因果掩码
上三角 -∞ mask 怎么让 decoder-only 在屏蔽未来的同时保持训练全并行
核心要点:
- Mask 把 attention score 上三角设 $-\infty$, softmax 后变 0
- 训练时全部位置并行算 loss,不串行
- Decoder-only CLM 每 token 都贡献 loss,比 BERT MLM 信号量大 6.7×
- Flash Attention 不 materialize N×N mask, tile 级跳过上三角约省一半计算
- KV cache 之所以可行,根源在 causal mask 保证历史 K/V 不被未来污染
名词定义
本篇共享名词在 4.1 总览 已定义 (Causal mask)。本篇新引入:
| 名词 | 定义 |
|---|---|
| Teacher forcing | 训练时把 ground truth 整段输入模型,同时计算每个位置 next-token loss; causal mask 让位置间不互相污染 |
| CLM (Causal Language Modeling) | next-token prediction 训练目标,每 token 都参与 loss (GPT 系) |
| MLM (Masked Language Modeling) | BERT 训练目标,随机遮 15% token 让模型预测 |
| Bidirectional attention | encoder-only (BERT) 的 attention,无 causal mask,每 token 看全序列 |
| Tile-level skip | Flash Attention v2 工程优化:若整个 Q×K tile 落在上三角,直接跳过不算 |
@tbl-causal-glossary 本篇新引入名词
为什么自回归需要因果掩码?
核心问题:GPT 训练目标是 next-token prediction (给定前 $t-1$ 个 token 预测第 $t$ 个)。但 self-attention 默认是双向的——位置 $i$ 看所有位置 $j$,包括 $j > i$ 的未来。直接训练会怎样?怎么破?
双向 attention 与自回归目标直接冲突:训练时位置 $i$ 能"偷看" $i+1$ 的真实 token,模型只要把它复制到 next-token 预测里就能拿满分,学不到任何语言知识。
不加 mask 的灾难:信息泄露
假设训练一个 GPT,输入序列 [t_1, t_2, t_3, t_4],标签是错位的下一个 token:位置 1 预测 $t_2$,位置 2 预测 $t_3$,等等 (teacher forcing 经典设置)。
如果不加 mask:
- 位置 1 的 hidden state 通过 self-attention 看到 $t_2, t_3, t_4$ 的 value
- 预测 $t_2$ 时,模型只要让 attention 给 $t_2$ 的 value 满权重就行——它已经在输入里看到 $t_2$ 了
- Loss = 0,模型什么都学不到
这是自回归任务的根本约束:训练时必须强制位置 $i$ 只能看 $j \leq i$,不能看未来。Causal mask 就是把"看未来" 这条路断掉的工程手段。
Mask 的具体形式:上三角 $-\infty$
在 attention score 矩阵 $\mathbf{S} \in \mathbb{R}^{s \times s}$ 上,把 $j > i$ 的元素 (上三角) 设为 $-\infty$。Vaswani 2017 §3.2.3 原文:
"masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections."
数学上:
$$\begin{equation} \mathbf{S}_{ij} = \begin{cases} \mathbf{q}_i \cdot \mathbf{k}_j / \sqrt{d_k} & j \leq i \\ -\infty & j > i \end{cases} \label{eq:causal-mask} \end{equation}$$Softmax 把 $-\infty$ 映射到 0: $e^{-\infty} = 0$,归一化后这些位置 attention weight 严格为 0, value 完全不被读取。
(数值稳定性的工程细节:实际实现用 log-space trick 减去每行的最大值后再 exp;混合精度训练里 softmax 通常保持 float32,不降到 bf16,避免 $-65504$ 这个 bf16 最小值不够接近 $-\infty$ 的问题。)
Causal mask 怎么让训练并行?
核心问题:Mask 看起来只是"断未来",跟"训练并行" 有什么关系?Mask 之后训练真的能一次前向算完整段序列吗?
Causal mask 让位置 $i$ 的输出仅依赖输入的 $\mathbf{x}_1, \ldots, \mathbf{x}_i$,但各位置之间互相独立——所有位置可同时算自己的 attention,没有"必须等前一步" 的数据依赖。
训练并行的关键:teacher forcing + mask
训练时模型吃整段真实序列 $\mathbf{x}_1, \ldots, \mathbf{x}_s$ (teacher forcing),一次 forward pass 同时算所有位置的 next-token logits:
- 位置 1 输出 → 预测 $t_2$,算 loss
- 位置 2 输出 → 预测 $t_3$,算 loss
- ...
