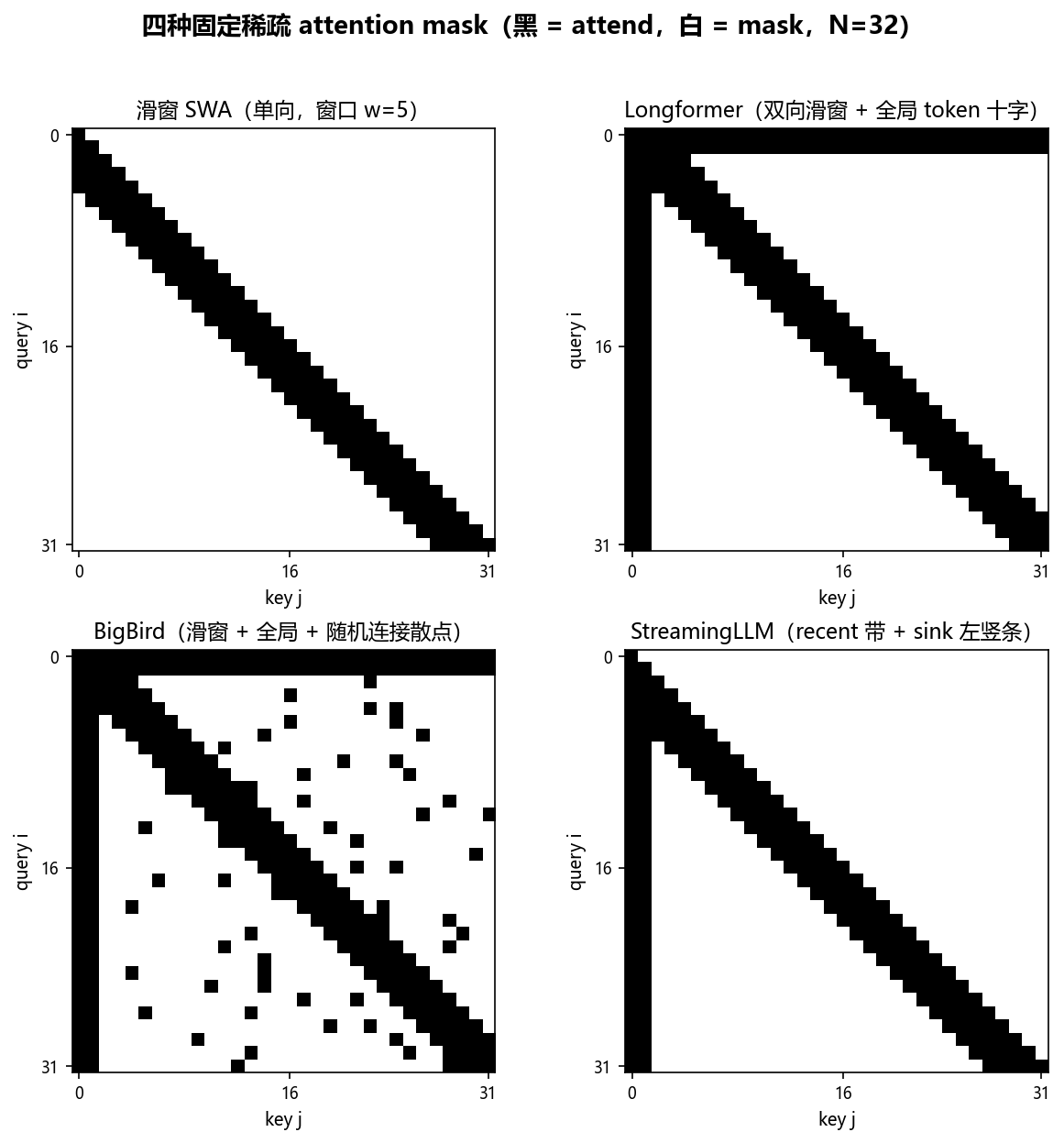
滑窗与固定稀疏
每个 query 看哪些 key 由位置预定义——滑窗取局部,全局 token 和随机连接补长程
核心要点:
- 固定稀疏按位置选 key,与内容无关,无打分开销
- 滑窗堆 $L$ 层感受野约 $L \times w$,靠深度覆盖长程
- rolling buffer 让 KV cache 恒为窗口大小不随序列增长
- 丢掉初始 token 会触发 attention sink 崩溃,PPL 爆 1000×
- StreamingLLM 保留 4 个 sink + 滑窗,撑住百万 token 流式生成
- Longformer 用全局 token、BigBird 用随机连接补全局视野
本篇是注意力机制章实现卷的**稀疏化(固定)**篇。机制族定位见 06-从dense到高效。固定稀疏与"按内容打分选 key"的动态稀疏(NSA / DSA / indexer,见动态稀疏选择篇 08,链接待回填)相对——本篇只讲位置预定义的稀疏模式。
名词定义
| 名词 | 定义 |
|---|---|
| 滑窗注意力 (SWA) | 每个 query 只 attend 最近 $w$ 个 token 的局部注意力 |
| 感受野 (receptive field) | 一个位置的表示能间接访问到的最远输入 token 距离 |
| Rolling buffer | 大小固定为窗口 $W$ 的循环 KV cache,按 $i \bmod W$ 写入 |
| 膨胀滑窗 (dilated SWA) | 滑窗内相邻被关注位置间跳 $d-1$ 个 token,扩大感受野不增算力 |
| Attention sink | 接收远超语义重要性的 attention 权重的 token,通常是初始位置 |
| Sink token | 专门吸收"无处安放"attention 权重的 token,可保留或预训练学习 |
| 全局 token (global token) | 少数 token 对全序列双向可见,作为信息汇聚节点 |
| 随机注意力 (random attention) | 每 query 额外随机连接 $r$ 个 key,借随机图缩短信息路径 |
@tbl-attn-fixed-glossary 本篇名词定义
固定稀疏靠什么省掉 $O(n^2)$?
