训练流程
从 32T token 预训练到 Specialist 后训练,及 Muon 优化器与 1.6T 零 rollback 稳定性方案
核心要点:
- 预训练数据:32T+ tokens,长文档优先 (科学论文 / 技术报告);4K → 16K → 64K → 1M 序列长度课程
- Muon 优化器:主用于 GEMM 矩阵参数;Hybrid Newton-Schulz 10 步两阶段正交化;AdamW 仅用于 embedding / norm / bias
- 稳定性:Anticipatory Routing (历史参数算路由) + SwiGLU Clamping, 1.6T 训练零 rollback
- 后训练:Specialist (10+ 领域 SFT + GRPO RL) → On-Policy Distillation (full-vocabulary reverse KL)
- 三档推理模式:Non-think (8K) / Think High (128K) / Think Max (384K)
- 基础设施:FP4 QAT 复用 FP8 框架 / token-WAL 抢占式 rollout / DSec Rust 沙箱
V4 的训练流水线分两个大阶段:预训练 (32T+ tokens, Muon 优化器,1M 长度课程) + 后训练 (Specialist Training + On-Policy Distillation)。
预训练数据是什么样
核心问题:32T tokens 怎么组织?长文档为什么是核心?
| 项目 | 配置 |
|---|---|
| 总规模 | 32T+ tokens |
| 来源 | 在 V3 数据基础上扩展,重点加强长文档语料 (科学论文 / 技术报告) / 数学 / 代码 / 多语言 |
| Filtering | 用启发式过滤批量自动生成的模板化内容,避免 model collapse 风险 (Zhu et al., 2024) |
| Tokenizer | 沿用 V3 tokenizer,新增少量 context-construction special token |
| 词表 | 128K |
| Token-splitting + FIM | 沿用 V3 策略 |
| 多文档打包 | 用 Ding et al. (2024) 的方法把不同来源文档打包到适当长度的序列,最小化样本截断 |
| Attention masking | V3 没用,V4 用样本级 attention masking — 同一打包序列中的不同样本互相不可见 |
| 训练 tokens | V4-Flash: 32T; V4-Pro: 33T |
@tbl-dsv4-train-data 预训练数据配置
V4 特别强调"长文档优先" — 科学论文 / 技术报告等结构化长文本帮助模型养成 1M 上下文下的长程注意力能力。
Mid-Training 阶段加入 Agentic 数据(论文 §4.1 verbatim):
"we further enhance the coding capabilities of DeepSeek-V4 series by incorporating agentic data during the mid-training phase."
mid-training 是 pre-training 末段(LR decay 阶段前后)的过渡,专门注入 agent-style 数据(工具调用、多步推理 trace),让 base 模型已具备 agent capability 而不是完全靠 post-training 灌输。
Sample-level Attention Masking(V4 vs V3 的关键差异):
| 版本 | 多文档打包策略 | 跨样本注意力 |
|---|---|---|
| V3 | 打包 | 不 mask,同序列内不同样本可互相 attend |
| V4 | 打包 | sample-level mask,同序列内不同样本互不可见 |
@tbl-dsv4-train-sample-mask V3 vs V4 多文档打包的注意力 mask 差异
V3 的设计可能让短样本拼接时无意中"借用"邻样本的上下文,对 1M 训练阶段(拼接稀疏长样本时)尤其有害。V4 严格 mask 避免污染。
Muon 优化器怎么算
核心问题:Muon 跟 AdamW 区别是什么?为什么 V4 主用 Muon?
