MoE 架构与路由策略
核心要点:
- DeepSeekMoE 框架:细粒度专家划分 + 共享专家隔离,是 V2/V3/V4 通用基础
- V4 路由函数:$\sqrt{\text{Softplus}}$ 替 Sigmoid,避免饱和 + 亚线性抑制 outlier
- 取消路由节点约束:V3 强制 ≤4 节点,V4 全局 top-6 自由选,靠工程吃下不均衡 All-to-All
- 前 3 层 Hash routing:稳定训练初期,后续层 learned routing
- Wave-scheduled EP: 1.92× 理论加速,实测通用 1.5-1.73× / RL rollout 1.96×
- 硬件平衡点:$C/B \le 2d = 6144$ FLOPs/Byte,超过此带宽收益递减
DeepSeek V4 的 MoE 模块沿用 DeepSeekMoE 框架 (V2 / V3 一脉),但在路由函数、负载均衡、前层路由策略三方面做了升级。
DeepSeekMoE 框架做了什么
核心问题:DeepSeekMoE 跟 GShard / Switch Transformer 的核心区别是什么?
DeepSeekMoE (Dai et al., 2024) 相对于 GShard / Switch Transformer 的核心区别在两点。
细粒度专家划分 (Fine-Grained Expert Segmentation)
- 传统 MoE 用少量大专家 (如 8 或 16 个),每个 expert 中间维很大
- DeepSeekMoE 把每个大专家切成多个小专家,专家总数从 8/16 增到 256/384,单 expert 中间维变小
- 直觉:更多更小的专家让"专家组合"的表达力指数增长,相当于在固定参数预算下显著提升表达粒度
共享专家隔离 (Shared Expert Isolation)
- 每个 token 除了 top-k 路由专家,还强制激活 1 个共享专家
- 共享专家承担"所有 token 都需要的通用知识" (词法 / 语法 / 通用世界知识)
- 路由专家可以专注捕获"领域特定"的差异化模式
- 这种分工让路由 entropy 更高 (专家分工更明确),训练更稳
V4 MoE 基础配置:
| 配置 | V4-Flash | V4-Pro |
|---|---|---|
| 共享专家数 | 1 | 1 |
| 路由专家数 | 256 | 384 |
| 每 token 激活路由专家数 (top-k) | 6 | 6 |
| Expert SwiGLU 中间维 | 2048 | 3072 |
| 总 MoE 层数 | 与 Transformer 层数一致 (V4 所有 block 都 MoE,没有 dense FFN) | 同左 |
@tbl-dsv4-moe-config V4 MoE 基础配置
V4 路由函数为什么从 Sigmoid 改 Sqrt(Softplus)
核心问题:路由函数换成 $\sqrt{\text{Softplus}}$ 解决了什么问题?
亲和度分数 (routing affinity) 的计算函数从 V3 的 Sigmoid 改为 $\sqrt{\mathrm{Softplus}(\cdot)}$ (论文 §2.1 原文:"from Sigmoid(·) into Sqrt(Softplus(·))"):
$$\begin{equation} \mathrm{affinity}_{\text{V3}}(x) = \mathrm{Sigmoid}(x) = \frac{1}{1+e^{-x}}, \qquad \mathrm{affinity}_{\text{V4}}(x) = \sqrt{\mathrm{Softplus}(x)} = \sqrt{\ln(1 + e^x)} \label{eq:dsv4-moe-softplus} \end{equation}$$值域对比:
- $\mathrm{Sigmoid}(x) \in (0, 1)$,对大 $x$ 饱和到 1
- $\sqrt{\mathrm{Softplus}(x)} \in [0, \infty)$,对大 $x$ 增长为 $\sqrt{x}$ (亚线性),既不饱和也不像纯 Softplus 那样线性放大
业界推测的三个设计点 (论文 §2.1 未明确说明):
- 避免 Sigmoid 饱和:Sigmoid 让"很相关"与"极其相关"的专家分数都接近 1,区分度模糊。Sqrt(Softplus) 单调上升不饱和,top-k selection 能拉开高分专家的距离
- 亚线性增长抑制 outlier:相比纯 Softplus (大 $x$ 近似线性), $\sqrt{\cdot}$ 让大 logits 增长被开方"软化",避免少数专家分数被无界放大破坏负载均衡
- 梯度行为更平滑:导数 $\frac{1}{2\sqrt{\mathrm{Softplus}(x)}} \cdot \mathrm{Sigmoid}(x)$ 在 $x$ 取负到中等正值的范围内都接近常数量级,不会出现 Sigmoid 在饱和区的梯度消失
负载均衡为什么要 Auxiliary-Loss-Free
核心问题:传统 auxiliary loss 有什么副作用?bias 调整怎么避开?
