总览
本章节范围:DeepSeek V4 系列 (V4-Pro 1.6T / V4-Flash 284B) 的架构创新 — mHC 残差 / Hybrid Attention (CSA + HCA + SWA) / MoE 升级 / Muon 优化器 / FP4 QAT / 1M 上下文。 目标读者:做 LLM 推理 / 训练性能分析、通信拓扑设计、并行策略选型的工程师。
范围与边界
- 包含:V4 整体定位与配置全表;mHC (Birkhoff 流形约束的 4 路残差);CSA / HCA / SWA 三种 attention 机制;V4 MoE 路由变化与 wave-scheduled EP; Muon + Newton-Schulz 优化器;OPD 后训练;V4 对通信原语 / 拓扑的具体需求。
- 不包含:通用 Transformer / MoE 入门 (假设读者已熟悉);集合通信原语本身 (见 04-集合通信); LLM 并行策略的通用通信模式 (见 05-LLM并行通信)。
名词定义
后续各节默认沿用这些定义。V4 自身新引入的概念 (mHC / CSA / HCA / Lightning Indexer / Muon / OPD 等) 在对应小节首次出现时详细展开,此表不重复。
| 名词 | 定义 |
|---|---|
| MoE (Mixture of Experts) | 混合专家。FFN 层用多个独立"专家"网络替换单一前馈层,每 token 只激活其中 top-k 个,实现"大参数总量 + 小激活量" |
| 激活参数 vs 总参数 | 总参数 = 全部模型权重;激活参数 = 单 token 推理实际用到的参数。V4-Pro 总 1.6T,每 token 只激活 49B |
| MLA (Multi-head Latent Attention) | DeepSeek V2 / V3 提出的注意力机制,把 KV 压缩到低维 latent 存储,attention 时再上投影回 head dim。维度方向的 KV 压缩 |
| DSA (DeepSeek Sparse Attention) | DeepSeek V3.2 提出的稀疏注意力:每个 query 只对 top-k 个最相关的 KV 做 attention |
| MQA / GQA | Multi-Query / Grouped-Query Attention — MHA 的简化,共享 K/V 减小 KV cache |
| MTP (Multi-Token Prediction) | 除标准 next-token 外,并行预测 next-2 等更远 token,增强训练信号并支持 speculative decoding |
| KV cache | 自回归推理时缓存历史 token 的 Key / Value 张量,避免重复计算。长上下文场景的主要内存瓶颈 |
| SWA (Sliding Window Attention) | 每个 query 只关注最近 $n_{\text{win}}$ 个 token,限制 attention 复杂度 |
| RoPE (Rotary Position Embedding) | 旋转位置编码 — 通过对 Q / K 部分维度做旋转矩阵乘法注入相对位置信息 |