优化器分工
V4 用 Muon (Jordan et al., 2024; Liu et al., 2025) 作为主优化器,AdamW 仅用于少数模块:
| 模块 | 优化器 | 原因 |
|---|---|---|
| Embedding 模块 | AdamW | embedding 是 lookup table,更新稀疏,element-wise 优化器更合适 |
| Prediction head | AdamW | 输出投影,类似 embedding |
| 所有 RMSNorm 权重 | AdamW | 1D 向量参数,无需正交化 |
| mHC 的静态偏置 $S$ | AdamW | bias 参数 |
| 其他所有参数 (GEMM 权重) | Muon | 矩阵参数,Muon 正交化更优 |
@tbl-dsv4-train-optimizer-split V4 中各模块的优化器选择
AdamW + Muon 共用超参(论文 §4.2.2)
V4 用统一的超参集让两个优化器协同工作:
| 超参 | AdamW | Muon | 备注 |
|---|---|---|---|
| $\beta_1$ / momentum $\mu$ | 0.9 | 0.95 | Muon 用更高动量利用 trajectory 累积 |
| $\beta_2$ | 0.95 | — | — |
| $\varepsilon$ | $10^{-20}$ | — | 极小 $\varepsilon$ 避免数值漂移 |
| weight decay $\lambda$ | 0.1 | 0.1 | 统一 |
| RMS rescale $\gamma$ | — | 0.18 | Muon 把 update RMS 重缩放到 0.18 |
@tbl-dsv4-train-optimizer-hyper AdamW + Muon 超参(V4-Flash / V4-Pro 共享)
$\gamma=0.18$ 的精妙处:把 Muon update 的 RMS 强制压到 0.18,与 AdamW update 的典型 RMS 量级相当 → 可以复用 AdamW 的 learning rate 调度(Liu et al. 2025 的 reutilization 技巧)。否则 Muon 因 update 量级不同需要重新调 LR,工程上极麻烦。
Muon 核心算法
每个训练步对每个逻辑独立的权重矩阵 $W \in \mathbb{R}^{n \times m}$:
- 计算梯度 $G_t = \nabla_W \mathcal{L}_t(W_{t-1})$
- 累积动量 $M_t = \mu M_{t-1} + G_t$, $\mu = 0.95$
- 混合 Newton-Schulz 正交化 $O_t' = \mathrm{HybridNewtonSchulz}(\mu M_t + G_t)$ (Nesterov trick)
- RMS rescale $O_t = O_t' \cdot \sqrt{\max(n, m)} \cdot \gamma$, $\gamma = 0.18$
- 权重更新 $W_t = W_{t-1} \cdot (1 - \eta \lambda) - \eta O_t$, weight decay $\lambda = 0.1$
Hybrid Newton-Schulz 详解
目标:把梯度矩阵 $M$ 近似正交化为 $UV^T$ (其中 $M = U \Sigma V^T$ 是 SVD)。
V4 采用 10 步两阶段 Newton-Schulz:
$$\begin{equation} M_k = aM_{k-1} + b(M_{k-1} M_{k-1}^T) M_{k-1} + c(M_{k-1} M_{k-1}^T)^2 M_{k-1} \label{eq:dsv4-train-newton-schulz} \end{equation}$$- 阶段 1 (前 8 步):用系数 $(a, b, c) = (3.4445, -4.7750, 2.0315)$ 快速收敛,把奇异值拉近 1。这组系数收敛快但稳定性差,最终奇异值在 1 附近震荡
- 阶段 2 (后 2 步):切换到系数 $(2, -1.5, 0.5)$ — 这是经典 Newton-Schulz 在奇异值已经接近 1 时的局部稳定形式,把奇异值精确锁定在 1
为什么不用 Frobenius normalization?因为 $M_0 = M / \|M\|_F$ 保证最大奇异值不超过 1,但需要先做一次 GEMM 算 $\|M\|_F$。V4 通过 RMS rescale 同等效果但更省。
与 mHC + Q/KV RMSNorm 的协同
Muon 早期论文 (Liu et al., 2025) 配套使用 QK-Clip 防止 attention logits 爆炸。V4 不用 QK-Clip — 因为 attention 模块内部已经在 query / KV entry 上做 RMSNorm (见 2.3 Hybrid Attention)。
训练课程怎么设计
核心问题:LR / batch / 序列长度 / 注意力稀疏化分别怎么调度?
LR 与 batch size
| 阶段 | V4-Flash | V4-Pro |
|---|---|---|
| Peak LR | $2.7 \times 10^{-4}$ | $2.0 \times 10^{-4}$ |
| LR warmup steps | 2000 | 2000 |
| 主体阶段 LR | 恒定 peak | 恒定 peak |
| 最终 LR (cosine 衰减) | $2.7 \times 10^{-5}$ | $2.0 \times 10^{-5}$ |
| Max batch size (tokens) | 75.5M | 94.4M |
@tbl-dsv4-train-lr LR 与 batch size 调度
Batch size 从小逐步升到 max — 经典的"小 batch 探索 + 大 batch 精炼"策略。
序列长度课程
V4 的训练序列长度按 4K → 16K → 64K → 1M 渐进:
- 4K 阶段:让模型先学好短距离依赖
- 16K / 64K:渐进延长,配合 RoPE 的频率调整
- 1M:最后阶段把上下文窗口扩到目标长度
注意力稀疏化课程
V4 的 CSA 稀疏选择不是从训练开始就启用 — 而是有两段式 warmup:
- 前 1T tokens:用 dense attention (CSA 不做 top-k,所有 compressed entry 都参与)
- 64K 序列阶段:开始引入稀疏。先短暂 warmup lightning indexer (让 indexer 学到合理的 query-key 相关性),再切换到正式的 top-k sparse attention
- 剩余训练:sparse attention 保持启用
这种课程避免了"训练初期 indexer 还没学好就强行做 top-k 选择"导致的训练不稳。
MoE 负载均衡参数
- Auxiliary-loss-free bias update speed: 0.001
- Sequence-level balance loss weight: 0.0001
- MTP loss weight: 0.3 (主训练阶段) → 0.1 (LR decay 阶段)
怎么让 1.6T 训练零 rollback
核心问题:万亿 MoE 普遍有 loss spike, V4 用什么手段彻底消除?
