IndexShare
利用相邻层 top-K 索引的 70-100% 重叠,让 3/4 的 Transformer 层跳过 indexer 计算
核心要点:
- DSA 每层的 lightning indexer 仍是 $O(L^2)$,200K 下占 prefill 81%
- 相邻层 top-K 重叠 70-100%,残差增量渐进
- F 层保留 indexer 并缓存 top-K,S 层直接复用
- 2.9× 是 FLOPs 比,非延迟比(HF blog 原文 "per-token FLOPs by 2.9×")
- 端到端延迟实测最高点:200K / 1.82×(IndexCache Table 1)
前置阅读
DSA 索引器为什么是瓶颈?
DSA 的每层注意力拆成两阶段:先用轻量 lightning indexer 对所有前文 token 打分、选出 top-K 个最相关的 key 位置;再用 core attention 只在这 K 个 token 上计算精确注意力。复杂度从 $O(L^2)$ 降到 $O(L \cdot K)$,但 indexer 本身仍是 $O(L^2)$。
indexer 的轻量是相对的——32 头 × 128 维、低秩投影、FP8 精度,单次点积 FLOPs 约为 MLA 主注意力的 1/10[1]。但 $O(L^2)$ 的平方项不因单次成本低而消失。
瓶颈随序列长度恶化。 IndexCache 论文对 GLM-5 30B 模型的实测[2]:200K token 上下文下,所有层的 indexer 计算合计占 prefill 总时间的 81%()。也就是说,prefill 阶段只有 19% 的时间在做"真正有效"的 core attention——其余全被 indexer 占用。
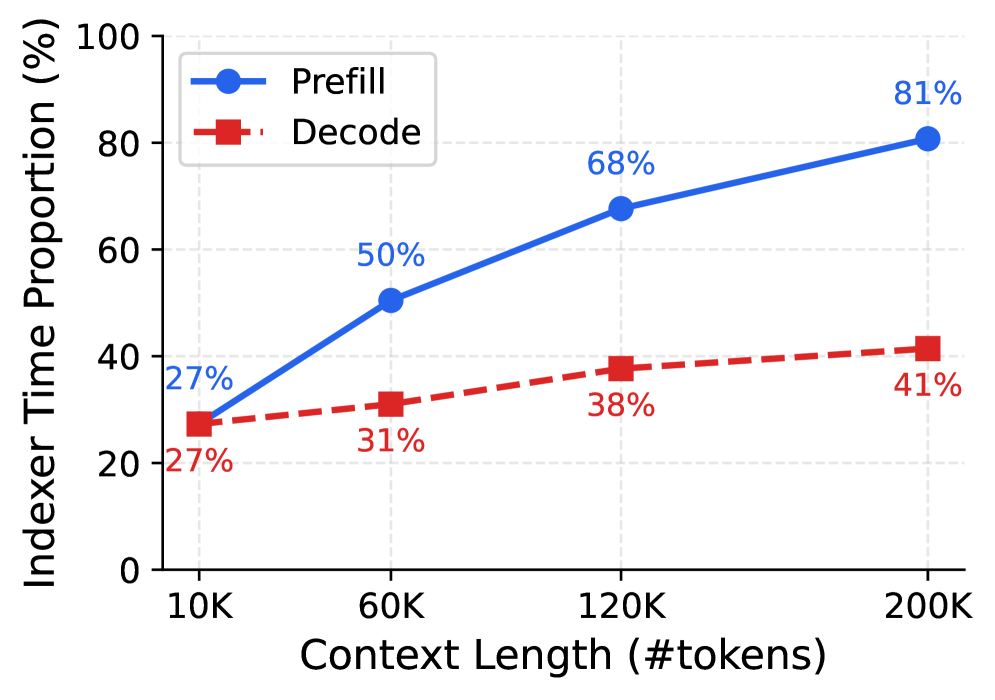
DSA 的根本矛盾在于:indexer 让注意力从 $O(L^2)$ 降到 $O(L \cdot K)$,但 indexer 自身的 $O(L^2)$ 又成了新瓶颈。 优化的方向不在继续压缩单层 indexer(它已经足够轻量),而在减少需要跑 indexer 的层数。
相邻层的 top-K 为什么高度重叠?