固定稀疏让每个 query 只对一组由位置预定义的 key 计算注意力,把 $O(n^2)$ 降到 $O(n \cdot k)$,且不需要任何打分器。它赌的是"相关的 key 在固定位置"——多数情况下是局部邻域。
这条假设带来两点工程优势:
- 零打分开销:哪些 key 可见在编译期就定了(一个稀疏掩码),不像动态稀疏要先算 index score 再选。
- 硬件友好:固定模式(带状、块状)的内存访问规整,易于 kernel 优化。
代价是可能漏掉位置上远但语义相关的 token。后面三节讲固定稀疏怎么用感受野叠加、全局 token、随机连接来补这个漏洞。
滑窗注意力堆几层能看多远?
SWA 让每个 query 只看最近 $w$ 个 token,单层算力降到 $O(n \cdot w)$,但堆叠 $L$ 层后感受野约 $L \times w$——靠深度而非单层窗口覆盖长程依赖[1][2]。
单层 SWA 对 query $q_i$ 只在局部窗口上算 attention:
$$\begin{equation} \mathrm{Attn}(q_i) = \mathrm{softmax}\!\left(\frac{q_i \cdot K_{[i-w:i]}^\top}{\sqrt{d_k}}\right) V_{[i-w:i]} \label{eq:attn-fixed-swa} \end{equation}$$感受野随深度线性扩展,推导与 CNN 同理:
- 第 1 层:位置 $i$ 直接 attend 输入的 $[i-w,\, i]$,感受野 $w$。
- 第 2 层:$i$ attend 第 1 层的 $[i-w,\, i]$,而其中 $h_{i-w}^{(1)}$ 已能访问输入 $[i-2w,\, i-w]$,故 $i$ 间接覆盖 $[i-2w,\, i]$,感受野 $2w$。
- 第 $k$ 层:感受野 $k \times w$。
例子:Mistral 7B 取 $w=4096$、$L=32$,顶层理论感受野 $32 \times 4096 = 131072 \approx 131\text{K}$ token——单层只看 4K,深层却能间接触达 131K[1]。
这解释了固定稀疏第一个补漏手段:长程依赖不靠单层窗口,靠多跳间接传递。代价是远距离信息要逐层接力,不如 dense 一跳直达。
滑窗的 KV cache 怎么不爆?
SWA 每步只需 $w$ 个 KV,但若不截断历史 KV 仍会无限累积;rolling buffer 用循环写入把 cache 固定为窗口大小[1]。
问题在于:位置 $i$ 的 KV 在其后 $w$ 步内都会被 attend,naïve 实现仍要存全部历史。rolling buffer 的机制:
$$\begin{equation} \text{cache\_slot}(i) = i \bmod W \label{eq:attn-fixed-rolling} \end{equation}$$token $i$ 的 KV 写入第 $i \bmod W$ 个槽位,$i \geq W$ 时覆盖最旧的。cache 大小恒为 $W$,不随序列增长——32K 序列相比完整 KV cache 省 8× 内存,8K 序列省 2×[1]。
配套的 chunk-based prefill:长 prompt 切成 $w$ 大小的块逐块填充,块内用 causal mask、块间靠 rolling cache 传上下文,避免一次性扫描整个 prompt 超出窗口。
为什么丢掉最前面几个 token 会让模型崩溃?