万亿参数 MoE 训练普遍存在 loss spike — 突然出现大幅度 loss 上升后短暂恢复。简单 rollback 治标不治本,因为 spike 会反复出现。V4 引入两个互补技术。
Anticipatory Routing
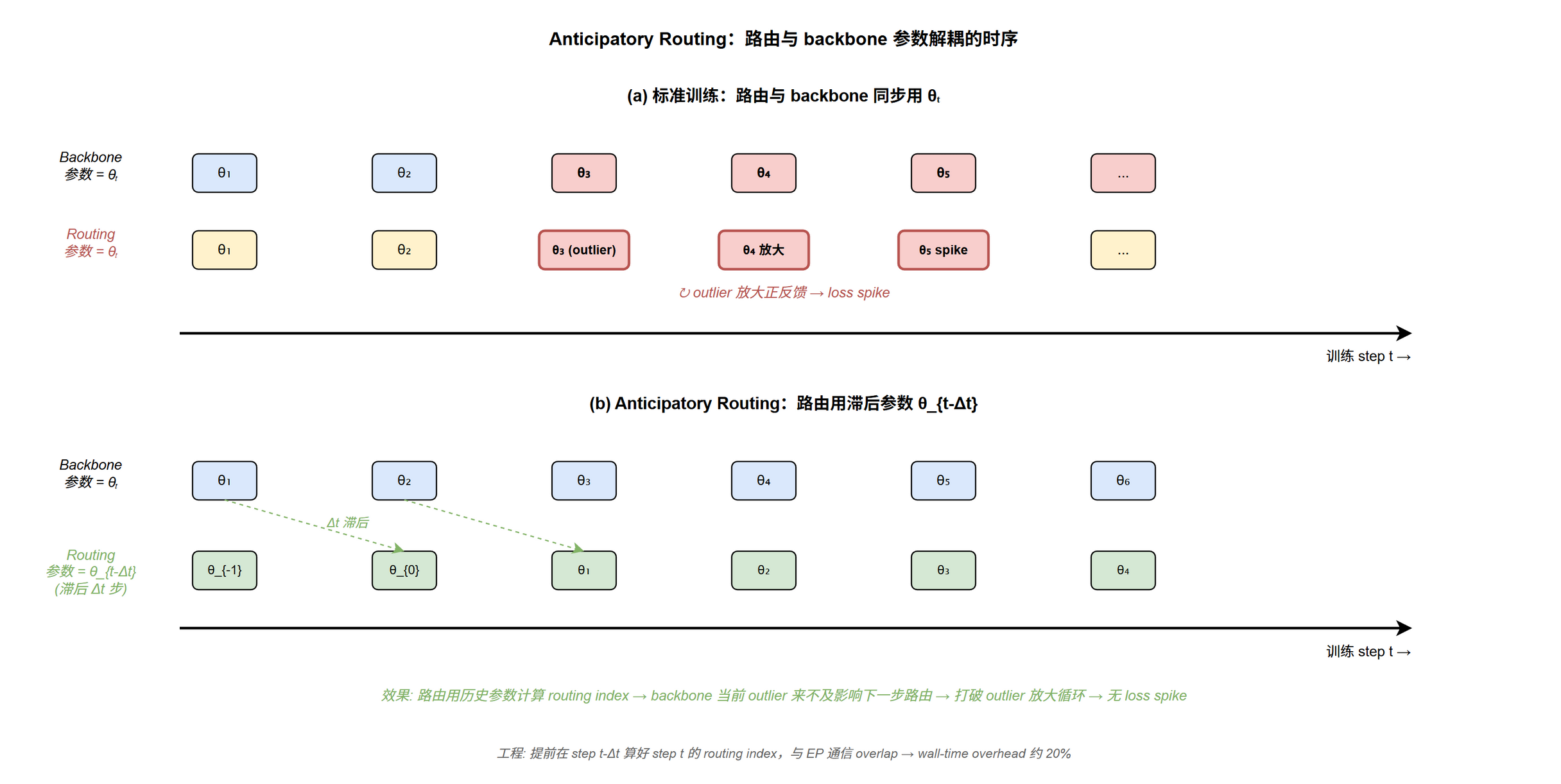
V4 的关键观察:spike 来自 MoE 层的 outlier + 路由的放大循环:
- 某个训练步 MoE expert 输出出现 outlier 值
- Outlier 影响下一步的 routing 输入分布
- Routing 决策因此偏离正常分布,把更多 token 送到产生 outlier 的 expert
- 该 expert 接收异常 token 分布,输出更大的 outlier
- 形成正反馈循环 → loss spike
Anticipatory Routing 打破这个循环:
- 在训练步 $t$,用历史参数 $\theta_{t-\Delta t}$ (落后 $\Delta t$ 步) 计算 routing 决策
- backbone 仍用当前参数 $\theta_t$ 做计算
- 路由与 backbone 解耦同步更新,outlier 来不及影响下一步路由
工程实现:
- 在 step $t - \Delta t$ 时就预先 forward 一次计算 step $t$ 要用的 routing index,缓存起来
- 这次额外 forward 与 EP 通信 overlap, wall-time overhead 约 20% (通过 overlap 已经把双倍 forward 的理论代价压下来)
- 通过自动 spike 检测 触发:检测到 loss spike 时短暂启用 anticipatory routing;运行一段时间后切回标准训练
SwiGLU Clamping
V4 直接限制 SwiGLU 的数值范围:
- Linear 分量 clamp 到 $[-10, 10]$
- Gate 分量上界 10
经验上这消除了 outlier 的主要来源 (V4 报告 §4.2.3 引用 OpenAI 2025 同期实践)。不影响最终性能。
Anticipatory Routing 与 SwiGLU Clamping 联合使用,让 V4 整个预训练没有发生需要 rollback 的 spike。
后训练流程怎么走
核心问题:Specialist Training + OPD 两阶段各做什么?Full-vocabulary KL 为什么关键?
