Slime RL 训练
Muon 预训练 + Slime 异步解耦 RL + GRPO+IcePop 硬门控 + OPD 双 teacher 蒸馏
核心要点:
- 预训练优化器:Muon + Muon Split(按 head 切分正交化 MLA 矩阵),非 AdamW;仅 Embedding/Bias/RMSNorm 走 AdamW
- 训练集群:GLM-5 预训练 100K × 昇腾 910B + MindSpore;RL 后训练 256 × H100
- Slime 异步解耦:SGLang rollout + Megatron 训练完全异步;Data Buffer 是 GRPO group 化的 dict-of-list;Weight Sync 4 条路径
- RL 算法是 GRPO + IcePop:超出 $[1/\beta, \beta]=[0.5, 2]$ 的 importance ratio token 梯度硬置零;KL 系数 = 0
- OPD 有两种公式形式:KL penalty (Slime docs) vs log-ratio 直接替换 advantage (GLM-5 paper),数学目标相近但实现不同
- Reward 全程二值 ORM:math/code/SWE-bench 都用 binary pass/fail,无 PRM、无 partial credit
- Tool 接口走 ToRA 风格:4 个 special token(system/user/assistant/observation),Python fenced code block 表 tool call
前置阅读
- GLM-5.2 完整配置 → 3.1 总览
- TITO Gateway 通信路径(HTTP 轨迹 + NCCL 权重 + Delta Sync) → 06-inference § TITO Gateway
- DeepSeek V4 训练对比(Muon + OPD) → ../02-DeepSeek-V4/05-training
Slime RL 为什么不是又一个 PPO 变种?
PPO、GRPO、REINFORCE 等主流 RL 训练框架共享一个前提:推理(rollout)和训练(policy update)在同一组 GPU 上交替执行。Rollout 生成一批轨迹 → 训练消费这批轨迹更新参数 → 再 rollout 下一批。GPU 在 rollout 等训练、训练等 rollout 的交替中空转。
Slime 把这个前提拆了[^slime-doc]。它把系统分成三个独立模块,部署在不同 GPU 上:
| 模块 | 引擎 | 职责 |
|---|---|---|
| Rollout 引擎 | SGLang + Router | 用当前 policy 生成轨迹、跑 reward/verifier、写入 Data Buffer |
| 训练引擎 | Megatron | 从 Data Buffer 读数据、执行梯度更新、同步参数到 Rollout 引擎 |
| Data Buffer | 桥接层 | 管理 prompt 初始化、轨迹收集、group ready 触发 |
@tbl-glm52-slime-arch Slime 三大模块
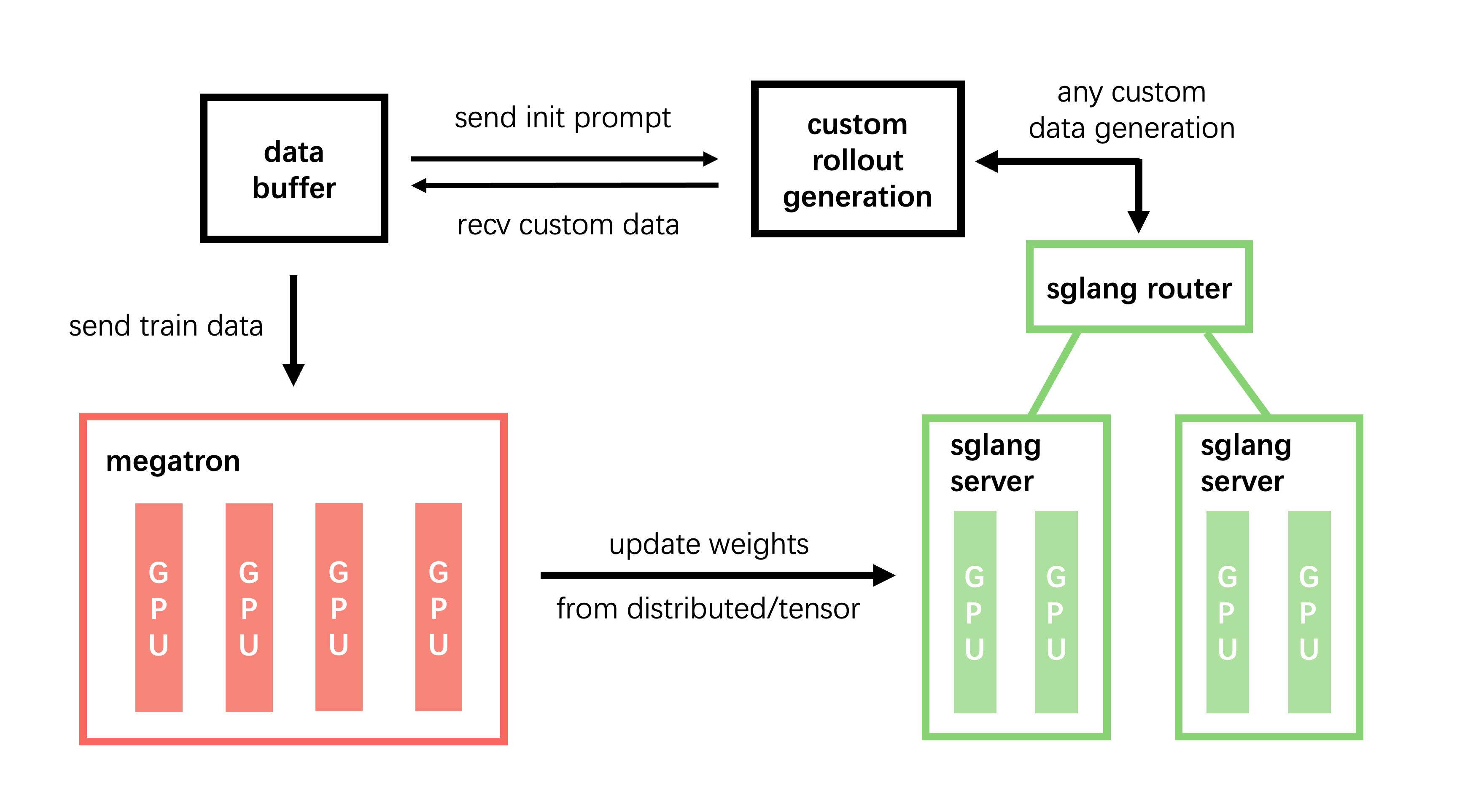
Rollout 和训练完全异步:训练引擎不等待当前 batch 的 rollout 完成——消费 Data Buffer 中已就绪 group。Rollout 引擎不等待训练——用最新可用参数生成新轨迹。两条流水线各自满负荷。