IndexCache 团队对 47 层 30B DSA 模型做了一个关键测量[2]:计算每对相邻层 indexer 输出 top-K token 集合的 Jaccard 重叠率。
结果:相邻层 top-K 重叠 70-100%()。热力图进一步显示,重叠度呈现聚类结构——层内块间(例如第 10-15 层之间)的重叠远高于跨块(例如第 10 层 vs 第 40 层),图中红框框出的对角块就是层内高重叠区。
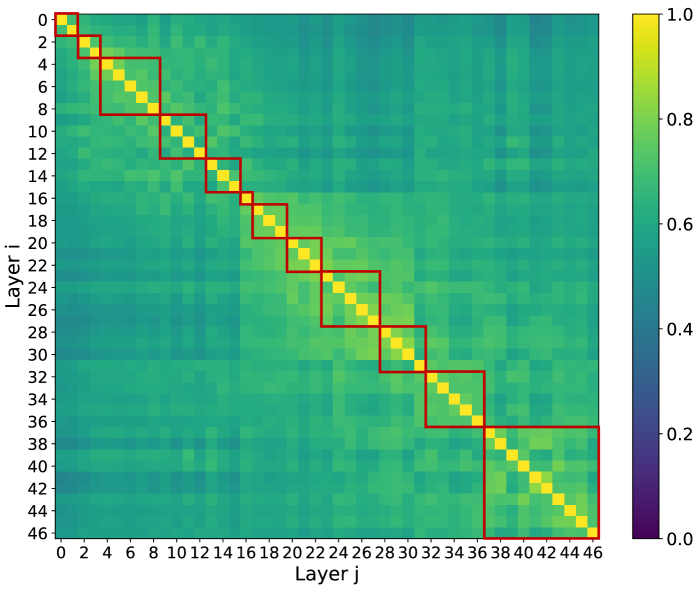
这个现象有清晰的直觉解释。残差连接意味着第 $\ell+1$ 层的 hidden state $h^{(\ell+1)}$ 是第 $\ell$ 层的增量修改:
$$\begin{equation} h^{(\ell+1)} = h^{(\ell)} + \Delta^{(\ell)} \label{eq:indexshare-residual-increment} \end{equation}$$其中 $\Delta^{(\ell)}$ 是 attention + FFN 子层的输出。在训练良好的深层 Transformer 中,$\Delta^{(\ell)}$ 的模长通常远小于 $h^{(\ell)}$——残差增量的变化是渐进的。因此 token $i$ 对 token $j$ 的"相关度"在相邻层之间不会剧烈跳变。Indexer 打出的分数高度相关,top-K 自然也高度重叠。
这个发现把瓶颈变成了机会:如果第 $\ell$ 层和第 $\ell+1$ 层索引器选出几乎相同的 token 集合,第 $\ell+1$ 层就不需要再跑一次 $O(L^2)$ 的 indexer——直接复用第 $\ell$ 层的结果即可。
Indexer 算子如何实现?
GLM-5.2 的 lightning indexer 不是一个独立的小型 attention,它复用了 MLA 的压缩 latent,在算子级与 MLA 紧密耦合。HF config 的实际字段名直接对应:index_n_heads=32 / index_head_dim=128 / index_topk=2048 / index_topk_freq=4(每 4 层共享一次)/ indexer_types(每个稀疏层标 full/shared,前 3 dense 层独立标 full)[3]。
Q/K 投影链路
Q 路径复用 MLA 的压缩 query latent $c^Q$($q_{\text{lora\_rank}}=2048$,参 01-总览 配置表),再过独立的 indexer Q 投影矩阵 $W^{Q,\text{idx}} \in \mathbb{R}^{2048 \times 4096}$,输出 32 头 × 128 维的 query[4]:
$$\begin{equation} q^I_{t} = \mathrm{Reshape}\Big(\mathrm{RMSNorm}(c^Q_t)\, W^{Q,\text{idx}}\Big) \in \mathbb{R}^{H^I \times d^I} \label{eq:indexshare-q-proj} \end{equation}$$K 路径走 MQA 风格,所有 32 个 query head 共享一个 128 维 key vector,从 hidden state 独立投影 $W^{K,\text{idx}} \in \mathbb{R}^{6144 \times 128}$:
$$\begin{equation} k^I_{s} = \mathrm{LayerNorm}\big(h_s\, W^{K,\text{idx}}\big) \in \mathbb{R}^{d^I} \label{eq:indexshare-k-proj} \end{equation}$$两个归一化的选择有意为之:Q 用 RMSNorm(与 MLA 主路径一致),K 用 LayerNorm 而非 RMSNorm,目的是收窄动态范围以便后续 FP8 量化(释义自 leonericsson 实现笔记[4])——K 因为要参与 FP8 GEMM,动态范围控制比 Q 严苛。
打分公式与激活
Indexer score 不是标准 softmax attention,而是 per-head ReLU 累加 + 标量门控[1]:
$$\begin{equation} \mathrm{score}_{t,s} = \sum_{j=1}^{H^I} w^I_{t,j} \cdot \mathrm{ReLU}\!\left(q^I_{t,j} \cdot k^I_s\right) \label{eq:indexshare-score} \end{equation}$$其中 $w^I_{t,j}$ 是每头的标量门控,由 $W^{W,\text{idx}} \in \mathbb{R}^{6144 \times 32}$ 投影得到,内含 $1/\sqrt{H^I \cdot d^I}$ 缩放因子。
为什么用 ReLU 而非 softmax:DeepSeek-V3.2 论文直接说明"We choose ReLU as the activation function for throughput consideration"[1]。ReLU 截断负相关、避免 softmax 的全局归一化,从而省掉 online normalization、单次 batched GEMM 就能算完——无需 FlashAttention 风格的分块归一化。
FP8 量化的具体粒度
Indexer 的 score GEMM 在 FP8 精度下执行[4]:
- Walsh-Hadamard 旋转:q、k 投影后先做 Hadamard 变换,均衡动态范围
- per-block 量化:FP8 scale 是 per-block(推断 block size = 128 elements,对应 H100 FP8 GEMM 标准块),不是 per-tensor 或 per-token