DeepSeek V3 引入的 auxiliary-loss-free load balancing (Wang et al., 2024) 在 V4 中继续使用,但调整了参数:
- 每个 expert 维护一个 bias,加到该 expert 的亲和度分数上
- 每个训练步根据 expert 接收的 token 数,调整 bias:接收多的减 bias,接收少的加 bias
- V4 中 bias 更新速度 = 0.001
为什么 auxiliary-loss-free 重要:
| 方法 | 副作用 |
|---|---|
| 传统 auxiliary loss (如 Switch Transformer 的 load balance loss) | 引入与主任务对抗的梯度 — 为了均衡专家,可能让模型选择次优 expert |
| Bias 调整 | 只通过 bias 调整分数排序,不改变 expert 内部参数的梯度方向,不与主任务冲突 |
@tbl-dsv4-moe-aux-loss-tradeoff 传统 auxiliary loss 与 bias 调整对比
V4 额外加了一个非常轻的 sequence-level balance loss (权重 0.0001),仅防止单个序列内出现极端不均 (比如所有 token 都路由到同一个 expert)。
V3 的节点路由约束是什么 / V4 为什么取消
核心问题:V3 的 ≤4 节点约束是模型自带还是部署侧加的?V4 取消后用什么消化通信压力?
V3 原文与机制
DeepSeek-V3 §2.1.2 "Node-Limited Routing":
"Like the device-limited routing used by DeepSeek-V2, DeepSeek-V3 also uses a restricted routing mechanism to limit communication costs during training. In short, we ensure that each token will be sent to at most M nodes, which are selected according to the sum of the highest Kr/M affinity scores of the experts distributed on each node."
译:与 V2 的 device-limited routing 类似,V3 也使用受限的路由机制,目的是在训练阶段限制通信成本。具体做法是:保证每个 token 最多被分发到 M 个节点;这 M 个节点的选择标准是 — 对每个节点,取该节点上所有 expert 的 affinity 分数中最高的 Kr/M 个相加,按这个和排序选 top-M。
"Under this constraint, our MoE training framework can nearly achieve full computation-communication overlap."