为什么对 Agentic RL 特别重要:Agentic 任务的 rollout 涉及 tool use、sandbox 执行、多步环境交互——单次 rollout 可能耗时数秒到数十秒,远长于一次梯度更新。同步模式下 GPU 在等沙盒;Slime 异步模式下训练 GPU 同时消费前一 batch 数据,不等沙盒。
Slime 内部数据流:Data Buffer 与 Weight Sync 协议
之前一句"Data Buffer 桥接层"太虚——实际数据流是源码级的协议设计[^slime-code]。
Data Buffer 数据结构
不是 ring buffer,是以 instance_id(prompt 唯一标识)为 key 的 dict-of-list[^slime-code]:
# 简化形式
buffer: Dict[instance_id, List[Sample]]
group_size = num_repeat_per_sample(即 GRPO 的 group 大小 $G$)决定一个 group 何时 ready——同一 prompt 的 $G$ 条 trajectory 集齐才能进入训练。
Buffer 是 on-policy 一次性消费,不存历史 trajectory,不做 replay——这是 GRPO 的 on-policy 特性决定,与 PPO 的 replay buffer 完全不同。多任务靠 /start_rollout HTTP endpoint 重建 buffer 实例,每次只服务一个 task_type。
Trajectory schema
每条 trajectory 由 Sample dataclass 表达(20+ 字段)[^slime-code]:
| 字段 | 类型 | 说明 |
|---|---|---|
tokens | List[int] | 完整 prompt + response token IDs |
loss_mask | List[int] | 只对 model-generated 部分计算 loss(observation token 掩掉) |
rollout_log_probs | List[float32] | rollout 时记录的 $\pi_{\text{rollout}}$ log-prob,FP32 |
reward | float | outcome reward |
session_id | str | 多轮 agent 同一 session 的标识 |
| ... | ... | 其余 metadata |
多轮 agent trajectory 由 TrajectoryManager 维护 per-session MessageNode 树,fork-on-drift 机制容忍 TITO 重 tokenize 时的细微漂移(重 tokenize 与原 token IDs 不完全一致时 fork 出新分支,不污染主路)。
Weight Sync 的 4 条路径
| 路径 | 协议 | 适用 |
|---|---|---|
| Colocated CUDA IPC | FlattenedTensorBucket 序列化 → Gloo gather → Ray IPC 零拷贝 | 训练+推理共享 GPU,零网络开销 |
| Disaggregated NCCL | 每 PP stage 一个独立 NCCL 组 (slime-pp_{pp_rank}),rank 0 broadcast | 跨 GPU 池,全量权重 |
| Disaggregated Disk | 训练写 safetensors 到共享 FS → SGLang update_weights_from_disk 热加载 | 跨 DC / 网络极差 |
| Delta Weight Sync | bytewise diff(视图转整数 != 比较),3 种编码:int32 绝对位置 / uint16 gap-delta / zstd 压缩 | 大模型同步带宽优化,与上面任一路径组合 |