- K scale cache:每个 token 的 key scale 缓存在
k_scale_cache中,与 KV cache 分离
这套组合让 indexer 单次点积的 FLOPs 仅为主 MLA 的约 1/10,但量化误差控制在不影响 top-K 排名的范围内。
Top-K 选择
K=2048 的选择走精确算法(推断为 CUDA radix select 或 bitonic sort),不用近似最近邻(HNSW 等)。Causal mask 隐含——prefill 阶段 query $t$ 只对 $s<t$ 的 token 有 $k^I$ 存在;decode 阶段 query 是单 token,无需显式 mask。
Indexer per-layer 算子表
下表给出 GLM-5.2 indexer 单层在 prefill 阶段的算子分解(B = batch, L = sequence length):
| 步骤 | 算子 | 形状变换 | 主导 FLOPs | 备注 |
|---|---|---|---|---|
| RMSNorm($c^Q$) | element-wise | $B{\times}L{\times}2048$ | $\sim 2BL{\cdot}2048$ | 共享 MLA latent |
| $W^{Q,\text{idx}}$ | GEMM | $\to B{\times}L{\times}32{\times}128$ | $2BL{\cdot}2048{\cdot}4096$ | indexer 独立 |
| $W^{K,\text{idx}}$ | GEMM | $B{\times}L{\times}6144 \to B{\times}L{\times}128$ | $2BL{\cdot}6144{\cdot}128$ | MQA 单 key |
| LayerNorm($k^I$) | element-wise | $B{\times}L{\times}128$ | $\sim 2BL{\cdot}128$ | 为 FP8 准备 |
| Hadamard(q, k) | rotate | 同 | $\sim BL{\cdot}(H^I{+}1){\cdot}128$ | 动态范围均衡 |
| Score GEMM (FP8) | batched GEMM | $B{\times}L{\times}32{\times}L$ | $\mathbf{2BL^2{\cdot}H^I{\cdot}d^I = 8192\,BL^2}$ | dominant |
| $W^{W,\text{idx}}$ + ReLU + 加权和 | GEMM + reduce | $B{\times}L{\times}L$ | $\sim 2BL{\cdot}6144{\cdot}32 + 3BL^2{\cdot}32$ | 门控合并 |
| Top-K select | radix-k | $\to B{\times}L{\times}2048$ | $\sim BL^2 \log L$ | 精确选择 |
@tbl-indexer-ops Lightning indexer 单层算子表(prefill 阶段)
Dominant term 是 score GEMM,$8192 B L^2$ FLOPs/layer。在 $L = 128\text{K}$ 时约 $1.34 \times 10^{14} B$ FLOPs,比 MLA 主注意力的 $5.4 \times 10^7 \cdot B \cdot L$ 贵约 20×——这就是 indexer 占 prefill 81% 的根本原因。
Decode 阶段单 token 的 score 是 $8192 \cdot L$ FLOPs/step,在 $L = 128\text{K}$ 下约 1.05 GFLOPs,相对 FFN 可忽略。Indexer 在 decode 阶段不是计算瓶颈,而是访存瓶颈(需读 $L \cdot 128$ bytes 的 FP8 key cache)。
F/S 层怎么共享索引?
IndexShare 把 Transformer 层分成两类,实现极简[2]。
F 层:保留完整 indexer
F 层(Full Layer)的行为与标准 DSA 完全相同:
- Indexer 打分:32 头 × 128 维的轻量 indexer 对全序列 $L$ 个 token 做 query-key 点积,产出 $L$ 个分数
- Top-K 选择:从 $L$ 个分数中选最高的 $K=2048$ 个 token 位置
- 缓存索引:将这 2048 个位置写入 $T_{\text{cache}}$(详见下一节内存口径)
- Core attention:在选出的 2048 个 token 上做精确 MLA 注意力
S 层:跳过 indexer
S 层(Shared Layer)没有 indexer。它直接读取最近 F 层写入的 $T_{\text{cache}}$,拿那 2048 个 token 位置做 core attention。
实现只需通过 forward 函数参数 prev_topk_indices 在层间传递 top-K 索引(SGLang deepseek_v2.py 实测代码[5])。S 层判断自己的 indexer_types[layer_idx] == "shared" 时跳过 indexer GEMM,直接用 prev_topk_indices 取 KV。
GLM-5.2 的 1/4 保留率
GLM-5.2 的 78 层按 [前 3 层 dense full] + [S, S, S, F] 周期循环[3]:
层: 1 2 3 | 4 5 6 7 | 8 9 10 11 | ...
类型: F F F | S S S F | S S S F | ...
