step 2:bias 调整后的 top-K 选择
引入每 expert 的动态 bias $b_i$(详见下一节 EMA 更新),加到原始分上做 top-K:
$$\begin{equation} \mathcal{T}_t = \mathrm{TopK}\big(\{ s_{i,t} + b_i \}_{i=1}^{256},\ K=8\big) \label{eq:moe-topk-with-bias} \end{equation}$$关键性质:bias 只影响 top-K 的选择,不进入权重计算。这是 noaux_tc 设计的核心 trick——让 bias 充当负载调度器,但不污染梯度路径。
Step 3:用原始 sigmoid 分做 L1 归一化
选出的 K 个 expert 用原始 $s_{i,t}$(不是 $s_{i,t}+b_i$)做 L1 归一化,对应 HF config norm_topk_prob=true:
Step 4:routed_scaling_factor 放大
归一化后再乘缩放因子(routed_scaling_factor=2.5):
为什么要放大 2.5×:sigmoid 输出位于 (0, 1),top-K=8 个 expert 经 L1 归一化后每个权重平均 $\approx 1/8 = 0.125$,导致 expert 输出加权和的总量级被压缩。乘 2.5 把量级抬回与 softmax 路由可比的范围[4]。
整套路由对应代码层的 original_scores → bias add → topk → norm → route_scale[5],DSV3 与 GLM-5.2 实现一致。
noaux_tc:bias EMA 怎么做负载均衡?
"noaux_tc" 全称 no-auxiliary-loss token-choice,核心机制是每 expert 一个动态偏置 $b_i$,靠 EMA 更新做隐式负载均衡[4]。
Bias EMA 更新规则
每 step 训练结束后:
- 统计本 step 内每 expert $i$ 收到的 token 数 $c_i$(含 padding 后)
- 计算平均 $\bar{c} = (1/N) \sum_i c_i$
- 调整 bias:
- $c_i > \bar{c}$(过载)→ $b_i \leftarrow b_i - \gamma$
- $c_i < \bar{c}$(欠载)→ $b_i \leftarrow b_i + \gamma$
$\gamma$ 是 bias adjustment rate(DSV3 公开值 0.001)。这是符号驱动的 EMA:只看过载/欠载的方向,不按差值大小缩放——简单而稳健。
训练末期冻结
DSV3 在训练最后约 500B token 把 $\gamma$ 退火到 0[4],冻结 bias。理由:训练末期模型 router 已经"学会"分散,bias 不再需要主动调度;冻结也让 checkpoint 加载到推理时行为可复现。
推理时的 bias
checkpoint 保存训练末期最终 $b_i$ 值;推理引擎(SGLang / vLLM)加载后不再更新——bias 只在 step 2(top-K 选择)参与计算,对所有推理 token 是固定常数。
保留的极小 aux loss
"noaux" 不等于"零 aux loss"——DSV3 仍保留一个 sequence-wise balance loss 作为安全网[4]:
$$\begin{equation} \mathcal{L}_{\mathrm{Bal}} = \alpha \sum_i f_i \cdot P_i, \quad \alpha = 0.0001 \label{eq:moe-seq-aux} \end{equation}$$- $f_i$ 是 expert $i$ 在序列内的激活频率
- $P_i$ 是序列内所有 token 对 $i$ 的平均 routing 概率
- $\alpha = 10^{-4}$,比 LM loss 小 3-4 个数量级
两者的分工:bias EMA 管 batch 级负载(防部分 expert 长期闲置);sequence-wise aux loss 防序列内极端不均衡(单一序列把全部 token 路由到几个 expert)。前者是 noaux_tc 的主力,后者是被动安全网。
GLM-5.2 vs DSV3 在 noaux_tc 实现上的差异
逐项对照 HF config 字段[2],GLM-5.2 与 DSV3 在 noaux_tc 路由上仅一处可见字段差异——其他参数(topk、scoring_func、scaling factor、bias 机制)均相同:
| 字段 | DSV3 | GLM-5.2 | 说明 |
|---|---|---|---|
n_group | 8 | 1 | DSV3 把 256 expert 分 8 组、token 限选 4 组内的 expert(node-limited routing) |
topk_group | 4 | 1 | GLM-5.2 取消组间约束,token 可在全 256 池中任选 |
DSV3 的 group routing 是 node-locality 约束——限制 token 跨节点的 all-to-all 范围。GLM-5.2 取消的具体动机公开资料未给出,可能 与 EP 通信拓扑或调度策略不同有关(GLM-5/5.2 已用 hierarchical all-to-all 分摊跨节点成本,group 约束相对收益小) [推断]。是否还有其他未公开的 noaux_tc 实现差异,无法确认。
