mHC
用 Birkhoff 流形约束把单流残差扩展为四路并行残差流
核心要点:
- Seesaw 困境:Pre-LN 单残差权重偏 identity → 表征退化;偏子层 → 梯度消失
- HC 思路:把残差从 $\mathbb{R}^d$ 扩到 $\mathbb{R}^{n_{hc} \times d}$,多路并行承担不同深度行为
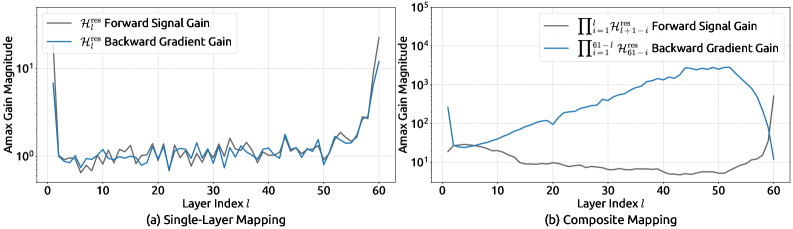
- HC 实测不稳:60 层 27B 上 composite mapping 的 Amax 峰值 ~3000(论文 Fig. 3b),训练 loss 比 mHC 高约 0.007 且持续不收敛
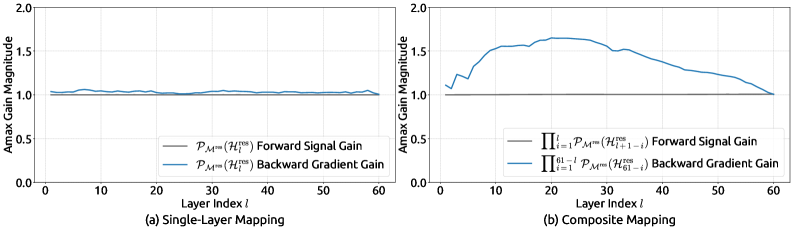
- mHC 流形约束:$\mathcal{H}_l^{\text{res}}$ 投影到 Birkhoff 多面体 (双随机矩阵凸包),保证 non-expansive + 多层闭包,composite Amax 压到 ~1.6(3 个数量级下降)
- Sinkhorn-Knopp:交替行 / 列归一化 $t_{\max}=20$ 步,初始 $\exp(\tilde{\mathcal{H}}^{\text{res}})$ 起步,投影未约束矩阵到双随机
- 关键超参:$n_{hc}=4$,$\alpha$ 初始化 $0.01$,Layer Norm $\epsilon=10^{-20}$
- 工程代价:激活 4×;TileLang 3-kernel 融合 + Sinkhorn 反向重算 + 选择性 recomputation(块大小 $L_r^* \approx \sqrt{nL/(n+2)}$)+ DualPipe 三 stream → wall-time overhead 6.7%
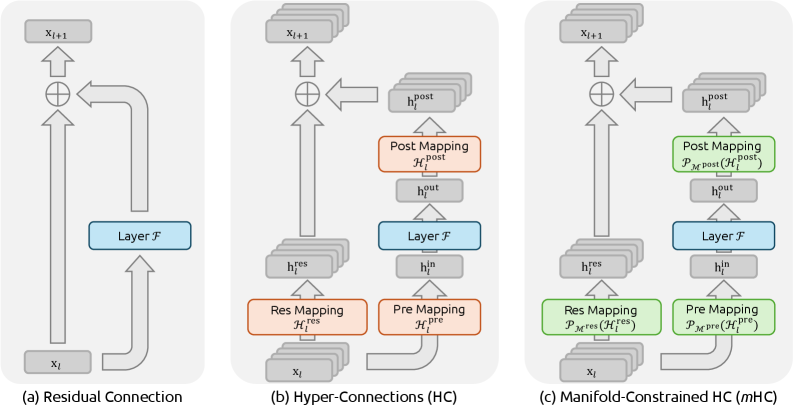
mHC 是 DeepSeek V4 替代标准残差连接的核心机制 — 把单流残差 $x' = x + f(x)$ 扩展为 4 路平行残差流,并通过把混合矩阵约束在 Birkhoff 多面体 (双随机矩阵的凸包) 上来保证训练稳定。
标准残差出了什么问题
核心问题:Pre-LN Transformer 的单残差为什么深层 scale 不上去?