(dense) | └─ 复用 L3 ──┘ └─ 复用 L7 ─┘
前 3 层为 dense MLP(非 MoE),indexer 类型均为 full。从第 4 层起进入稀疏 MoE 区,按 [S, S, S, F] 周期循环——F 层落在每个 4 层组的末尾,紧邻其后的 3 个 S 层从下一组复用本组 F 层的 top-K。78 层中共 21 个 F 层(3 dense + 18 MoE)、57 个 S 层——indexer 计算量降至约 1/4。
为什么 F 在组末尾而非开头:执行顺序上 S 层先于 F 层时,S 必须读 前一组 的 F;F 在组末意味着每个 F 服务"下一组" 3 个 S。这与 KL 蒸馏目标($\mathcal{L}_{\text{multi}}^I$ 中 $j$ 取 1..m)方向一致——F 训练时学的就是"为下方 3 层服务"。
为什么选 1/4 而不是 1/2 或 1/8? 这是精度-FLOPs tradeoff 的 sweet spot[2]:
| 保留率 | F 层占比 | Indexer 节省 | 精度影响 |
|---|---|---|---|
| 1 (全 indexer) | 100% | 0 | 基线 |
| 1/2 | 50% | 50% | 论文报告 "near-lossless"(具体精度差未给数)[2] |
| 1/4 | 25% | 75% | uniform interleaving 在 RULER 上可匹配/超越全索引器[2] |
| 1/8 | 12.5% | 87.5% | 层间距离过大,重叠衰减,精度退化(论文未给具体数) |
@tbl-indexshare-retention F/S 保留率 tradeoff
1/2 精度好但省得少,1/8 省得多但性能下降。1/4 在 Training-aware 模式下能匹配全索引器精度——F 层 indexer 学会服务其后 3 个 S 层的需求。
F 层 cache 的内存口径
之前一句"复用 DSA 已分配的 top-K 索引空间"描述太虚——实际 cache 的字节口径和生命周期需要更精确说明,因为它影响 KV cache 预算与并行切分。
数据结构与字节公式
F 层 cache 存的是 int32 token 索引,不含 score/logit。SGLang 实现明确 dtype[5]:
buffer = torch.zeros(
(max_batch_size, num_layers, topk_size),
dtype=torch.int32, device=device,
)
实际 cache 分两层:
- Layer-to-layer 临时 tensor:每个 F 层算完 top-K 后通过函数参数
prev_topk_indices直传下一层,形状 $(B, K)$,单份覆写,不随 F 层数累积 - 持久 buffer(可选,用于 RL / 投机采样):形状 $(B, F_{\text{layers}}, K)$,dtype int32
字节公式:
$$\begin{equation} \text{cache\_bytes} = B \cdot F_{\text{layers}} \cdot K \cdot 4 \label{eq:indexshare-cache-bytes} \end{equation}$$代入 GLM-5.2 ($F_{\text{layers}}=21$, $K=2048$):
| 场景 | 临时 tensor | 持久 buffer |
|---|---|---|
| prefill 1M / batch=1 | 8 KB | 168 KB |
| prefill 1M / batch=8 | 64 KB | 1.34 MB |
@tbl-indexshare-cache-bytes F 层 cache 字节数(GLM-5.2,K=2048,int32)
关键性质:cache 大小与 seq_len 无关——它存的是"每个 batch token 选了哪 2048 个 KV 位置",不是 KV 本身。1M 上下文下 F 层 cache 仍 < 2 MB。论文原话"no additional GPU memory beyond what standard DSA already allocates"指这一点[2]。
不进 KV cache 的 paged pool
F 层 cache 是独立 contiguous buffer,与 KV cache 的 paged memory pool 解耦。SGLang DSATokenToKVPool 管理 paged KV 块,index cache 不进这块——两者生命周期与访问模式完全不同(cache 是密集索引、按 batch 整批读写;KV 是 paged、按 token 局部读写)。
Prefill vs Decode 的写入差异
- Prefill:F 层一次性对全 $L$ 个 token 算完 top-K,写入临时 tensor,S 层在同一 forward pass 内即时读取。chunked prefill 下每 chunk 写各自的 token 范围
- Decode:F 层每步对完整 KV cache 重新算 top-K(论文 §4.2 明示[2]),每步覆写。新 token 进来后排名可能变,所以 F 层不能复用前一步的 top-K
这意味着 IndexShare 在 decode 阶段的节省机制和 prefill 不同——下一节专门展开。
Decode 阶段的 IndexShare 收益是什么?
Prefill 阶段的故事干净:F 层一次性算 top-K、S 层直接复用,indexer 计算量降到 1/4。但 decode 阶段F 层每步重算,IndexShare 的"复用"是怎么发生的?
