记忆分类体系
从表示、时间、内容、控制四个正交维度切分 agent 记忆,建立统一分类框架
核心要点:
- 记忆按四个正交维度分类
- 表示范式:token / 中间表示 / 参数
- 时间尺度:工作 / 短期 / 长期
- 内容类型:情节 / 语义 / 程序性
- 控制策略:启发式 / 提示 / 学习
为什么记忆需要四个维度而不是一个标签?
核心问题:为什么不能简单地把 agent 记忆分成"短期"和"长期"两类?
单一维度会把正交的设计决策混为一谈。一段记忆"存在哪里"(载体)、"活多久"(时间)、"存的是什么"(内容)、"谁来增删改"(控制)是四个独立选择,任意组合都可能出现。学术界 2023 年后形成的共识是用正交分类:CoALA 从认知科学引入内容类型[1],多篇 survey 补上表示范式与控制策略两轴[2][3]。
把四维拆开的价值在于:设计一个 agent 记忆系统时,可以在每根轴上独立选点,而不是套用某个现成系统的整体方案。下文逐维展开。
表示范式:记忆用什么载体存?
核心问题:同样一条"用户偏好深色主题"的记忆,可以用哪几种物理形式保存?
记忆按存储载体分三种范式,从显式到隐式、从短期到长期排列[2]。
| 范式 | 载体 | 特点 |
|---|---|---|
| 自然语言 token | 上下文窗口内的文本、scratchpad、摘要 | 可读、可检索,以短期显式内容为主 |
| 中间表示 | KV cache、隐状态、向量索引 | 隐式、高密度,支持近似检索 |
| 模型参数 | 权重、LoRA adapter、微调 checkpoint | 长期隐式知识,读取零延迟,写入代价高 |
@tbl-agent-memory-representation-paradigms 记忆三种表示范式对比:自然语言 token、中间表示、模型参数的载体与特点
三者的工程权衡是可检视性 vs 读取成本:token 形式人能读能改但占上下文;参数形式读取免费但要重训才能写入;中间表示居中。多数生产系统以 token 形式为主干,因为可 git 版本化、可人工审查(详见 04-文件型外置记忆)。
时间尺度:记忆活多久?
核心问题:agent 的记忆是否都该永久保留?
按存活时长分三档,读写频率和抽象粒度随之递变[3]。
- 工作记忆 (working memory):当前上下文窗口内激活的信息,生命周期等于一个决策周期。
- 短期 / 情节记忆:带时间戳的具体经验(工具调用历史、对话轮次),存在外部 session 日志。
- 长期语义记忆:去语境化的抽象知识,跨会话持久,落在向量索引、知识库或模型权重。
FluxMem 在短期与长期之间补了一层 中期情节记忆 (MTEM),三层结构 STIM → MTEM → LTSM 各承担不同读写频率,并首次把"用哪层"本身建模为可学习决策[4]。这条线索表明时间尺度不是固定三档,而是一个可按任务细分的连续谱。
内容类型:记忆存的是哪种知识?
核心问题:"发生过什么"和"世界是什么样"是同一种记忆吗?
CoALA 直接接地认知科学,把长期记忆按功能分三类[1]。这套划分借鉴认知科学的记忆模型(Atkinson-Shiffrin 多存储结构与 Tulving 的内容分型),是 agent 记忆研究里被引用最广的内容分类。
| 类型 | 定义 | 对应载体 |
|---|---|---|
| 情节记忆 (episodic) | 来自过往决策周期的经验:事件历史、轨迹 | 会话日志、历史存储 |
| 语义记忆 (semantic) | 关于世界和自身的知识 | 外部数据库、RAG corpus、知识图谱 |
| 程序性记忆 (procedural) | 怎么做的隐式 + 显式知识 | 模型权重、代码、skills |
@tbl-agent-memory-content-types 记忆内容类型分类:情节、语义、程序性三类定义及对应存储载体
四者构成一条完整推理链:程序性记忆给出"怎么做",语义记忆给出"规则是什么",情节记忆给出"发生过什么",工作记忆持有"当前在推理什么"[3]。这条链解释了为什么完整的 agent 需要四类记忆协同,而非只做一个向量库。
控制策略:谁决定记忆的增删改?
