推理部署
Effort Level + MTP 投机解码 + HiSparse/TITO/EP 通信路径 + 8 家国产卡 Day-0 适配,MIT 开源
核心要点:
- Effort Level:通过 Jinja2 chat template 注入
Reasoning Effort: Max/High标记;单 checkpoint 共享权重,模型训练中学会调整<think>深度- MTP n=7 是 linear chain(参数共享,1 个 MTP layer 复用 7 次),KVShare + IndexShare + 端到端 TV loss 让接受长度 4.56→5.47(+20%)
- HiSparse:GPU 热缓冲 + CPU pinned memory + DSA top-K 驱动 H2D swap;当前同步路径(async draft),throughput +3% 到 +192%
- TITO Gateway:训推跨集群协议,HTTP 轨迹 + NCCL/disk 权重同步 + Delta Weight Sync + consistent hashing DP-aware routing
- EP 通信:层数 80→GLM-5.2 的 78 / 75 MoE,hierarchical all-to-all intra/inter-node overlap,64 EP 单 forward 929 MB
- 国产卡三大技术断层:FP8 / FlashMLA 等价 / All-to-all——只有 3 家原生 FP8(昇腾、摩尔线程、平头哥真武)
- 定价 $1.40/$4.40:比 Claude Opus 4.8 / GPT-5.5 便宜 3.6-7×,比 DSV3.2 贵 5×
前置阅读
- GLM-5.2 完整配置 → 3.1 总览
- MTP IndexShare + KVShare 在注意力层的机制 → 3.2 IndexShare § MTP
- HiSparse 与 attention 计算的耦合(kernel 流) → 3.3 注意力架构 § HiSparse 与 attention 计算的耦合
- Slime RL 与 TITO 训推通信的全貌 → 3.5 Slime RL 训练 § TITO Gateway
Effort Level:System Prompt 注入式推理预算
GLM-5.2 借鉴 DSV4 的 reasoning_effort 机制,提供 High / Max 两档思考强度[1]。底层机制不是 sampling 参数差异、不是 checkpoint fork,而是通过 Jinja2 Chat Template 在请求预处理时向 system prompt 注入一行标记[2]:
Reasoning Effort: Max
或 High。模型在训练中学会根据该标记自主调整 <think> 链深度——不是显式 token budget 截断(区别于 Anthropic 的 budget_tokens 硬上限)。单 checkpoint,两档共享同一套权重。
API 暴露
| 引擎 | 字段路径 | 默认 |
|---|---|---|
| Z.ai 官方 API | 顶层 body reasoning_effort: "max" | "high" | Max |
| vLLM | extra_body={"chat_template_kwargs": {"reasoning_effort": "high"}} | Max |
| SGLang | chat template kwargs 同上 | Max |
| 关闭思考 | enable_thinking: false | — |
@tbl-glm52-effort-api Effort Level API 字段
任何非 "high" 的值都走 Max——这是默认偏激进的设计。
Token 消耗口径
HF blog 给的口径是 Max 比 High 多约 +55% output token[1];社区第三方 SDK 文档[3]观察到的 Max ~85k / High ~42k(对应 +100%)与 HF blog 数字不一致——可能因 benchmark 平均口径不同。本节诚实标注两个公开口径,未做单点裁定。
与业界对应物对比