@tbl-glm52-weight-sync Weight Sync 四条路径
Delta 的关键性质:接收端直接原地覆盖字节——无浮点反量化、无累积舍入误差。这保证训推 model state 字节级一致,避免 RL 中"训推不同步导致 importance ratio 偏差"的 silent failure。
编排:Ray Actor + SGLang Router
Orchestrator 不是微服务 / Kubernetes,是 Ray Actor 模型[^slime-code]:
ServerGroup按 RayPlacementGroup绑定 GPU 资源,支持异构 TP(prefill / decode 不同 TP size)- SGLang Router 做前端 HTTP load balancing;DP-aware 路由用
Sample.session_id做 consistent hashing key(同一 session 的所有 step 路由到同一 DP rank,最大化 KV cache locality) - Slime 禁用 Router 自带的 circuit breaker 和 health check,统一由
RolloutHealthMonitor后台线程管:rollout_health_check_interval轮询,失败后ray.kill(engine)置 None
DP 调度策略
DP(数据并行)的 sample 分配走 pack-first 后 distribute-second[^slime-code]:
- Pack:first-fit 或 FLOPs 均衡,把 sample 装进固定 token 容量的"包"
- Distribute:strided round-robin 或 KK 算法,把包均衡分到各 DP rank
这两步组合保证每个 DP rank 的 FLOPs 负载接近一致,是 batch 内长度差异大(agent 轨迹长短不一)时避免 straggler 的关键。
TITO Gateway:异步偏移的校正信号
异步解耦引入了一个新问题:rollout 时的 policy($\pi_{\text{rollout}}$)和训练时的 policy($\pi_{\text{train}}$)之间差了若干步梯度更新。off-policy 修正需要重要性采样比:
$$\begin{equation} \rho_{i,t} = \frac{\pi_{\text{train}}(a_t | s_t)}{\pi_{\text{rollout}}(a_t | s_t)} \label{eq:slime-is-ratio} \end{equation}$$但这个比值需要 $\pi_{\text{rollout}}$ 的 log-prob——传统 RL 框架通常通过"保存旧模型快照再算 log-prob"获取(PPO 的 $\pi_{\text{old}}$),额外消耗显存和计算。
TITO Gateway(Token-In Token-Out)的解法[^glm5-report]:在 SGLang rollout 阶段直接截获每个生成 token 的 log-prob,与 token ID 一起写入 Data Buffer 的 rollout_log_probs 字段(FP32)。训练时无需重算 $\pi_{\text{rollout}}$。
通信路径(HTTP API 轨迹流 + NCCL 权重同步 + Delta Sync)在 06-inference § TITO Gateway 已写,本文不重复。
四阶段 RL 管线怎么推进?