答案是:复用发生在同一 step 内的层间,不是跨 step。每个 decode step 内,22 个 F 层各自算一遍当前 step 的 top-K(每步 $8192 \cdot L$ FLOPs/F 层),56 个 S 层全部跳过——节省的是同一 step 内 S 层的 indexer 计算,而不是把 F 层的结果"缓存到下一步"。
| 阶段 | F 层行为 | S 层行为 | 节省来源 |
|---|---|---|---|
| Prefill | 一次性对全 L 算 top-K | 跨层读 F 层 cache | 75% 层的 $O(L^2)$ |
| Decode 每步 | 对当前 KV cache 重算 top-K | 同 step 跨层读 F 层 cache | 75% 层的 $O(L)$ + key cache 读取 |
@tbl-indexshare-prefill-vs-decode IndexShare 在 prefill / decode 的不同收益形式
Decode 收益更偏访存而非算力。indexer 单 token 在 decode 时算力极小($8192 L$ FLOPs/step)、但要扫一遍 $L \cdot 128$ bytes 的 FP8 key cache。S 层跳过 indexer 等于跳过 75% 层的 key cache 扫读——在 long context decode 下,这是访存带宽的实质节省。
IndexCache 论文 200K decode 实测 1.48× tok/s 提升[2],与这套机制吻合:算力节省小、访存节省大、综合加速 ~1.5×。
Training-free vs Training-aware:两条部署路径
IndexCache 论文提供了两种将 IndexShare 部署到 DSA 模型的方式[2]。
Training-free:贪婪搜索
不需要更新模型权重,直接在已有 DSA 模型上搜索最优的 F/S 层分配。算法如下:
- 从全部层均为 F 层(全 indexer)开始
- 对每个候选层,模拟将其翻转为 S 层后的 LM loss 增量
- 选 loss 上升最小的层执行翻转(贪心)
- 重复 2-3 直到达到目标保留率
为什么贪心有效? 论文给出三条经验支撑[2]: (1) 贪心搜索产出的 pattern 质量始终优于 uniform interleaving; (2) 搜索过程自然区分出"容易替代"和"关键保留"两类层(被早期翻转为 S 的层更容易被替代); (3) 同一标定集上学到的 pattern 在不同标定集上仍有效(pattern 迁移性)。从直觉上,残差连接的增量变化在相邻层之间是渐进的,因此一层被翻转的影响主要集中在邻近几层,不同层的翻转决策近似独立。
Training-free 模式在 GLM-5 30B 模型上实现了 1.82× prefill 加速(200K 上下文),精度损失可忽略。
Training-aware:多层 KL 蒸馏
在训练阶段引入跨层蒸馏,让 F 层 indexer 学会服务其后所有 S 层。
多层蒸馏损失[2]:
$$\begin{equation} \mathcal{L}_{\text{multi}}^I = \sum_{j=0}^{m} \frac{1}{m+1} \cdot \sum_{t} D_{\text{KL}}\left(p_t^{(\ell+j)} \parallel q_t^{(\ell)}\right) \label{eq:indexshare-multi-kl} \end{equation}$$其中:
- $\ell$ 为 F 层位置,$m$ 为该 F 层服务的 S 层数量(GLM-5.2 中 $m=3$)
- $p_t^{(\ell+j)}$ 是第 $\ell+j$ 层(S 层)的全注意力 softmax 分布
- $q_t^{(\ell)}$ 是 F 层 indexer 的注意力分布
- $\frac{1}{m+1}$ 是均匀加权——每个 S 层等权重
训练目标:F 层 indexer 的优化目标不是匹配自身层的注意力分布,而是匹配其下 $m$ 个 S 层的平均注意力分布。这让 F 层的 top-K 选择兼顾后续多层的需求,而不偏向某一层。
uniform interleaving 为什么能匹配全索引器? 当 F 层均匀分布(每 4 层 1 个),每个 S 层距离其 F 层最多 3 层。在这个距离内,残差增量的累积仍不足以改变 token 间的相关度排序(由 70-100% 重叠验证)。Training-aware 的 KL 蒸馏进一步让 F 层 indexer 的分布向 S 层靠拢,消除剩余的微小偏差。
GLM-5.2 的选择
GLM-5.2 走 Training-aware 路径。从 mid-training 阶段(序列长度 128K)引入 IndexShare[6],让模型在训练中学习适应跨层共享。这比 Training-free 更稳定——F 层 indexer 经过了专门优化以服务后续 S 层,而非硬塞一个未经适配的索引。
如何解读 2.9× 加速比?
