线性注意力与 SSM
不再做两两内积 + softmax,改用核函数或状态空间递推,把序列写成固定大小的前缀状态
核心要点:
- 换算子放弃 softmax dot-product,稀疏/压缩仍保留 softmax
- 线性注意力用核函数 + 右积优先把 $O(n^2)$ 降到 $O(n)$
- 线性注意力等价 RNN:固定 $d\times d$ 状态,无 KV cache
- SSM 用状态空间递推,Mamba 加选择性(B/C/Δ 依赖输入)
- Mamba-2 的 SSD 证明 SSM 与结构掩码注意力对偶
本篇是注意力机制章实现卷的换算子篇。线性注意力和 SSM 看似两套数学,但都做同一件事——放弃 softmax,把序列写成固定大小的前缀状态递推,因此合为一篇,末节的 SSD 给出它们的统一。分布式序列并行(LASP)只锁定算子属性,工程细节链 interconnect 上下文并行篇(链接待回填)。
名词定义
| 名词 | 定义 |
|---|---|
| 线性注意力 | 用核函数 $\phi$ 替代 softmax,使注意力可线性复杂度计算 |
| 核函数 / 特征映射 $\phi$ | 把 $q,k$ 映到特征空间,使 $\mathrm{sim}(q,k)=\phi(q)^\top\phi(k)$ |
| 右积优先 | 先算 $\phi(K)^\top V$ 得 $d\times d$ 状态,再左乘 $\phi(Q)$ |
| 状态矩阵 $M_s$ | 线性注意力的固定 $d\times d$ 前缀状态,不随序列增长 |
| SSM (State Space Model) | 用状态空间递推 $h_t=\bar A h_{t-1}+\bar B x_t$ 建模序列 |
| 选择性 (selective) | Mamba 让 $B/C/\Delta$ 依赖输入,按内容记忆/遗忘 |
| SSD (State Space Duality) | Mamba-2 证明 SSM 与结构掩码注意力的对偶 |
| SMA (结构掩码注意力) | $(QK^\top)\circ L$ 形式,$L$ 是结构化掩码矩阵 |
@tbl-attn-linssm-glossary 本篇名词定义
换算子和稀疏/压缩差在哪?
稀疏和压缩都保留 softmax attention 只是少看或压短 key,换算子直接放弃 softmax dot-product 本身。这是换算子族与前几篇的根本分野:它改的是 attention 算子的数学形式,不是"看哪些 key"。
放弃 softmax 换来一个根本性质:序列可以写成固定大小的前缀状态递推,推理时状态不随序列增长、无 KV cache。代价是失去 softmax 的"sharp attention"(聚焦少数 key)能力,质量在大规模上通常逊于 softmax attention。线性注意力和 SSM 是这条路的两个分支,下面分别讲,最后用 SSD 统一。
线性注意力怎么去掉 softmax 把 $O(n^2)$ 降到 $O(n)$?