| token / 上下文 / 序列长度 | token = 模型最小处理单元;上下文 / 序列长度 = 单次推理输入 + 输出的最大 token 数 |
| FP4 / FP8 / BF16 | 浮点格式。FP4 (E2M1) = 1 符号 + 2 指数 + 1 尾数;FP8 (E4M3) = 1 + 4 + 3; BF16 = 16-bit Brain Float |
| GRPO (Group Relative Policy Optimization) | DeepSeek 提出的 RL 算法,PPO 变种,去掉 value model 用组内相对奖励估计 advantage |
| EP / TP / PP / DP | Expert / Tensor / Pipeline / Data Parallelism — 四种主流并行策略 |
| Pre-LN Transformer | 标准 Transformer 变体,把 LayerNorm 放在残差分支内部子层之前 (x + f(LN(x))),比 Post-LN 训练更稳 |
@tbl-dsv4-overview-glossary 第 8 章共享名词表
V4 在 DeepSeek 代际中的位置
DeepSeek 从 V3 到 V4 的核心方向是逐代加强长上下文效率,每代都在前代瓶颈上做一项关键架构替换:
| 版本 | 发布时间 | 总参数 / 激活 | 上下文 | 关键架构 |
|---|---|---|---|---|
| DeepSeek V3 | 2024-12 | 671B / 37B | 128K | MLA + DeepSeekMoE + MTP |
| DeepSeek V3.2 | 2025-09 | 685B / 37B | 160K | MLA + DSA (DeepSeek Sparse Attention) |
| DeepSeek V4-Flash | 2026-04 | 284B / 13B | 1M | 前 2 层纯 SWA + 后续 CSA / HCA 交错 + mHC + Muon |
| DeepSeek V4-Pro | 2026-04 | 1.6T / 49B | 1M | 前 2 层 HCA + 后续 CSA / HCA 交错 + mHC + Muon |
@tbl-dsv4-overview-lineage DeepSeek 模型代际演进
关键转折:
- V3 → V3.2:注意力从纯 dense MLA 引入稀疏选择 (DSA), KV cache 不再随序列线性涨,开始考虑超长上下文
- V3.2 → V4:注意力从"latent 压缩" (MLA) 转向序列维显式压缩 (CSA / HCA),同时引入 sparse 选择;残差路径从单流 Pre-LN 升级到 4 路 mHC;优化器从 AdamW 改为 Muon
- V4 系列核心目标是 "1M token 上下文 + 推理效率",不是单纯继续堆参数 (V4-Flash 比 V3 还小一半)
Pro / Flash 配置对比
两个变体共享同一套架构创新 (mHC / CSA / HCA / Muon / MoE),仅在规模上拉开档次。
| 维度 | V4-Flash | V4-Pro |
|---|---|---|
| 总参数 | 284B | 1.6T |
| 激活参数 | 13B | 49B |
