注意力架构
78 层 MLA 低秩注意力 + DSA 动态稀疏选择 + 1/4 层跨层复用索引——稀疏路线堆出 1M 无损上下文
核心要点:
- MLA 将 KV 压到 512 维 latent,per-token KV cache(BF16)实际 1152 bytes(含 64 维 RoPE key)
- 78 层全部使用 DSA 稀疏注意力,无全注意力层、无 SWA 层
- IndexShare 在 DSA 之上叠加 F/S 层索引复用,1M 下 indexer 计算降至 1/4
- Decode 阶段走 MLA Absorb:在 512 维 latent 空间做 attention,绕过对历史 token 上投影
- 业界俗称 "KV8" 实为 FP8 E4M3,per-token 实际 656 bytes;SGLang 默认 per-tensor scale
- 1M 上下文由四件套联合支撑:IndexShare(架构)+ KV FP8(量化)+ LayerSplit(推理引擎)+ HiSparse(推理引擎)
前置阅读
- GLM-5.2 完整配置 → 3.1 总览
- IndexShare 的 F/S 机制与算子分解 → 3.2 IndexShare
- DSA 的 lightning indexer + top-K 通用机制 → 08-动态稀疏选择
- DSV4 的 CSA/HCA 序列压缩路线 → ../02-DeepSeek-V4/03-attention
GLM-5.2 的注意力系统由哪些组件构成?
GLM-5.2 的一次 attention 运算经过三个组件的叠加[1],底层到顶层依次为:
| 层序 | 组件 | 解决的问题 | 作用范围 |
|---|---|---|---|
| L1 底座 | MLA(Multi-head Latent Attention) | KV cache 显存墙——per-token KV 太大 | 每层、每 token |
| L2 选择 | DSA(Dynamic Sparse Attention) | $O(L^2)$ 计算墙——长序列下注意力 FLOPs 爆炸 | 每层、每 token |
| L3 复用 | IndexShare(跨层索引复用) | DSA indexer 自身的 $O(L^2)$ 成了新瓶颈 | 层间共享 |
@tbl-glm52-three-components GLM-5.2 注意力系统三层组件
三个组件全部 78 层同时跑 MLA + DSA,再叠加 IndexShare 的 F/S 层分配,无全注意力层、无 SWA 层。GLM-5.2 的 MLA 直接沿用 DSV3 的设计( 右下半),区别在于 head dim、低秩维度等数值。
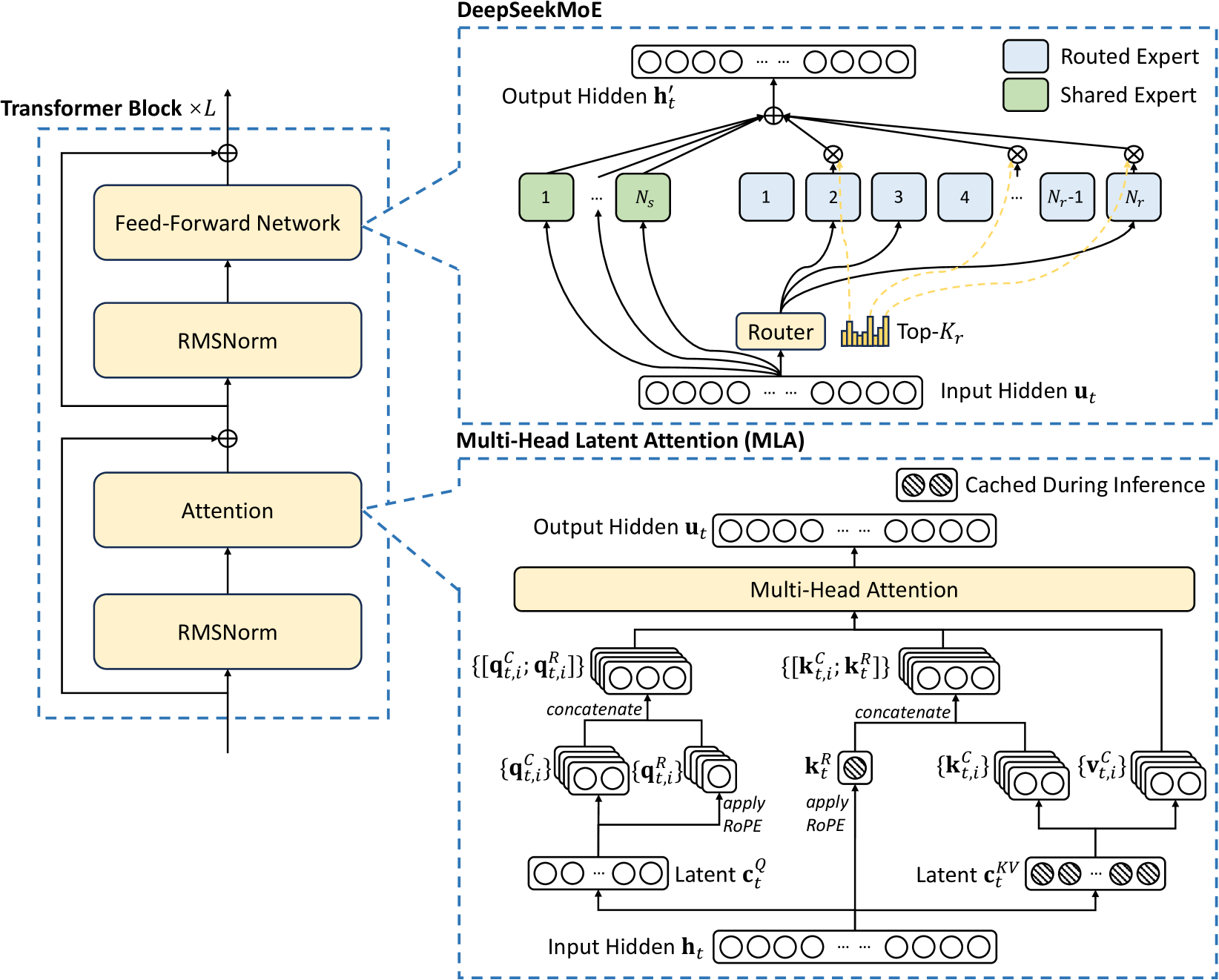
MLA 算子链路:从 hidden state 到 attention 输出
GLM-5.2 的 MLA 有 5 个权重矩阵串成的 GEMM 链[2][3]。下表给出 naive prefill 路径(不带 absorb)的完整投影链。注意:GLM-5.2 HF config 中 v_head_dim=256(与 DSV3 的 128 不同),所以 K nope 192 + V 256 = 每 head 448 维。
| # | GEMM | 输入 → 输出 | 权重维度 | 备注 |
|---|---|---|---|---|
| 1 | $W^{Q,A}$ | $6144 \to 2048$ | $6144 \times 2048$ | hidden → Q latent ($q_{\text{lora\_rank}}$) |
| 2 | $W^{Q,B}$ | $2048 \to 64 \times 256$ | $2048 \times 16384$ | Q latent → 64 head × (NoPE 192 + RoPE 64) |
| 3 | $W^{KV,A}$ | $6144 \to 576$ | $6144 \times 576$ | hidden → (512 latent + 64 RoPE key);KV 共享 latent |
| 4 | $W^{KV,B}$ | $512 \to 64 \times 448$ | $512 \times 28672$ | KV latent → 64 head × (K_nope 192 + V 256);prefill 时展开 |