之前的版本直接把 2.9× 当延迟加速比用,这是误读。2.9× 的原始出处是 HF blog 一句话[6]:
reducing per-token FLOPs by 2.9× at a 1M context length
也就是说:2.9× 是 per-token FLOPs 减少比,不是端到端 prefill 延迟加速比。FLOPs 减少不直接等于延迟减少——kernel launch、memory bandwidth、CUDA 调度开销都不随 FLOPs 缩放。
Measured vs Estimated
把现有数字按 "实测 / 推断" 分清:
| 来源 | 指标类型 | seq | 数值 | batch | 状态 |
|---|---|---|---|---|---|
| IndexCache Table 1 | prefill 延迟加速 | 10K | 1.27× | 1 | 实测 |
| IndexCache Table 1 | prefill 延迟加速 | 60K | 1.31× | 1 | 实测 |
| IndexCache Table 1 | prefill 延迟加速 | 120K | 1.51× | 1 | 实测 |
| IndexCache Table 1 | prefill 延迟加速 | 200K | 1.82× | 1 | 实测 |
| IndexCache Table 1 | decode tok/s | 200K | 1.48× | 1 | 实测 |
| HF blog | per-token FLOPs 减少 | 1M | 2.9× | 未注 | 理论值 |
@tbl-indexshare-measured-vs-estimated 加速比来源分类(30B DSA,BS=1,H100)
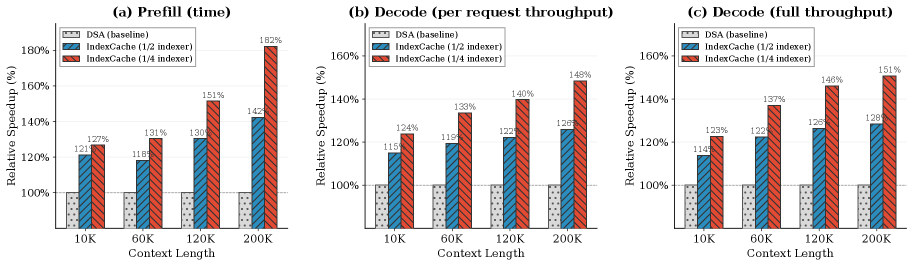
结论:实测延迟加速比的最高点是 200K 下 1.82×,1M 下 2.9× 是 FLOPs 理论比。端到端延迟在 1M 下的预期落在 ~2× 左右——具体数字依赖 kernel launch overhead 在 dominant term 之外的占比。
FLOPs 节省率公式
设 $r(L)$ 为 indexer 占 attention 部分 FLOPs 的比例(含 indexer + core attention 的 $QK^\top$ 与 $AV$,不含 FFN),按算子表的 dominant GEMM 推:
$$\begin{equation} r(L) = \frac{1}{1 + \dfrac{H \cdot K \cdot (d_{qk} + d_v)}{H^I \cdot L \cdot d^I}} = \frac{1}{1 + 10240/L_{\text{tokens}}} \label{eq:indexshare-fraction} \end{equation}$$代入 GLM-5.2 参数 $H=64$, $H^I=32$, $K=2048$, $d_{qk}=192$(MLA 主 Q/K head dim,含 NoPE+RoPE), $d_v=128$, $d^I=128$,得到分子常数 $H \cdot K \cdot (d_{qk}+d_v) / (H^I \cdot d^I) = 10240$(以 token 为单位)。
| L (tokens) | indexer 占 attention $r(L)$ | 跳过 3/4 F 层节省 | 理论 attention FLOPs 加速 |
|---|---|---|---|
| 10K | 49.4% | 37.0% | 1.59× |
| 100K | 90.7% | 68.0% | 3.13× |
| 200K | 95.1% | 71.4% | 3.49× |
| 1M | 99.0% | 74.3% | 3.89× |
@tbl-indexshare-fraction Indexer 占 attention 部分 FLOPs 的比例与节省(不含 FFN)
为什么 r(L) 表与 81% 实测、1.82× 实测不直接对应
三个数同时出现容易混淆,必须分清口径:
| 数字 | 分母 | 分子 | 性质 |
|---|---|---|---|
| 表中 r(L) 在 200K 下 95% | 仅 attention 部分(含 indexer + core) | indexer | 纯 GEMM FLOPs 比 |
| 论文 200K 下 indexer 占 81% | prefill 总时间(含 FFN + kernel launch) | indexer wall-time | wall-time 比 |
| 论文 200K 下 prefill 加速 1.82× | 跳过 75% F 层后的端到端 wall-time | — | 端到端实测延迟 |
关键差异:表 r(L) 不含 FFN,论文 81% 含 FFN;FFN 在 prefill 中是 $O(L)$ 而 indexer 是 $O(L^2)$,所以长 seq 下 indexer 必然主导,但短 seq 下 FFN 仍占可观比例——这就是为什么 wall-time 占比(81%)低于纯 attention FLOPs 占比(95%)。表 r(L) 的"理论 attention FLOPs 加速"(200K 下 3.49×)也比 wall-time 实测(1.82×)激进——因为后者被 FFN 抬高了分母。
正确读表方式:r(L) 表说明 attention 部分能省多少 FLOPs;想推总加速比,需乘以 attention 在 prefill 总时间中的占比(200K 下约 50-60%,估算)。
加速比在不同 batch / TP / PP 下的衰减
论文实测只覆盖单 batch、单卡(dp_size=8 dp_attention)。把 IndexShare 推到生产规模需要回答三个问题。下文标 [实测]/[工程推断]/[纯理论],读者据此判断采信强度。
Batch 维度 [工程推断]
理论上 indexer FLOPs $\propto B \cdot L^2$,core attention FLOPs $\propto B \cdot L \cdot K$,二者均 $\propto B$,比值不随 batch 变化——所以 IndexShare 的 FLOPs 节省比例不随 batch 衰减 [纯理论]。
转换到 wall-time 时仍有 batch-dependent 二阶效应(无公开实测,以下均 [工程推断]):