GLM-5 的后训练走四个阶段[^glm5-report],GLM-5.2 沿用此管线:
| 阶段 | 训练内容 | 关键设计 |
|---|---|---|
| Stage 1 SFT | 基础行为先验 | Interleaved Thinking(tool call 前打草稿)+ Preserved Thinking(多轮保 <think> blocks) |
| Stage 2 Reasoning RL | 数学、科学、代码推理 | GRPO + IcePop(见下节),verifier 打分 |
| Stage 3 Agentic RL | SWE 任务、终端操作、多步搜索 | 同 GRPO+IcePop 框架;observation token loss masked;Docker sandbox |
| Stage 4 General RL | 教学正确性、对话质量 | 混合 rule-based + ORM + GRM (LLM-as-judge);三维优化(基础正确性 / 情感智能 / 任务质量) |
@tbl-glm52-four-stage 四阶段 RL 管线(GLM-5.2 沿用)
GRPO + IcePop:硬门控替代软 clip
之前文档说"Slime 不是又一个 PPO 变种"——具体算法在 GLM-5 报告里有完整描述[^glm5-report]:GRPO + IcePop。
基础 GRPO 框架
- Advantage 是纯 Monte Carlo outcome + 组内均值归一化,无 value network、无 GAE:
- Group size $G = 32$(DSV3 的 R1 用 64,GLM-5 选更小)
- KL 正则系数 = 0——divergence 控制完全靠 IcePop 门控,不靠 soft KL constraint
IcePop pop() 硬门控
IcePop 的核心操作 pop(ρ):对每个 token 的 importance ratio $\rho_{i,t}$,超出阈值范围直接置零梯度:
即 $\rho < 0.5$ 或 $\rho > 2$ 的 token 不参与梯度。这比 PPO 的 clip 到边界更激进——对分布偏移过大的 token,宁可丢弃信号也不冒险用偏差大的修正。
非对称 clip
剩余 token 仍走 PPO 风格 clip,但 clip 区间非对称:$\epsilon_{\text{low}} = 0.2$, $\epsilon_{\text{high}} = 0.28$[^glm5-report]。高侧放宽是为了让 reward 高的 token(advantage 正)能获得足够梯度推动;低侧保持紧以防过度抑制 reward 低 token 的合理探索。
总损失
每 token 的 policy gradient 损失:
$$\begin{equation} \mathcal{L}_{\text{policy}} = -\mathbb{E}\Big[\mathrm{pop}(\rho_{i,t}) \cdot \mathrm{clip}\big(\rho_{i,t},\, 1-\epsilon_{\text{low}},\, 1+\epsilon_{\text{high}}\big) \cdot A_{i,t}\Big] \label{eq:icepop-loss} \end{equation}$$KL 项不出现(系数 0)。这套设计在 GRPO + 异步 rollout 下经验上比标准 PPO clip 更稳。
TIR:Tool-Integrated Reasoning 的接口
TIR 路线由 ToRA 论文[^tora-paper](Tsinghua + Microsoft Research,2023——清华 Yang Yujiu / Huang Minlie 组,非 THUDM/Tang Jie 组)首次提出,GLM-5/5.2 在此基础上实现 agent 化 tool 接入。
4 个 special token 角色
GLM 系列用 4 个 chat 角色 special token——没有独立的 <|tool_call|> token[^glm5-report]:
| Token | 角色 |
|---|---|
| `< | system |
| `< | user |
| `< | assistant |
| `< | observation |
Tool call 格式
Tool call 用 Python fenced code block 表示,工具名作为 <|assistant|> block 的 metadata:
<|assistant|> tool_name=python_executor
<think> ... 思考 ... </think>
```python
import math
math.sqrt(2)
<|observation|> 1.4142135623730951 <|assistant|> ...