| 5 | $W^O$ | $64 \times 256 \to 6144$ | $16384 \times 6144$ | attention output → hidden |
@tbl-mla-gemm-chain MLA 五个 GEMM 的完整投影链(GLM-5.2 实际配置)
NoPE 192 + RoPE 64 为什么要拆?
QK head dim 256 拆成 NoPE 192 + RoPE 64 的根本原因是 RoPE 不与 MLA absorb 兼容:
- NoPE 192:不携带位置信息,可以参与 absorb——后面会看到 $W^{UK}_{\text{nope}}$ 可以吸到 $W^Q_{\text{nope}}$ 里
- RoPE 64:旋转角与 token 位置绑定,每个 token 的旋转因子不同,无法 absorb,必须独立保留
拆分意味着 attention score 由两部分相加:$\text{score} = q_{\text{nope}} \cdot k_{\text{nope}}^\top + q_{\text{rope}} \cdot k_{\text{rope}}^\top$。FlashMLA 在单个 kernel 内 concat $[c^{KV}|k_{\text{rope}}] = $ head_dim 576 一起做点积,不走双 kernel[4]。
KV cache 字节口径(per-token per-layer)
KV cache 只存 共享的 KV latent + RoPE key,不存上投影后的 K/V[4]:
$$\begin{equation} \text{KVcache}_{\text{per-token, per-layer}} = \underbrace{d_{\text{latent}} \cdot \text{bytes}}_{c^{KV}} + \underbrace{d_{\text{rope}} \cdot \text{bytes}}_{k_{\text{rope}}} \label{eq:mla-kv-bytes} \end{equation}$$代入 $d_{\text{latent}}=512$, $d_{\text{rope}}=64$:
| 精度 | $c^{KV}$ 字节 | RoPE key 字节 | scale 字节 | 合计 |
|---|---|---|---|---|
| BF16 | $512 \times 2 = 1024$ | $64 \times 2 = 128$ | — | 1152 bytes |
| FP8 E4M3 + BF16 RoPE,per-tensor scale(SGLang 默认) | $512 \times 1 = 512$ | $128$ | 共享,per-token 摊销 ≈ 0 | ~640 bytes |
| FP8 E4M3 + BF16 RoPE,per-group scale(group=128,alt 路径) | $512$ | $128$ | $4 \text{ groups} \times 4 \text{ B} = 16$ | 656 bytes |
| FP8 E4M3 + BF16 RoPE,per-head scale(vLLM 2026-04+) | $512$ | $128$ | 每 head 4 B 摊销小 | ~640-648 bytes |
@tbl-mla-kv-bytes MLA per-token per-layer KV cache 实际字节(按量化粒度区分)
与标准 MHA 比较 (n_h=64, d_head=128, BF16):$2 \times 64 \times 128 \times 2 = 32768$ bytes/token/layer。MLA BF16 压缩 28.4×、FP8 压缩 ~51×(按 640 bytes 计)。常见的 "MLA 压缩 64×" 是 K/V latent 不含 RoPE key 的口径,把 RoPE key 一起算只有 28×。
本文档后续算例统一使用 FP8 per-tensor scale 的 640 bytes/token/layer 口径(SGLang 生产默认)。
MLA Absorb:decode 阶段走 latent 空间 attention