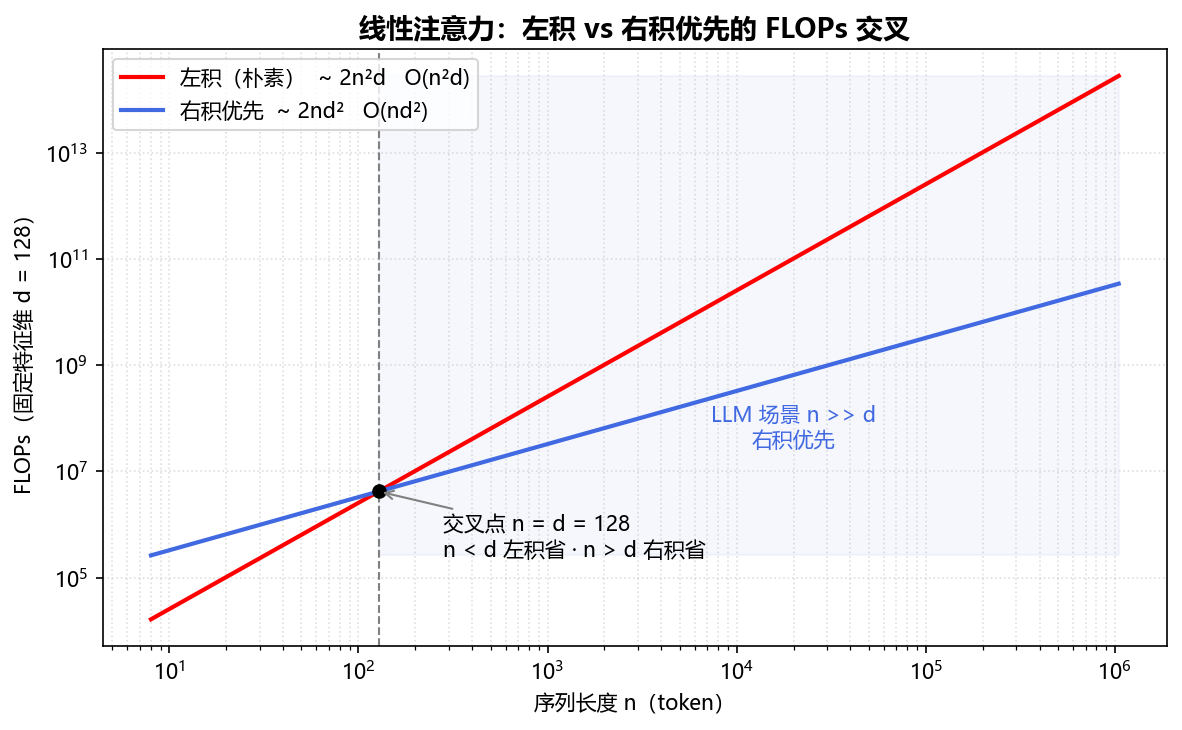
线性注意力用核函数 $\phi$ 把 softmax 的相似度拆成 $\phi(q)^\top\phi(k)$,再靠矩阵结合律先算 KV 侧,把 $O(n^2 d)$ 降到 $O(nd^2)$[1]。
标准 attention 的 $\exp(q_i^\top k_j)$ 耦合了 $q_i, k_j$,必须逐对算、构造 $n\times n$ 矩阵。核技巧假设 $\mathrm{sim}(q,k)=\phi(q)^\top\phi(k)$,得:
$$\begin{equation} o_i = \frac{\phi(q_i)^\top \sum_j \phi(k_j)^\top v_j}{\phi(q_i)^\top \sum_j \phi(k_j)} \label{eq:attn-linssm-kernel} \end{equation}$$右积优先是关键:矩阵乘满足结合律 $\phi(Q)(\phi(K)^\top V)$,先算 $S=\phi(K)^\top V \in \mathbb{R}^{d\times d}$(花 $O(nd^2)$),再对每个 query 左乘 $\phi(q_i)$。避开了 $n\times n$ 中间矩阵:
| 做法 | 中间量 | 复杂度 |
|---|---|---|
| 左积(朴素) | $\phi(Q)\phi(K)^\top \in \mathbb{R}^{n\times n}$ | $O(n^2 d)$ |
| 右积优先 | $\phi(K)^\top V \in \mathbb{R}^{d\times d}$ | $O(nd^2)$ |
@tbl-attn-linssm-leftright 左积 vs 右积优先
$d \ll n$ 时 $nd^2 \ll n^2 d$,关于序列长度线性。Katharopoulos 等在超长序列自回归上报告比标准 Transformer 快至多 4000×[1]。
为什么线性注意力等价于 RNN?