`<|observation|>` block 的 token 进入 attention,但**在 loss 中被 mask**——只对模型生成的 token 算梯度。
### Preserved Thinking
`<think>...</think>` 块在多轮对话中是否保留由 `clear_thinking` 标记控制[^together-glm5]:
- `clear_thinking: false` 模式下 thinking blocks 保留在 KV cache 跨轮复用
- 要求 prefix 精确匹配——session_id consistent hashing(见 [§Slime 内部数据流](#slime-内部数据流data-buffer-与-weight-sync-协议))保证同 agent 实例路由同 DP rank
## 多步环境:Sandbox + 视觉观测
Agentic RL 的环境构造[^glm5-report]:
| 任务类型 | Sandbox / Observation | Reward |
|---------|----------------------|--------|
| SWE-bench-like | Docker(RepoLaunch / DockSmith 管线),10k+ 仓库覆盖 9 种语言 | binary F2P / P2P pass |
| Terminal 操作 | shell command set,Docker isolation | binary task completion |
| Browser 浏览 | **Set-of-Mark + 截图**(不是 DOM tree / accessibility tree)| binary goal reach |
@tbl-glm52-env-table Agentic RL 环境矩阵
Set-of-Mark:截图上叠加可点击元素的数字标记,模型输出"点击元素 #N"——避免 DOM 解析复杂度,对视觉 reasoning 更直接。
## Reward Function:全程二值 ORM
GLM-5/5.2 reward 设计**异常简洁**[^glm5-report]:
- **Math / Code / SWE-bench**:全部用 **binary ORM**(Outcome Reward Model)——pass=1, fail=0
- **没有 PRM**(Process Reward Model),不做 partial credit
- **没有独立 tool reward**:工具调用成功本身不加分,只关心最终 outcome
- **没有 length / repetition penalty**:通过 IcePop 隐式控制(过长生成会触发 advantage 归一化的分母变大、相对吸引力下降)
这种"硬 binary outcome"路线赌的是 IcePop + 大 batch + 多 group 能稳住分布漂移;不像 RLHF 时代依赖 reward shaping 微调。
## OPD 蒸馏:两种公式形式必须区分
四阶段顺序训练有灾难性遗忘风险(Stage 3 覆盖 Stage 2、Stage 4 覆盖前面)。OPD(On-Policy Cross-Stage Distillation)的解法**有两种公式形式,文档常混用**(Slime docs[^slime-opd] vs GLM-5 paper[^glm5-report]):
### 形式 1:KL penalty(Slime docs 呈现)
在原 advantage 上减一个 KL 项:
$$
\begin{equation}
\hat{A}_t = A_t - \lambda_{\text{opd}} \cdot D_{\text{KL}}\big(\pi_{\text{teacher}} \,\|\, \pi_{\text{student}}\big)_t
\label{eq:opd-kl-penalty}
\end{equation}
$$
精确算需要全词表 softmax 才能得到完整分布,计算量较大。
### 形式 2:log-ratio 直接替换 advantage(GLM-5 paper)
直接把 advantage 替换为 teacher / student 的 log-ratio[^glm5-report]:
$$
\begin{equation}
\hat{A}(i,t) = \mathrm{sg}\big[\log \pi_{\text{teacher}}(a_{i,t}|s) - \log \pi_{\text{student}}(a_{i,t}|s)\big]
\label{eq:opd-log-ratio}
\end{equation}
$$
`sg[]` = stop gradient。只需采样 token 的 log-prob(不需全词表),**计算量大幅低于形式 1**。GLM-5 实际选这种形式。