Prefill 阶段每个 query token 都要看全部历史 token,FLOPs 主导是 $L^2$ 量级的 score GEMM,按上投影后的 head dim 算更便宜。Decode 阶段不同——单个 query token 要看 $L$ 个历史 KV,access 主导是 KV cache 读字节。MLA Absorb 利用矩阵乘法结合律把上投影"吸"到查询侧,让 decode 直接在 512 维 latent 空间做 attention[5]。
Absorb 数学
定义两个吸收矩阵,显式区分 per-head 与 global 视角:
Q-side 吸收(per head $h$):把第 $h$ 个 Q head 的 NoPE 上投影矩阵 $W^{Q,B}_{h,\text{nope}} \in \mathbb{R}^{2048 \times 192}$ 与对应 K head 的上投影矩阵 $W^{KV,B}_{h,K} \in \mathbb{R}^{512 \times 192}$ 预乘:
$$\begin{equation} W^{KQ}_h = W^{Q,B}_{h,\text{nope}} \cdot (W^{KV,B}_{h,K})^\top \in \mathbb{R}^{2048 \times 512}, \quad h=1,\ldots,64 \label{eq:mla-absorb-q} \end{equation}$$每个 head 一个 $W^{KQ}_h$,64 头共 64 个矩阵。
Output-side 吸收(global):V 上投影与 $W^O$ 预乘——因 $W^O$ 跨 head 做 reduction,写成 global 形式更清晰。把 $W^{KV,B}_V \in \mathbb{R}^{512 \times 16384}$(含 64 head × 256 V dim)与 $W^O \in \mathbb{R}^{16384 \times 6144}$ 相乘:
$$\begin{equation} W^{OV} = W^{KV,B}_V \cdot W^O \in \mathbb{R}^{512 \times 6144} \label{eq:mla-absorb-o} \end{equation}$$Decode score(NoPE 部分,per head):
$$\begin{equation} \text{score}^{(h)}_{\text{nope}} = c^Q \cdot W^{KQ}_h \cdot (c^{KV})^\top \label{eq:mla-absorb-score} \end{equation}$$——完全在 latent 空间做,绕过对 $L$ 个历史 token 的 K 上投影。RoPE 部分仍需单独保留 $k_{\text{rope}}$,但 64 维远小于 256 维 head_dim 的代价。
为什么 prefill 不 absorb?
Absorb 把 $W^{Q,B} \times (W^{KV,B}_K)^\top$ 预乘,让 decode 的 $c^Q \cdot W^{KQ}$ 操作维度变大(2048 vs 256 per head)。Prefill 时 $L$ 个 query token 都要做这步,operand $L \times 2048$ 比 $L \times 256$ 大 8 倍——计算变贵,不划算[5]。Absorb 的红利只在 $S_q \ll S_{kv}$(即 decode)时显现。
SGLang / FlashMLA 的 kernel 路由
SGLang DSA backend 按精度 / 阶段选 kernel(来源:SGLang 源码 python/sglang/srt/layers/attention/dsa/ 阅读,非官方文档[6]):
| Hopper | KV BF16 prefill | KV BF16 decode | KV FP8 prefill | KV FP8 decode |
|---|---|---|---|---|
| kernel | flashmla_sparse | fa3 | flashmla_sparse | flashmla_kv |
Blackwell(B200)走 trtllm 路径,规避当前 B200 FP8 精度 bug。
DSA 为什么覆盖全部 78 层?