因果线性注意力的前缀和可写成固定 $d\times d$ 状态矩阵的递推——这就是 RNN,推理时无需 KV cache 随序列增长[1]。自回归下位置 $s$ 只看 $j\le s$:
$$\begin{equation} M_s = M_{s-1} + \phi(k_s)^\top v_s, \qquad o_s = \phi(q_s)\, M_s \label{eq:attn-linssm-recurrence} \end{equation}$$$M_s \in \mathbb{R}^{d\times d}$ 是固定大小状态,每步 $O(d^2)$ 更新、与序列长无关。推理内存 $O(d^2)$,对比标准 Transformer KV cache 的 $O(nd)$——这是"Transformers are RNNs"的核心:训练时(prefill)用并行矩阵乘,推理时退化成固定状态 RNN。
代表方法的差别在 $\phi$ 的选择:
- Katharopoulos:$\phi(x)=\mathrm{elu}(x)+1$(保正,稳定分母),是 softmax 核的启发式近似[1]。
- Performer:用正随机特征(FAVOR+)对 softmax 核做无偏估计,正交随机特征理论上 MSE 更低;用 $\exp$ 而非三角函数保证特征非负、attention 权重不为负[2]。
- RWKV:不显式定义 $\phi$,用时间衰减指数权重,RWKV-5/6 的状态递推 $M_s=\mathrm{diag}(w)M_{s-1}+k_s^\top v_s$ 是线性注意力加指数衰减门控的实例。
陷阱:线性注意力质量普遍逊于 softmax——softmax 能聚焦少数 key(sharp),线性核趋向平均;去掉归一化分母还易训练不稳(需 LayerNorm 或正特征映射缓解)。
线性注意力序列并行为什么传状态不传 KV?
线性注意力的状态矩阵 $M_s \in \mathbb{R}^{d\times d}$ 大小固定,序列并行只需在 chunk 边界传这个状态、通信量与序列长无关——这与标准注意力序列并行(Ring Attention)必须传正比于 $n$ 的 KV 是代数结构上的根本区别[3]。
LASP-2 利用这点:各设备算完本地状态增量后,用一次 AllGather 同步 $(B,H,d,d)$ 状态矩阵(与 $n$ 无关)。对比 LASP-1 的 ring P2P($2(W-1)$ 轮),LASP-2 前向只剩 2 次集合通信。2048K 序列、64 GPU 上 LASP-2 比 Ring Attention 快 36.6%、比 LASP-1 快 15.2%[3]。
边界:这里只锁定"传固定状态不传 KV"的算子属性。分布式实现(AllGather 时序、与标准注意力混合的 LASP-2H)是上下文并行的工程问题,详见 interconnect 上下文并行篇 — 异构 Attention 下的 CP。
SSM 怎么用状态空间递推建模序列?
SSM 从一阶线性 ODE 出发,离散化后得到前缀递推,隐状态固定大小、不随序列增长[4]。连续形式:
$$\begin{equation} h'(t) = A h(t) + B x(t), \qquad y(t) = C h(t) \label{eq:attn-linssm-ssm-cont} \end{equation}$$用 zero-order hold 离散化(步长 $\Delta$):$\bar A = e^{\Delta A}$、$\bar B = (\Delta A)^{-1}(e^{\Delta A}-I)\Delta B$,得递推:
$$\begin{equation} h_t = \bar A\, h_{t-1} + \bar B\, x_t, \qquad y_t = C h_t \label{eq:attn-linssm-ssm-disc} \end{equation}$$$h_t \in \mathbb{R}^N$ 完整压缩了历史 $x_1,\dots,x_t$,$N$ 是超参数、与序列长 $L$ 无关。推理每步只更新 $h_t$,内存 $O(N)$——和线性注意力一样,无 KV cache 随 $L$ 增长。这和线性注意力的递推 $\eqref{eq:attn-linssm-recurrence}$ 结构同源(差一个衰减系数 $A$)。
Mamba 的选择性解决了 S4 什么问题?