译:在这一约束下,MoE 训练框架几乎可以做到计算和通信完全 overlap。
V3 配置 (§3.2.2 / §4.2): 256 routed expert + 每 token 激活 8 个 + 保证 ≤4 节点 (M=4)。
V3 约束的三层归属
要回答"≤4 节点是模型自带还是部署时加的",必须把约束拆成三层:
| 层次 | 内容 | 由谁决定 |
|---|---|---|
| A. 路由器输出形状 | 每 token 从 256 expert 中选 top-8 | 模型权重 |
| B. Group 打分逻辑 | router 把 256 expert 分成 8 组,按"组内 top Kr/M affinity 之和"选 top-M=4 组,再在组内选 top-8 | 模型权重 + 训练时固定 |
| C. Group → 物理节点映射 | 一个 expert group 落在哪台机器上 | 部署侧 |
@tbl-dsv3-routing-constraint-layers V3 节点约束的三层归属
- A 层 (top-8 expert):纯模型决定,任何部署都一样
- B 层 (≤4 group):上面原文 "selected according to the sum of the highest Kr/M affinity scores of the experts distributed on each node" 写在 router 的 forward 计算图里,不是后处理;训练阶段一直按 M=4 在跑,router 学到的 affinity 分布天然适配"8 组、每组 32 expert"的结构。因此"router 选出的 top-8 expert 跨越 ≤4 个 group"无论谁部署都成立 — 模型架构 + 训练好的权重共同保证
- C 层 (≤4 物理节点):V3 论文里的 "node" 对应逻辑分组 (expert group),不是天生的物理机器。"4 个物理节点"成立的前提是 DeepSeek 官方的部署假设 — 1 expert group = 1 物理节点 (8 组 → 8 节点训练集群)。换映射后可能有任意数量物理节点
归属结论:
- 模型本身的硬约束 (任何部署都成立):每 token top-8 expert + 这 8 个 expert 跨越的 expert group 数量 ≤ 4
- 部署侧才有的约束 (依赖 expert placement):这 ≤4 个 expert group 横跨多少物理节点
常见误解需要避开:不要说"V3 的 ≤4 节点是 DeepSeek 自己部署时加的限制" — 这只对一半。V3 在训练阶段就硬性按 M=4 训的,模型权重对"≤4 group"有强 inductive bias,不是部署阶段才加的软约束;只是"4 个物理节点"这个具体数字依赖部署侧 expert placement。
V4 原文与配置变化
DeepSeek-V4 §2.1 "Designs Inherited from DeepSeek-V3":
"For DeepSeek-V4, we remove the constraint on the number of routing target nodes, and carefully redesign the parallelism strategy to maintain training efficiency."
译:在 V4 中,我们取消了对路由目标节点数量的约束,并精心重新设计并行策略以维持训练效率。
V4 配置变化:
| 维度 | V3 | V4-Flash | V4-Pro |
|---|---|---|---|
| Routed experts | 256 | 256 | 384 |
| 每 token 激活 | 8 | 6 | 6 |
| 节点路由约束 | ≤4 节点 | 取消 | 取消 |
| Group / node 概念 | 存在 | 论文不再提及 | 论文不再提及 |
@tbl-dsv4-moe-v3-v4-routing-constraint V3 / V4 节点路由约束的配置对比
V4 论文不再出现 group / node 概念 — router 直接从 256 / 384 个 expert 中按全局 affinity 选 top-6,没有任何分组打分约束。
V4 取消约束的逻辑反推
V4 论文只用一句话带过取消的理由 ("carefully redesign the parallelism strategy to maintain training efficiency")。结合架构变化反推的动机:
- 路由质量优先:V3 的 group 打分本质是"先按节点选 group,再选 expert",是通信压力下的妥协,会降低专家特化能力。V4 直接全局选 top-6,路由器更自由
- 激活数从 8 降到 6,总 expert 增到 384:更稀疏的激活让单 token 的 all-to-all 负载本身下降,部分抵消"取消上界"带来的流量增长
- 并行策略重做:V4 用细粒度 EP wave 调度 (见下文),让"当前波次计算 / 下一波次 token 传输 / 已完成 expert 回传"三者并发,配合 DeepEP 风格融合通信 kernel,把不再受约束的 all-to-all 流量 overlap 吃掉
- 代价:all-to-all 流量分布更不均衡 — 论文承认这一点 ("redesign parallelism to maintain efficiency"),但工程手段把它从瓶颈变成可承受成本
一句话对比:V3 用 router 内置的 group / node 约束把通信压到训练能 overlap 的程度 (模型架构层面的妥协);V4 直接拆掉约束让路由按质量选,靠 wave 化 EP + 融合通信 kernel 在工程层面消化更不均衡的 all-to-all (工程层面的进步替代架构层面的限制)。
通信建模含义
V3 跨节点 all-to-all 流量上界应写成:
$$\begin{equation} \text{跨节点 all-to-all 流量} \le (\text{token 数}) \times (\text{≤4 group}) \times (\text{group\_to\_node\_fanout}) \label{eq:dsv4-moe-cross-node-bound} \end{equation}$$group_to_node_fanout 由部署侧 expert placement 决定,DeepSeek 官方部署下 = 1。
V4 取消该约束后,流量上界退化为 top-6 expert 所跨节点数的纯部署函数,无模型侧上界 — 通信模型需按实际 expert placement 与 expert 选中概率分布来估算。
前 3 层为什么用 Hash Routing
核心问题:V4 在前 3 个 MoE 层改用 Hash routing,后续层 learned routing,设计动机是什么?