Pre-LN Transformer 普遍采用形如
$$\begin{equation} x_{l+1} = x_l + \mathcal{F}_l(\mathrm{LN}(x_l)) \label{eq:dsv4-mhc-residual} \end{equation}$$的单残差路径。这种设计存在长期被观察到的两难 — Seesaw Effect (Zhu et al., 2024[1]):
- 残差权重偏向 $x_l$ (identity 路径强) → 解决梯度消失,但深层信息无法充分聚合,表征退化 (representation collapse)
- 残差权重偏向 $\mathcal{F}_l$ (子层路径强) → 表征更新充分,但梯度更易消失
Hyper-Connections (HC) 的提出动机是用多条平行残差流取代单流,让网络在不同流上分别承担不同的"深度行为" — 有的流偏 identity 保留信号,有的流偏聚合学习深层表示,混合矩阵根据输入动态调整偏重。
标准 HC 怎么工作
核心问题:HC 的三个映射 $A_l$ / $B_l$ / $C_l$ 各自角色是什么?为什么 HC 在深层堆叠下不稳?
HC 把残差状态从 $\mathbb{R}^d$ 扩到 $\mathbb{R}^{n_{hc} \times d}$, V4 中 $n_{hc} = 4$。
令第 $l$ 层输入 $X_l \in \mathbb{R}^{n_{hc} \times d}$ (行堆叠:第 $i$ 行为残差流 $i$ 的隐藏状态 $\mathbf{x}_{l,i} \in \mathbb{R}^d$),三个学习的线性映射:
- 输入映射 $A_l \in \mathbb{R}^{1 \times n_{hc}}$:把 $n_{hc}$ 路加权汇总为 1 路 $A_l X_l \in \mathbb{R}^d$,送入实际子层 $\mathcal{F}_l$
- 残差映射 $B_l \in \mathbb{R}^{n_{hc} \times n_{hc}}$:在 $n_{hc}$ 路之间重新混合
- 输出映射 $C_l \in \mathbb{R}^{n_{hc} \times 1}$:把子层输出广播回 $n_{hc}$ 路
更新规则:
$$\begin{equation} X_{l+1} = B_l X_l + C_l \mathcal{F}_l(A_l X_l) \label{eq:dsv4-mhc-hc-update} \end{equation}$$$\mathcal{F}_l$ 的输入 / 输出仍是 $d$ 维 (attention 子层或 MoE 子层均不感知残差宽度)。
HC 的理论价值:
- 残差宽度 $n_{hc}$ 解耦于隐藏维度 $d$,参数代价仅在 $A_l$ / $B_l$ / $C_l$ 这三个小矩阵
- $B_l$ 提供"流间重路由"能力,可让某些流主要承担 identity / 其他流承担学习
HC 的实际问题 (mHC 论文 §3.1 实证 — 27B / 60 层 MoE 训练 5 万步):
- $\mathcal{H}_l^{\text{res}}$ 谱无约束。论文用 Amax Gain Magnitude 度量稳定性:定义为 composite mapping $\prod_{i=1}^{l} \mathcal{H}_{l+1-i}^{\text{res}}$ 的最大行 / 列绝对和
- 单层 HC(Fig. 3a):Amax ~1,看起来正常;但 多层 composite(Fig. 3b):Amax 峰值可达 3000,反向梯度 gain 在中间层(20-50 层)持续放大三个数量级
- 训练 loss vs mHC 的绝对差距持续 ~0.005-0.007 不收敛 (论文 Fig. 2a),gradient norm 大幅震荡 (Fig. 2b)
mHC 的流形约束怎么保稳定
核心问题:把 $B_l$ 限制在 Birkhoff 多面体上能保证什么数学性质?为什么这等于训练稳定?