Pipeline 总体
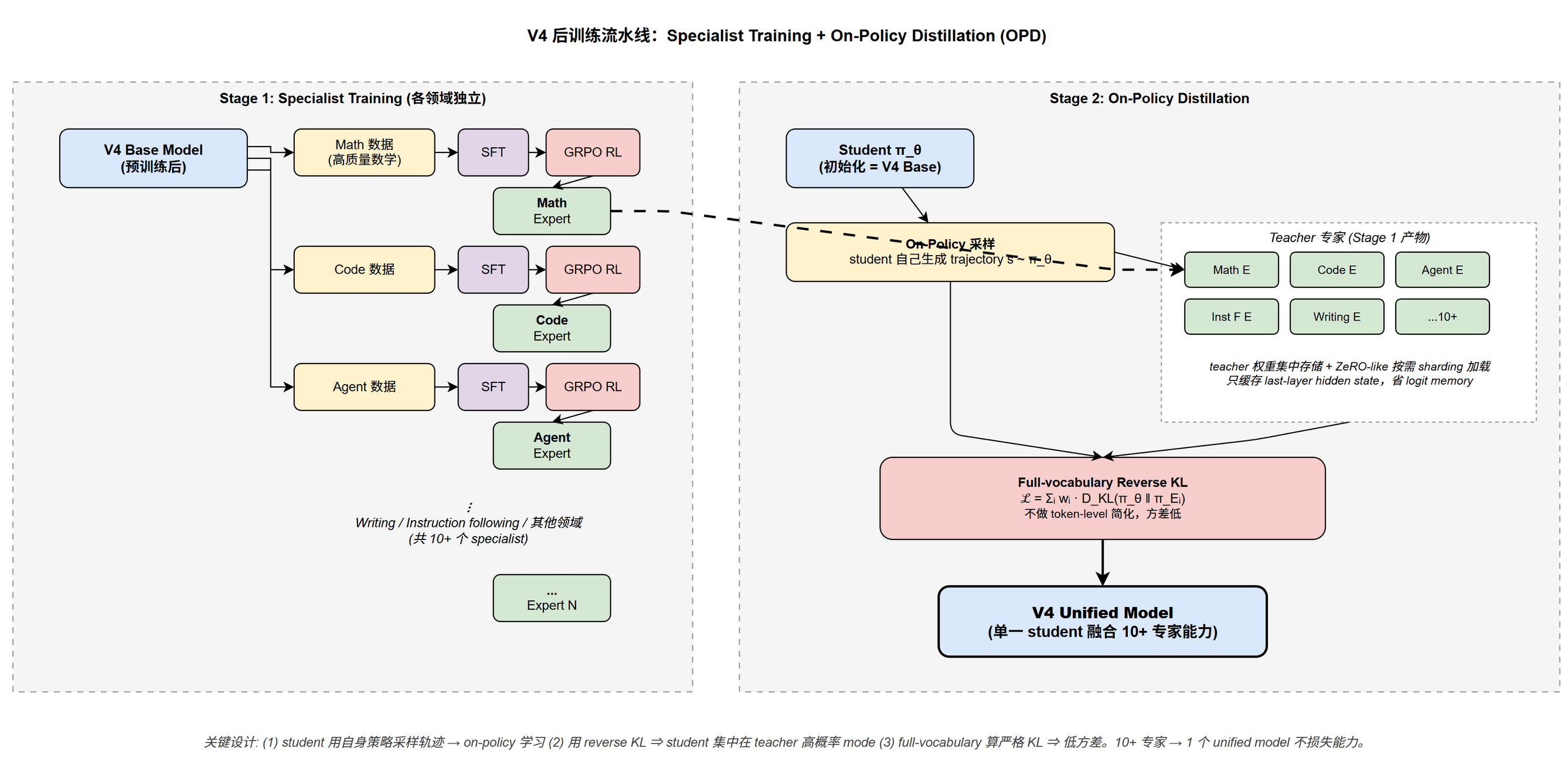
V4 后训练对 V3.2 做了关键方法学替换(论文 §5.1 verbatim):
"Although the training pipeline largely mirrored that of DeepSeek-V3.2, a critical methodological substitution was made: the mixed Reinforcement Learning (RL) stage was entirely replaced by On-Policy Distillation (OPD)."