| 模型 | 档位数 | 控制方式 |
|---|---|---|
| OpenAI o-series | 3 (low / medium / high) | 隐式 token budget |
| GLM-5.2 | 2 (High / Max) | System prompt 注入 + 训练学会自调 |
| Anthropic Claude extended thinking | 连续值 | budget_tokens: int 显式硬上限 |
@tbl-effort-vs-industry Effort 控制谱
GLM-5.2 介于两端——比 OpenAI 少一档(无 Low,但 enable_thinking: false 承担"零思考"角色),比 Anthropic 粗(无精细数值预算)。
MTP 投机解码完整协议
GLM-5.2 的 MTP(Multi-Token Prediction)是投机解码(speculative decoding)的 draft model。下面把 head 结构、draft + verify 流、rejection sampling 协议挖到完整[1]。
Head 结构:1 layer 共享,7 步 sequential
GLM-5.2 的 MTP 直接沿用 DSV3 的 sequential 模板():每一步是一个独立 module("MTP Module 1/2/..."),输入是上一步预测的 token + 主模型 embedding,输出经独立 Cross-Entropy 训练。GLM-5.2 把 module 数压到 1 通过参数共享展开 7 次。
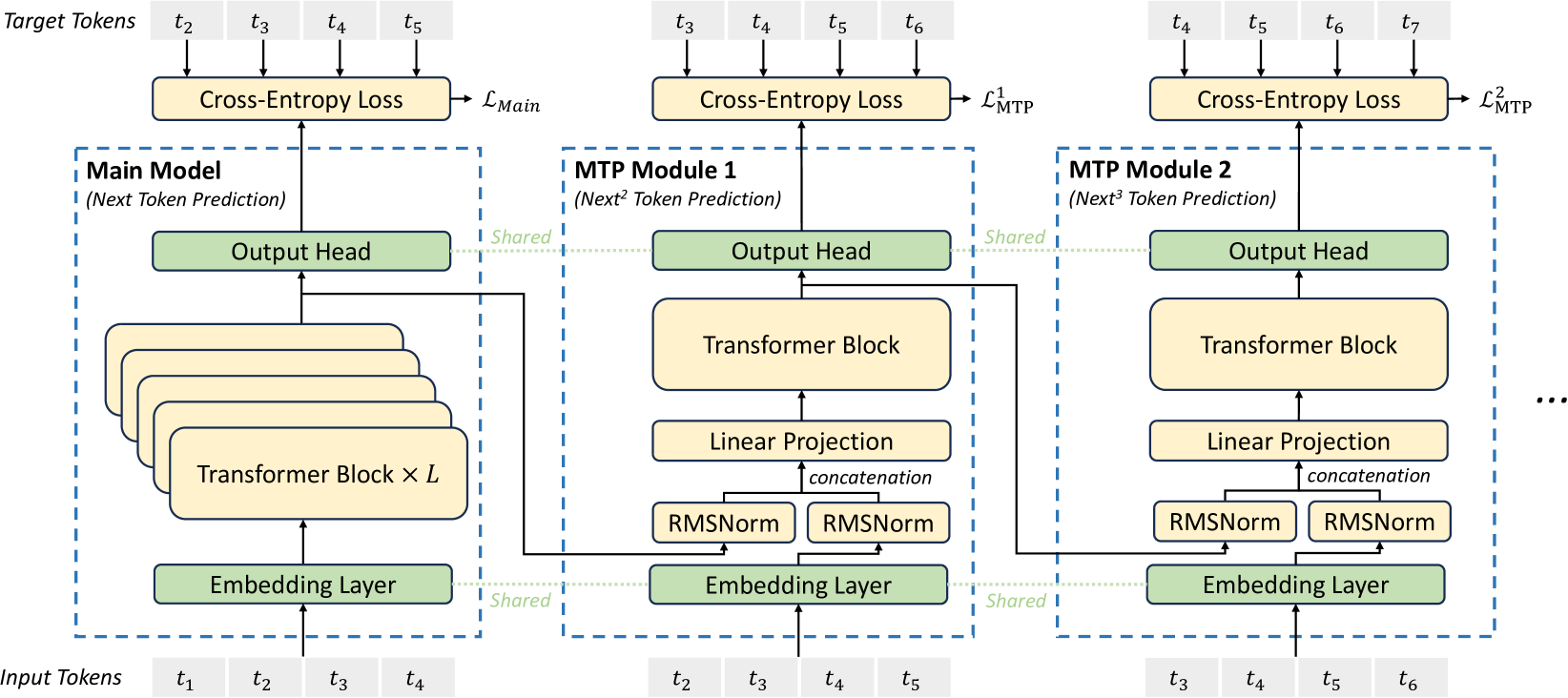
mtp_layers=1,但通过参数共享 + 7 步 sequential 展开实现 $n=7$ 预测:
- 单套 MTP transformer 层权重被复用 7 次,内存等同 1 层
- 拓扑是 linear chain(每步 top-k=1),不是 balanced binary tree
- 前一步的 draft token embedding 与主模型 hidden state 拼接后送入下一步
Draft + Verify 算子流
Draft 阶段(生成 7 个候选 token):
- 主模型先跑一次 forward,得到 hidden state $h$ 与首 token
- 把 $h$ 与上一步 draft token embedding 拼接 → 送入 MTP layer
- 复用主模型的 FlashMLA / DSA kernel(不为 MTP 单独维护 kernel)
- KVShare:所有 7 步 draft 只使用主模型的 KV cache,不为 MTP 单独维护 KV——消除 GLM-5.1 训推 KV 分布漂移
- IndexShare on MTP:7 步中只在 step 1 算 top-K=2048 索引,后续 6 步复用(HF config
index_share_for_mtp_iteration: true[4])
Verify 阶段:7 个 draft token 拼入序列,主模型做单次 prefill-style forward,输出每位置的 target logits $p_{\text{target}}$。同步算 draft logits $p_{\text{draft}}$(draft 阶段已记录)。
Rejection Sampling 协议
标准协议(Leviathan 2022[5]):
$$\begin{equation} \alpha_i = \min\!\left(1, \frac{p_{\text{target}}(x_i)}{p_{\text{draft}}(x_i)}\right) \label{eq:mtp-accept-prob} \end{equation}$$接受时保留 $x_i$;拒绝时从归一化余分布 $\text{normalize}(\max(0,\, p_{\text{target}} - p_{\text{draft}}))$ 重采样。
端到端 TV loss:GLM-5.2 的核心创新
接受率 $\alpha$ 与 draft / target 的 Total Variation 距离有直接关系:
$$\begin{equation} \mathbb{E}[\alpha] = 1 - \mathrm{TV}(p_{\text{target}},\, p_{\text{draft}}) \label{eq:mtp-tv-accept} \end{equation}$$GLM-5.2 直接用 TV 距离作为 MTP 训练 loss[1]——最小化 TV 等价于最大化期望接受率,比 KL 散度的代理更直接、对小 draft head 更优。
接受长度消融
| 改进 | 接受长度 | 增量 |
|---|---|---|
| Baseline (GLM-5.1 MTP) | 4.56 | — |
| + IndexShare + KVShare | 5.10 | +0.54 |
| + Rejection Sampling 改进 | 5.29 | +0.19 |
| + 端到端 TV Loss | 5.47 | +0.18 |
@tbl-mtp-ablation MTP 改进消融(GLM-5.2,coding 任务)
总计接受长度 +20%,对应 throughput ≈ 1.5-2× 提升[1]。
$n$ 训练 vs 部署的差异:模型训练支持的预测步数 $n=7$(HF config),但 vLLM/SGLang 部署 recipes 默认推荐 num_speculative_tokens=5——部署时按显存 / kernel launch 开销折中,常用比训练上限略小的步数以避免长链 reject 后浪费 verify 算力。两者不矛盾,是不同层面(模型能力 vs 部署默认)。
与 EAGLE / Medusa 对比
| 维度 | GLM-5.2 MTP | EAGLE | Medusa |
|---|---|---|---|
| Head 结构 | 1 layer × 7 步共享 (sequential chain) | feature-level autoregressive | 多 MTP head 并行 |
| 独立 KV cache | 无(KVShare) | 有 | 无 attention |
| 索引 / 路由复用 | IndexShare(仅 step 1) | 无 | 不适用 |
| 训练 loss | TV loss 直接优化 $\alpha$ | feature MSE | cross-entropy |
| Draft 接受长度 | 5.47 (coding) | 5-7(benchmark 不同) | ~3-5 |
@tbl-mtp-vs-spec-decoding MTP 与主流投机解码对比
GLM-5.2 的优势:KVShare 零额外 KV 开销 + TV loss 直接优化接受率 + 原生集成主模型 checkpoint。
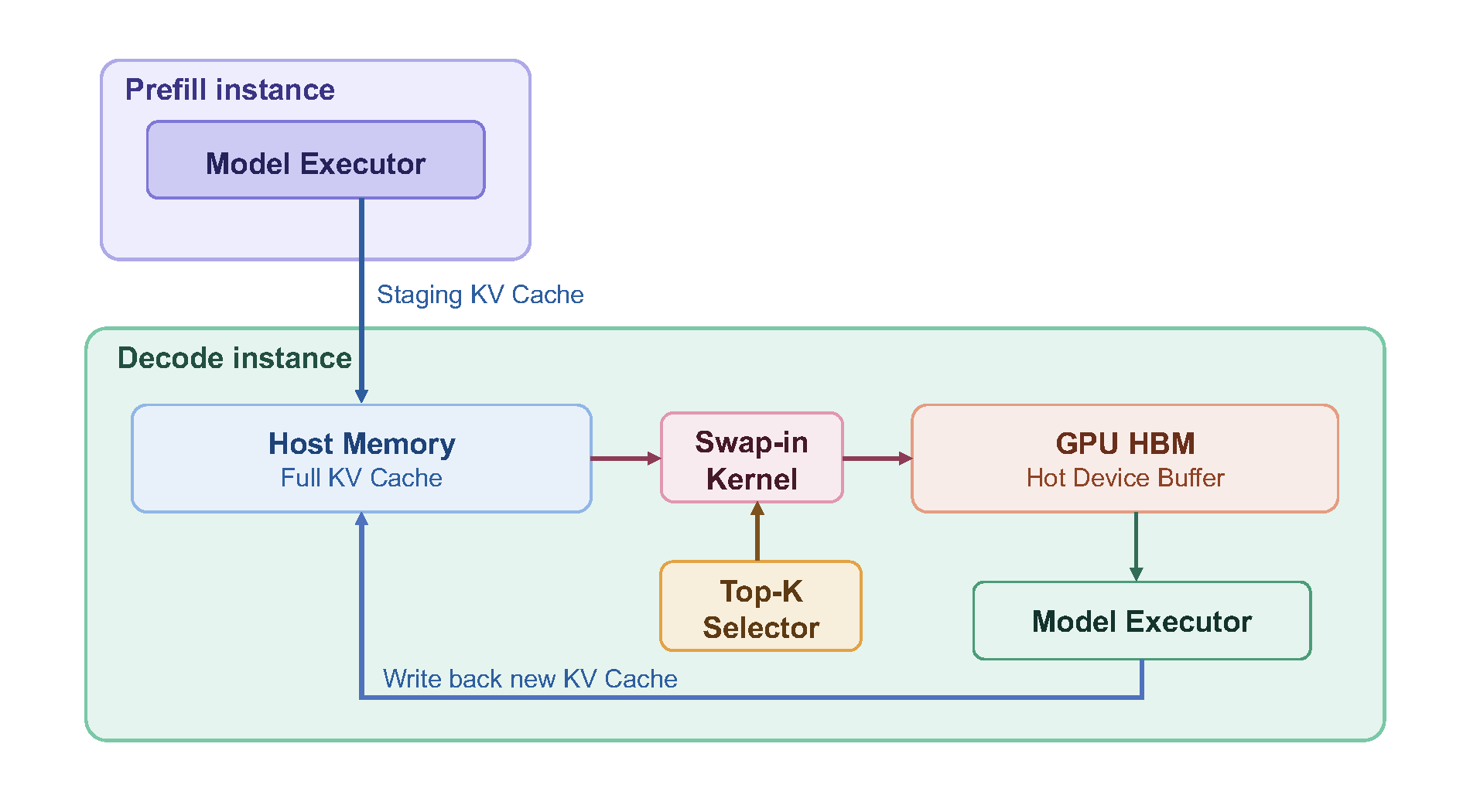
HiSparse 的通信路径:GPU↔CPU KV swap
1M 上下文下,即便经过 MLA + KV FP8 压缩,78 层的 KV cache 总量仍远超单卡显存。HiSparse 的解法是把 KV cache 分层存储——GPU HBM 上只保留近期高频访问的"热"槽位,完整 KV 放在 CPU pinned memory[6]。
数据通路
HiSparse 的 swap-in kernel 工作流程[6]:
- Top-K cache miss 检测:DSA indexer 算出本 step 的 top-K 索引后,比对设备 buffer,找出未命中的位置
- LRU 淘汰:从设备 buffer 中选淘汰候选(LRU 策略)
- H2D 拉取:更新 page table,从 host memory 异步 DMA 拉取所需 KV 条目到 device
关键参数:device_buffer_size 在 4096-6144 slot 区间(slot = KV page,page size 16 token);host_to_device_ratio(host 存储量 / device buffer)= 8-10。整套数据通路如 。
传输协议与带宽口径