| 训练 tokens | 32T | 33T |
| Transformer 层数 $L$ | 43 | 61 |
| Hidden dim $d$ | 4096 | 7168 |
| 词表 | 128K | 128K |
| 上下文 | 1M | 1M |
| 前 2 层注意力类型 | 纯 SWA | HCA |
| 后续层 | CSA / HCA 交错 | CSA / HCA 交错 |
| CSA 压缩率 $m$ | 4 | 4 |
| CSA top-k | 512 | 1024 |
| CSA Lightning Indexer head 数 $n_h^I$ | 64 | 64 |
| CSA Indexer head dim $c^I$ | 128 | 128 |
| HCA 压缩率 $m'$ | 128 | 128 |
| Attention query head 数 $n_h$ | 64 | 128 |
| Attention head dim $c$ | 512 | 512 |
| Query 压缩维 $d_c$ | 1024 | 1536 |
| 输出投影分组数 $g$ | 8 | 16 |
| 每组输出中间维 $d_g$ | 1024 | 1024 |
| Sliding window 大小 $n_{\text{win}}$ | 128 | 128 |
| MoE 路由专家数 | 256 | 384 |
| MoE 共享专家数 | 1 | 1 |
| Expert 中间维 (SwiGLU) | 2048 | 3072 |
| 每 token 激活路由专家数 (top-k) | 6 | 6 |
| 前 N 个 MoE 层用 Hash routing | 3 | 3 |
| MTP 模块深度 | 1 | 1 |
| mHC 扩展因子 $n_{hc}$ | 4 | 4 |
| Sinkhorn-Knopp 迭代次数 $t_{\max}$ | 20 | 20 |
@tbl-dsv4-overview-config V4-Pro 与 V4-Flash 完整配置对比
关键观察:
- 深度差异主导规模:Pro 多了 18 层 (43 → 61) 和更大 hidden (4096 → 7168),但 CSA / HCA / mHC 等结构参数完全一致
- Expert 数量翻倍 + 增大单 expert:256 → 384 routed experts,单 expert 中间维 2048 → 3072
- Attention head 数翻倍:64 → 128 query heads,但 head dim 同为 512
- top-k 翻倍:CSA 选取的 compressed entry 数 512 → 1024, Pro 在长上下文下能看到更多远距离信息
V4 Transformer Block 是什么形态
V4 系列沿用 Transformer 主干 + DeepSeekMoE FFN + MTP 模块的整体形态,但在 block 内部把单残差路径换成 4 路 mHC 残差流。
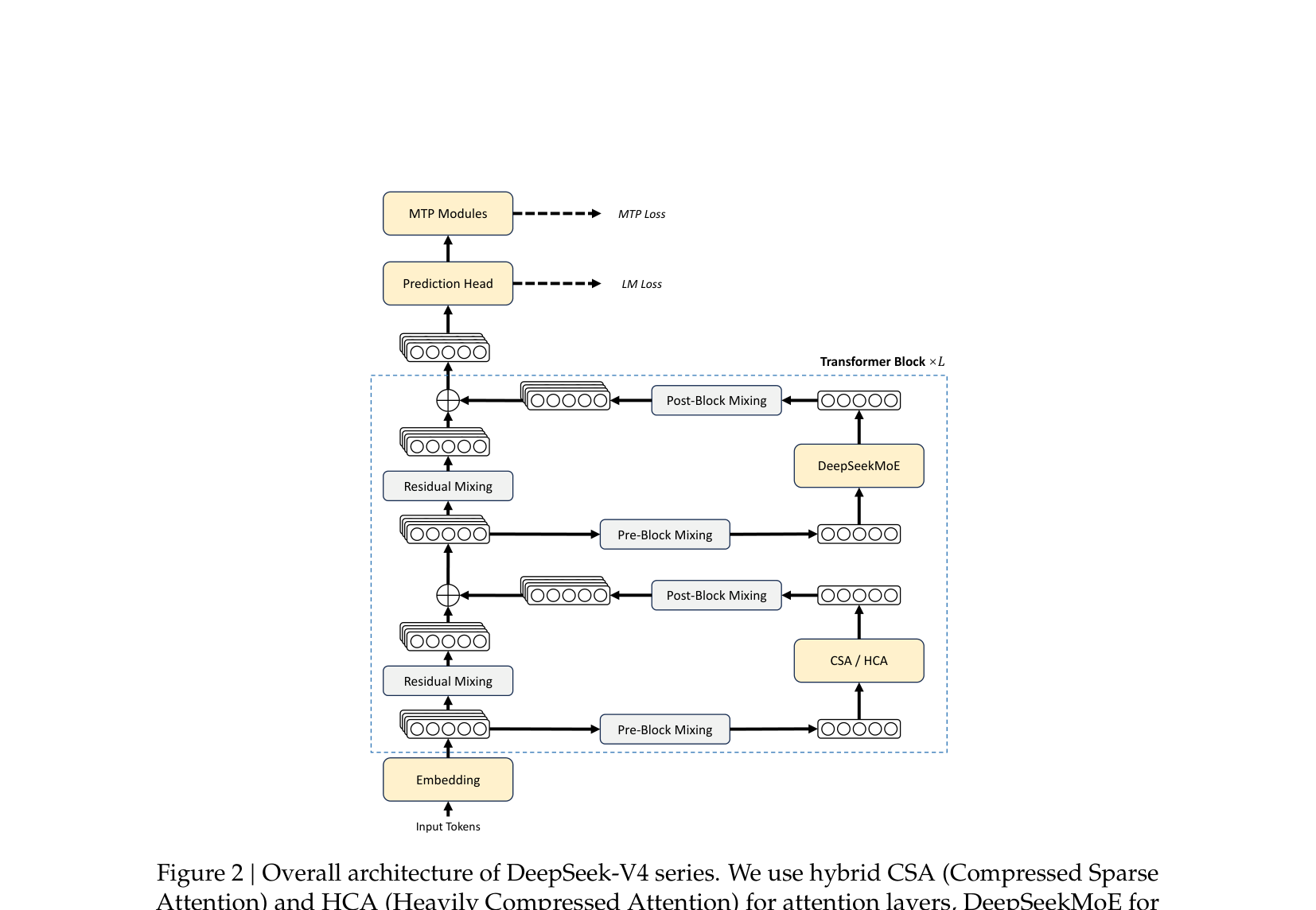
一个 V4 Transformer Block 的数据流 (每个 token 经过的逻辑顺序):