窗口注意力一旦驱逐初始 token 的 KV,perplexity 会爆炸约 1000×——根因是 softmax 把初始 token 训练成了 attention sink[3]。这是固定稀疏(尤其滑窗流式推理)必须正视的失败模式。
实测对比悬殊(Llama-2-13B, 20K token)[3]:
| 配置 | Perplexity |
|---|---|
| 窗口注意力(0 sink + 1024 recent) | 5158.07 |
| StreamingLLM(4 sink + 1020 recent) | 5.40 |
@tbl-attn-fixed-sink-ppl 驱逐初始 token 前后的 perplexity 对比(Llama-2-13B, 20K)
attention sink 是结构性的,不是语义性的。可视化显示初始 token 在绝大多数层和头中吸收超 50% 的 attention 权重,远超其语义贡献。用换行符替换初始 token(内容无意义),PPL 仅从 5.40 微升到 5.60——证明起作用的是位置不是内容[3]。
根因在 softmax 的归一化约束:
$$\begin{equation} a_{ij} = \frac{\exp(q_i \cdot k_j / \sqrt{d})}{\sum_l \exp(q_i \cdot k_l / \sqrt{d})}, \qquad \sum_j a_{ij} = 1 \label{eq:attn-fixed-softmax-sink} \end{equation}$$陷阱:即使当前 query 与所有历史 token 都无强关联,softmax 也不允许把权重全部给 0——总和必须为 1,多余的权重必须倒给某些 token。模型在训练中学会:把这部分"无处安放"的权重集中到对所有后续位置都可见的初始 token。初始 token 因此被训成专职吸收权重的 sink[3]。
崩溃的因果链:推理时 cache 满 → 初始 token KV 被驱逐 → softmax 仍要权重和为 1 → 权重被迫重分到 recent token,但它们没被训成 sink、承接不了 → 表征崩溃。崩溃发生在驱逐的瞬间,不是渐进[3]。
这一点有理论支撑:对触发式条件任务,softmax 的概率单纯形归一化在数学上必然产生 sink,而非归一化的 ReLU attention 能完成同样任务却不产生任何 sink——归一化约束是 sink 形成的充要条件[4]。
StreamingLLM 怎么用 4 个 sink token 撑住流式生成?
StreamingLLM 的关键发现:不必保留初始 token 的语义内容,只要保留它们的 KV 作为 sink 锚点,就能让滑窗模型稳定处理数百万 token[3]。KV cache 组成两块:
$$\begin{equation} \text{KV cache} = \underbrace{\text{KV}_{[0:k]}}_{\text{attention sink}} \;+\; \underbrace{\text{KV}_{[t-m:t]}}_{\text{recent window}} \label{eq:attn-fixed-streaming} \end{equation}$$$k$ 个 sink token + $m$ 个最近 token,总 cache 恒为 $k+m$。位置编码按 cache 内连续位置重新赋值(0 到 $k+m-1$),而非原始序列位置——RoPE 缓存旋转前的 key、每步重新 apply[3]。
为什么是 4 个而非 1 个(跨模型消融,400K token)[3]:
| sink 数 $k$ | Falcon-7B | MPT-7B | Pythia-12B |
|---|---|---|---|
| 0 | 17.90 | 460.29 | 21.62 |
| 1 | 12.12 | 14.99 | 11.95 |
| 4 | 12.12 | 14.98 | 12.09 |
| 8 | 12.12 | 14.98 | 12.02 |
@tbl-attn-fixed-sink-ablation sink token 数量消融(400K token 拼接文本)
$k=0$ 崩溃(MPT 飙到 460),$k \geq 4$ 充分,8 几乎无改善。需要 4 个是因为这些模型预训练时没设计专用 sink,初始几个 token 内容每样本不同,sink 职责分散在前若干位置[3]。
对比:learnable sink token 在预训练时插入一个专用 placeholder,把 sink 职责集中到单个 token——之后推理只需 1 个 sink token 就达到普通模型 4 个的效果,把更多 cache 预算留给 recent window[3]。
效果:Llama-2 / MPT / Falcon / Pythia 在 400 万+ token 下稳定推理,比"滑窗 + 重计算"快 22.2×,已集成进 HuggingFace Transformers 与 TensorRT-LLM[3]。
局部窗口怎么补上全局视野?