V3.2 在多领域 RL 阶段用 mixed RL(同时拿多领域 reward 跑 RL),V4 完全用 OPD 替代:先分别 RL 训出领域专家,再用 OPD 合并。两者的根本差别:
| 维度 | V3.2 Mixed RL | V4 Specialist + OPD |
|---|---|---|
| 多领域优化 | 同一模型同时学多领域 reward | 各领域独立专家 → OPD 合并 |
| Reward 冲突 | 不同领域 reward 信号互相干扰 | 专家阶段无冲突,合并阶段统一目标 |
| 退化风险 | 弱领域可能被强领域压制 | 每个专家独立到 SOTA 才进合并 |
| 工程复杂度 | 单流程但调参难 | 流程长但每段目标明确 |
@tbl-dsv4-train-v3-vs-v4-rl V3.2 Mixed RL vs V4 Specialist + OPD 范式对比
Stage 1 — Specialist Training:
- 对每个目标领域 (数学 / 代码 / agent / instruction following / writing 等)独立训练一个专家模型
- 流程:SFT on 高质量领域数据 → GRPO RL 进一步优化(与 DeepSeek-V3 论文同 hyperparameter 集 — 论文 §5.1.1 verbatim "maintaining hyper-parameters closely aligned with our prior research")
- 每个专家在自己领域达到 SOTA,但只是该领域专家,不是通用模型
- 论文 §5.1.2: 一共 10+ 个 teacher 模型进入 OPD
Stage 2 — On-Policy Distillation (OPD):
- 把 10+ 个 specialist expert 合并为单一 unified 模型
- Student 自己生成轨迹 (on-policy),用 reverse KL 学多个 teacher 的输出分布
- 与传统 SFT distillation 的区别:用 student 自己生成的数据而非 teacher 生成的,避免 distribution mismatch
OPD 目标函数:
$$\begin{equation} \mathcal{L}_{\text{OPD}}(\theta) = \sum_{i=1}^{N} w_i \cdot D_{\text{KL}}\big(\pi_\theta(\cdot \mid s) \,\|\, \pi_{E_i}(\cdot \mid s)\big), \quad s \sim \pi_\theta \label{eq:dsv4-train-opd} \end{equation}$$$\pi_\theta$ 是 student 策略,$\pi_{E_i}$ 是第 $i$ 个 teacher 专家策略,$w_i$ 是每个专家的权重,状态 $s$ 由 student 自己采样 (on-policy)。
KL 方向约定:本公式中 student 放在 || 左侧、teacher 放在右侧 — 蒸馏文献通常称这种写法为 reverse KL (相对于传统师生蒸馏中 teacher 在左侧的 forward KL)。Reverse KL 的语义是"让 student 集中在 teacher 高概率的 mode 上",配合 on-policy 采样能避免学生在 teacher 分布的低概率区做无意义的探索。
Full-Vocabulary KL
传统 OPD 实现常常把 reverse KL 简化为 single-sample stochastic estimate (仅用 ground-truth token 的 log-ratio 来估计 KL):
$$\begin{equation} \widehat{D_{\text{KL}}}_{\text{token}} \approx \mathrm{sg}\left[ \log \frac{\pi_\theta(y_t | x, y_{<t})}{\pi_{E_i}(y_t | x, y_{<t})} \right] \label{eq:dsv4-train-kl-single-sample} \end{equation}$$$\mathrm{sg}[\cdot]$ 是 stop-gradient。这种估计方差很高,导致训练不稳定。
V4 用 full-vocabulary logit distillation:保留完整的 logit 分布,在词表上算严格 KL。