V4 在前 3 个 MoE 层改用 Hash Routing (Roller et al., 2021),后续层仍用 affinity-based learned routing。
Hash routing 的逻辑:
- 根据 input token ID 的哈希值确定 expert (确定性映射)
- 不依赖学习到的亲和度,纯粹按 token ID 分配
- 每个 token 在浅层固定路由到固定 expert 组合
设计动机 (论文未明说,业界推测):
| 动机 | 解释 |
|---|---|
| 训练初期负载均衡 | learned routing 初期不稳定,前几层 hash 路由保证 expert 利用率均匀 |
| 梯度路径确定 | hash 路由不依赖学习参数,浅层梯度路径稳定,加快收敛 |
| 与 token 表示语义不稳定吻合 | 浅层 token 表征还未充分形成"语义相似性",按 ID 分配比按浅层学到的相似性更合理 |
@tbl-dsv4-moe-hash-routing-motivation 前 3 层用 Hash routing 的设计动机
V3 全部 MoE 层都用 learned routing, V4 这个改动是新的。
MTP 在 V4 中保留了什么
核心问题:V4 的 MTP 跟 V3 完全一致还是有变化?
V4 的 MTP 模块与 V3 完全一致 (MTP 来自 Gloeckle et al., 2024 与 DeepSeek V3 论文):
- 每个位置除了预测 next-1 token,还预测 next-2 token (depth=1)
- 用独立的小型 transformer block 处理 next-2 预测
- 训练时 MTP loss 与 LM loss 联合优化,权重 0.3 (LR decay 阶段降到 0.1)
- 推理时可用 MTP 模块做 speculative decoding (每步并行预测多个 token,验证后接受)
MTP 不只是加速推理 — 联合训练增强主模型的表征质量。V4 没有继续探索 depth > 1 (V3 实验显示 depth=2 相对 depth=1 的额外增益有限)。
Wave-Scheduled EP 怎么把通信吃掉
核心问题:Wave scheduling 跟 Comet 的 dispatch-linear overlap 区别在哪?怎么达到 1.92×?
MoE 的工程瓶颈是 expert 分布在多个节点时的 all-to-all 通信:每个 token 要 dispatch 到 top-6 expert 所在节点,再 combine 回原节点。V4 提出 fine-grained EP scheme + Wave Scheduling (论文 §3.1)。
MoE 层的 4 stage 分解
论文 §3.1 把每个 MoE 层分解为 4 个阶段,2 个 comm-bound + 2 个 compute-bound:
| Stage | 类型 | 内容 |
|---|---|---|
| Dispatch | comm-bound | All-to-All 把 token activation 送到目标 expert 所在 GPU |
| Linear-1 | compute-bound | SwiGLU 的 gate / up projection GEMM |
| Activation + FP8 Cast | compute(轻量) | SwiGLU 非线性 + 重新量化到 FP8 |
| Linear-2 | compute-bound | SwiGLU 的 down projection GEMM |
| Combine | comm-bound | All-to-All 把 expert 输出送回 token 原 GPU |
@tbl-dsv4-moe-stages MoE 层的 5 阶段分解(comm/compute 标注)
关键 insight (论文 verbatim §3.1):
"within a single MoE layer, the total time of communication is less than that of the computation. Therefore, after fusing communication and computation into a unified pipeline, computation remains the dominant bottleneck."