S4 的参数时不变(LTI),不能按内容选择记忆/遗忘;Mamba 让 $B/C/\Delta$ 依赖输入,代价是不能再用卷积、必须硬件感知地做并行扫描[4]。
S4 的 $(A,B,C,\Delta)$ 对所有时间步相同,等价于固定卷积核,无法做基于内容的推理。Mamba 的选择性:
$$\begin{equation} B_t = \mathrm{Linear}_B(x_t), \quad C_t = \mathrm{Linear}_C(x_t), \quad \Delta_t = \mathrm{softplus}(\mathrm{Linear}_\Delta(x_t)) \label{eq:attn-linssm-selective} \end{equation}$$$A$ 仍固定(对角,HiPPO 初始化)。$\Delta_t$ 控制记忆折扣:大 → $\bar A_t\approx 0$ 遗忘历史吸收当前,小 → $\bar A_t\approx I$ 保留历史。这像 LSTM 门控,但基于结构化状态。
代价是不能再用卷积——卷积核要求参数时不变,$B_t/C_t/\Delta_t$ 依赖输入后每步都变。Mamba 转而用三项硬件感知技术:parallel scan(关联递推用前缀并行扫描 $O(\log L)$ 深度)、kernel fusion(离散化+扫描+输出融进单 kernel,在 SRAM 内算避免 materialize $(B,L,D,N)$ 状态)、recomputation(反向重算隐状态不存)。Mamba-3B 推理吞吐 5× 于同参 Transformer、质量匹配 2× 参数的 Transformer[4]。
Mamba-2 的 SSD 怎么统一 SSM 和注意力?
Mamba-2 约束 $A_t = a_t I$(标量衰减),使 SSM 的全序列输出可写成结构掩码注意力,证明 SSM 与注意力对偶(SSD)——线性注意力是这个框架的特例[5]。
标量约束下,矩阵积 $A_{i:j}^\times$ 退化为标量 $a_{i:j}^\times$,SSM 输出 $Y=MX$ 为:
$$\begin{equation} M = (CB^\top) \circ L, \qquad L_{ij} = a_{i:j}^\times \;(i\ge j) \label{eq:attn-linssm-ssd} \end{equation}$$$M$ 是 1-半可分矩阵(下三角子矩阵秩 $\le 1$),这与结构掩码注意力(SMA) $Y=((QK^\top)\circ L)V$ 完全同构($Q\leftrightarrow C$、$K\leftrightarrow B$、$L$ 是掩码)。SSD 统一的是 SSM 与 SMA——SMA 是更大的框架,$L$ 可以是任意结构矩阵;线性注意力是 $L=$ 下三角因果掩码的特例。这正是本篇把线性注意力和 SSM 合篇的深层依据:两者都 softmax-free、都落在 SMA 框架下。
SSD 的实用价值:把序列切 chunk,chunk 内用矩阵乘(Tensor Core 加速)、chunk 间用递推,让 SSM 能用 GPU 矩阵乘单元。Mamba-2 核心层比 Mamba-1 快 2–8×,状态维从 16 扩到 128[5]。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 换算子定位 | 放弃 softmax dot-product,序列写成固定状态递推,无 KV cache |
| 线性注意力 | 核函数 $\phi$ + 右积优先,$O(n^2 d)\to O(nd^2)$ |
| 等价 RNN | $M_s=M_{s-1}+\phi(k_s)^\top v_s$,固定 $d\times d$ 状态 |
| LASP-2 | 传 $d\times d$ 状态不传 KV,通信与序列长无关 |
| SSM | 状态空间递推 $h_t=\bar A h_{t-1}+\bar B x_t$,状态固定大小 |
| Mamba 选择性 | $B/C/\Delta$ 依赖输入,弃卷积、硬件感知 scan |
| SSD | SSM 与结构掩码注意力对偶,线性注意力是其特例 |
@tbl-attn-linssm-takeaway 线性注意力与 SSM 核心知识点
参考资料
- Katharopoulos et al., Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, arXiv:2006.16236, 2020. https://arxiv.org/abs/2006.16236
- Choromanski et al., Rethinking Attention with Performers, arXiv:2009.14794, 2021. https://arxiv.org/abs/2009.14794
- Sun et al., LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid, arXiv:2502.07563, 2025. https://arxiv.org/abs/2502.07563
- Gu & Dao, Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv:2312.00752, 2023. https://arxiv.org/abs/2312.00752
- Dao & Gu, Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv:2405.21060, 2024. https://arxiv.org/abs/2405.21060