HiSparse 的 H2D 路径走 pinned memory + cudaMemcpyAsync 而非 Unified Memory[工程推断]——UM 的隐式 page fault 不适合推理关键路径。带宽实际可用范围由 host-device 链路决定(PCIe Gen4 ~32 GB/s 或 Gen5 ~64 GB/s 单向,NVLink-C2C 视 SKU 而定),官方未给具体带宽数字。
性能口径
HiSparse 在 32K-1024K request length 上对 GLM-5.1 的 throughput 提升 3× - 5×[6]——上限发生在最长 context、最严显存压力下;短 context 收益小(接近 1×)。这是 HiSparse 的设计特征:解决"放不下",不是"算得快"。
与 attention 计算耦合细节、slot=page 单位、搬的是 latent 而非上投影详见 03-attention § HiSparse 与 attention 计算的耦合。
TITO Gateway:训推协同的通信协议
GLM-5.2 沿用 GLM-5 引入的 TITO(Token-In Token-Out)Gateway[7],是 Slime RL 框架中跨集群通信的核心。"TITO" 一词指训练管线消费的 token 流与推理引擎产出的 token 流逐字节对齐——避免重新 tokenize 引起的训练-推理分布漂移。
通信拓扑
Slime 把推理(SGLang)和训练(Megatron)放在不同 GPU 集群(disaggregated 模式),靠 TITO Gateway 协调:
| 数据 | 协议 | 频率 |
|---|---|---|
| 轨迹(token IDs + log-prob metadata) | HTTP API[8] | 每个 rollout episode |
| 权重同步(colocated) | NCCL UpdateWeightFromTensor | RL 训练每轮 |
| 权重同步(disaggregated) | NCCL 直连 / disk checkpoint 热加载 / Delta Weight Sync | RL 训练每轮 |
@tbl-tito-channels TITO Gateway 通信通道
Delta Weight Sync 是 GLM-5 的工程优化——大模型全量权重同步带宽开销大,只传字节级 diff(详见 05-training § Weight Sync 4 路径)。
DP-Aware Routing
TITO Gateway 用 consistent hashing 把同一 agent instance 的所有请求路由到同一 DP rank[7],最大化 KV cache locality——RL 多步对话中后续 step 复用前面 step 的 KV,避免跨 rank 重算或拉取。这是 RL agent 场景下的特化优化,常规 inference 不需要。
GLM-5.2 的 delta
公开资料未见 GLM-5.2 在 TITO 协议层面相对 GLM-5 有新改动。沿用 [7]。
EP all-to-all:层数缩减 + Hierarchical 通信
GLM-5.2 的 MoE 部分依赖 EP(Expert Parallelism)做 token-to-expert 路由的跨卡分发,每 MoE 层两次 all-to-all(dispatch + combine)。GLM-5 引入了两项 EP 通信优化,GLM-5.2 沿用[7]:
层数选择
GLM-5 把层数从 GLM-4.5 的 128 降到 80,GLM-5.2 进一步到 78(含 3 dense + 75 MoE)[4]。明确为了"minimize expert parallelism communication overhead"[7]——all-to-all 次数 ∝ MoE 层数。
Hierarchical All-to-All
GLM-5 训练栈对 long-context QKV tensor 通信使用 hierarchical all-to-all,显式拆分 intra-node(NVLink)和 inter-node(RDMA/IB)两层做 overlap[7]。这与业界 MegaScale 风格类似。
MoE token dispatch 是否也走分层 all-to-all 公开资料未明说——[工程推断] 大概率是,但无 verbatim 支撑。