- 优点:低方差估计,训练稳定
- 代价:需要 teacher 完整 logits 在 forward 时可用
OPD 工程基建(论文 §5.2.2)
10+ teacher 模型 × 词表 100K+ × 万亿参数 — naive 物化所有 teacher logits 不可承受。V4 用 4 层工程优化让它可行:
| 优化点 | 做法 |
|---|---|
| Teacher 权重存储 | 集中式 distributed storage,ZeRO-like sharding,forward pass 时按需加载 |
| 不存 full logits | 只缓存 last-layer hidden state 到 centralized buffer,训练时按需调 prediction head 重算 logits — 显著节省存储 |
| Teacher 调度 | mini-batch 内 sample 按 teacher index 排序 → 同时刻 device memory 上只驻留 1 个 teacher prediction head |
| 异步 I/O | 所有参数 / hidden state 加载 / offload 在后台异步进行,不阻塞主 critical path |
| TileLang KL kernel | KL divergence 用专用 TileLang kernel 算,降低动态内存分配 |
@tbl-dsv4-train-opd-engineering OPD 工程基建 5 项优化
为什么"按 teacher 排序"是关键:mini-batch 不排序时多个 teacher head 同时入 device 内存 → 单卡放不下;排序后单 head load 一次跑完所有该 teacher 的 sample,每 mini-batch 内每 head 只 load 一次,峰值显存按"最大单 head" 计。
Reasoning Modes 三档
V4 在后训练支持三种推理模式 (论文 §5.1.1 Table 2):
| 模式 | 特征 | 典型场景 | 响应格式 |
|---|---|---|---|
| Non-think | 快速直觉响应 | 日常任务,紧急反应 | </think> 后直接 summary |
| Think High | 复杂逻辑分析 | 复杂问题,规划 | <think> thinking </think> summary |
| Think Max | 极限推理努力 | 探索模型推理边界 | 注入特殊 system prompt + thinking + summary |
@tbl-dsv4-train-reasoning-modes 三种推理模式
每个模式在 RL 训练时用不同的 length penalty 和 context window:
- Non-think: 8K context
- Think High: 128K context
- Think Max: 384K context
Think Max 的 system prompt 注入 (论文 §5.1.1 Table 3):
Reasoning Effort: Absolute maximum with no shortcuts permitted. You MUST be very thorough in your thinking and comprehensively decompose the problem to resolve the root cause, rigorously stress-testing your logic against all potential paths, edge cases, and adversarial scenarios. Explicitly write out your entire deliberation process, documenting every intermediate step, considered alternative, and rejected hypothesis to ensure absolutely no assumption is left unchecked.
Generative Reward Model
传统 RL 用专门的 reward model (scalar 输出) 评估 trajectory。V4 用 Generative Reward Model (GRM):
- Actor 网络本身充当 GRM — 同一个模型既负责生成 trajectory,又负责评判 trajectory