mHC (Xie et al., 2026[2]) 的核心改动是把 $B_l$ 约束在 Birkhoff 多面体 $\mathcal{M}$ 上 — 所有非负、行和列和都为 1 的方阵的凸包:
$$\begin{equation} B_l \in \mathcal{M} := \{ M \in \mathbb{R}^{n \times n} \mid M \mathbf{1}_n = \mathbf{1}_n,\ \mathbf{1}_n^T M = \mathbf{1}_n^T,\ M \ge 0 \} \label{eq:dsv4-mhc-birkhoff} \end{equation}$$这种约束带来三个关键性质:
- 谱范数有界:$\|B_l\|_2 \le 1$。双随机矩阵每行和、每列和均为 1,所以 $\|B_l\|_1 = \|B_l\|_\infty = 1$;由矩阵范数的几何均值不等式 $\|M\|_2 \le \sqrt{\|M\|_1 \|M\|_\infty}$ 立得 $\|B_l\|_2 \le 1$ (Perron-Frobenius 给出的是谱半径 $\rho(B_l)=1$,不直接得到谱范数界)。这保证残差映射严格 non-expansive,前向不会爆炸
- 闭包性:$M_1 M_2 \in \mathcal{M}$。多层 mHC 堆叠后整体残差路径仍保持 non-expansive,对深网络至关重要
- 行和列和守恒:信号"总量"在残差混合中守恒,避免某些流被静默归零
输入映射 $A_l$ 和输出映射 $C_l$ 也需要约束以避免 signal cancellation:通过 Sigmoid 函数把它们压到 $[0, 1]$ ($C_l$ 的上界改为 2),保证非负且有界。
约束的实测效果 (论文 §5.4 + Fig. 7):mHC 的 composite mapping Amax 在 60 层全程稳定在 ~1.6,相比 HC 的 ~3000 降低三个数量级。残差信号 / 反向梯度 gain 在层间分布近似均匀(Fig. 8 的矩阵可视化对比:HC 散乱大值斑块 vs mHC 均匀分布)。
动态参数化怎么实现
核心问题:mHC 三个映射怎么从输入动态生成?$\alpha$ 初始化为什么是关键?
mHC 的三个映射不是固定参数,而是输入依赖 — 根据当前 token 状态生成。每个映射拆分为"动态项 + 静态项"。
输入 $X_l \in \mathbb{R}^{n_{hc} \times d}$ 先 flatten + RMSNorm:
$$\begin{equation} \hat{X}_l = \mathrm{RMSNorm}(\mathrm{vec}(X_l)) \in \mathbb{R}^{1 \times n_{hc} d} \label{eq:dsv4-mhc-rmsnorm} \end{equation}$$然后生成未约束的原始参数:
$$\begin{align} \tilde{A}_l &= \alpha_l^{\text{pre}} \cdot (\hat{X}_l W_l^{\text{pre}}) + S_l^{\text{pre}} \label{eq:dsv4-mhc-a-tilde}\\ \tilde{B}_l &= \alpha_l^{\text{res}} \cdot \mathrm{Mat}(\hat{X}_l W_l^{\text{res}}) + S_l^{\text{res}} \label{eq:dsv4-mhc-b-tilde}\\ \tilde{C}_l &= \alpha_l^{\text{post}} \cdot (\hat{X}_l W_l^{\text{post}})^T + S_l^{\text{post}} \label{eq:dsv4-mhc-c-tilde} \end{align}$$其中:
- $W_l^{\text{pre}} \in \mathbb{R}^{n_{hc} d \times n_{hc}}$, $W_l^{\text{post}} \in \mathbb{R}^{n_{hc} d \times n_{hc}}$, $W_l^{\text{res}} \in \mathbb{R}^{n_{hc} d \times n_{hc}^2}$:学习的动态权重 (论文中记作 $\varphi_l^{\text{pre}} / \varphi_l^{\text{post}} / \varphi_l^{\text{res}}$)
- $\mathrm{Mat}(\cdot)$ 把长度 $n_{hc}^2$ 的向量 reshape 成 $n_{hc} \times n_{hc}$ 矩阵
- $S_l^{\text{pre}} \in \mathbb{R}^{1 \times n_{hc}}$, $S_l^{\text{post}} \in \mathbb{R}^{n_{hc} \times 1}$, $S_l^{\text{res}} \in \mathbb{R}^{n_{hc} \times n_{hc}}$:学习的静态 bias
- $\alpha_l^{\text{pre}}, \alpha_l^{\text{res}}, \alpha_l^{\text{post}} \in \mathbb{R}$:可学的 gating 标量,初始化为 $0.01$ (论文 §4.2 实测值,不是泛指"小值")
- RMSNorm $\epsilon = 10^{-20}$ — 用极小 $\epsilon$ 是为了让 $\hat{X}_l$ 的方差归一化更精确,避免 dynamic projection 的 scale 漂移
$\alpha = 0.01$ 初始化是论文记录的具体超参,不是经验法则:训练初期 $\alpha \tilde{X}_l W$ 项贡献 ~1% 量级,网络几乎只依赖静态 bias $S$ (等效一个固定权重的经典残差),随训练推进 $\alpha$ 渐增,动态成分逐步生效,避免训练早期被未充分学习的动态权重打乱。
混合精度策略 (论文 §4.3):
| 组件 | 数据类型 | 说明 |
|---|---|---|
| 动态投影 $\varphi$ 的 GEMM | TF32 | 内部累加用 TF32 保精度 |
| 残差状态 $X_l$ | BF16 | 与主模型权重同精度 |
| Sinkhorn-Knopp 迭代中间 / RMSNorm 累加 | FP32 | 数值敏感操作必须升精度 |
@tbl-dsv4-mhc-mixed-precision mHC 三个子操作的数据类型选择
Sinkhorn-Knopp 投影怎么做
核心问题:怎么把未约束的 $\tilde{B}_l$ 投影到 Birkhoff 多面体上?为什么行列双向归一化才正确?
得到未约束 $\tilde{B}_l$ 后,需要投影到 Birkhoff 多面体。mHC 用 Sinkhorn-Knopp 迭代 完成:
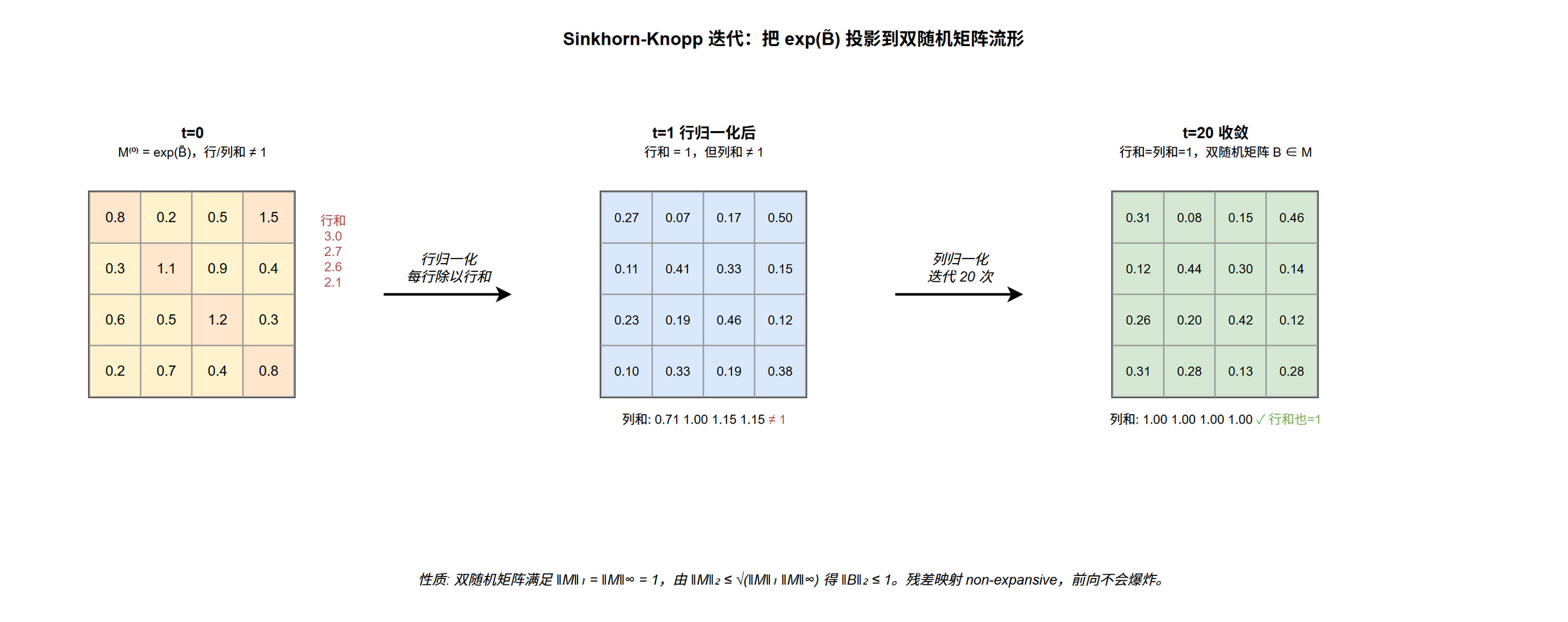
第 0 步 (保证正性):
$$\begin{equation} M^{(0)} = \exp(\tilde{B}_l) \label{eq:dsv4-mhc-sinkhorn-init} \end{equation}$$迭代步 (交替行 / 列归一化):
$$\begin{equation} M^{(t)} = \mathcal{T}_r(\mathcal{T}_c(M^{(t-1)})) \label{eq:dsv4-mhc-sinkhorn} \end{equation}$$$\mathcal{T}_r$ 表示行归一化 (每行除以行和),$\mathcal{T}_c$ 表示列归一化。迭代收敛到双随机矩阵 $B_l = M^{(t_{\max})}$。V4 实际取 $t_{\max} = 20$ 次迭代。
对照传统 attention 中"行 softmax + 列归一化"的做法:
- 那种做法只对行归一化,列和无约束 → 不在 Birkhoff 多面体上 → 失去闭包性和谱范数有界性
- Sinkhorn-Knopp 双向归一化才严格落在流形上,多层堆叠才稳定
输入 / 输出映射约束相对简单:
$$\begin{equation} A_l = \sigma(\tilde{A}_l), \quad C_l = 2\sigma(\tilde{C}_l) \label{eq:dsv4-mhc-gate} \end{equation}$$$\sigma$ 即 Sigmoid。
mHC 的工程代价能压到多少
核心问题:mHC 的内存 / 通信 / 计算开销在哪?论文用什么手段把 overhead 压到 6.7%?
mHC 的代价集中在三处,论文 §3.2 给出精确量化公式:
| 维度 | 标准残差 | HC / mHC | 论文 §3.2 |
|---|---|---|---|
| 每 token 内存读 | $2C$ | $(5n+1)C + n^2 + 2n$ | 11C → 21C (n=4) |
| 每 token 内存写 | $C$ | $(3n+1)C + n^2 + 2n$ | 1C → 13C (n=4) |
| 激活体量 | $C$ | $nC$ | ×4 |
| 跨 PP stage 传输 | $C$ | $nC$ | ×4 通信量 |
| 额外 GEMM | 0 | 3 个 $\varphi$ + 20 步 Sinkhorn | — |
@tbl-dsv4-mhc-io-cost mHC vs 标准残差的内存 I/O 与计算成本($C=d=$hidden dim)
论文 §4.3 三项工程优化把 wall-time overhead 压到 6.7%:
TileLang Kernel Fusion (§4.3.1)
mHC 通过 TileLang 实现三类专用 kernel:
| Kernel | 内含操作 | 优化点 |
|---|---|---|
| Pre kernel (Eq. 14-15) | 2 次 RMSNorm + 动态 $\varphi^{\text{pre}}$ → Sigmoid | forward / backward 各融为单 kernel,省 ATen 层多次启动 |
| Post-Res fused kernel (Eq. 16-18) | $\mathcal{H}^{\text{post}} \cdot \mathcal{F} + \mathcal{H}^{\text{res}} X$ 合并 | 读取量从 $(3n+1)C$ 降到 $(n+1)C$ |
| Sinkhorn kernel (Eq. 19) | $\exp$ + 20 步行列归一化 | backward 自定义重算中间矩阵 $M^{(t)}$,避免存 20 份 $n\times n$ 张量 |
@tbl-dsv4-mhc-kernels TileLang 三 kernel 划分
选择性 Recomputation (§4.3.2)
backward 不缓存全部中间张量,只把每 $L_r$ 层的第一层输入 $X_{l_0}$ 存下,块内其他层 forward-on-demand 重算。最优块大小:
$$\begin{equation} L_r^* \approx \sqrt{\frac{nL}{n+2}} \label{eq:dsv4-mhc-recompute} \end{equation}$$其中 $L$ 是总层数。该公式由 "存的字节数 $nC \cdot \lceil L/L_r \rceil$" + "重算字节数 $(n+2)C \cdot L_r$" 对 $L_r$ 求导极小化得来。$n=4, L=60$ 代入得 $L_r^* \approx 6.3$,即每 6 层一个 checkpoint。
DualPipe 三 Stream 调度 (§4.3.3)

- High-priority compute stream:专跑 $\mathcal{F}^M_{\text{post,res}}$ 的 MLP kernel,与主 attention 路径 overlap
- 避免 persistent kernel:attention 层不用常驻 kernel,留出抢占窗口让 mHC kernel 切入
- Recomputation 解耦 pipeline 依赖:每 stage 本地缓存 $X_{l_0}$,重算不阻塞 PP send-recv
Sinkhorn 输出维度极小问题