GLM-5 的消融实验给出了答案[7]。团队在 GLM-9B 上测试了多种高效注意力方案:
| 方法 | RULER (128K) | 结论 |
|---|---|---|
| Full Attention | 75.28 | 精度天花板 |
| DSA | ~75 | 与 Full Attention 持平 |
| SWA(简单交错) | 44.93 | 大幅退化 |
| SWA(模式搜索优化) | 69.59 | 仍有损失 |
@tbl-glm52-ablation-attention GLM-9B 高效注意力方案消融(128K RULER)
DSA 是唯一在改造过程中不损失精度的方案。SWA 即使经过模式搜索优化,仍丢失了远距离精确检索能力——这对 1M 上下文是致命缺陷。
因此 GLM-5.2 选择全量 DSA:78 层全部使用 DSA 的 lightning indexer + top-K 稀疏选择,不留任何全注意力层或 SWA 层作为"安全网"。这与 DSV4 的 Hybrid Attention(CSA/HCA/SWA 三种注意力类型按层混合堆叠)是截然不同的哲学——DSV4 把注意力多样性当作特性,GLM-5.2 追求统一机制下的极致效率。
三层如何协同:一次 attention 的完整数据流
下面分别给出 F 层(prefill)/ S 层(prefill)/ S 层(decode + absorb)三条路径的算子流。
F 层 prefill(含 indexer)
- hidden $\in \mathbb{R}^{B \times L \times 6144}$
- $c^Q = $ hidden · $W^{Q,A}$ → RMSNorm → $W^{Q,B}$ → 64 head × 256(NoPE+RoPE)
- $c^{KV}, k_{\text{rope}} = $ hidden · $W^{KV,A}$ split → KV cache 写入 latent + RoPE key
- Indexer(32 head × 128,FP8 + Hadamard):query · 全 L 个 key → ReLU 累加 → top-K=2048 → 写 F 层 cache(详见 02-indexshare § 算子表)
- MLA core attention in top-2048:上投影 K/V → softmax(QK^T / √d) · V → 输出
- $W^O$ → hidden
S 层 prefill(跳过 indexer)
跟 F 层完全一致,但跳过步骤 4,直接读最近 F 层缓存的 2048 个 token 位置。
S 层 decode(absorb 路径)
- hidden $\in \mathbb{R}^{B \times 1 \times 6144}$
- $c^Q = \text{hidden} \cdot W^{Q,A} \to W^{Q,B}$ → 拆 NoPE/RoPE
- 读 KV cache 中 latent + RoPE key(仅 1152 bytes/token/layer 而非 32 KB)
- 读 F 层 cache 取本 step 的 top-K=2048 索引(同 step 内 F 层已重算)
- Score:$c^Q \cdot W^{KQ} \cdot (c^{KV})^\top + q_{\text{rope}} \cdot k_{\text{rope}}^\top$(NoPE 路径全 latent)
- Output:$\text{softmax(score)} \cdot c^{KV} \cdot W^{OV}$ → hidden(无需上投影 V)
关键含义:S 层 decode 几乎只剩 $O(K \cdot d_{\text{latent}})$ 的 latent 空间 GEMM——$L^2$ 的 indexer、$L \cdot d$ 的 KV 投影、$L \cdot d_{\text{head}}$ 的 V 上投影都被消化。这是 MLA + DSA + IndexShare + Absorb 四重叠加在 decode 阶段的最终形态。
KV cache 量化:FP8 E4M3 的具体口径
术语订正:业界与文档里常出现的 "KV8" 在 GLM-5.2 / SGLang 路径上实际是 FP8 E4M3,不是 INT8。SGLang 当前主线只支持 FP8 和 FP4,无 INT8 KV cache 路径[8]。本文继续称 "KV FP8" 以避免歧义。
量化粒度
| 引擎 | 默认粒度 | 备注 |
|---|---|---|
| SGLang | per-tensor(单标量 scale) | 简单、无需校准;FlashMLA backend 在 Kimi 实测发现一致性下降,建议校准[8] |
| vLLM (2026-04+) | per-head(k/v_scale = [num_kv_heads]) | 需要 FA3 后端 + 校准数据[9] |
| KIVI(学术参考) | K per-channel / V per-token,非对称 | INT8 路径,不在生产引擎默认 |
每 token 的 FP8 KV 实际字节随粒度变化:per-tensor scale 摊销近 0 → ~640 bytes(SGLang 默认);per-group scale (group=128) → 656 bytes;per-head scale (vLLM) → ~640-648 bytes(详见上节 )。512 + 128 的拆解来自 FlashMLA KV layout 描述[4]。
量化时机
Prefill 和 decode 均在写入 KV cache 时实时量化,无 lazy 机制。chunked prefill 内 per-chunk 计算 scale。这意味着 KV cache 始终以 FP8 形态存在,读 cache 的 attention kernel 必须自己做 dequant[8]。
Dequant 必须 fused