通信时间小于计算时间,完全 overlap 后系统不再受通信带宽约束 — 这是硬件平衡点 $2d=6144$ FLOPs/Byte 公式背后的根本前提。
Wave Scheduling 思路
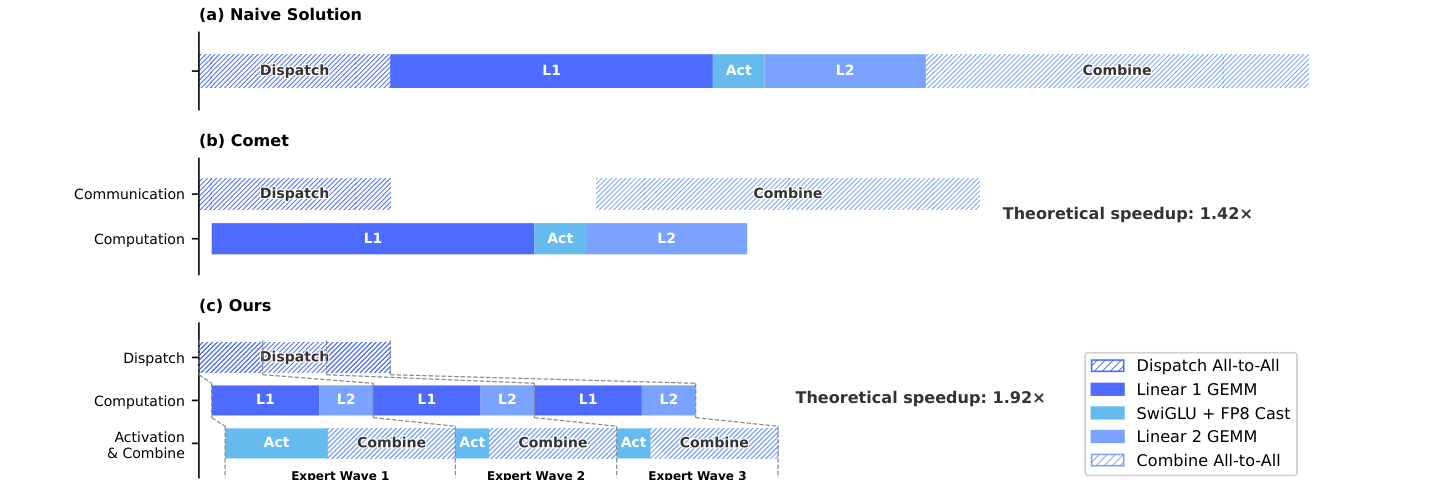
不像 Comet (Zhang et al., 2025) 那样把 dispatch 与 linear-1、combine 与 linear-2 分开 overlap,V4 把 expert 分成多个 wave,每个 wave 是部分 expert 的子集:
- Wave 1 的 expert dispatch 完成后立刻开始 wave 1 的 linear-1 + activation + linear-2
- 同时 wave 2 的 expert 在做 dispatch
- 已完成的 wave 1 立刻开始 combine
- 整个流水线像 N 个 wave 之间的滑动窗口
理论加速:相比 Comet 的 1.42×, V4 wave-scheduling 达到 1.92×。
实测收益
| 场景 | 加速比 |
|---|---|
| 通用推理 workloads | 1.50–1.73× |
| RL rollout / 高延迟敏感场景 | 高达 1.96× |
@tbl-dsv4-moe-wave-speedup Wave-scheduled EP 在不同场景的实测加速比
V4 把 CUDA mega-kernel 实现开源,名为 MegaMoE(作为 DeepGEMM PR #304 集成)。HUAWEI Ascend NPU 平台也做了适配 — 同一个 fine-grained EP scheme 在 NVIDIA / Ascend 两套硬件上都验证过。
Pull-based Dispatch(论文 §3.1 硬件提议节)
V4 的 Dispatch all-to-all 采用 pull-based 模式:每个 GPU 主动从远端 GPU 读取自己需要的 activation,而不是远端 push 过来。原因(论文 verbatim):
"We adopt a pull-based approach where each GPU actively reads activations from remote GPUs, avoiding the high notification latency that fine-grained push entails."