核心问题:记忆该存该删,是写死规则还是让模型自己判断?
控制权从硬规则逐步上移到学习策略,分三层[3]。这一轴决定了系统的自主程度。
| 策略 | 机制 | 代表 |
|---|---|---|
| 启发式 (heuristic) | 硬编码规则:top-k 检索、每 n 轮摘要、d 天到期删除 | 多数 RAG 系统 |
| 提示自控 (prompted) | 记忆暴露为工具调用,模型自己决定何时读写 | MemGPT 的 archival_memory_search |
| 学习控制 (learned) | 用 RL 训练 store/retrieve/update/discard 为可调用动作 | Agentic Memory RL pipeline |
@tbl-agent-memory-control-strategies 记忆控制策略三层:启发式规则、提示自控、学习控制的机制与代表系统
这层正是 survey 所称 policy-managed 记忆 的来源[2]:控制策略本身成为被优化的对象。从启发式到学习控制,是 agent 记忆从"工程配置"走向"可训练能力"的主线。
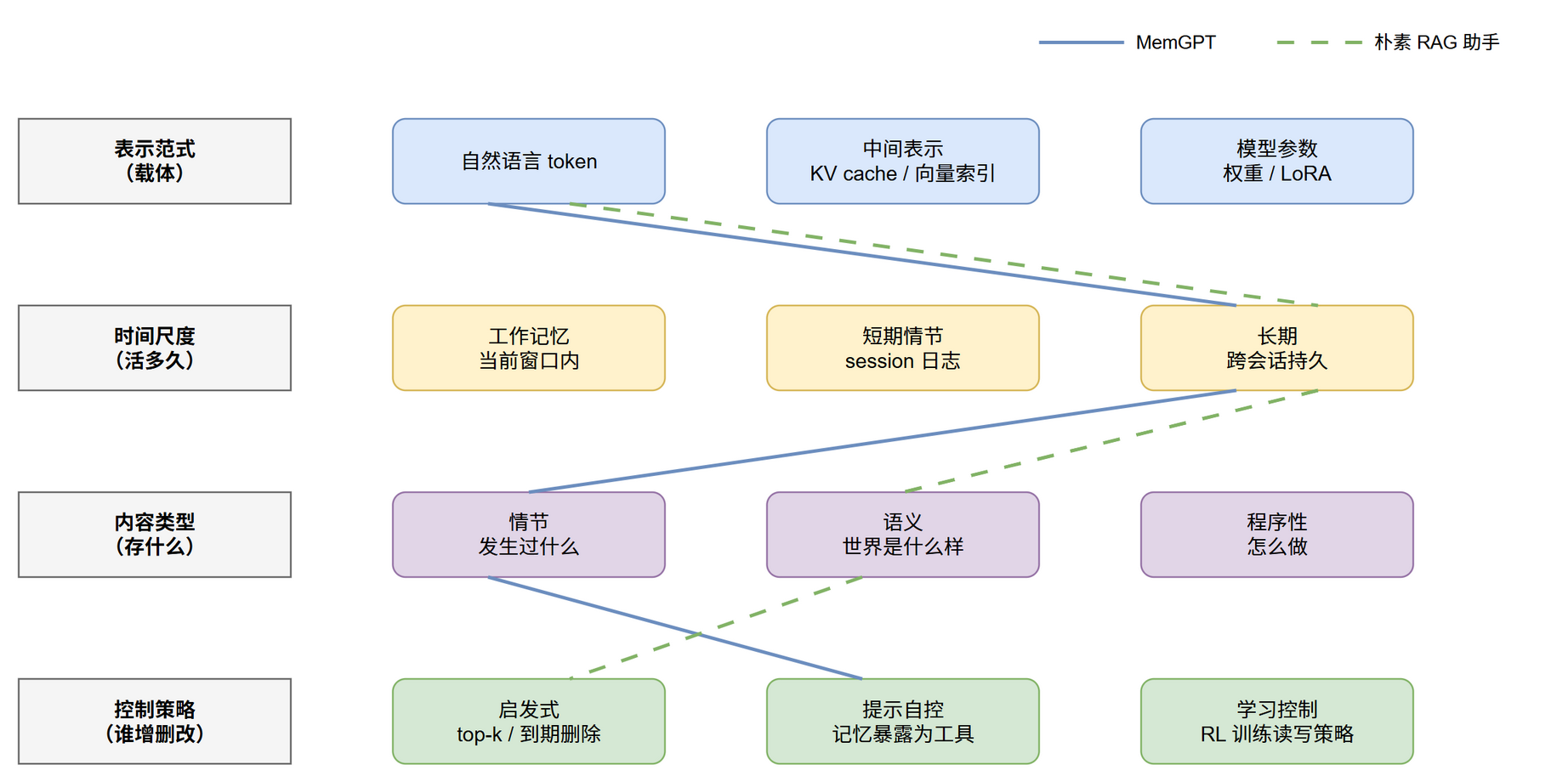
四维如何组合成一个真实系统?
核心问题:一个具体系统在四维上各占哪个点?
真实系统是四维各取一点的组合,不存在"全选"。例如 MemGPT 的组合是:token 表示 + 工作/长期分层 + 情节为主 + 提示自控;一个朴素 RAG 助手则是:token 表示 + 长期 + 语义 + 启发式。
例子:同一条记忆"用户偏好深色主题"在四维上的坐标——
- 表示:token(写成一句话存文件或向量库),而非塞进模型参数。
- 时间:长期(跨会话持久),不是只活一个回合的工作记忆。
- 内容:语义(关于用户的稳定事实),不是某次具体事件的情节记忆。
- 控制:可以是启发式(命中关键词就召回)或提示自控(模型判断该不该用)。
换一条"用户上次让我把超时改成 30s"则落在 情节 + 短期,坐标完全不同——这说明同一系统里不同记忆条目可以占不同坐标,四维是逐条而非整体的。
判断一个记忆方案是否完备,可以逐维自查:载体是否匹配读写频率?时间分层是否够细?四类内容是否都有落点?控制是否过度依赖硬规则?这套四维坐标也是 07-生产记忆系统对标 横向比较各系统的基准。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 四维正交 | 表示 × 时间 × 内容 × 控制,独立选点,不可混为一谈 |