如果先把 FP8 反量化到 BF16 再做 GEMM("unfused"路径),dequant 开销会显著抹掉量化的访存节省。生产路径都用 fused dequant——在 attention kernel 内做 FP8 → FP32 accumulation,dequant 与 GEMM 在同一 kernel 里完成。SGLang 文档明确警告 unfused 路径极慢[8]。
与 MLA latent 的叠加顺序
量化作用在已经被 MLA 压缩的 512 维 latent 上,不是上投影后的 head dim。这一点很关键——如果在上投影后再量化,per-token 字节就变成 64 head × (192 + 128) × 1 = 20 KB(含 scale),反而比 BF16 MLA 大。正确顺序:MLA 先压(64 head 共享 512 latent),FP8 再压(512 × 1 byte)。
配置入口
GLM-5.2 HF config 里没有 kv_cache_dtype 字段——KV FP8 是推理引擎运行时选项,不是训练嵌入。vLLM 部署 GLM-5.2 标配 --kv-cache-dtype fp8_e4m3[10];不开 FP8 KV 则 1M context 显存不足。
LayerSplit:按层段分片 KV,mmap 共享
LayerSplit 是 Z.ai 为 GLM 系列设计的 KV cache 分片机制,按 transformer 层段切分(PP 风格),每张 GPU 只持有部分层的 KV[1]。它不是 PP/TP 的别名,而是专门解决"1M context 下 KV 在单卡放不下"的独立层。
切分维度与跨卡读取
- 切分维度:按 transformer layer 段切到不同 PP stage(每张 GPU 持有部分层的 KV)
- 跨卡 KV 读:不走 collective(all-gather / send-recv),而是 CPU 上的 mmap 共享池[11]
- 在同一层组内(同 PP stage 的多个 TP rank),TP rank 0 作 writer 执行 D2H 备份到 CPU mmap 池
- 同层组的其他 TP rank 作 reader,attach 同一 mmap、直接 H2D 拉取,避免每个 TP rank 各持一份 host KV 副本
- TP barrier 保证写入完成后再读
- 跨 PP stage 仍按 PP P2P 走 hidden state,不走 mmap
效果数字
8×H200 测试(SGLang PR #27370[11]):CPU 内存从约 460 GB 降至约 60 GB——(TP-1)/TP 的副本被消除,多 GPU rank 通过 mmap 共享同一份 host KV,不再重复持有。
与 PP/TP 的关系
| 维度 | 作用 | 是否跨卡通信 |
|---|---|---|
| PP | 把模型层切到不同 stage | stage 间 hidden state P2P send/recv |
| TP | 把 head 切到不同 rank | head 间 all-reduce / all-gather |
| LayerSplit | 把 KV cache 按层段放到不同 rank | mmap 共享(writer/reader + TP barrier) |
@tbl-layersplit-vs-pp-tp LayerSplit 与 PP/TP 的对比
LayerSplit 可以叠加在 TP/PP 之上——它管的是 KV cache 放哪里,不是计算切到哪里。
HiSparse 与 attention 计算的耦合
HiSparse 在 06-inference 中已写过通信路径(GPU↔CPU swap,详见 06-inference § HiSparse 的通信路径)。这里只关心 attention 计算过程怎么和 swap 路径耦合。
三步串行流水
一次 attention(F 或 S 层)的执行顺序[12][13]:
- Indexer 选 top-K:DSA indexer 算出本 step 的 top-K=2048 索引(F 层重算 / S 层复用)
- Cache miss 检测 + swap-in:专用 CUDA kernel 比对 device buffer,找出未命中的 KV 页,LRU 驱逐旧页,从 CPU pinned pool 异步 H2D 拉取 miss 页
- Attention kernel:在完整的 top-K KV 上跑 MLA core attention(用 FlashMLA / FA3)
当前同步路径:异步 IO overlap 仍是 draft(SGLang PR #28523[13]),主线版本 swap-in 与 attention 串行执行——这意味着 swap-in 延迟直接计入 TTFT / TPOT。
Slot 单位与 page size
device_buffer_size 在 LMSYS blog 中以 "slots" 计(4096-6144),单位实际是 KV page(page size 推断 = 16 token,对齐 SGLang chunked-prefill-size),不是 token[12]。也就是说 4096 slots ≈ 65536 token 的 KV 容量。
搬的是 latent,不是上投影
HiSparse 在 CPU↔GPU 之间搬运的是 MLA 压缩后的 512 维 latent KV(+ 64 RoPE key),不是上投影后的 head dim KV[14]。上投影和 RoPE absorb 在 GPU 的 attention kernel 内完成,与 swap 路径解耦。
这一点和 KV FP8 配合得非常自然——搬的字节只有约 640 bytes/token/layer,对 PCIe 带宽友好。1M context 下完整 KV ≈ 640 × 1M × 78 ≈ 50 GB,PCIe Gen5 ~64 GB/s 的理论"全集 swap"时长 ~O(1s)。但实际推理中并不会一次性搬全集——swap-in 按 cache miss 触发、按 top-K 中未命中页粒度拉取,实际计入 TTFT/TPOT 的延迟由 miss 率决定,不能直接用全集带宽估算。