- Push 模式需要 sender 在每个细粒度 chunk 完成后发送 notification,notification latency 在小 chunk 下被放大
- Pull 模式 receiver 主动拉,避免 sync notification 开销
- 论文同时提议:未来硬件如果有更低延迟的 cross-GPU signaling,push 就能变得可行,支持更自然的通信模式
V4 论文给硬件厂商的 4 条具体提议
论文 §3.1 末尾给硬件厂商 4 条建议,是 V4 设计经验的副产品:
| 提议 | 来源观察 |
|---|---|
| Computation-Communication Ratio(即 $C/B \le 2d$) | 互联带宽超 6144 FLOPs/Byte 平衡点后投资递减,应转向算力 / 电源 |
| Power Budget | 极端 kernel fusion 让 compute / memory / network 同时高负载,power throttling 成性能瓶颈 → 硬件需提供 fully-concurrent workloads 的电源裕量 |
| Communication Primitives | 当前 pull-based 是无奈选择,若硬件提供低延迟跨 GPU signaling 则 push 可行 |
| Activation Function | 提议用无 exp / div 的轻量 element-wise activation 替代 SwiGLU,避免 post-GEMM 的 activation 阻塞 GEMM pipeline |
@tbl-dsv4-moe-hardware-proposals V4 论文 §3.1 给硬件厂商的 4 条提议
最反常的一条是 SwiGLU 替换:V4 自己用 SwiGLU 但承认它包含 sigmoid + 乘法,post-GEMM 处理会拖慢整个 pipeline。这是给下一代模型架构的"反向硬件兼容性"建议 — 后续模型若想完全 overlap,激活函数需更便宜。
硬件平衡点分析
完整的通信-计算 overlap 需要满足:
$$\begin{equation} \frac{C}{B} \le \frac{V_{\text{comp}}}{V_{\text{comm}}} \label{eq:dsv4-moe-ratio-bound} \end{equation}$$$C$ 是 peak 计算吞吐 (FLOPs/s), $B$ 是互联带宽 (Bytes/s), $V_{\text{comp}}$ 是 expert 的计算量,$V_{\text{comm}}$ 是通信量。
符号约定:$h$ 表示模型 hidden dim (V4-Pro 为 7168),$d$ 表示 expert SwiGLU 的中间维 (V4-Pro 为 3072)。
V4-Pro 配置下,每个 token-expert pair 需要 $6hd$ FLOPs (SwiGLU 的 gate / up / down 三个 GEMM,每个为 $h \times d$ 或 $d \times h$ 各 $2hd$ FLOPs),但只有 $3h$ Bytes 通信 (FP8 dispatch 占 $h$ Byte + BF16 combine 占 $2h$ Bytes)。化简后通信-计算比为:
$$\begin{equation} \frac{C}{B} \le \frac{6hd}{3h} = 2d = 2 \times 3072 = 6144 \text{ FLOPs/Byte} \label{eq:dsv4-moe-balance} \end{equation}$$结果只依赖 expert 中间维 $d$,与 hidden $h$ 无关 — 因为 SwiGLU 三个 GEMM 总计算量随 $hd$ 线性增长、而通信量随 $h$ 线性增长,分母 $h$ 抵消。
即每 1 GB/s 互联带宽能隐藏 6.1 TFLOPs/s 计算的通信。
论文给硬件厂商的建议:互联带宽超过这个平衡点后继续投入带宽收益递减,应该把硅面积投到其他地方 (如提升单卡算力或加电源裕量)。
V4 的 MoE 工程基建(TileLang + DeepGEMM + 确定性 kernel)
核心问题:V4 论文 §3.2 §3.3 给的 TileLang + 确定性 kernel 库怎么支撑 MoE 的 fine-grained 调度?