通信量公式与算例
EP 通信公式与 64 EP / 929 MB / forward 算例(仅 attention all-reduce 的 13%)详见 04-moe § EP 通信成本建模。
TBO overlap 在 S 层失效
SGLang 的 Two-Batch Overlap 把 attention 与 EP all-to-all 重叠,但 IndexShare S 层 attention FLOPs 降至正常 0.2%——TBO 重叠条件不成立,EP 通信会裸露在 critical path 上(详见 04-moe § TBO overlap 在 S 层失效)。
vLLM / SGLang 部署配方
GLM-5.2 在 vLLM 和 SGLang 上有官方 recipes[2],关键 launch flag 整理如下。
完整 flag 矩阵
| Flag | vLLM | SGLang | 典型值 |
|---|---|---|---|
| 张量并行 | --tensor-parallel-size | --tp | 8 |
| 流水并行 | --pipeline-parallel-size | --pp-size | 2(多节点) |
| Expert 并行 | --enable-expert-parallel | --ep | flag / 4 |
| 数据并行 | --data-parallel-size | --dp | 2 |
| KV cache 精度 | --kv-cache-dtype fp8_e4m3 | 自动(Blackwell fp8 / Hopper bf16) | fp8_e4m3 |
| 最大长度 | --max-model-len | — | 262144 ~ 1048576 |
| 并发请求 | --max-num-seqs | --max-running-requests | 32-48 |
| Chunked prefill | --enable-chunked-prefill --chunked-prefill-size | 同 | 32768(与 HiSparse page 对齐) |
| MTP 投机解码 | --speculative-config.method=mtp --num_speculative_tokens N | --speculative-algorithm EAGLE --speculative-num-steps N | N=5 推荐 |
| TBO / DBO | --enable-dbo | --enable-two-batch-overlap | flag |
| HiSparse | — | --enable-hisparse --hisparse-config '{...}' | — |
| EP all-to-all 后端 | --all2all-backend deepep_* | --moe-a2a-backend deepep | deepep |
| DP attention | — | --enable-dp-attention | flag |
| Prefix cache | --enable-prefix-caching | 默认开 | flag |
| Reasoning parser | --reasoning-parser glm45 | — | glm45 |
| Tool call parser | --tool-call-parser glm47 | — | glm47 |
@tbl-glm52-launch-flags vLLM / SGLang 部署 flag 完整清单
硬件门槛与配置模板
| 配置 | 硬件 | 上下文上限 | 备注 |
|---|---|---|---|
| 标准 | 8 × H200 (640 GB HBM) | 256K | FP8 权重 744 GB > 640 GB,须 HiSparse offload |
| 1M context | 8 × B200 (1536 GB) 或 16 × H200 + HiSparse | 1M | 1M 显存压力主导 |