Expert FFN:SwiGLU 三矩阵的算子分解
每个路由 expert 是一个标准 SwiGLU FFN[6],由 gate / up / down 三个 GEMM 组成:
$$\begin{equation} \mathrm{Expert}_i(x) = W^{\text{down}}_i \cdot \big( \mathrm{SiLU}(W^{\text{gate}}_i \cdot x) \odot (W^{\text{up}}_i \cdot x) \big) \label{eq:moe-swiglu} \end{equation}$$| 矩阵 | 形状 | 参数量 |
|---|---|---|
| $W^{\text{gate}}_i$ | $6144 \times 2048$ | 12.58M |
| $W^{\text{up}}_i$ | $6144 \times 2048$ | 12.58M |
| $W^{\text{down}}_i$ | $2048 \times 6144$ | 12.58M |
| 单 expert 总参 | — | 37.74M |
@tbl-glm52-expert-swiglu 单 expert SwiGLU 三矩阵
共享 expert 中间维与路由 expert 一致(2048)[2],参数量同为 37.74M。
单 token MoE 层最终输出公式
token $t$ 进入 MoE 层后的最终输出:
$$\begin{equation} y_t = \mathrm{Expert}_{\text{shared}}(u_t) + \sum_{i \in \mathcal{T}_t} \tilde{g}_{i,t} \cdot \mathrm{Expert}_i(u_t) \label{eq:moe-final-output} \end{equation}$$- 共享 expert 对所有 token 恒激活(无路由权重)
- 路由 expert 用 step 3-4 算得的 $\tilde{g}_{i,t}$ 加权
- 输出维度回到 hidden=6144
单 token MoE 层算子表
| 算子 | 输入 → 输出 | FLOPs | 备注 |
|---|---|---|---|
| Router GEMM | $6144 \to 256$ | $2 \cdot 6144 \cdot 256 \approx 3.1$M | sigmoid 打分 |
| Router sigmoid + bias + top-K | — | $O(256)$ | 选 8 个 expert |
| Router L1 norm + scaling | — | $O(8)$ | 计算 $\tilde{g}_i$ |
| 路由 expert SwiGLU × 8 | grouped GEMM | $\approx 8 \cdot 75.5$M $= 604$M | dominant |
| 共享 expert SwiGLU × 1 | dense GEMM | $\approx 75.5$M | |
| 加权合并 | element-wise | $\approx 9 \cdot 6144$ | 最终求和 |
@tbl-glm52-moe-ops 单 token MoE 层算子分解(不含 attention)
单 token MoE 层 FLOPs 合计 ≈ 682M,其中路由 expert 占 89%。每路由 expert 单次 SwiGLU = $3 \times 2 \times 6144 \times 2048 \approx 75.5$M FLOPs,与 grouped GEMM 实现下的批维 8 一致。
Dense FFN 对比(前 3 层)
Dense 层 SwiGLU(intermediate=12288):
- 三矩阵 $6144 \times 12288$ + $6144 \times 12288$ + $12288 \times 6144$
- 单层参数量 $\approx 226$M(约为 1 路由 expert 的 6×)
- 单 token FLOPs $\approx 453$M(约为 MoE 层激活 FLOPs 的 66%)
MoE 层 vs Dense 层的账:MoE 单 token FLOPs(682M)比 dense(453M)多 50%,但激活参数 339M 也比 dense 多 50%——FLOPs/激活参数比一致。MoE 真正的优势在总参 9.66B / layer vs dense 226M,差 43 倍——这是稀疏激活换大池子的本质。
EP 通信成本建模
GLM-5.2 把 256 expert 切到 $N_{\text{EP}}$ 张卡,每张持 $256/N_{\text{EP}}$ 个 expert;每层 MoE 前后各一次 all-to-all(dispatch / combine)。
均匀负载下的 dispatch 公式
设 $T$ = 一次 forward 处理的总 token 数,$k=8$,$d_{\text{model}}=6144$,BF16(2 bytes),$N_{\text{EP}}$ = EP 切分数。每张卡平均发送字节[7]:
$$\begin{equation} \mathrm{Dispatch}_{\text{per-card}} = \frac{T \cdot k \cdot d_{\text{model}} \cdot 2 \cdot (N_{\text{EP}} - 1)}{N_{\text{EP}}^2} \label{eq:moe-dispatch-bytes} \end{equation}$$Combine(反向)通信量对称。
数值算例($T = 4096$, $N_{\text{EP}}=64$):
- 单 dispatch / 单卡 ≈ $4096 \times 8 \times 6144 \times 2 \times 63/4096^2 \approx 6.19$ MB/层
- 75 MoE 层 × 2(dispatch+combine) ≈ 929 MB / 卡 / forward
- 同等配置 attention all-reduce(hidden 跨 TP 同步)≈ 7.5 GB / 卡 / forward
结论:EP all-to-all 在大 EP 配置下不是通信主瓶颈——单卡总量约为 attention all-reduce 的 13%。但decode 小 batch 下 RDMA 启动延迟才是实际瓶颈,不是带宽。
Hierarchical all-to-all(intra + inter node)
GLM-5 引入分层 all-to-all(详见 06-inference § EP all-to-all),把 $N_{\text{EP}} = N_{\text{intra}} \times N_{\text{inter}}$ 拆成两步[1]:
| 步骤 | 链路 | 每卡发送 |
|---|---|---|
| Step 1(intra-node) | NVLink | $T \cdot k \cdot d \cdot 2 \cdot (N_{\text{intra}}-1) / (N_{\text{intra}}^2 \cdot N_{\text{inter}})$ |
| Step 2(inter-node) | RDMA / IB | $T \cdot k \cdot d \cdot 2 / N_{\text{inter}}$(per node 聚合后) |
@tbl-glm52-hierarchical-a2a 分层 all-to-all 两步的通信量
总字节与扁平 all-to-all 一致,但延迟路径分离——NVLink 与 RDMA 可 pipeline overlap,端到端延迟降低。
TBO overlap 在 S 层会失效
SGLang 的 Two-Batch Overlap(TBO)把一个 micro-batch 拆成两个 sub-batch,让 batch A 的 attention 与 batch B 的 EP all-to-all 时间重叠。要满足重叠条件需要 $T_{\text{attn}} \geq T_{\text{a2a}}$[7]。
IndexShare 的 S 层跳过 indexer 后,attention 计算骤降——1M context 下 S 层 attention FLOPs 约为正常的 0.2%,远小于 EP all-to-all 的时间。TBO overlap 条件不成立,EP 通信会裸露在 critical path 上。
这是 IndexShare 省算力的代价:S 层省 indexer 计算的同时,让 EP 通信变成新的瓶颈。GLM-5.2 整体架构上必须在 F 层尽量榨取 indexer + a2a overlap,S 层认命让通信主导。
Capacity factor 与 token drop
GLM-5.2 config 中没有 expert_capacity 字段[2]——不设硬上限,依赖 noaux_tc 的 bias EMA 软均衡。DSV3 论文报告"14.8T token 训练全程无 token drop"[4],可作为 bias EMA 软均衡有效性的同族佐证。
共享专家与 3 层 Dense 的分工
1 个共享专家始终激活:无论 token 被路由到哪 8 个路由专家,共享专家的输出都会参与最终融合(见 eq:moe-final-output)。共享专家负责所有 token 都需要的"通用知识",路由专家负责"专长知识"——这是 DeepSeekMoE 提出的细粒度分工[8]。
前 3 层为什么用 dense? 浅层 Transformer 的 hidden state 仍在构建 token 的基础语义表示(词性、语法结构、局部上下文),尚未形成足够清晰的"专家分工"信号。过早引入 MoE 路由会导致路由决策基于噪声,反而降低效率。
3 层 dense 的 FFN 维度(12288)远大于单 expert(2048),提供更宽的浅层表征空间;第 4 层起切换为 MoE——hidden state 已经成熟,路由可做有意义的专家选择。
业界主流方案谱
把 GLM-5.2 放到 2024-2026 MoE 路由方案的谱里看[9]:
| 模型 | 路由 / 共享 / top-K | Expert 中间维 | 打分 | 负载均衡 | dense 层数 |
|---|---|---|---|---|---|
| GLM-5.2 | 256 / 1 / 8 | 2048 | sigmoid | noaux_tc (bias EMA) | 3 |