与 chunked prefill / continuous batching 交互
- Chunked prefill:每 chunk 内 KV 边算边量化边写入 device buffer,超出 buffer 触发 swap-out 到 CPU pool
- Continuous batching:device buffer 在多 request 间共享(不是 per-request 隔离),不同 request 的热 KV 在同一池中按 LRU 竞争——高并发时长时间空闲的 request 的 KV 会被驱逐
无 fallback
没有"miss 太多就跳过稀疏化"的 fallback 逻辑[14]。这意味着如果 device buffer 太小或工作负载导致 hit rate 极低,attention 会被 swap-in 拖慢——LMSYS blog 报的低并发场景 "swap-in 反而是净负担"对应这一情形。
1M 上下文:本文不覆盖的几个维度
为避免主题失焦,本文专注架构 + 算子层 + 工程实现。以下与 1M 长上下文相关但属于其他子领域的话题本文不展开:
- RoPE base scaling(YaRN / NTK / dynamic NTK):GLM-5.2 用
rope_theta=8,000,000(详见 01-总览 配置表),是否在训练中走 NTK-aware scaling、推理时是否动态调整公开资料未明示。详见外部资料。 - Attention sink:长 context 下首 token 偏置现象与 DSA top-K 选择的交互。GLM-5.2 是否专门处理 sink token(如 strict 保留首 4 token)公开资料未提。
- SWA 边界(不适用):GLM-5.2 全量 DSA,无 SWA 层,所以也没有 SWA window 边界相关问题。
这些留作后续调研挖坑,不在本文范围。
1M 上下文四件套(数字订正版)
| 技术 | 层面 | 解决的问题 | 关键数字 |
|---|---|---|---|
| IndexShare | 模型架构 | Prefill 计算量 | 1/4 indexer 保留率,FLOPs 比 2.9×(非延迟比) |
| KV FP8 E4M3 | 推理量化 | KV cache 显存占用 | 1152 → ~640 bytes/token/layer (per-tensor),约 44% 节省 |
| LayerSplit | 推理引擎 | KV 跨卡分布 | mmap 共享后 8×H200 CPU ~460 → 60 GB |
| HiSparse | 推理引擎 | Decode KV 搬运 | 4-6k slot device buffer,throughput +3% 到 +192% |
@tbl-glm52-four-piece 1M 上下文四件套(含实际数字)
四件套的协同:IndexShare 管算力 / KV FP8 管字节密度 / LayerSplit 管多卡分布 / HiSparse 管 GPU↔CPU 流转。1M context 在单 H200 装不下,必须四件套全员上场。
三件套的 prefill / decode 算子表
下表参数:$B$ = batch, $L$ = sequence length, $K$ = 2048 top-K, $H^I=32$, $d^I=128$, $H=64$, $d_h=128$(V)/ 192(K nope)/ 64(RoPE),$d_{\text{lat}}=512$。
F 层 prefill 单层算子(dominant)
| Op | FLOPs | Bytes Read (主导项) |
|---|---|---|
| Q proj(W^{Q,A} + W^{Q,B}) | $2BL(d \cdot r_Q + r_Q \cdot H d_h) \approx 2BL \cdot 2048 \cdot 16384$ | $BL \cdot d$ |
| KV proj(W^{KV,A}) | $2BL \cdot d \cdot 576$ | $BL \cdot d$ |
| Indexer score GEMM | $\mathbf{8192 B L^2}$ | $BL \cdot H^I d^I$ |
| Top-K + scatter | $O(BL^2 \log L)$ | $BL^2$ |
| Core QK^T(top-K) | $2 B L \cdot H \cdot 256 \cdot K$ | $BLK \cdot H \cdot 256$ |
| Softmax | $\sim 5BL \cdot HK$ | — |
| AV matmul | $2 B L \cdot H \cdot K \cdot d_h$ | $BLK \cdot H d_h$ |
| W^O | $2BL \cdot H d_h \cdot d$ | $BL \cdot H d_h$ |
@tbl-glm52-prefill-f F 层 prefill 算子表(dominant 为 indexer score GEMM)
S 层 prefill
= F 层算子表去掉 indexer score GEMM 与 Top-K(节省 $8192 BL^2$ FLOPs)。其余完全一致。
Decode 单 step(absorb 路径)
| Op | FLOPs | Bytes Read | Bound |
|---|---|---|---|
| Q proj | $\sim 4M \cdot B$ | weight $\sim 36$ MB | compute |
| 读 KV cache(latent,FP8 per-tensor scale) | — | $\mathbf{L \cdot 640}$ bytes/layer/token | memory |