mHC 内部涉及一个输出维度仅为 24 的矩阵乘法 ($n_{hc} + n_{hc}^2 + n_{hc} = 4 + 16 + 4 = 24$,对应 $\tilde{A}_l$ / $\tilde{B}_l$ / $\tilde{C}_l$ 拼接后的总输出)。小输出维度 GEMM 在小 batch 下必须用 split-k 分解,但 split-k 默认实现非确定(依赖原子加法)。论文为此自研确定性 split-k:每个 split 分别输出到独立 buffer,后续用确定性 reduction kernel 合并,保证 bitwise 可复现。
mHC 论文实证结果
核心问题:mHC 在什么规模上验证过?相比 HC / 标准残差具体涨多少?
mHC 论文 §5 在 4 个 MoE 规模上做了对照实验:
| 模型 | 总参数 | 激活参数 | 层数 $L$ | hidden $C$ | Routed expert | Tokens |
|---|---|---|---|---|---|---|
| 3B | 3B | — | — | — | 6 active + 2 shared | 39.3B |
| 9B | 9B | — | — | — | — | 105B |
| 27B | 27B | 4.14B | 30 | 2560 | 72 routed (6+2 shared) | 262B |
| 3B-1T | 3B | — | — | — | — | 1.05T |
@tbl-dsv4-mhc-paper-models mHC 论文实验配置(论文 Table 5;27B 配置最完整)
27B 主结果 (论文 Table 4,5 万训练步):
| Benchmark | Baseline | HC | mHC | Δ(mHC − Baseline) |
|---|---|---|---|---|
| BBH (EM) | 43.8 | 48.9 | 51.0 | +7.2 |
| DROP (F1) | 47.0 | 51.6 | 53.9 | +6.9 |
| GSM8K (EM) | 46.7 | 53.2 | 53.8 | +7.1 |
| HellaSwag (Acc.) | 73.7 | 74.3 | 74.7 | +1.0 |
| MATH (EM) | 22.0 | 26.4 | 26.0 | +4.0 |
| MMLU (Acc.) | 59.0 | 63.0 | 63.4 | +4.4 |
| PIQA (Acc.) | 78.5 | 79.9 | 80.5 | +2.0 |
| TriviaQA (EM) | 54.3 | 56.3 | 57.6 | +3.3 |
@tbl-dsv4-mhc-benchmarks 27B 模型上 mHC vs HC vs 标准残差对比(mHC 论文 Table 4)
消融 (论文 Table 1,相对 mHC 的绝对 loss gap):
| 移除组件 | Δ Loss |
|---|---|
| 移除 $\mathcal{H}_l^{\text{post}}$ | +0.027 (影响最大) |
| 移除 $\mathcal{H}_l^{\text{pre}}$ | +0.025 |
| 移除 $\mathcal{H}_l^{\text{res}}$ 约束 (退回 HC) | +0.022 |
@tbl-dsv4-mhc-ablation 三个映射的消融(loss gap 越大代表组件越关键)
关键观察:
- mHC 在所有 8 项 benchmark 上全面超过 HC 和 baseline,MATH 上 HC 略高 0.4 但落在噪声范围内
- $\mathcal{H}_l^{\text{post}}$ 移除影响最大 — 说明"广播回多流"比"输入混合"更关键
- HC 流形约束的引入只是消融排第三,但整篇论文为它做了流形理论、Sinkhorn 投影、确定性 split-k 三层工程 — 因为没有约束 HC 在 60+ 层规模会 loss spike 而无法训练完
mHC 跟原始 HC 关系是什么
核心问题:mHC 的工作脉络 + 后续业界跟进?
