序列压缩注意力
沿序列方向把若干 token 的 KV 加权融合成一个压缩 entry,减少 entry 总数
核心要点:
- 序列压缩减 KV entry 数量,维度压缩减每 entry 维度
- compressor 用 softmax 加权池化把 $m$ 个 token 压成一个 entry
- overlap transform 让相邻 entry 共享 token,消除边界断裂
- HCA 压缩 128× 后 entry 少到可直接做 dense attention
- flash compressor 把 5 次 HBM 访问融合成 2 次
本篇是注意力机制章实现卷的压缩化(序列)篇,是 compressor 的唯一主词条。CSA 压缩后还要用 lightning indexer 做 top-k 稀疏选择——那是 CSA 的稀疏半边,归 08-动态稀疏选择(indexer + top-k 主词条),本篇只讲压缩半边、不重写。维度压缩 MLA 归维度压缩篇 10(链接待回填),本篇只对比。
名词定义
| 名词 | 定义 |
|---|---|
| 序列压缩 | 沿序列方向把 $m$ 个 token 的 KV 融合成一个 entry,减少 entry 总数 |
| 维度压缩 | 把每个 token 的 KV 投影到低维 latent,减少每 entry 的维度(MLA) |
| Compressed entry | 由若干原始 token 的 K/V 加权融合得到的单个压缩 KV |
| Compressor | 把 token 块压成 compressed entry 的算子(softmax 加权池化) |
| CSA (Compressed Sparse Attention) | V4 的压缩 + 稀疏注意力,4× 压缩 + indexer top-k;对应 V4 的 C4 层 |
| HCA (Heavily Compressed Attention) | V4 的激进压缩 dense 注意力,128× 压缩无 top-k;对应 V4 的 C128 层 |
| Overlap transform | CSA 用 a/b 双流投影使相邻 compressed entry 共享同一段 token |
| Flash compressor | 把 compressor 流水线融合成单次 on-chip pass 的 kernel |
@tbl-attn-seqcomp-glossary 本篇名词定义
序列压缩和维度压缩差在哪?
序列压缩减少 KV entry 的数量,维度压缩减少每个 entry 的维度——两者作用轴正交,可叠加。这是压缩化机制族内部的根本分野。
- 序列压缩:把 $m$ 个连续 token 的 K/V 融合成一个 compressed entry,序列长度从 $n$ 压到 $n/m$。代表:CSA、HCA、NSA 的压缩分支[1]。
- 维度压缩:每个 token 仍有独立 KV,但把它投影到低维 latent $d_c \ll d$。代表:MLA(见维度压缩篇 10)。
对比:序列压缩是"把多个包裹打包成一个",维度压缩是"把每个包裹缩小尺寸"。DeepSeek V4 选择用序列压缩替代 MLA——去掉 MLA,改用 compressor + MQA 共享 KV[2]。本篇讲序列压缩,MLA 在 10 篇。
compressor 怎么把多个 token 压成一个 KV entry?
compressor 用一组学习的 per-token logit(下式的 $Z$ 流)做 softmax,再加权平均块内 token 的 K/V,产出一个 compressed entry[2]。CSA 默认 $m=4$(4× 压缩),且用 a/b 双流投影。
给定隐状态 $H \in \mathbb{R}^{n \times d}$,先产生两条 KV 流和两条 logit 流:
$$\begin{equation} C^a = H W^{KV_a}, \quad C^b = H W^{KV_b}, \qquad Z^a = H W^{Z_a}, \quad Z^b = H W^{Z_b} \label{eq:attn-seqcomp-csa-proj} \end{equation}$$第 $i$ 个 compressed entry 覆盖当前块 $[mi,\, m(i{+}1){-}1]$($C^a$ 流)和前一块 $[m(i{-}1),\, mi{-}1]$($C^b$ 流),行向 softmax 跨这 $2m$ 行联合归一化:
$$\begin{equation} \begin{bmatrix} S^a \\ S^b \end{bmatrix} = \mathrm{Softmax}_{\text{row}}\!\left( \begin{bmatrix} Z^a_{mi:m(i+1)-1} + B^a \\ Z^b_{m(i-1):mi-1} + B^b \end{bmatrix} \right) \label{eq:attn-seqcomp-csa-softmax} \end{equation}$$ $$\begin{equation} C_i^{\text{Comp}} = \sum_{j=mi}^{m(i+1)-1} S^a_j \odot C^a_j + \sum_{j=m(i-1)}^{mi-1} S^b_j \odot C^b_j \label{eq:attn-seqcomp-csa-pool} \end{equation}$$$B^a, B^b \in \mathbb{R}^{m \times c}$ 是可学习位置偏置,让模型对块内各位置赋不同重要性;$\odot$ 是 Hadamard 积。学习的 softmax 权重让 compressor 不是简单均值池化,而是内容感知的加权融合。
边界:CSA 压缩出 entry 后,lightning indexer 还要从中选 top-512 个做稀疏 attention——那是 CSA 的稀疏半边,机制见 08 动态稀疏选择,本篇不重写。
overlap transform 为什么让相邻 entry 共享 token?