- 位置 $s-1$ 输出 → 预测 $t_s$,算 loss
因果 mask 保证位置 1 的输出只看 $\mathbf{x}_1$,位置 2 看 $\mathbf{x}_1, \mathbf{x}_2$, ……,各自互不影响。所以这 $s-1$ 个位置的输出可以在一次矩阵乘里并行算完,这就是 02-大模型是什么 里讲的"训练时序列维全并行"的具体落地。
CLM vs MLM:训练信号密度差 6.7×
Causal Language Modeling (CLM, GPT 系) vs Masked Language Modeling (MLM, BERT):
| 维度 | CLM (GPT) | MLM (BERT) |
|---|---|---|
| 训练目标 | 每位置预测 next token | 随机遮 15% token 让模型预测 |
| 每序列贡献 loss 的 token 数 | $s$ 个 (除位置 0) | $0.15 s$ 个 |
| 信号密度 | 100% | 15% |
| 比较 | — | CLM 信号量是 MLM 约 6.7× |
@tbl-causal-clm-vs-mlm CLM 与 MLM 训练信号密度
这是 GPT 系训练效率高于 BERT 的根本原因之一:同样一个 batch 序列,GPT 拿到的 loss 信号是 BERT 的 6.7 倍。在大规模训练上这种"每个 GPU 小时学到多少东西" 的差距非常显著。
工程实现:三档优化
核心问题:上三角 $-\infty$ 听起来很简单,实际 PyTorch / Llama / Flash Attention 怎么实现?真的需要 materialize 一个 $N \times N$ mask 矩阵吗?
实现按硬件友好度分三档:朴素 mask 矩阵 → PyTorch 内置 SDPA → Flash Attention 不 materialize。
档 1:朴素实现 (nanoGPT)
nanoGPT (Karpathy) 是最简洁的教学版本[1]:
class CausalSelfAttention(nn.Module):
def __init__(self, ...):
# 预建 lower-triangular buffer (不计入梯度)
self.register_buffer("bias",
torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size))
def forward(self, x):
# ... 算出 att score 矩阵 [B, n_head, T, T]
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float('-inf'))
att = att.softmax(dim=-1)
# ... 后续
核心代码两行:register_buffer 预建 lower-triangular 0/1 矩阵;masked_fill 把 0 位置改 $-\infty$。
代价:需要 materialize 整个 $T \times T$ 矩阵到 HBM,长序列下显存占用 $O(T^2)$,计算也 $O(T^2)$。
档 2: PyTorch 内置 SDPA
PyTorch 2.0+ 提供 F.scaled_dot_product_attention,内部自动选最佳后端 (Flash / Memory-efficient / Math):
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)
is_causal=True 告诉 PyTorch 应用 causal mask,不需要传 mask 矩阵。后端自动调用 CUDA kernel,无需 materialize $N \times N$ 矩阵到 HBM。
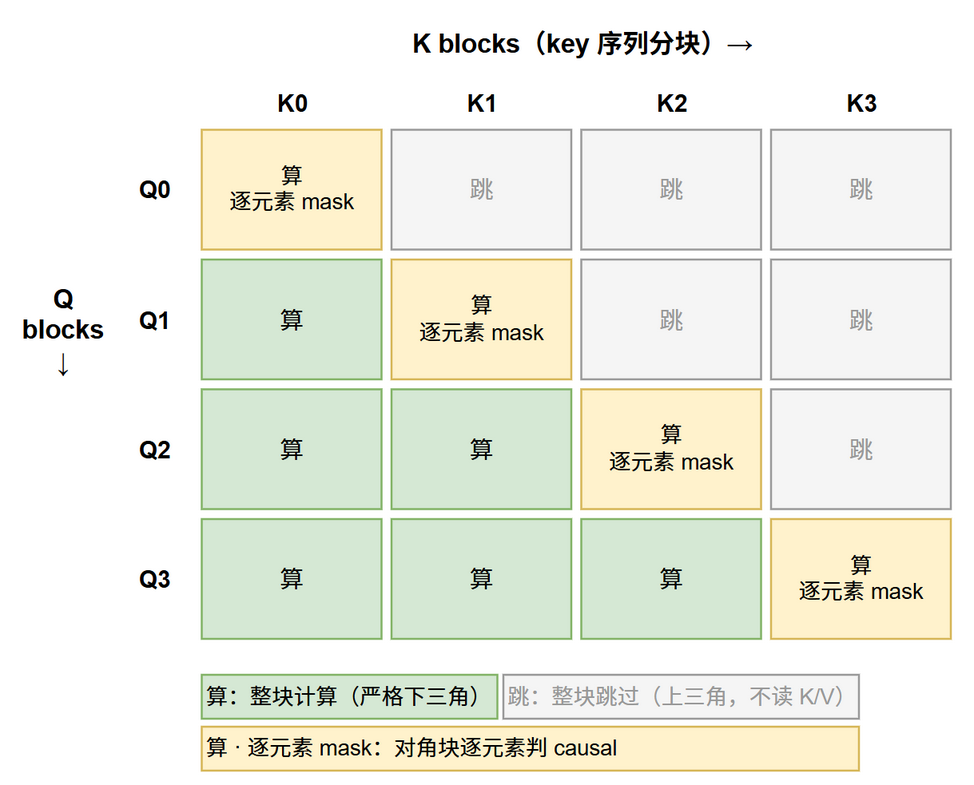
档 3: Flash Attention v2 的 tile 级跳过