**两种形式数学上目标相近**(都是让 student 向 teacher 拉近),但**实现成本与梯度路径不同**——形式 2 是 GLM-5 paper 实际用的,formal 1 是 Slime docs 解释用的。理解 OPD 必须知道这层区分。
### 双 teacher 是数据层混合,不是 logit ensemble
两个 teacher checkpoint(Reasoning RL stage 末 + General RL stage 末)对应各自训练数据集,**按比例从两个数据集采样 prompt**,每条 prompt 用对应的 teacher 监督。**不是 logit 平均,不是 mixture-of-experts 风格 ensemble**——这是数据层而非模型层的混合[^glm5-report]。
精确数据集比例与 $\lambda_{\text{opd}}$ 数值 GLM-5 报告未公开(Slime 代码默认 $\lambda_{\text{opd}}=1.0$ 可查)。
### 工程配置
- group size 从 RL 阶段的 32 **降至 1**(teacher log-ratio 直接充当 advantage,不需要 group 内归一化)
- batch size 扩至 1024
- 不使用 outcome reward——仅靠 KL/log-ratio 驱动
- reverse KL(mode-seeking),不是 forward KL(mean-seeking)
## 预训练:Muon + Muon Split + 100K 昇腾
GLM-5.2 预训练沿用 GLM-5 的成果,在此基础上做 mid-training 长上下文扩展[^glm5-report]。
### 优化器:Muon + Muon Split
GLM-5 / 4.5 用 **Muon 优化器**[^muon-jordan](Keller Jordan 2024)——通过 Newton-Schulz 迭代做矩阵正交化,比 AdamW 在 2D 权重(dense matrix)上收敛更快。
**Muon Split 自研改进**[^glm5-report]:MLA 的 $W^{Q,B}$ / $W^{KV,B}$ 是 64 head × per-head dim 的拼接矩阵,整体正交化会破坏 head 间独立性。Muon Split 按 head 切分子矩阵分别正交化,让 attention logit 在整个预训练中**无需梯度裁剪**——这与 DSV4 的"整体正交化"路线不同。
**Muon 不覆盖所有参数**:以下走 AdamW(Muon 在 1D / 小矩阵上无优势):
- Embedding
- Bias
- RMSNorm scale
**超参(继承 GLM-4.5)**[^glm45-report]:Muon `N=5`(NS 迭代数),$\mu=0.95$,RMS scale 0.2,weight_decay 0.1。AdamW 超参未公开。
### LR / batch schedule
- **主预训练**:cosine decay,warmup 0 → $2 \times 10^{-4}$ → 衰减到 $4 \times 10^{-5}$
- **Mid-training 三段**:统一线性衰减 $4 \times 10^{-5} \to 1 \times 10^{-5}$
- **Batch size ramp-up**:前 500B tokens 从 **16M → 64M tokens** 逐步扩大,之后固定 64M
### 数据组成与处理
- **27T 主预训练**(4K context)+ **1.55T mid-training**(32K → 128K → 200K)
- **Web**:DCLM + sentence-embedding 双分类器
- **Code**:fuzzy dedup 后 unique token +28% vs GLM-4.5
- **Math/Science**:LLM 打分过滤
- **Wikipedia 分类器** 增强 world knowledge
**配比比例 GLM-5 报告未公开**——这是常见的 closed-source 数据策略隐私。
### Tokenizer
vocab_size = **154,880**,`TokenizersBackend` 实现;具体 BPE / SentencePiece / Tiktoken 算法 GLM-5 / 5.2 公开资料**未明确**[^hf-config]。
### 预训练集群
GLM-5 主预训练在 **昇腾 910B × 100,000 片** + MindSpore 框架完成[^glm5-report](SMIC 7nm DUV)。GLM-5.2 是否沿用昇腾、是否换 H100、规模多大——公开资料**未披露**。RL 后训练 256 × H100 已知。
## Mid-training + DSA 稀疏适配
| 阶段 | 数据规模 | 序列长度 | 备注 |
|------|---------|---------|------|
| Pre-training | 27T tokens | 4K | Muon + Muon Split |
| Mid-training | 1T tokens | 32K | rope_theta 升至 8M[^hf-config] |
| Mid-training | 500B tokens | 128K | 从此引入 IndexShare |
| Mid-training | 50B tokens | 200K | 长 context 微调 |