TileLang 三大特性(论文 §3.2)
V4 用 TileLang 替代手写 CUDA,把"数百个细粒度 Torch ATen 算子"融成少量 fused kernel。三个关键设计:
| 特性 | 解决的问题 | 效果 |
|---|---|---|
| Host Codegen | Python 侧 per-invocation 校验开销 | CPU validation 从几十~几百 µs 降到 < 1 µs |
| Z3 SMT-Solver 集成 | 编译器对整数表达式的 formal analysis 不够强 → 多优化机会无法触发 | layout inference / memory hazard detection / 向量化等 pass 解锁,编译时间 +几秒 |
| 数值精度可控 | 默认禁用 fast-math,opt-in 用 T.__exp / T.__log;strict IEEE-754 用 T.ieee_fsqrt / T.ieee_fdiv | 配 layout pinning 可达 bitwise reproducible(对 NVCC baseline) |
@tbl-dsv4-moe-tilelang TileLang 三大特性
Batch-Invariant + Deterministic Kernel(论文 §3.3)
为了让 pre-training / post-training / inference 三阶段 bitwise 对齐,V4 实现 batch-invariant kernel。核心难点与解法:
| 操作 | 难点 | V4 方案 |
|---|---|---|
| Attention(decode) | Split-KV 跨多个 SM 破坏 invariance;不用 split-KV 又触发 wave-quantization | Dual-kernel 策略:满 wave 用 single-SM kernel,末尾不满 wave 用 multi-SM kernel + thread-block cluster 的 distributed shared memory;两 kernel 累加顺序对齐保 bitwise 同 |
| Matrix Multiplication | cuBLAS 不保证 invariance;小 batch 用 split-k 又破坏 invariance | 端到端换 DeepGEMM;小 batch 不用 split-k,靠 DeepGEMM 内部优化 |
| MoE 专属 | Wave 调度 + 多 expert → 累加顺序敏感 | MegaMoE 内部约束所有 wave 的 reduction 顺序固定 |
@tbl-dsv4-moe-batch-invariance V4 实现 batch invariance 的 3 个 kernel 改造
直观影响:训练 loss 曲线在不同 batch size / micro-batch 拆分下 bitwise 一致 — 是 debug / 稳定性分析 / RL rollout 离线 replay 的硬前提。
FP4 QAT 怎么做到反量化无损
核心问题:V4 怎么用 FP4 量化又复用 FP8 训练框架?
V4 在后训练阶段引入 FP4 Quantization-Aware Training (QAT),应用于:
- MoE expert 权重:所有路由专家与共享专家的 SwiGLU GEMM
- CSA Lightning Indexer 的 QK 路径:indexer queries 与 compressed keys 的乘法
FP4 → FP8 dequantization 无损
FP4 (MXFP4 E2M1) 与 FP8 (E4M3) 都是低精度浮点:
| 格式 | 指数位 | 尾数位 | Dynamic range |
|---|---|---|---|
| FP4 E2M1 | 2 | 1 | 较窄 |
| FP8 E4M3 | 4 | 3 | 比 FP4 宽很多 |
@tbl-dsv4-moe-fp4-vs-fp8 FP4 E2M1 与 FP8 E4M3 的位宽对比
FP8 比 FP4 多 2 个 exponent bit, dynamic range 大 4 倍。V4 的 FP4 量化以 1×32 sub-block 为粒度 (共享一个 scale factor),FP8 量化以 128×128 tile 为粒度 (共享一个 scale factor)。只要每个 FP8 tile 内不同 FP4 sub-block 的 scale 最大值 / 最小值之比不超过 FP8 exponent 余量,FP4 → FP8 反量化就是无损的。
实测 V4 训练后的 expert 权重满足此条件,因此整个 QAT 流水线可以复用现有 FP8 训练框架,无需任何修改:
- 前向:FP4 权重反量化到 FP8 做计算
- 反向:梯度对 FP8 权重计算,直接传回 FP32 master 权重 (等价于 STE 通过量化操作)
- 推理:直接用原生 FP4 权重
理论上当硬件原生支持 FP4 × FP8 操作 (即将到来的新一代加速器),还能再获得 1/3 加速。
Indexer Score 量化
CSA 的 indexer score $I_{t, s}$ 在前向中要保留 FP32 精度做累加 (保证 top-k 排序稳定)。V4 把它量化到 BF16:
- top-k selector 加速 2×
- 召回率 99.7% (与 FP32 几乎无差)
- KV entry 的 top-k 排序对小数值差异不敏感,BF16 的精度足够
V4 vs V3 MoE 一表速查
核心问题:V4 相对 V3 在 MoE 架构、路由策略、节点约束、训练技巧上有哪些关键变化?