Longformer 和 BigBird 在滑窗之外加全局 token、随机连接,让固定稀疏不靠多层接力也能一跳触达全局。两者复杂度都保持 $O(n)$。
Longformer:全局 token + 膨胀滑窗
Longformer 组合三种固定模式,全局 token 由任务绑定[2]:
- 滑窗:token $i$ attend $[i-w/2,\, i+w/2]$(Longformer 是双向 encoder,窗口宽 $w$ 居中;前文 SWA 是 decoder 单向回看最近 $w$ 个),复杂度 $O(n \cdot w)$。
- 膨胀滑窗:被关注位置间跳 $d-1$ 个 token,感受野扩到 $L \times d \times w$、算力不变;实验中只对少数 head 开膨胀(保局部+抓远程分工)。
- 全局 token:少数 $g$ 个 token 用独立投影 $(Q_g, K_g, V_g)$ 对全序列双向可见,额外开销 $O(n \cdot g) = O(n)$。
全局 token 按任务选:分类任务用 [CLS]、QA 任务用全部问题 token、共指消解不用。它充当信息汇聚节点——读全序列、再广播回全序列,$g = O(1)$ 不破坏线性复杂度[2]。
BigBird:随机连接 + 随机图理论
BigBird 的稀疏注意力是随机 + 局部滑窗 + 全局三类连接的并集,每 token 关注数 $g + w + r = O(1)$[5]:
$$\begin{equation} \text{总注意力对数} = n \cdot (g + w + r) = O(n) \label{eq:attn-fixed-bigbird} \end{equation}$$随机连接的正当性来自图论:$n$ 节点的 Erdős–Rényi 随机图只需 $\Theta(n)$ 条边,任意两节点最短路径 $O(\log n)$(小世界效应),且谱展开性保证信息扩散快。局部滑窗给局部性,随机连接给桥接,任意 token 对间有对数长度信息路径,近似全连接的信息流[5]。
BigBird 有 Longformer 没有的理论保证:保留星形图(全局 token 连接所有 token)后,它是通用近似器、且 Turing 完备——全局 token 充当图灵机的"工作带"实现寻址,稀疏图的对数路径保证有限步信息可达[5]。
全局 token 两种放法:ITC(从原序列内部指定,不增参数)vs ETC(序列外追加 $g$ 个自由 token,表达更强但要新 embedding)[5]。
两者对比
| 维度 | Longformer | BigBird |
|---|---|---|
| 补长程手段 | 膨胀滑窗 + 全局 token | 随机连接 + 全局 token |
| 全局 token | 任务绑定(CLS / 问题 token) | ITC(内部)/ ETC(外部追加) |
| 理论保证 | 无显式证明 | Turing 完备 + 通用近似(有证明) |
| 实现粒度 | token 级稀疏掩码 | block 级(GPU 友好) |
| 设计哲学 | 膨胀代替随机 + 多头分工 | 随机图理论背书 |
@tbl-attn-fixed-longformer-bigbird Longformer 与 BigBird 固定稀疏模式对比
三种固定稀疏的选型直觉:长程依赖稀疏、可接受逐层接力 → 纯 SWA 堆层最省;依赖集中在少数关键全局位置(问题 / [CLS])→ Longformer 全局 token;需要任意位置间稳定信息流 + 理论保证 → BigBird 随机连接。三者都不打分,区别只在"补长程"的手段。
Takeaway
| 知识点 | 核心结论 |
|---|---|
| 固定稀疏本质 | 按位置预定义选 key,零打分开销,$O(n^2) \to O(n \cdot k)$ |
| SWA 感受野 | 单层 $w$,堆 $L$ 层约 $L \times w$(Mistral:32×4096≈131K) |
| Rolling buffer | $i \bmod W$ 循环写入,cache 恒为窗口大小,32K 省 8× |
| Attention sink | softmax 归一化逼模型把多余权重倒给初始 token,丢之即崩(PPL 5158 vs 5.40) |
| StreamingLLM | 保留 4 sink + 滑窗,撑 400 万 token;learnable sink 使 1 个足够 |
| Longformer | 全局 token(任务绑定)+ 膨胀滑窗,$O(n)$ |
| BigBird | 随机连接(Erdős–Rényi 小世界)+ 全局,Turing 完备 |
@tbl-attn-fixed-takeaway 滑窗与固定稀疏核心知识点
参考资料
- Jiang et al., Mistral 7B, arXiv:2310.06825, 2023. https://arxiv.org/abs/2310.06825
- Beltagy et al., Longformer: The Long-Document Transformer, arXiv:2004.05150, 2020. https://arxiv.org/abs/2004.05150
- Xiao et al., Efficient Streaming Language Models with Attention Sinks, ICLR 2024, arXiv:2309.17453. https://arxiv.org/abs/2309.17453
- Attention Sinks Are Provably Necessary in Softmax Transformers, arXiv:2603.11487, 2026. https://arxiv.org/abs/2603.11487
- Zaheer et al., Big Bird: Transformers for Longer Sequences, NeurIPS 2020, arXiv:2007.14062. https://arxiv.org/abs/2007.14062