- Pre-Block Mixing (mHC 的 $A_l$):从 4 路残差流 $X_l \in \mathbb{R}^{4 \times d}$ 加权混合出 1 路 $A_l X_l \in \mathbb{R}^d$,送入子层
- Attention 子层:CSA 或 HCA 执行对 $A_l X_l$ 的注意力运算 (V4-Flash 前 2 层 SWA-only, V4-Pro 前 2 层 HCA-only),输出 $\mathcal{F}^{\text{Attn}}(A_l X_l) \in \mathbb{R}^d$
- Post-Block Mixing ($C_l$):把单路输出广播回 4 路 $C_l \mathcal{F}^{\text{Attn}} \in \mathbb{R}^{4 \times d}$
- Residual Mixing ($B_l$):把当前 4 路残差与广播回来的 4 路输出相加 $X_l' = B_l X_l + C_l \mathcal{F}^{\text{Attn}}$, $B_l$ 是双随机矩阵
- Pre-Block Mixing (FFN 的 $A_l$):再次从 4 路混合出 1 路送入 MoE
- DeepSeekMoE 子层:1 shared expert + top-6 of 256 / 384 routed experts
- Post-Block Mixing + Residual Mixing:与 attention 子层结构对称
- block 输出 $X_{l+1} \in \mathbb{R}^{4 \times d}$ 进入下一层
最终 block 之上:Prediction Head (标准 LM loss) + MTP Module (额外预测 next-1 token, depth=1)。
关键观察:mHC 不仅替代单点残差,而是把整个网络的"主信号通路"从单流变成 4 流。attention / FFN 仍是单流 (保持参数效率),只在残差混合处吃 4× 带宽。
V4 效率提升来自哪里
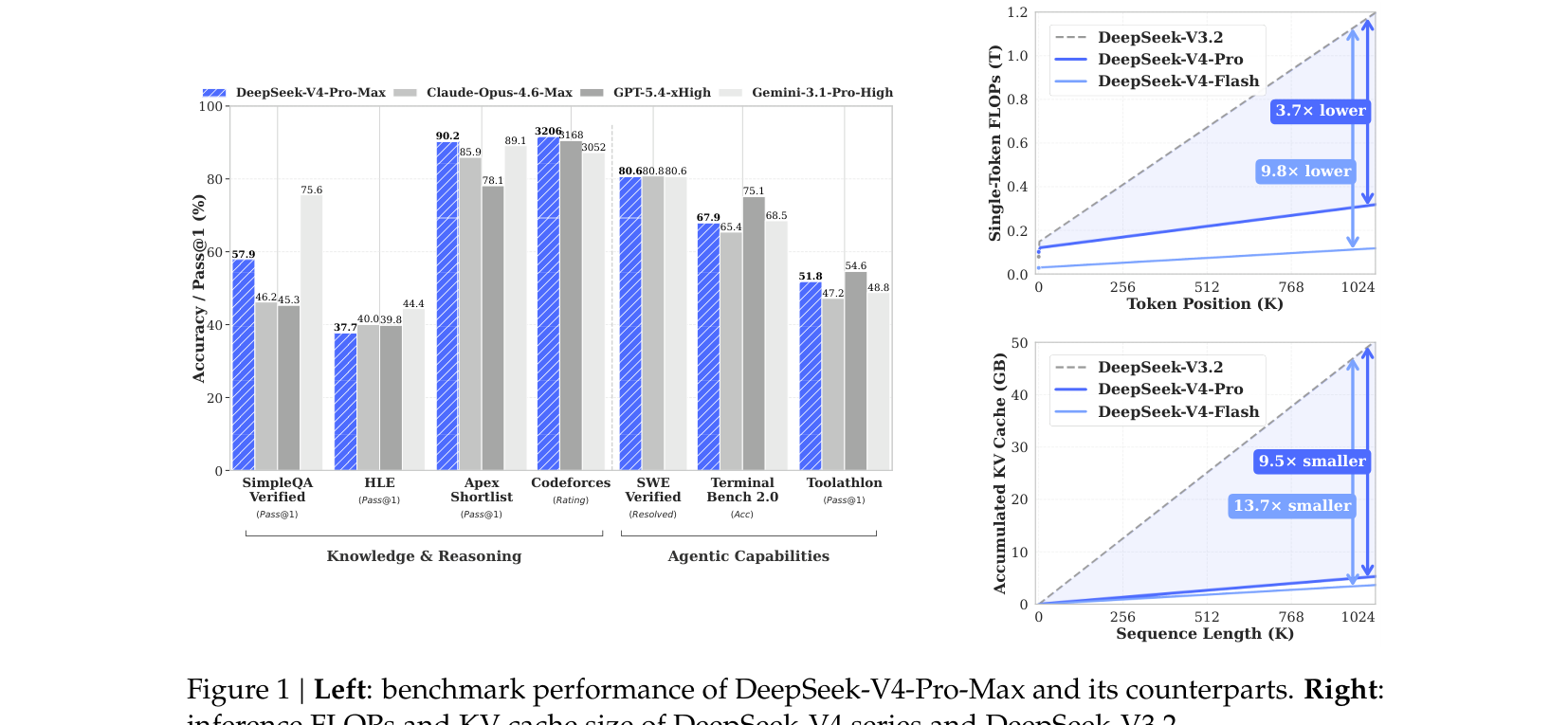
V4 系列在长上下文场景下的效率提升来自三个叠加:
- CSA / HCA 压缩:CSA 把 KV 压成 1/4, HCA 压成 1/128
- CSA 稀疏选择:top-k 只让 query 看 512 或 1024 个 compressed entry
- 混合精度:KV cache 中 RoPE 维 BF16 / 其余 FP8; indexer QK 路径 FP4; MoE expert 权重 FP4
1M token 上下文下的效率对比:
| 指标 | V3.2 (baseline) | V4-Flash | V4-Pro |
|---|---|---|---|
| 单 token 推理 FLOPs (FP8 等效) | 1.0× | 0.10× | 0.27× |
| 累计 KV cache 大小 | 1.0× | 0.07× | 0.10× |
| 1M 上下文 KV cache vs BF16 GQA8 (head_dim=128) baseline | — | — | 约 2% |
@tbl-dsv4-overview-efficiency 1M 上下文下的效率指标对比