| Indexer score(仅 F 层) | $\sim 8192 BL$ | $L \cdot H^I d^I$ | memory |
| Top-K(仅 F 层) | $O(BL \log L)$ | $BL$ | memory |
| Score(absorb 路径) | $2 B K \cdot 2048$(latent 内) | KV latent + Q | memory |
| Output(absorb 路径) | $2 B K \cdot d_{\text{lat}} \cdot d$ | KV latent | memory |
@tbl-glm52-decode Decode 单 step 算子表(absorb 路径,几乎全部 memory-bound)
关键含义:decode 阶段每个 attention step 的算力极小(≤ $10^{10}$ FLOPs/step),瓶颈完全在 KV cache 字节读取。这就是为什么 FP8 KV + HiSparse + Absorb 三者叠加效果最显著——它们都直接攻击访存。
与 GQA / MQA 的字节基准
把 GLM-5.2 的 MLA 放到 KV cache 压缩谱里看:
| 方案 | 配置 | per-token per-layer 字节 (BF16) | vs MHA |
|---|---|---|---|
| MHA | $n_h=64$, $d_h=128$ | 32,768 | 1× |
| GQA-8 | 8 KV head | 4,096 | 8× |
| MQA | 1 KV head | 512 | 64× |
| GLM-5.2 MLA | $d_{\text{lat}}=512$ + RoPE 64 | 1,152 | 28× |
| GLM-5.2 MLA + FP8 (per-tensor) | 同上 + e4m3 量化 | ~640 | ~51× |
| DSV4 CSA | 4× 序列压缩 + dense | ~128(平均) | ~256× |
| DSV4 HCA | 128× 序列压缩 | ~4(平均) | ~8192× |
@tbl-glm52-kv-bytes-vs-baselines KV cache 字节谱系
GLM-5.2 的 MLA + FP8 在常规压缩方案里靠前(50×),但相对 DSV4 的序列压缩路线(256-8192×)仍差两个数量级——后者通过 token 维度的压缩获得更高密度,代价是信息损失来自压缩本身。详见下节。
与 DSV4 CSA/HCA 的路线级差异
GLM-5.2 和 DeepSeek V4 都面向 1M 上下文,但走了两条截然不同的技术路线。
| 维度 | GLM-5.2 | DeepSeek V4 |
|---|---|---|
| 注意力底座 | MLA(维度压缩) | MLA(维度压缩) |
| 长上下文策略 | 稀疏选择:DSA indexer top-K,少算 query-key 对 | 序列压缩:CSA 压 4×、HCA 压 128×,少存 KV entry |
| 每 token 关注的 KV 数 | 2048(固定 top-K) | CSA ≤1024(top-K 选择)/ HCA ~8K(dense 压缩 entry) |
| 注意力类型混合 | 无混合,全量 DSA | CSA / HCA / SWA 按层混合堆叠 |
| 单 F 层 indexer FLOPs (1M, BS=1) | $\sim 8.2 \times 10^{12}$ | CSA $\sim 1.0 \times 10^{12}$(压缩后 L/4 个 entry) |
| 1M KV cache 大小 | ~49 GB(FP8 per-tensor,78 层 × 1M × 640 B) | ~12 GB(HCA 主导,估算) |
| 核心优化手段 | 跨层复用 indexer(IndexShare) | 序列方向压缩 KV entry(CSA/HCA) |
@tbl-glm52-vs-dsv4 GLM-5.2 与 DeepSeek V4 注意力路线对比
两种路线的本质差异不在最终效率,而在"看什么"的保真度:
- 稀疏选择(GLM-5.2):每个被关注的 token 都是精确的原始 token——DSA indexer 从全序列中选出 top-2048 个原始 key 做精确 attention。适合需要精确匹配的长上下文任务(代码库检索、长文档问答)。
- 序列压缩(DSV4):被关注的 entry 是多个原始 token 的压缩表示——CSA 把每 4 个连续 token 压成 1 个 compressed entry,HCA 压 128 个。适合需要全局视野但不要求逐 token 精确匹配的任务。
两者选取的 entry 数在同一数量级,真正的区别是 entry 的语义精度而非数量——原始 token vs 压缩 token。GLM-5.2 为什么选稀疏选择而非压缩?技术理由是 DSA 的 token 预算效率——GLM-5 团队发现,通过 20B token 的稀疏适配就能让 DSA indexer 追平全注意力精度(对比 DS V3.2 的 DSA 需要 943.7B token)[15]。IndexShare 进一步把 indexer 成本压到 1/4,使稀疏选择的算力代价不再成为瓶颈。
纯稀疏路线的代价:GLM-5.2 没有全注意力层兜底,DSA indexer 的训练质量直接决定模型上限。GLM-5 通过预热(1000 步冻结主模型仅训 indexer)+ 20B token 稀疏适配来保证 indexer 质量,但这条路的鲁棒性依赖持续的高质量 indexer 训练——一旦 indexer 退化,没有 dense attention 作为安全网。相比之下,DSV4 的 CSA 压缩保留了对所有压缩 entry 的 dense attention,信息损失来自压缩本身而非选择错误。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 三层叠加 | MLA(KV 压缩 28×/50×)+ DSA(top-K=2048 稀疏选择)+ IndexShare(1/4 层跑 indexer),全部 78 层统一运行 |