| 表示范式 | token(可检视) / 中间表示(高密度) / 参数(零延迟读、高代价写) |
| 时间尺度 | 工作 → 短期情节 → 长期语义,可继续细分(MTEM) |
| 内容类型 | 情节(发生过什么) / 语义(世界是什么) / 程序性(怎么做),源自认知科学 |
| 控制策略 | 启发式 → 提示自控 → 学习控制,自主程度递增 |
| 设计含义 | 设计记忆系统 = 在四根轴上各选一点,逐维自查完备性 |
参考资料
- Sumers et al. Cognitive Architectures for Language Agents (CoALA). arXiv:2309.02427, 2023. https://arxiv.org/abs/2309.02427
- Tang et al. LLM Agent Memory: A Survey from a Unified Representation-Management Perspective. Preprints.org 202603.0359, 2026. https://www.preprints.org/manuscript/202603.0359
- Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers. arXiv:2603.07670, 2026. https://arxiv.org/html/2603.07670v1
- Lu et al. Choosing How to Remember: Adaptive Memory Structures for LLM Agents (FluxMem). arXiv:2602.14038, 2026. https://arxiv.org/abs/2602.14038
延伸阅读
- Shichun Liu et al. Memory in the Age of AI Agents: A Survey. https://github.com/Shichun-Liu/Agent-Memory-Paper-List
- 06-记忆操作生命周期 — 分类之后,记忆如何被增删改查