- BS=1:indexer score GEMM 是单 head 的窄 GEMM,GPU 利用率低于峰值;跳过 indexer 的 wall-time 节省比 FLOPs 比预测略高
- 大 batch + compute-bound:indexer / core attention 都接近峰值 FLOPs,wall-time 加速比 ≈ 理论 FLOPs 比
- 极长 seq + memory-bound:跳过 indexer 还省了 $B \cdot L^2$ 量级的 HBM 读写,wall-time 节省可能略超 FLOPs 比
结论:无公开多 batch 实测;理论上比例稳定,工程上 BS 4-32 区间应接近论文 BS=1 数值,但不应直接外推到具体数字。
TP 切分 [工程推断 + 代码佐证]
GLM-5.2 的 32 个 indexer head 跟随 MLA 主 Q 的 64 head 一起按 head 维度切——每 TP rank 持有 $H^I / TP$ 个 indexer head 的 query 和对应的 K cache 分片。
F 层 cache(top-K indices)在 TP rank 间默认各自计算、不同步。SGLang 实现可选 SGLANG_DSA_TOPK_BROADCAST 走 rank-0 broadcast,强制全 rank 用相同 top-K[5]:
group.broadcast(topk_indices, src=0)
为什么默认不 broadcast?S 层只需要本 rank head 持有的 KV 分片对应的 indices,跨 rank 同步没必要。Broadcast 仅在需要严格 deterministic top-K(如训练)时启用。
PP 切层 [工程推断]
GLM-5.2 的 indexer_types 从第 4 层起按 [S, S, S, F] 周期,F 落在每组末尾。PP 切点最优应对齐组末尾,让一个 F 和它服务的 3 个 S 落在同一 stage。
- 真实切点位置:前 3 dense 后(layer 3 后)+ 第 $3 + 4k$ 层后($k \geq 1$)——即 layer 3, 7, 11, ..., 75
- 若切到组中间(如 F 在 stage A,下一组 S 在 stage B),下游 S 需要本组 F 的 top-K:
topk_indices作为 layer 返回值随hidden_states一起走 PP P2P send/recv(无专用 stage-to-stage 通道) - 额外通信量:$B \cdot 2048 \cdot 4$ bytes/step = $8 B$ KB/step($B$ = batch size)——相对 hidden state 的 $B \cdot 6144 \cdot 2$ bytes = $12 B$ KB 是同量级,但增加一次同步点
实操建议:PP 切点对齐 $3 + 4k$ 边界($k \geq 1$)以消除 stage 间 cache 传递,这是 IndexShare 给 PP 调度增加的硬约束。
与 HiSparse 的共存 [工程推断]
HiSparse 把冷 KV 推到 CPU,GPU 上仅保留近期高频访问的"热"token 子集(具体保留率论文未公开,远小于 $L$)[7]。这对 IndexShare 的影响:
- F 层 indexer 只看 GPU 上的热 token 子集,top-K 选择范围从 $L$ 收窄到热子集大小
- IndexShare 跳过 75% F 层 indexer 计算的机制依然成立,但作用对象变小
- 两者解决正交问题(IndexShare 减算力 / HiSparse 减显存),叠加收益方向上正向——但目前没有公开实测确认乘法关系是否成立
EP 切分 [工程推断]
IndexShare 作用于 attention,EP 作用于 MoE FFN,模块独立。SGLang TBO overlap 中,S 层跳过 indexer 后 attention 整体变短,理论上可能让 EP all-to-all 偶尔露出 critical path,但大 batch 下影响可忽略(无公开实测)。
与 NSA/MoBA/HySparse 的本质差异
IndexShare 并非"另一种稀疏注意力",而是对已有 DSA 的跨层复用优化。它不改变注意力的稀疏选择方式(仍然用 DSA indexer + top-K),只减少需要跑 indexer 的层数。
| 维度 | IndexShare (GLM-5.2) | NSA (DeepSeek) | MoBA | HySparse (小米) |
|---|---|---|---|---|
| 稀疏机制 | DSA indexer top-K | 块级压缩 + 动态选择 + 滑窗三分支 | 块级 MoE 路由选择 | 全注意力做 oracle + 稀疏层交替 |
| 跨层复用 | 有(70-100% 重叠) | 无 | 无 | 有(全注意力层传 top-K) |
| Indexer 成本 | ~MLA 1/10 | 包含在三分支门控中 | MoE 路由 | 全注意力($O(L^2)$ 完整计算) |
| 训练方式 | Mid-training 128K 引入 | End-to-end 预训练 | 预训练集成 | 交替训练 |
| 每层都跑 indexer? | 否(仅 1/4 层) | 是(每层三分支) | 是(每层路由) | 全注意力层跑完整 attention |
@tbl-indexshare-competitors 与竞品的机制级对比
逐项对比:
- vs NSA:NSA 每层独立跑三分支门控,无跨层复用。IndexShare 通过 F/S 共享消除 75% indexer 计算,NSA 每层都需完整门控。但 NSA 的优势是端到端原生训练,不需要 DSA 的预热+稀疏适配两阶段。
- vs MoBA:MoBA 用 MoE 风格路由选 token 块,块边界硬切不可避免丢失跨块 token 关系。IndexShare 继承 DSA 的 token 级精细选择,粒度优势明显。
- vs HySparse:HySparse 的"跨层复用"依赖全注意力层做 oracle——先跑一次 $O(L^2)$ 全注意力,再把 top-K 传给后续稀疏层。oracle 成本远高于 IndexShare 的轻量 indexer(~MLA 1/10 vs 完整 MLA)。
- 为什么 GLM-5.2 不用 SWA:GLM-5 的消融实验[8]显示,SWA 在 128K RULER 上得分 69.59,对比全注意力 75.28、DSA ~75。即使模式搜索优化后,SWA 仍丢失了远距离精确检索能力。GLM 路线因此选择全量 DSA 稀疏而非 SWA + DSA 混合。