非重叠的分组池化会在块边界断裂局部依赖——overlap transform 用 a/b 双流让相邻 compressed entry 回看同一段 token,以零额外 entry 成本保住边界连续性[2]。
问题在于:硬切分下块 $i$ 和块 $i{+}1$ 的 token 各归不同 entry,跨边界的局部依赖在压缩后消失。overlap 的关键是覆盖区间的重叠:
| 流 | entry $i$ 覆盖的 token |
|---|---|
| $C^a$(当前块) | $[mi,\; m(i+1)-1]$ |
| $C^b$(前一块) | $[m(i-1),\; mi-1]$ |
@tbl-attn-seqcomp-overlap CSA 双流的 token 覆盖区间
entry $i$ 的 $C^a$ 区间 = entry $i{+}1$ 的 $C^b$ 区间——下一个 entry 用 $C^b$ 重新回看本 entry 用 $C^a$ 覆盖的那批 token。于是每批 $m$ 个 token 被相邻两个 entry 各引用一次,消除信息孤岛。
$i=0$ 的边界处理:第 0 个 entry 的 $C^b$ 需要位置 $[-m, -1]$,这些 token 不存在。处理是把它们的 logit 设为 $-\infty$、向量置零,使 softmax 后权重趋近 0,第 0 个 entry 退化为纯 $C^a$ 单流压缩:
$$\begin{equation} Z^b_{-m:-1} = -\infty, \qquad C^b_{-m:-1} = \mathbf{0} \label{eq:attn-seqcomp-overlap-bound} \end{equation}$$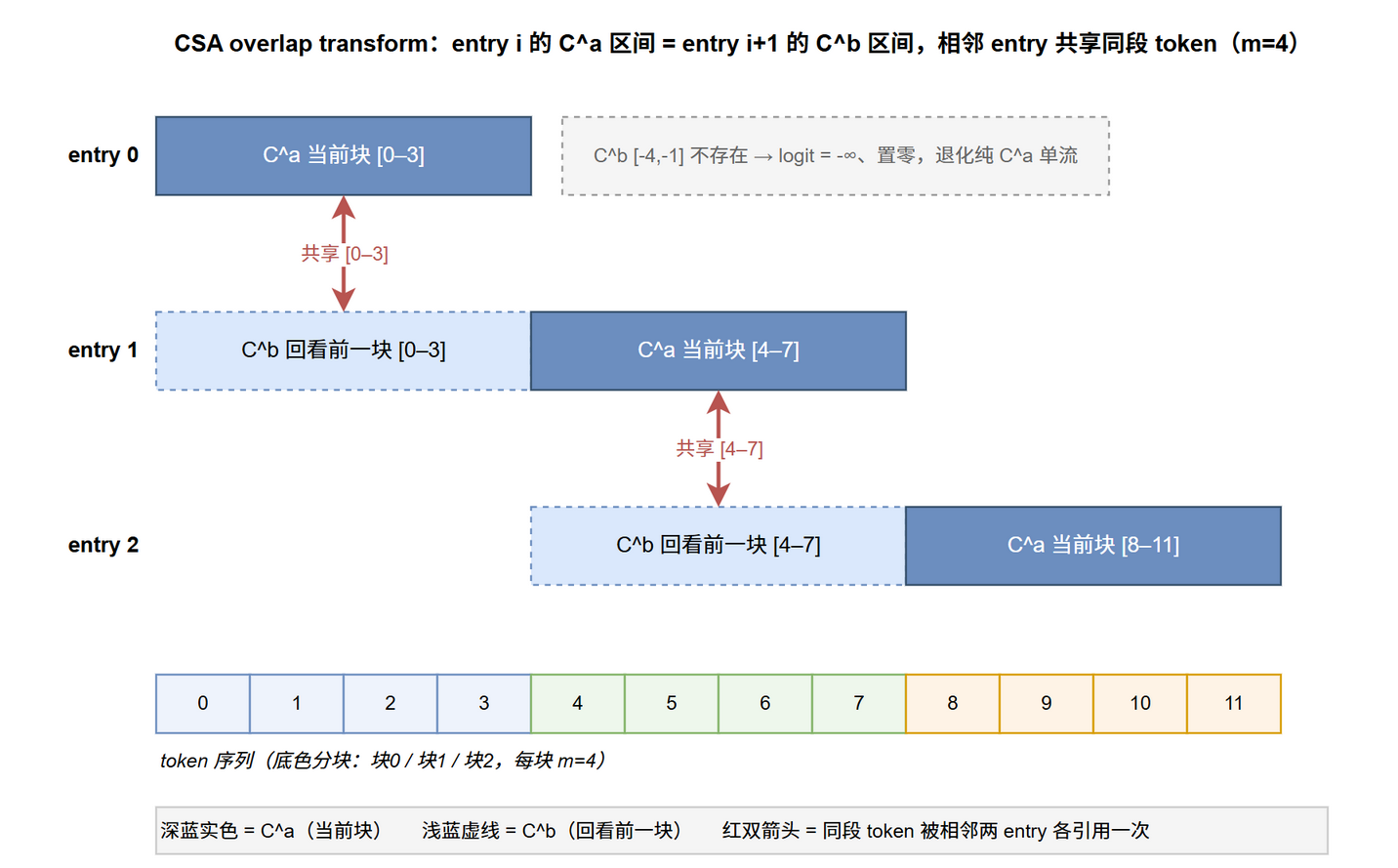
HCA 怎么靠 128× 压缩做 dense attention?