| DSA 稀疏适配 | 20B tokens | 128K+ | 1000 步冻结主模型仅训 indexer + 解冻联合训 |
@tbl-glm52-pretrain 预训练与 mid-training 阶段
**rope_theta = 8M 是 GLM-5.2 的设置**(GLM-5 config 中只到 1M);mid-training 引入大 RoPE base 支持 200K → 1M context。RoPE 不做 YaRN / dynamic scaling[^hf-config]。
**DSA 稀疏适配仅需 20B token**(1000 步预热冻结主模型仅训练 indexer + 后续联合训练),对比 DSV3.2 的 DSA 需 943.7B token——token 预算约 1/50[^glm5-report]。
## 训练故障与稳定性
GLM-5 报告披露的具体训练故障[^glm5-report]:
- **`torch.topk` 非确定性导致 RL 开局崩溃**:GPU 并行版本 `torch.topk` 对相同分数输入不保证返回相同 index,导致 RL 开始几步内 entropy 急剧下降、性能急跌。修复方式是改用确定性实现(CPU fallback 或 sort-then-topk)。
这是已记录的工程级故障,与预训练 loss spike 的成因不同——不是数值不稳定,是 PyTorch 算子的隐式假设破坏。
**预训练 loss spike / loss curve / checkpoint 间隔等细节** GLM-5 / 5.2 公开资料未给出。
## 评测进度
GLM-5.2 发布时**无完整 benchmark 表格**[^hf-blog]——这与近年公开评测氛围有些反差。有精确数字的只有 Agentic 评测:
| Benchmark | GLM-5.2 | 对比 Claude Opus 4.8 |
|-----------|---------|---------------------|
| SWE-bench Pro | 62.1 | (未直接公开) |
| AIME 2026 | 99.2 | — |
| Terminal-Bench | 81.0 | — |
| SWE-Marathon | 13.0% | 26.0%(落后约半数)|
@tbl-glm52-evals GLM-5.2 公开评测数字
**RULER / HumanEval / MMLU / Arena-Hard 均未公开**[^hf-blog]——这片数据空白让"GLM-5.2 vs 闭源旗舰"的对比难以精确。
## 与 DSV3 / V4 训练路线对比
| 维度 | GLM-5.2 | DSV3 | DSV4 |
|------|---------|------|------|
| 优化器 | Muon + **Muon Split**(按 head 正交) | AdamW(DSV3) | Muon(整体正交) |
| 预训练 token | 27T 主 + 1.55T mid | 14.8T | 推测 ~20T |
| RL 算法 | GRPO + IcePop(hard gate)+ 非对称 clip | GRPO | GRPO[推断] |
| KL 系数 | **0** | 非零 [推断] | 非零 [推断] |
| Reward | binary ORM only | ORM + 少量 PRM [推断] | 推测 ORM [推断] |
| OPD 形式 | log-ratio replacement | — | KL penalty[推断] |
| 双 teacher | 数据层混合 | — | logit ensemble[推断] |
| Group size | 32 | 64 (R1) | — |
| 预训练硬件 | 100K × 昇腾 910B + MindSpore | NVIDIA H800 | NVIDIA H800/H100 |
@tbl-glm52-vs-dsv3v4-training GLM-5.2 / DSV3 / DSV4 训练路线对比
**核心路线差异**:GLM-5 选 "国产卡 + Muon + GRPO+IcePop + binary reward" 的简洁极端组合;DSV 走 "更大数据 + 软 clip + reward shaping" 的稳健渐进路线。两种风格的胜负目前由公开评测决定——GLM-5.2 在 Agentic benchmark 上仍落后 Claude Opus 4.8 半数。
## 开放问题
- GLM-5.2 预训练集群规模 / 是否沿用昇腾
- 数据配比(web / code / math / 比例)
- AdamW 超参(lr / β1 / β2 / weight_decay)
- OPD $\lambda_{\text{opd}}$ 精确数值与退火策略
- RULER / MMLU / Arena-Hard 评测数据
- 训练 loss 曲线 / loss spike 处理 / checkpoint 间隔
- 数据集层比例(reasoning vs general teacher 数据集采样权重)
## Takeaway
| 知识点 | 核心结论 |
|--------|---------|