| DeepSeek-V3 | 256 / 1 / 8 | 2048 | sigmoid | noaux_tc + group routing | 3 |
| DeepSeek-V4 (Flash/Pro) | 256/384 / 1 / 6 | 2048/3072 | softmax [推断] | aux loss [推断] | 3 |
| Mixtral 8x22B | 8 / 0 / 2 | 16384 | softmax | aux loss | 0 |
| Qwen3 235B-A22B | 128 / 0 / 8 | 1536 | softmax [推断] | aux loss ($\alpha=0.001$) | 0 |
| Llama 4 Maverick | 128 / 1 / 1 | 8192 | softmax [推断] | aux loss | MoE/dense 交替 |
@tbl-moe-spectrum MoE 路由方案谱(来源 [9])
GLM-5.2 在谱中的三条定位
- 细粒度专家路线:256 expert × 中间维 2048,组合空间 $\binom{256}{8} \approx 4 \times 10^{14}$。对比 Mixtral 8 expert × 16384 维的 $\binom{8}{2}=28$ 组合数小 13 个数量级——但 Mixtral 单 expert 更"大"。两者目标不同:细粒度赌组合表达力,粗粒度赌单 expert 容量。
- 无辅助损失路线:GLM-5.2 / DSV3 同走 noaux_tc + bias EMA;Mixtral / Qwen3 仍以辅助损失为主。无辅助损失的好处是省一个超参(aux loss 权重),但要求 bias EMA 训练阶段稳定,且 sequence-wise 兜底足够。
- 1 共享专家路线:GLM / DSV / Llama 4 都用 1 共享 expert;Mixtral / Qwen3 不用。共享 expert 的代价是每 token 多算 1 次 FFN(约 9% 额外 FLOPs),收益是把通用知识固化、避免在 expert 池里浪费容量。
训练稳定性技术:哪些 GLM-5.2 用了?
业界 MoE 训练有 6 个常见稳定性技术。核对 GLM-5.2 公开资料的覆盖情况[9]:
| 技术 | 出处 | GLM-5.2 是否用 |
|---|---|---|
| noaux_tc + bias EMA | DSV3 §2.1.2 | 是(topk_method: noaux_tc,公开可证) |
| sequence-wise aux loss ($\alpha=0.0001$) | DSV3 §2.1.2 | 推断沿用(GLM-5 未单独提,DSV 体系一致) |
| Router z-loss | ST-MoE | 公开资料未提[10] |
| Router FP32 upcast | 业界惯用 | 公开资料未提 |
| Expert dropout | 业界惯用 | 公开资料未提 |
| Token shuffling | 防 prompt 集中 | 公开资料未提 |
@tbl-glm52-stability 训练稳定性技术核查
诚实结论:只有 noaux_tc 是公开可证的。Router z-loss / FP32 upcast / expert dropout / token shuffling 这四项是业界常见做法,GLM-5/5.2 可能也用了——但 GLM-5 技术报告和 HF config 都没显式说明,不写入正文,留作开放问题。
Expert 激活分布的公开数据
GLM-5 / GLM-5.2 / DSV3 / Qwen3 等闭源 + 半开源大模型均未公开 expert load distribution 直方图。可定量的实测数据只来自学术界对 Mixtral 等小规模 MoE 的事后分析(呈现"长尾 + 中间层最不均匀"模式)和 Cerebras 报告的"learned routing 在头尾层易 collapse"。
这是一片公开数据空白:GLM-5.2 实际负载分散程度、dead expert(never selected)数量、热门 expert 集中度,全都不可知。
4 类失败模式
- Dead expert:某 expert 长期不被选中、梯度稀疏退化
- Routing collapse:大部分 token 涌向少数 expert(aux loss / bias EMA 的核心目标就是防这个)
- Sudden expert reassignment:训练中途 expert 专长突变(Ling 300B 报告过)
- Router oscillation:相邻 step 间 routing 反复震荡(ST-MoE 的 z-loss 缓解)
GLM-5.2 公开资料未报告任何具体失败模式。以下都是 [推断],无 GLM-5 / GLM-5.2 公开实测支撑:
- bias EMA 主动调度可能减轻 dead expert 与 routing collapse 风险
- sigmoid 独立打分可能降低 logit 竞争下的 sudden reassignment 概率
- bias EMA 的符号驱动更新(每步只看方向不看差值)可能有抑制 oscillation 的作用