- 直接对 GRM 做 RL 优化 (让模型的"评判"能力也提升)
- 只需少量 rubric 数据 + 模型自身泛化即可达到高质量评估
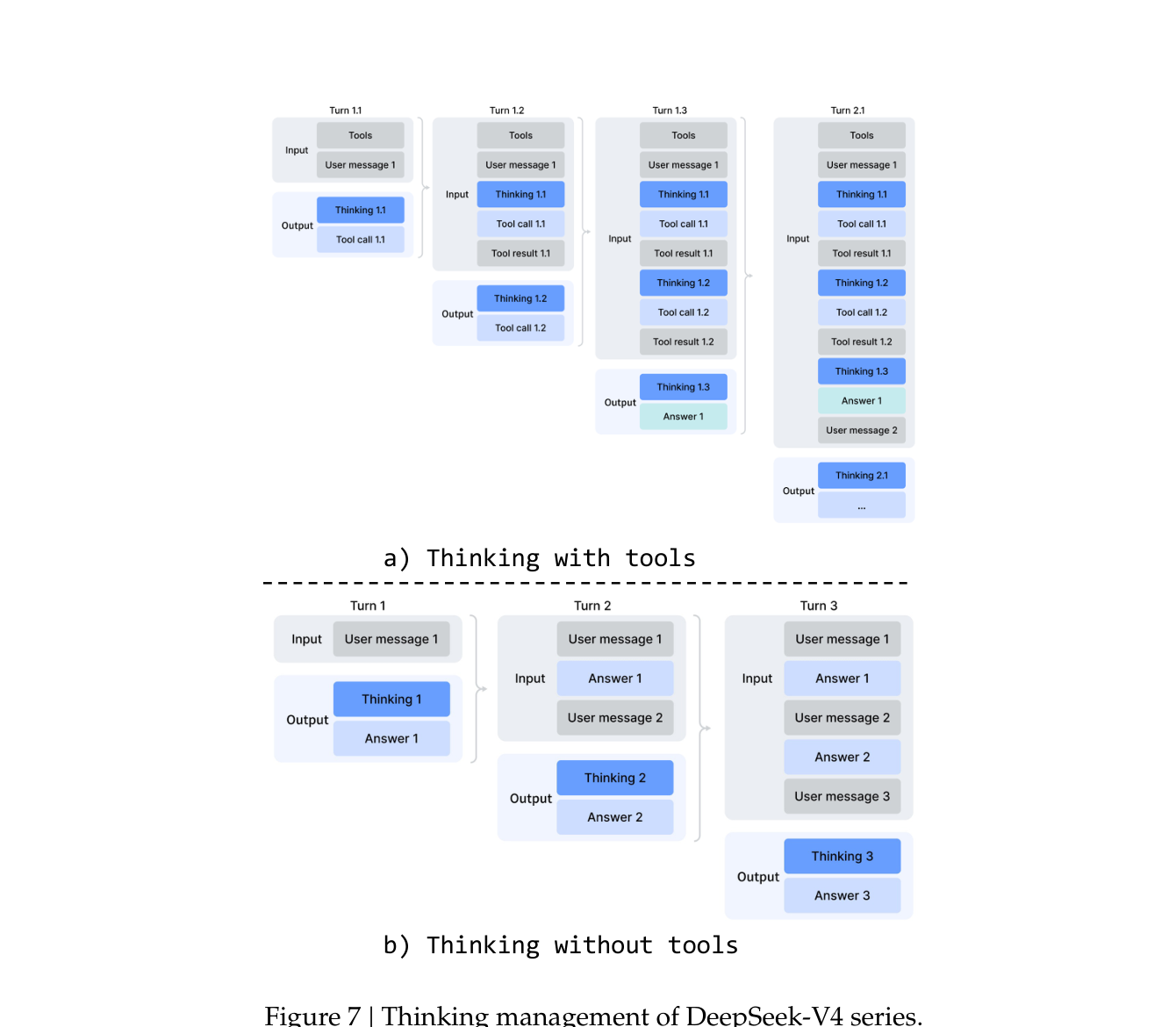
Interleaved Thinking 与 Quick Instruction
Interleaved Thinking 是 V4 利用 1M 上下文做的对话管理优化:
- 工具调用场景:所有 thinking 内容在整个对话中保留 (即使跨过 user message),让 agent 维持连贯的思考链
- 普通对话场景:thinking 在每个 user message 到来时丢弃 (节省 context)
Quick Instruction 用专用 token 复用 KV cache:
| 任务 token | 用途 |
|---|---|
<|action|> | 判断是否需要 web search |
<|title|> | 生成对话标题 |
<|query|> | 生成搜索 query |
<|authority|> | 判断信息权威性需求 |
<|domain|> | 识别用户 prompt 的领域 |
<|extracted_url|>, <|read_url|> | URL 抓取与阅读 |
@tbl-dsv4-train-quick-instruction Quick Instruction 任务 token
这些辅助任务原本需要独立小模型并预填重复 prompt,现在直接在主模型上附加 token 复用已计算的 KV cache,省 TTFT 与维护成本。
Tool Call Schema (DSML)
V4 引入自研的 DSML (DeepSeek Markup Language) 格式做 tool call,用 <|DSML|...> 系列 special token:
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$PARAMETER_NAME" string="true|false">$PARAMETER_VALUE
</|DSML|parameter>
...
</|DSML|invoke>
</|DSML|tool_calls>
相比 JSON-based tool call 的优势:
- XML 风格嵌套清晰,转义错误少
- Special token 让 tokenizer 更高效
- 实验证明 tool-call 错误率显著降低
基础设施怎么支撑
核心问题:FP4 QAT / 抢占式 rollout / DSec 沙箱各解决什么工程问题?
FP4 QAT
后训练阶段把 FP4 量化扩展到:
- MoE expert 权重 (与预训练阶段相同)
- CSA Lightning Indexer 的 QK 路径 — activation 也量化到 FP4
QAT 流程:
- FP32 master 权重 → FP4 量化 → FP8 反量化 → FP8 matmul
- Backward 直接对 FP8 权重计算梯度,等价于 Straight-Through Estimator (STE) 穿过量化
- 整个流水线复用 FP8 训练框架,无需修改
推理时直接用原生 FP4 权重,行为与训练完全一致 (因为训练时就用 FP4 量化的权重计算 forward)。
Preemptible / Fault-Tolerant Rollout
RL 阶段需要大量 rollout (让 actor 生成 trajectory)。V4 部署在抢占式 GPU 集群上,引入 token 级 WAL (Write-Ahead Log):
- 每生成一个 token 立即追加到 WAL
- 任务被抢占时暂停 inference engine、保存 KV cache
- 恢复时从 WAL 加载已生成 token + KV cache,从中断点继续 decode
- 即使发生硬件故障,也可以从 WAL 重新 prefill 重建 KV cache
为什么不能简单"重新从头生成"?论文 §5.2.3 verbatim:
"shorter responses are more likely to survive interruption, regenerating from scratch makes the model more prone to producing shorter sequences whenever an interruption occurs."