| 维度 | V3 | V4 |
|---|---|---|
| 路由函数 | Sigmoid | $\sqrt{\text{Softplus}}$ |
| 负载均衡 | aux-loss-free (同思路) | aux-loss-free + 序列级 balance loss (0.0001) |
| Routing target node 约束 | 有 | 无 |
| 前几层路由 | learned routing 全程 | 前 3 层 Hash routing |
| MoE 层 vs Dense FFN | 前 3 层 dense FFN + 后续 MoE | 全部 MoE 层 (前 3 层用 Hash routing) |
| Expert 数量 | 256 (V3) | 256 (Flash) / 384 (Pro) |
| 量化 | FP8 | FP8 + 后训练 FP4 QAT for expert |
| EP 通信 | DualPipe overlap | Wave-scheduled MegaMoE,理论加速 1.92× |
@tbl-dsv4-moe-v3-vs-v4 V3 与 V4 MoE 的对比
Takeaway
| 知识点 | 核心结论 |
|---|---|
| DeepSeekMoE 框架 | 细粒度专家划分 + 共享专家隔离,是 V2/V3/V4 通用基础 |
| 路由函数 | $\sqrt{\text{Softplus}}$ 替 Sigmoid,避免饱和 + 亚线性抑制 outlier |
| 负载均衡 | aux-loss-free bias 调整 (更新速度 0.001) + 轻量序列级 loss (0.0001) |
| 取消节点约束 | V3 ≤4 节点是 router 训练硬约束,V4 取消后靠工程 (wave + 融合 kernel) 吃下不均衡 |
| 前 3 层 Hash routing | 稳定训练初期,浅层语义未定按 token ID 分配比 learned 合理 |
| MoE 层 5 阶段分解 | Dispatch / L1 / Act+Cast / L2 / Combine — 通信时间 < 计算时间是 overlap 前提 |
| Wave-scheduled EP | 1.92× 理论加速,实测 1.50-1.73× / RL rollout 1.96×,开源 MegaMoE (DeepGEMM PR #304) |
| 硬件平衡点 | $C/B \le 2d = 6144$ FLOPs/Byte,超过此带宽收益递减 |
| Pull-based Dispatch | receiver 主动读远端 activation,避免细粒度 push 的 notification 延迟 |
| 硬件 4 条提议 | Compute-Comm Ratio / Power Budget / Push-friendly signaling / 替代 SwiGLU 的轻量 activation |
| TileLang 基建 | Host Codegen (CPU 校验 < 1µs) + Z3 SMT 强整数分析 + IEEE-754 opt-in |
| Batch-invariance | Attention dual-kernel + DeepGEMM 替 cuBLAS,pre/post/inference bitwise 对齐 |
| FP4 QAT | sub-block 1×32 scale + FP8 tile 128×128, FP4→FP8 反量化无损,复用 FP8 框架 |