是否真未发生这 4 类失败、训练曲线在何时出现 expert load 异常波动,公开资料没有数据。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| MoE 规模 | 256 路由 + 1 共享,top-8 激活,总参 744B / 激活 ~40B (5.4%) |
| 路由 4 步公式 | sigmoid 独立打分 → +bias 做 top-K → 用原始 sigmoid L1 归一化 → ×2.5 缩放 |
| noaux_tc | bias EMA γ=0.001,过/欠载方向性更新;训练末期冻结;推理 bias 固定 |
| Bias 不进权重 | bias 仅影响 top-K 选谁,不污染梯度路径——这是核心 trick |
| 极小 aux loss | $\alpha=0.0001$ sequence-wise 兜底,比 LM loss 小 3-4 数量级,与"noaux"不矛盾 |
| vs DSV3 唯一差异 | GLM 取消 group routing (n_group=topk_group=1);其余完全一致 |
| Expert SwiGLU | 三矩阵 $6144 \times 2048$,单 expert 37.7M 参数 |
| 单 token MoE FLOPs | 682M(路由 expert 89%);MoE/dense 激活参数比 1.5× / 总参比 43× |
| EP 通信 | $T \cdot k \cdot d \cdot 2 (N_{\text{EP}}-1) / N_{\text{EP}}^2$;64 EP 下 929 MB 总量,仅 attention all-reduce 的 13% |
| TBO overlap 失效 | IndexShare S 层 attention 过短,EP a2a 裸露 critical path——IndexShare 省算力的代价 |
| 训练稳定性 | 仅 noaux_tc 公开可证;z-loss / upcast / dropout / shuffling 均未披露 |
| Expert 激活分布 | GLM 系列 + DSV3 + Qwen3 均未公开实测——业界数据空白 |
开放问题
- GLM-5.2 是否使用 router z-loss / FP32 upcast / expert dropout / token shuffling?
- bias EMA 的 $\gamma$ 退火时间表(在 GLM-5 中是否与 DSV3 的"末 500B token"一致)
- Expert 激活分布实测——dead expert 数量、热门 expert 集中度
- 取消 group routing(n_group=1)对长序列 + 高 EP 时的 cross-node load 影响
参考资料
- GLM-5 Technical Report, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
- HuggingFace GLM-5.2 config.json. https://huggingface.co/zai-org/GLM-5.2/blob/main/config.json
- HuggingFace, GLM-5.2 Blog, 2026-06. https://huggingface.co/blog/zai-org/glm-52-blog
- DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024. https://arxiv.org/abs/2412.19437
- DeepSeek-V3 inference/model.py, Gate 实现参考(
original_scores → bias add → topk → norm → route_scale). https://github.com/deepseek-ai/DeepSeek-V3 - HuggingFace Transformers
modeling_glm_moe_dsa.py. https://github.com/huggingface/transformers - 本文档第二轮深化调研笔记 (Sub 3, EP 通信成本),
.cache/iforge-research/glm-5.2-r2-04/_sub3_ep_comm.md。 - DeepSeekMoE, arXiv:2401.06066, 2024. https://arxiv.org/abs/2401.06066
- 本文档第二轮深化调研笔记 (Sub 4, 全谱对比 + 稳定性),
.cache/iforge-research/glm-5.2-r2-04/_sub4_spectrum_stability.md。 - ST-MoE: Designing Stable and Transferable MoE, arXiv:2202.08906, 2022. https://arxiv.org/abs/2202.08906
延伸阅读
- ../02-DeepSeek-V4/04-moe — DeepSeek V4 MoE(softmax + aux loss、wave-scheduled EP)
- 06-inference — EP all-to-all 层数缩减 + hierarchical 设计沿用 GLM-5
- 02-indexshare — IndexShare F/S 层与 EP overlap 的交互