| 异步解耦 | SGLang rollout + Megatron 训练完全异步,Slime 是该路线的实现 |
| Data Buffer | dict-of-list keyed by instance_id,GRPO group_size 触发 ready,on-policy 一次性消费 |
| Weight Sync | 4 路径:Colocated IPC / Disaggregated NCCL / Disk / Delta(bytewise diff,与前 3 路径组合)|
| TITO Gateway | rollout 时记录 FP32 log-prob,训练端无需重算 $\pi_{\text{old}}$ |
| RL 算法 | GRPO + IcePop($\rho \notin [0.5, 2]$ 硬置零)+ 非对称 clip(0.2 / 0.28)+ KL 系数 0 |
| Reward | 全程 binary ORM,无 PRM,无 partial credit |
| TIR 接口 | 4 special token (system/user/assistant/observation),Python fenced code block 表 tool call |
| OPD 形式 | 必须区分:KL penalty (Slime docs) vs log-ratio replacement (GLM-5 paper),后者实际用 |
| 双 teacher | 数据层混合,不是 logit ensemble |
| 优化器 | Muon + Muon Split(按 head 正交化 MLA);Embedding/Bias/RMSNorm 走 AdamW |
| 集群 | 预训练 100K × 昇腾 910B + MindSpore;RL 后训练 256 × H100 |
| 故障 | torch.topk 非确定性导致 RL 开局崩溃,改确定性实现修复 |
## 参考资料
[^slime-doc]: Slime RL Documentation. https://thudm.github.io/slime/
[^slime-opd]: Slime On-Policy Distillation Documentation. https://thudm.github.io/slime/advanced/on-policy-distillation.html
[^slime-code]: THUDM/slime source code (`slime/utils/types.py` 的 `Sample` dataclass、`slime/backends/megatron_utils/update_weight/`、`slime/utils/dp_schedule.py`)。https://github.com/THUDM/slime
[^glm5-report]: GLM-5: from Vibe Coding to Agentic Engineering, arXiv:2602.15763, 2025. https://arxiv.org/abs/2602.15763
[^glm45-report]: GLM-4.5 Technical Report, arXiv:2508.06471, 2025. https://arxiv.org/abs/2508.06471
[^hf-config]: HuggingFace GLM-5.2 config.json. https://huggingface.co/zai-org/GLM-5.2/blob/main/config.json
[^hf-blog]: HuggingFace, *GLM-5.2 Blog*, 2026-06. https://huggingface.co/blog/zai-org/glm-52-blog
[^tora-paper]: ToRA: Tool-Integrated Reasoning Agent, arXiv:2309.17452, 2023. https://arxiv.org/abs/2309.17452
[^muon-jordan]: Keller Jordan, *Muon: An optimizer for hidden layers in neural networks*, 2024. https://kellerjordan.github.io/posts/muon/
[^together-glm5]: Together AI, GLM-5 Quickstart (`clear_thinking` / Preserved Thinking 文档). https://docs.together.ai/docs/glm-5-quickstart
## 延伸阅读
- [../02-DeepSeek-V4/05-training](../02-DeepSeek-V4/05-training.md) — DeepSeek V4 的 Muon(整体正交化)与 OPD 后训练
- [06-inference](./06-inference.md) — TITO Gateway 通信路径 + Slime weight sync 通信侧
- [02-indexshare](./02-indexshare.md) — DSA 稀疏适配的 indexer 训练与 KL 蒸馏