关键观察:V4-Pro 激活参数比 V3.2 大 (49B vs 37B),即使如此 FLOPs 仍只有 V3.2 的 27% — 结构优化的收益远超规模上涨成本。V4-Flash 因激活参数更小 (13B),效率进一步降到 10% FLOPs / 7% KV cache。
V4 在同代模型中的位置
DeepSeek 内部对照评测 (论文 §1, §5.3) 的几个结论。表中 V4-Pro-Max 指 V4-Pro 在 Think Max 模式 (最大推理努力) 下的评测结果。
| 任务 | V4-Pro-Max | 同代闭源 SOTA | 备注 |
|---|---|---|---|
| SimpleQA-Verified | 57.9 | Gemini-3.1-Pro 75.6 | 开源 SOTA,但落后顶尖闭源 |
| Codeforces Rating | 3206 | GPT-5.4 xHigh 3168 | 超过闭源 SOTA |
| HMMT 2026 Feb | 95.2 | GPT-5.4 97.7 | 接近闭源 SOTA |
| Putnam-2025 (hybrid formal-informal) | 120/120 | Axiom 120/120 | 并列最佳 |
| BrowseComp | 83.4 | Gemini-3.1-Pro 85.9 | 开源 SOTA |
| GDPval-AA | 1554 | GPT-5.4 1674 | 落后 |
| MRCR 1M | 83.5 | Opus 4.6 92.9 | 1M 上下文检索强但落后 Opus |
@tbl-dsv4-overview-positioning V4-Pro-Max 与同代闭源模型对照
整体判断 (DeepSeek 自评):
- 代码 / 数学 / 长上下文:开源 SOTA,部分指标超过闭源 SOTA
- 知识密集型任务:开源 SOTA,落后顶尖闭源 3–6 个月
- Agentic:与 K2.6 / GLM-5.1 持平,落后闭源
- V4-Flash-Max (用最大推理努力) 能在多个 benchmark 上接近 V4-Pro-Max,性价比突出
子文档索引
- 2.2 mHC — mHC 残差:Birkhoff 流形约束的 4 路残差 + Sinkhorn-Knopp 投影 + 动态参数化。
- 2.3 Hybrid Attention — Hybrid Attention: CSA (4× 压缩 + top-k 稀疏) / HCA (128× 压缩 dense) / SWA (局部窗口) 三种机制混合堆叠。
- 2.4 MoE 架构与路由策略 — V4 MoE: $\sqrt{\text{Softplus}}$ 路由;取消路由节点约束;前 3 层 Hash routing; Wave-scheduled EP; FP4 QAT。
- 2.5 训练流程 — 预训练 (Muon + Newton-Schulz + 4K→1M 课程) / 稳定性 (Anticipatory Routing + SwiGLU Clamping) / 后训练 (Specialist + OPD)。
- 2.6 V4 对通信的新需求 — V4 对通信原语 / 硬件 / 拓扑的具体需求;Pull-based dispatch; Two-stage CP; 6144 FLOPs/Byte 平衡点。