Flash Attention v2 (Dao 2023)[2] 在 tile 粒度上跳过完全在上三角内的 Q×K tile:
算法直觉:Q 序列切成 block, K 序列也切成 block。两个 block 的 index 满足 $j > i + B$ (block size) 时,整个 tile 落在上三角内,完全不读 K/V,直接跳过。仅对角线附近的 tile 需要逐元素检查 mask。
实测收益:causal mask 下约跳过一半计算,相比无 mask 提速 1.7-1.8×。这是 Flash Attention 在 decoder-only LLM 上效率的关键。
Llama HF 实现:mask 工厂函数
Llama HuggingFace 实现用 create_causal_mask 工厂函数按 attn_implementation 参数路由 (eager / sdpa / flash):
# 底层 mask 函数
mask_fn = lambda b, h, q, kv: kv <= q # query 索引 q, key 索引 kv
# 加法施加 (不是 masked_fill)
attn_weights = attn_weights + attention_mask # mask 预填 -inf
加法施加而非 masked_fill 是为了兼容 fused attention kernel,把 mask 当成 attention bias 一路传到底层 SDPA / Flash 接口。
与 BERT bidirectional attention 的对比
核心问题:BERT 没有 causal mask,每个 token 都看全序列。这种 bidirectional 模式在哪些任务上有优势?为什么 2020 年后被 decoder-only 全面取代?
Bidirectional 适合理解 (classification / NER),但生成时陷入循环依赖,不可行。
Bidirectional 的根本困难:生成时的循环依赖
BERT 训练时 attention 双向,任意 $i$ 看 $\{1, 2, \ldots, s\}$ 所有位置。这种设计在 classification / token classification 任务上表达力更强 (双向上下文)。
但生成时不可行:生成第 $t+1$ 个 token 需要先知道它是什么 (因为它会进 attention 影响所有先生成的 token),形成循环依赖。MLM 是绕开生成靠 "fill-in-the-blank",不是真生成。
更致命:KV cache 在 bidirectional 下不可行。因为新生成 token 的 K/V 会改变所有历史位置的 attention 输出,历史 K/V 缓存不再有效,每生成一个 token 都要重算全序列。
Decoder-only 取代 encoder-only 的 4 个技术原因
业界从 2020 年 GPT-3 起明确转向 decoder-only, Wang 2022[3] 实证 decoder-only 在 zero-shot 泛化上最强,2025 年再次确认 decoder-only 主导 compute-optimal frontier[4]。技术原因:
- 训练信号密度:CLM 每 token 全贡献 loss, MLM 仅 15%,信号密度差 6.7× (前文已展开)
- 数据 concat 简单:多文档拼接训练不需要复杂 masking,任意位置都是合法训练样本
- 推理形式与预训练一致:预训练就是 next-token,推理直接 next-token,无 fine-tuning gap
- 生成场景友好:CoT 推理 / tool use / 多轮对话天然适配 decoder-only 自回归形式
KV cache 的必要性源头
核心问题:KV cache 几乎是所有 decoder-only LLM 推理优化的核心,它为什么可行?为什么训练时不用?