HCA 把压缩比拉到 128×,entry 总数少到可以让所有 entry 都参与 attention,因此不需要 top-k 稀疏选择[2]。它是单流、无 overlap 的激进压缩:
$$\begin{equation} S = \mathrm{Softmax}_{\text{row}}(Z + B), \qquad C_i^{\text{Comp}} = \sum_{j=m'i}^{m'(i+1)-1} S_j \odot C_j, \qquad m'=128 \label{eq:attn-seqcomp-hca} \end{equation}$$softmax 只在单块内 $m'=128$ 行上归一化,无 $C^a/C^b$ 区分。HCA 与 CSA 的本质区别:
| 维度 | CSA | HCA |
|---|---|---|
| 压缩比 | $m=4$(4×) | $m'=128$(128×) |
| KV 流 | 双流 $C^a+C^b$ | 单流 |
| overlap | 有 | 无 |
| 访问模式 | 稀疏(indexer 选 top-512,见 08) | dense(所有 entry 全参与) |
| 1M token 下 entry 数 | $\sim$250K(选 512 个) | $\sim$7800(全参与) |
@tbl-attn-seqcomp-csa-hca CSA 与 HCA 的对比
为什么 HCA 能 dense 而 CSA 要稀疏:CSA 压缩比轻(4×),1M token 仍有约 250K entry,全参与代价大,得靠 indexer 选 512 个;HCA 压缩比重(128×),1M token 只剩约 7800 entry,dense attention 的 FLOPs 已经极低,无需 indexer。两者分工:CSA 抓局部精确依赖,HCA 抓文档级粗粒度语义[2]。层分布上,V4 前 2 层纯 HCA、中间层 CSA/HCA 交错[3]。
flash compressor 怎么把 5 次 HBM 访问降到 2 次?
naive compressor 一次要 5 次 HBM 往返,flash compressor 把整条流水线融合成单次 on-chip pass,只剩 1 读 + 1 写[2]。compressor 是 memory-bandwidth bound,HBM 访问次数直接决定速度。
naive 实现(PyTorch 拆分算子)的 5 次 HBM 访问:读 $H$ → 写 $C^a/C^b$ 投影 → 写 $Z^a/Z^b$ logit → 读回做 softmax + Hadamard → 写 compressed entry。每次都要 HBM↔SRAM 搬运,latency 串行叠加。
flash compressor 融合:读入 $H$(1 次 HBM 读)→ 在 SRAM 内算投影 + softmax + Hadamard + 加权求和 → 写出 $C_i^{\text{Comp}}$(1 次 HBM 写)。HBM round-trip 从 5 次降到 2 次,达约 80% 峰值内存带宽、比 naive 快 >10×[2]。
陷阱:这个 >10× 是 compressor 专项 kernel 相对 naive 的加速,不是整体推理加速。系统级 end-to-end(含 RoPE、cache 插入等其他 fusion)的复合提速口径不同、量级更低。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 序列 vs 维度压缩 | 序列减 entry 数(compressor),维度减每 entry 维度(MLA),正交可叠加 |
| compressor | softmax 加权池化把 $m$ 个 token 压成一个 entry,内容感知非均值 |
| overlap transform | a/b 双流使相邻 entry 共享同段 token,零额外成本保边界连续 |
| CSA vs HCA | CSA 4× 压缩 + indexer 稀疏选(见 08);HCA 128× 压缩 + dense |
| HCA 能 dense | 128× 压后 entry 少到约 7800,全参与 FLOPs 已极低,无需 indexer |
| flash compressor | HBM 访问 5→2,约 80% 带宽,>10× over naive |
@tbl-attn-seqcomp-takeaway 序列压缩注意力核心知识点
参考资料
- Yuan et al., Native Sparse Attention, arXiv:2502.11089, 2025. https://arxiv.org/abs/2502.11089
- LMSYS, DeepSeek V4 Day-0 Deployment, 2026-04-25. https://lmsys.org/blog/2026-04-25-deepseek-v4/
- Hugging Face, DeepSeek-V4: a million-token context, 2026. https://huggingface.co/blog/deepseekv4