| CloudMatrix 384 | 384 × Ascend NPU | 128K(当前验证) | vllm-ascend 路径 |
@tbl-glm52-hardware GLM-5.2 部署硬件门槛
关键约束:FP8 权重就 744 GB——8 × H200 装不下完整权重 + KV cache,必须借 HiSparse 把冷 KV 推到 CPU。
Chunked prefill 与 HiSparse 对齐
chunked-prefill-size 推荐 32768 token——这与 HiSparse 的 page size 16 对齐(32768 / 16 = 2048 pages/chunk,便于 swap-in batch 化)[2]。
国产卡 Day-0 适配:三大技术断层
GLM-5.2 发布当日完成 8 家国产卡推理适配(比 GLM-5 多 1 家,新增平头哥真武 PPU)。但适配深度差异巨大——关键短板集中在三个技术点[9]:
8 家芯片关键能力矩阵
| 厂商 | 卡型 | Collective | FP8 原生 | FlashMLA 等价 | SGLang 主线 |
|---|---|---|---|---|---|
| 华为 Ascend | 910B / 950 | HCCL (EP320 验证) | ✅ Cube Unit | ✅ AMLA (86.8% FLOPS) | ✅ |
| 摩尔线程 | MTT S5000 | MCCL | ✅ 首批国产原生 | ✅ MATE | ✅ (2026-05 入主线) |
| 平头哥真武 | PPU 810E | DeepEP (MoE 专用) | ✅ (DeepEP 量化路径) | 未公开 | ✅ (0.5.12) |
| 沐曦 | C500 | MCCL (EP144) | ❌ BF16 | ✅ MetaX-MACA/FlashMLA (Gitee) | ✅ (0.5.4) |
| 海光 | DCU K100 / Z100 | RCCL (DTK ≥24.04) | ❌ BF16 | 未公开 | 未公开 |
| 寒武纪 | MLU 590 / 690 | CNCL(AllToAll 未公开) | ⚠ 探索阶段 | 未公开 | 未公开 |
| 昆仑芯 | XPU P800 | BKCL(AllToAll 未公开) | ❌ BF16 | 未公开 | ✅ |
| 壁仞 | BR166 | BRCCL(AllToAll 未公开) | ❌ BF16 | 未公开 | ✅ |
@tbl-glm52-domestic-chips GLM-5.2 国产卡 Day-0 适配能力矩阵
三大技术断层
- FP8 原生:只有 3 家——昇腾、摩尔线程、平头哥。其余 5 家须以 BF16 跑,FP8 权重 744 GB → BF16 需 1.5 TB 显存,集群规模压力翻倍
- FlashMLA 等价:只有华为 AMLA 和沐曦 MetaX 公开,其余 6 家"未公开",DSA 稀疏注意力性能损失未知
- All-to-All:华为 HCCL(EP320 验证)、沐曦 MCCL(EP144)、海光 RCCL、平头哥 DeepEP 已公开支持;寒武纪 / 昆仑芯 / 壁仞 / 摩尔线程的 AllToAll 公开资料无法确认
华为 CloudMatrix 384
华为 Day-0 适配方案的旗舰是 CloudMatrix 384 超节点(详见 arXiv:2506.12708[9]):
| 维度 | CloudMatrix 384 | NVL72 |
|---|---|---|
| 规模 | 384 NPU/Pod | 72 GPU/rack |
| Scale-out 带宽 | 25 GB/s/die | ~5.5 GB/s/die |
| Scale-up 带宽 | 392 GB/s | 1800 GB/s |
| 功耗比 | 4.1× | — |
@tbl-cm384-vs-nvl72 CloudMatrix 384 vs NVL72
优势:scale-out 带宽 4.5× NVL72,适合大 EP(EP320 已论文验证)
代价:scale-up 带宽仅 NVL72 的 22%,功耗 4.1×
对 GLM-5.2 意义:78 层 + 256 expert 配 CloudMatrix 384 的 EP320 通信优势契合度高,但单 NPU 算力密度被 scale-up 带宽拖累,需要 hierarchical all-to-all 弥补