数学不正确而非工程不便利 — 重新生成等于对 trajectory 分布做了"短偏好" condition,让 RL 训练梯度向"生成短输出" 倾斜,破坏了 on-policy 性质。Token 级 WAL 完整保留进度,避免该偏置。
替代方案的对比(论文同节):
| 方案 | 数学正确? | 工程开销 |
|---|---|---|
| 重新从头生成 | ❌ 引入 length bias | 重跑 decoding,最贵 |
| PRNG seed 一致 + 重新生成 | ✅ 要求 batch-invariant + deterministic kernel | 仍需重跑 decoding |
| Token 级 WAL(V4 选择) | ✅ 直接续传 | 最便宜,仅磁盘 append |
@tbl-dsv4-train-rollout-recovery 抢占式 rollout 三方案对比
DSec Sandbox
Agent 训练需要执行用户代码、调用 API 等隔离环境。V4 自研 DSec (DeepSeek Elastic Compute) — Rust 实现的弹性沙箱,单集群百万级并发实例:
| Substrate | 用途 |
|---|---|
| Function Call | 轻量函数调用,预热 container pool |
| Container | Docker 兼容,EROFS on-demand loading |
| microVM | 基于 Firecracker, VM 级隔离 |
| fullVM | 基于 QEMU,任意 OS |
@tbl-dsv4-train-dsec-substrate DSec 四种执行 substrate
四种 substrate 共享统一的 Python SDK (libdsec),切换只需改参数。
Scaling RL for 1M Context
1M 上下文的 RL rollout 数据量极大,V4 用两个技巧:
- Metadata / Token 分离:rollout 数据拆成轻量元数据 (全局加载用于 shuffling / packing) + 重 token 字段 (共享内存 loader 消除节点内冗余)
- Dynamic mini-batch sizing:根据 workload 动态调整每设备 mini-batch 数,平衡计算与 I/O overlap
Evaluation 亮点
核心问题:V4 在哪些维度超过 V3.2 / 闭源 SOTA?
Base Model (pre-training 后,未做 post-training)
| 任务 | DeepSeek-V3.2-Base | V4-Flash-Base (13B) | V4-Pro-Base (49B) |
|---|---|---|---|
| MMLU (5-shot) | 87.8 | 88.7 | 90.1 |
| GSM8K (8-shot) | 91.1 | 90.8 | 92.6 |
| HumanEval | 62.8 | 69.5 | 76.8 |
| LongBench-V2 | 40.2 | 44.7 | 51.5 |
| Simple-QA verified | 28.3 | 30.1 | 55.2 |
@tbl-dsv4-train-base-eval Base model 评测节选
V4-Flash-Base (13B 激活) 超过 V3.2-Base (37B 激活) 大多数 benchmark — 参数减半但性能反升,验证架构改进的价值。V4-Pro-Base 进一步全面超越。
Post-Training V4-Pro-Max (最大推理努力)
- 代码:Codeforces Rating 3206 (超过 GPT-5.4 xHigh 3168,开源 SOTA)
- 数学:Putnam-2025 在 hybrid formal-informal pipeline 下 120/120 (与 Axiom 并列),formal-only Putnam-200 Pass@8 81%
- 长上下文:1M MRCR 8-needle 仍保持 0.59 MMR
- Agent: Tool-Decathlon 47.2, MCPAtlas 73.6 等接近闭源
- 知识:MMLU-Pro 87.5 / SimpleQA-Verified 57.9 (开源 SOTA)
整体:V4-Pro-Max 在代码、数学、长上下文处于开源 SOTA 甚至超过部分闭源 SOTA;知识密集任务相比 Gemini-3.1-Pro 等仍落后约 3–6 个月。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 预训练数据 | 32T+ tokens,长文档优先;mid-training 阶段注入 agentic 数据强化 coding |
| Sample-level masking | V4 严格 mask 同序列内不同样本(V3 不 mask),避免长序列拼接污染 |
| Muon | 主用于 GEMM; Hybrid Newton-Schulz 10 步两阶段;AdamW 用于 embedding / norm / bias |
| 优化器超参 | AdamW β1=0.9 β2=0.95 ε=1e-20 wd=0.1;Muon μ=0.95 wd=0.1 γ=0.18(与 AdamW LR 复用) |
| 注意力稀疏化 | 前 1T tokens dense; 64K 阶段 indexer warmup;之后正式 sparse |
| 稳定性 | Anticipatory Routing (20% wall-time)+ SwiGLU Clamping ([-10,10] linear, 10 gate cap) 让 1.6T 训练零 rollback |
| V3→V4 后训练方法学替换 | mixed RL 整段替换为 Specialist + OPD,分领域独立 RL 再合并 |
| 后训练 | Specialist (SFT + GRPO RL, hyperparams 同 V3) → 10+ teacher OPD (full-vocabulary reverse KL) |
| OPD 工程 | 只缓存 last-layer hidden state + sample 按 teacher 排序 + 异步 I/O + TileLang KL kernel |
| 三档推理 | Non-think 8K / Think High 128K / Think Max 384K |
| 基础设施 | FP4 QAT 复用 FP8 框架 / token-WAL 抢占式 rollout / DSec Rust 沙箱 |
| Rollout 数学正确性 | 重新从头生成引入 length bias,token-WAL 是唯一便宜的正确方案 |
| Evaluation | Base V4-Flash 13B 超 V3.2 37B; Pro-Max 代码 / 数学 / 长上下文开源 SOTA |