| MLA 算子链 | 5 个 GEMM(Q lora down/up + KV lora down/up + W^O),naive prefill 走完整链,decode 走 absorb |
| Absorb 技巧 | Decode 用 $W^{KQ}, W^{OV}$ 在 latent (512 维) 做 attention,绕过对历史 token 上投影;prefill 不 absorb(红利仅在 $S_q \ll S_{kv}$) |
| NoPE+RoPE 拆分 | 192/64 拆分原因:RoPE 不可 absorb,必须独立;FlashMLA 单 kernel concat 处理 |
| KV cache 字节 | BF16 1152 / FP8 ~640 (per-tensor scale) ~ 656 (per-group scale);MLA 压 28×、加 FP8 共 ~51× |
| KV FP8 ≠ INT8 | 业界俗称 "KV8" 在 SGLang/vLLM 路径实际是 FP8 E4M3;SGLang 默认 per-tensor scale;dequant 必须 fused |
| LayerSplit | 按 layer 段切分 + 同 PP stage 内多 TP rank 通过 CPU mmap 共享(writer/reader + TP barrier),8×H200 CPU ~460→60 GB |
| HiSparse 耦合 | indexer→swap-in→attention 三步串行(async 仍 draft);搬的是 latent (~640B/token);slot = KV page |
| 全量 DSA | 消融证明 DSA 是唯一无损的高效注意力方案,SWA 有质量损失,因此不留全注意力层兜底 |
| vs DSV4 | GLM-5.2 看原始精确 token(top-K=2048),DSV4 看压缩表示(CSA ≤1024 / HCA ~8K);KV 字节 DSV4 更省 4-160× |
参考资料
- HuggingFace, GLM-5.2 Blog, 2026-06. https://huggingface.co/blog/zai-org/glm-52-blog
- 本文档第二轮深化调研笔记 (Sub 1, MLA 算子层),
.cache/iforge-research/glm-5.2-r2-03/_sub1_mla_ops.md。 - HuggingFace GLM-5.2 config.json. https://huggingface.co/zai-org/GLM-5.2/blob/main/config.json
- FlashMLA, deepseek-ai/FlashMLA. https://github.com/deepseek-ai/FlashMLA
- vLLM Discussion: MLA weight absorption rationale. https://github.com/vllm-project/vllm
- SGLang DSA backend 源码 (
python/sglang/srt/layers/attention/dsa/),sgl-project/sglang。https://github.com/sgl-project/sglang - GLM-5 Technical Report, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
- SGLang Quantized KV Cache Documentation. https://docs.sglang.io/advanced_features/quantized_kv_cache.html
- vLLM, FP8 KV Cache State, 2026-04. https://vllm.ai/blog/2026-04-22-fp8-kvcache
- vLLM Recipes: GLM-5.2 deployment. https://recipes.vllm.ai/zai-org/GLM-5.2
- SGLang PR #27370, CPU memory share across TPs. https://github.com/sgl-project/sglang/pull/27370
- LMSYS, SGLang HiSparse: Long-Context Inference, 2026-04. https://lmsys.org/blog/2026-04-10-sglang-hisparse/
- SGLang PR #28523, HiSparse IO overlap (draft). https://github.com/sgl-project/sglang/pull/28523
- 本文档第二轮深化调研笔记 (Sub 3, LayerSplit + HiSparse),
.cache/iforge-research/glm-5.2-r2-03/_sub3_layersplit_hisparse.md。 - GLM-5 Technical Report, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
延伸阅读
- 02-indexshare — IndexShare F/S 机制与 indexer 算子表
- 06-inference — HiSparse 通信路径 / TITO Gateway / EP all-to-all
- ../02-DeepSeek-V4/03-attention — DSV4 的 CSA/HCA 序列压缩路线
- 08-动态稀疏选择 — DSA/NSA/MoBA 通用机制 SSOT