当前没填的空格
寒武纪 / 海光 / 平头哥 FlashMLA 等价、昆仑芯 / 壁仞 / 摩尔线程 AllToAll 实测——这片数据空白让"8 家全适配"的实际生产可用性仍有不确定性。
业界定价对比
GLM-5.2 官方价 $1.40 / $4.40 per M tokens(输入 / 输出,比 3.14×)[10]。其他模型价格来自第三方汇总(DeepSeek 官方 API / OpenAI 官方价 / Anthropic 官方价;GLM-5.2 第三方价来自 OpenRouter / GMI / Fireworks)[11]:
| 模型 | 输入 $/M | 输出 $/M | 输入/输出比 | 上下文 | 相对 GLM-5.2 |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | $0.14 | $0.28 | 2.0× | 64K | 10× 便宜 |
| DeepSeek V3.2 | $0.28 | $0.42 | 1.5× | 64K | 5× 便宜 |
| DeepSeek V4 | $0.30 | $0.50 | 1.7× | 128K | 4.7× 便宜 |
| GLM-5.2 (Z.ai) | $1.40 | $4.40 | 3.14× | 1M | 基准 |
| GLM-5.2 (GMI FP8) | $1.12 | $3.52 | 3.14× | 1M | 0.8× |
| Claude Opus 4.8 | $5.00 | $25.00 | 5.0× | 200K | 3.6× 贵 |
| GPT-5.5 | $5.00 | $30.00 | 6.0× | 128K | 3.6× 贵 |
@tbl-glm52-pricing 业界推理定价对比
两端定位:比闭源旗舰(Claude / GPT)便宜 ~3.6×(按输入价),比 DeepSeek 系列贵 5× 输入 / 10× 输出——GLM-5.2 的输入/输出比 3.14× 也高于 DSV3.2 的 1.5×,对长输出场景成本压力更明显。GLM-5.2 占的是"开源 + 1M context + 工程可靠"的中间档。
缓存优化:GLM-5.2 缓存输入 $0.26/M,约为标准输入价的 18.6%——多轮 agent 场景下成本进一步降低。
开源生态
- 协议:MIT License,无区域限制,可商用、修改、分发
- 权重:HuggingFace(
zai-org/GLM-5.2)+ ModelScope 同步开源 - 推理框架:SGLang 原生(HiSparse + DSA backend)、vLLM 原生、Slime RL 内置 SGLang rollout
- 第三方提供商:Together / Fireworks / GMI / OpenRouter 等,价差最高 1.8×
开放问题
- GLM-5.2 是否会出 thinking_budget 数值精细预算(向 Anthropic 风格靠近)
- 国产卡 5 家未公开 FP8 / FlashMLA / AllToAll 的实测性能
- HiSparse async IO overlap 何时合入主线
- CloudMatrix 384 对 1M context 的实际部署口径
Takeaway
| 知识点 | 核心结论 |
|---|---|
| Effort Level 机制 | System prompt 注入(Reasoning Effort: Max|High),单 checkpoint 共享权重 |
| Effort API | Z.ai 顶层 reasoning_effort;vLLM extra_body.chat_template_kwargs;默认 Max |
| MTP head 结构 | 1 layer 共享,7 步 sequential linear chain,参数复用 |
| MTP draft KV | KVShare:使用主模型 KV cache,零额外开销;消除 GLM-5.1 训推漂移 |
| MTP loss | 端到端 TV loss 直接优化 $\mathbb{E}[\alpha] = 1 - \mathrm{TV}$,比 KL 代理优 |