| 工作 | 时间 | 团队 | 贡献 |
|---|---|---|---|
| Hyper-Connections | 2024-09 (arXiv 2409.19606) | 字节跳动 Seed (Zhu et al.) | 提出多路残差 + 动态混合,验证在 dense / sparse LLM + 视觉任务 |
| mHC | 2026 | DeepSeek (Xie et al.) | 把 $B_l$ 约束到 Birkhoff 流形 + Sinkhorn-Knopp 投影,解决 HC 训练不稳问题 |
| DeepSeek V4 | 2026-04 | DeepSeek | 首次在 1.6T 级 MoE 上验证 mHC 的可 scale 性 |
@tbl-dsv4-mhc-lineage HC 与 mHC 的工作脉络
后续业界跟进 (基于 arXiv 截至 2026-05 的检索结果):
- JPmHC (Sengupta et al., arXiv 2602.18308):把混合矩阵推广到 Stiefel / Grassmann 等流形,用 Cayley 变换避免 Sinkhorn 迭代
- EΔ-MHC-Geo Transformer (Shahmansoori, arXiv 2605.06729): mHC + Deep Delta Learning + Cayley 旋转的统一框架
- MGT (Manifold-Geometric Transformer) (Su & You, arXiv 2601.01014):把 mHC 解释为"残差约束在局部切空间上"
- Ablate and Rescue (Peng et al., arXiv 2603.14833):首个开源 mHC 语言模型 + 探索多路残差的功能分化
mHC 已经从单一架构创新发展成一个几何约束残差的新研究分支。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| Seesaw 困境 | Pre-LN 单残差偏 identity → 表征退化;偏子层 → 梯度消失 |
| HC 思路 | 残差扩到 $n_{hc} \times d$ 路,三映射动态混合;但 $\mathcal{H}^{\text{res}}$ 谱无约束 → 27B/60 层 composite Amax ~3000 |
| mHC 流形约束 | $\mathcal{H}^{\text{res}} \in$ Birkhoff 多面体,$\|\cdot\|_2 \le 1$ non-expansive;composite Amax 压到 ~1.6(3 个数量级) |
| Sinkhorn-Knopp | 初始 $\exp(\tilde{\mathcal{H}}^{\text{res}})$ + 交替行 / 列归一化 $t_{\max}=20$ 步 |
| 关键超参 | $n_{hc}=4$,$\alpha$ 初始化 $0.01$,RMSNorm $\epsilon=10^{-20}$ |
| 27B 实证 | mHC 在 8 项 benchmark 全面胜 baseline(BBH +7.2 / MMLU +4.4) |
| 工程代价 | I/O 读写涨 ~2×~13×,激活 ×4;TileLang 3-kernel + $L_r^* = \sqrt{nL/(n+2)}$ + DualPipe 三 stream → wall-time 仅 +6.7% |
| 确定性 split-k | mHC 内部 24 维 GEMM 需 split-k,论文自研确定性 reduction kernel 保 bitwise 可复现 |
| 业界脉络 | HC (字节 2024) → mHC (DeepSeek 2026, arxiv 2512.24880) → JPmHC / MGT / Ablate 等几何约束残差分支 |
参考资料
- Zhu et al., Hyper-Connections, arXiv 2409.19606, 2024.
- Xie et al., mHC: Manifold-Constrained Hyper-Connections, arXiv 2512.24880, 2026.