KV cache 之所以可行,根源在 causal mask 保证历史 K/V 不会被未来 token 影响——这是 decoder-only 架构的"礼物"。
Decode 阶段为什么必须串行
推理 decode 阶段一次只生成 1 个 token,必须串行 (因为生成第 $t+1$ 个 token 才能知道它的值,才能继续生成 $t+2$)。这跟训练的"全序列一次性 forward" 形态完全不同 (详见 02-大模型是什么)。
KV cache 的核心观察
Causal mask 让位置 $i$ 的 K/V 不会被位置 $j > i$ 的输入污染——所以历史 K/V 一旦算出来,后续永远不变,可以缓存复用。
每生成新 token $t$:
- 之前算过的 K/V (位置 $1, \ldots, t-1$) 直接从 cache 读,无需重算
- 只算新 token $t$ 自己的 K/V,写入 cache
- Attention 输出 = 用新 $\mathbf{q}_t$ 和 cache 里的所有 K/V 算 attention
代价:从 $O(t)$ 投影 + $O(t)$ attention 降到 $O(1)$ 投影 + $O(t)$ attention,实际工程上对长上下文是巨大节省。
KV cache 的工程细节 (paged attention / eviction / 量化等) 归 08-推理/03-kv-cache,本篇仅点到为止。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| Mask 数学 | Attention score 上三角设 $-\infty$, softmax 后 $e^{-\infty} = 0$,这些位置完全不读 value |
| 训练并行根基 | 各位置输出互不依赖,一次 forward 算完整段序列,不串行 |
| Teacher forcing | 训练时整段输入 + causal mask + 错位标签,每 token 都贡献 loss |
| CLM vs MLM 信号 | CLM 100% token 贡献 loss, MLM 仅 15%,差 6.7× |
| nanoGPT 实现 | register_buffer 下三角 buffer + masked_fill 上三角设 $-\infty$ |
| PyTorch SDPA | F.scaled_dot_product_attention(q,k,v,is_causal=True) 一键搞定 |
| Flash Attention v2 | tile 级跳过上三角,约省一半计算,1.7-1.8× 加速 |
| BERT bidirectional 局限 | 生成时循环依赖,KV cache 不可行 |
| Decoder-only 胜出 | 信号密度 / 数据 concat / 推理一致性 / 生成友好 |
| KV cache 来源 | causal mask 保证历史 K/V 不被未来污染,可永久缓存 |
开放问题
- Bidirectional 是否在某些任务上仍有不可替代价值:classification / NER 等理解任务上 BERT 系仍被使用,decoder-only 是否能完全取代仍待观察
- causal mask 的"对角线对齐" 选择:Vaswani 选 $j \leq i$ (含自己),有论文测过 $j < i$ (严格小于自己) 的影响,业界结论是含自己更稳,但理论上仍有讨论
- Mask 模式的扩展:prefix-LM (UL2 / GLM) 把 prefix 部分双向 attend,后续 causal,是否能在某些任务上获益,还无定论
- Flash Attention 之后还有什么:tile 级跳过已经很优,下一代 attention 加速 (Ring Attention / Striped Attention) 是否仍依赖 causal 性质
延伸阅读
- 上一步:Q/K/V 投影 → 4.3 自注意力 Q/K/V
- 下一步:多头注意力 → 4.5 多头注意力
- KV cache 工程细节 → 08-推理/03-kv-cache
- 完整推理 prefill / decode → 08-推理/02-prefill与decode
- Flash Attention 详细算法 → 暂未在本知识库覆盖,见 https://arxiv.org/abs/2307.08691
参考资料
- Karpathy. nanoGPT CausalSelfAttention 实现。https://github.com/karpathy/nanoGPT/blob/master/model.py
- Dao. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. 2023. https://arxiv.org/abs/2307.08691
- Wang et al. What Language Model to Train if You Have One Million GPU Hours?. 2022. https://arxiv.org/abs/2210.15424
- Encoder-Decoder or Decoder-Only? Revisiting Architectures. 2025. https://arxiv.org/abs/2510.26622