| MTP 接受长度 | 4.56 → 5.47 (+20%),对应 throughput 1.5-2× |
| 部署 launch flag | 17+ 关键 flag 矩阵;HiSparse / TBO / EP / chunked prefill 是 1M 部署四件套 |
| 硬件门槛 | 8 × H200 须 HiSparse offload;1M context 需 8 × B200 或 16 × H200 |
| 国产卡三大断层 | FP8 / FlashMLA 等价 / AllToAll——只有 3 家原生 FP8(华为 / 摩尔线程 / 平头哥) |
| CloudMatrix 384 | scale-out 带宽 4.5× NVL72,scale-up 仅 22%,功耗 4.1× |
| 定价 | $1.40/$4.40,输入价比 Claude/GPT 便宜 ~3.6× / 比 DSV3.2 贵 5×;输出价贵 DSV3.2 10×;缓存输入 18.6% |
参考资料
- HuggingFace, GLM-5.2 Blog, 2026-06. https://huggingface.co/blog/zai-org/glm-52-blog
- vLLM Recipes: GLM-5.2 Deployment. https://recipes.vllm.ai/zai-org/GLM-5.2
- DataCamp, Hands-on Guide to GLM-5.2, 2026. https://www.datacamp.com/blog/glm-5-2
- HuggingFace GLM-5.2 config.json. https://huggingface.co/zai-org/GLM-5.2/blob/main/config.json
- Leviathan et al., Fast Inference from Transformers via Speculative Decoding, arXiv:2211.17192, 2022. https://arxiv.org/abs/2211.17192
- LMSYS, SGLang HiSparse: Long-Context Inference, 2026-04. https://lmsys.org/blog/2026-04-10-sglang-hisparse/
- GLM-5: from Vibe Coding to Agentic Engineering, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
- Slime RL Documentation. https://thudm.github.io/slime/
- Huawei CloudMatrix384: Serving Large Language Models, arXiv:2506.12708, 2025. https://arxiv.org/abs/2506.12708
- Z.ai API Documentation. https://docs.z.ai/guides/llm/glm-5.2
- 价格汇总:DeepSeek API (https://api-docs.deepseek.com/quick_start/pricing)、OpenAI Pricing (https://openai.com/api/pricing/)、Anthropic Pricing (https://www.anthropic.com/pricing)、OpenRouter Models (https://openrouter.ai/models),2026-06 抓取。
延伸阅读
- 3.2 IndexShare — IndexShare F/S 机制 + MTP IndexShare 用法
- 3.3 注意力架构 — MLA Absorb 路径 + HiSparse 与 attention 的耦合
- 3.4 MoE 路由 — EP all-to-all 通信成本建模 + TBO overlap 失效
- 3.5 Slime RL 训练 — Slime RL + TITO Gateway 训推协议全貌