MTP 层的 IndexShare + KVShare
GLM-5.2 的 MTP(Multi-Token Prediction)同样应用 IndexShare[6],HF config 中对应字段是 index_share_for_mtp_iteration: true[3]。MTP 需要为 $n_{\text{steps}} = 7$ 个预测步各跑一次 attention:传统做法每步独立跑 indexer + core attention,共 $7 \times O(L^2)$ indexer 计算。
IndexShare on MTP:indexer 仅在第 1 步运行,top-K 索引供后续 6 步复用——indexer 计算从 $7\times$ 降到 $1\times$。
KVShare:第 1 步的 KV 缓存同样供后续步复用。这消除了 GLM-5.1 中训练(无 KV 复用)和推理(有 KV 复用)的分布不一致问题。
| 改进 | 投机解码接受长度 | 增量 |
|---|---|---|
| Baseline(GLM-5.1 MTP) | 4.56 | — |
| + IndexShare + KVShare | 5.10 | +0.54 |
| + Rejection Sampling | 5.29 | +0.19 |
| + End-to-end TV Loss | 5.47 | +0.18 |
@tbl-indexshare-mtp MTP 消融:接受长度 4.56 → 5.47(+20%)
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 为什么需要 IndexShare | DSA indexer 每层 $O(L^2)$,200K 下占 prefill 81%,是主要瓶颈 |
| 为什么可以共享 | 相邻层 top-K 重叠 70-100%,残差增量的渐进变化不改变 token 相关度排序 |
| Indexer 算子实现 | Q 复用 MLA latent + 独立投影、K 走 MQA、ReLU 累加无 softmax、FP8 per-block + Walsh-Hadamard、精确 radix top-K |
| F/S 层机制 | 78 层 = 3 dense full + 18 MoE-F + 57 MoE-S;从 layer 4 起按 [S,S,S,F] 周期,F 在组末尾服务下游 3 S |
| F 层 cache 字节 | int32 索引、独立 contiguous buffer、与 seq 无关、1M/BS=8 持久 buffer 仅 1.34 MB |
| Prefill vs Decode | Prefill 一次性算、S 层同 step 复用;Decode F 层每步重算、节省在同 step 跨层 + key cache 扫读 |
| 部署路径 | Training-free 贪婪搜索或 Training-aware KL 蒸馏;GLM-5.2 选后者,128K mid-training 引入 |
| 2.9× 的正确解读 | per-token FLOPs 比,非延迟比;实测延迟最高点 200K/1.82×;r(L) 表是纯 attention FLOPs 比,与论文 wall-time 81% 因含/不含 FFN 而口径不同 |
| Batch/TP/PP 衰减 | Batch FLOPs 比不变(wall-time 工程推断略变);TP 跟随 head 切、可选 broadcast;PP 切点建议落在 3+4k 层后 |
| 与竞品本质差异 | 不改稀疏选择方式,只减 indexer 层数;唯一同时做到 token 级精细选择 + 跨层复用 + 轻量 indexer |
参考资料
- DeepSeek-AI, DeepSeek-V3.2 Technical Report, arXiv:2512.02556, 2025. https://arxiv.org/abs/2512.02556
- Z. Yang et al., IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse, arXiv:2603.12201, 2026. https://arxiv.org/abs/2603.12201
- HuggingFace GLM-5.2 config.json. https://huggingface.co/zai-org/GLM-5.2/blob/main/config.json
- L. Ericsson, DeepSeek Sparse Attention Implementation Notes, 2025-10. https://leonericsson.github.io/blog/2025-10-16-dsa
- SGLang DSA indexer implementation,
python/sglang/srt/layers/attention/dsa/dsa_indexer.pyandpython/sglang/srt/state_capturer/base.py, sgl-project/sglang. https://github.com/sgl-project/sglang - HuggingFace, GLM-5.2 Blog, 2026-06. https://huggingface.co/blog/zai-org/glm-52-blog
- LMSYS, SGLang HiSparse: Long-Context Inference, 2026-04. https://lmsys.org/blog/2026-04-10-sglang-hisparse/
- GLM-5 Technical Report, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
延伸阅读
- 08-动态稀疏选择 — DSA/NSA/MoBA 通用机制 SSOT
- 03-attention — GLM-5.2 MLA + DSA + IndexShare 三层注意力堆叠
- 06-inference — HiSparse 通信路径、TITO Gateway、国产卡适配
- ../02-DeepSeek-V4/03-attention — DSV4 CSA/HCA 序列压缩路线,与 IndexShare 的稀疏选择路线互补