AI 使用经验分享
背景
AI 编程工具(Claude Code、Cursor、Copilot 等)的单次对话能力很强,社区也有不少工作流框架。日常使用中遇到几类跟模型能力无关、跟工作流相关的问题:
- 设计决策不落地:AI 拿到任务就开始改代码,讨论共识散落在对话里,下次对话就丢了
- 审核方式取舍:自审快但有盲点,独立审客观但成本高,多角色审覆盖广但调用成本大
- 调试从代码开始:多个 Bug 叠加可能恰好抵消,看起来"结果正确"
- spec 和实现细节混在一起:写满了函数名和行号,代码重构后就过时
- 流程一刀切:固定全套流程,一个小改动也要走完整步骤
这些问题不是模型能力问题,得靠工作流来管。
主流工具
Claude Code 生态目前比较活跃的(描述用官方原文翻译):
工作流框架(自带方法学的完整工作流):
- Superpowers(19 万+ Star):实战可用的智能体技能框架 + 软件开发方法学
- gstack(9.8 万+ Star):Garry Tan 同款 Claude Code 配置——23 个有主见的工具,分别担当 CEO / 设计师 / 工程经理 / 发布经理 / 文档工程师 / QA
- github/spec-kit(10 万+ Star,GitHub 官方):帮你开始 Spec-Driven Development 的工具包
Subagent 集合(专职子代理 subagent 的合集):
- wshobson/agents(3.5 万+ Star):Claude Code 的智能自动化和多智能体编排
- VoltAgent/awesome-claude-code-subagents(2 万+ Star):100+ 个专门的 subagent 合集,覆盖广泛的开发场景
精选清单(awesome list 类的资源索引):
- hesreallyhim/awesome-claude-code(4.4 万+ Star):Claude Code 生态精选清单(skill / hook / slash 命令 / 智能体编排 / 应用 / 插件)
这些工具覆盖大部分场景。下面分享的是在主流工具基础上做的一些工作流调整,不是要替代它们。
对比
按背景段的 5 个问题,跟有完整工作流的三个框架对比:
| 问题 | Superpowers | gstack | spec-kit | 本文做法 |
|---|---|---|---|---|
| 设计决策不落地 | brainstorming 出 design 文档但不冻结 | 无 spec 概念,靠 /office-hours /autoplan 等 slash 链路 | 有 spec 但不冻结 | spec 评审后冻结,偏差独立记录 |
| 审核方式取舍 | 自审 | 多角色(CEO / Eng / Design / DevEx 四角度审同一份 plan) | 弱 | 三阶段独立 Agent 审 |
| 调试起点 | 不强制查 spec | 不覆盖(无独立调试环节) | 不覆盖(spec 驱动工具,不涉及调试流程) | 第 0 步查 spec |
| 文档混杂 | design 文档允许实现细节 | 无对应设计文档概念 | spec 含技术栈等实现描述 | spec / plan / issue 内容分层 |
| 流程一刀切 | 任务大小走全套 TDD 流程 | 角色 slash 链路固定 | 主推 spec → plan → tasks → implement 全套 | discuss 按复杂度路由 |
@tbl-share-comparison 5 个问题在主流工具与本文做法上的覆盖度对比
工作流
主线是 discuss → spec → plan → act,由 discuss 入口按任务复杂度分流。debug 流程独立旁路,三阶段(spec / plan / code)各配一道独立审核。
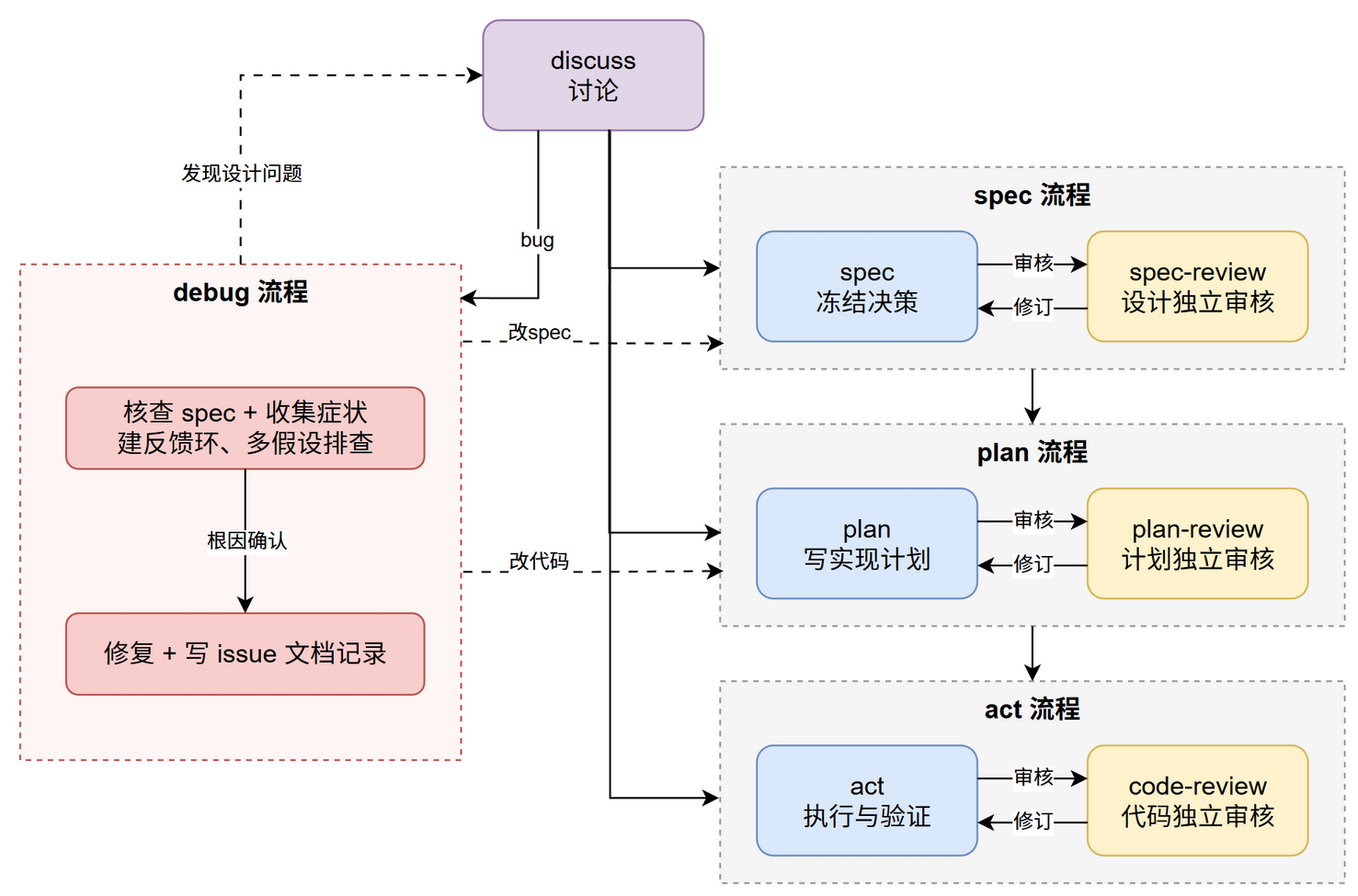
图里几个设计点的取舍:
- 复杂度路由:主流框架对简单改动是过度消耗。让流程深度匹配任务复杂度——简单任务直接 act,复杂任务才走 spec
- Spec 冻结:Superpowers 的 brainstorming(构思阶段)也产出 design 文档,但定位是"实施前快照",跟代码一起演化。本文做法是把 spec 当作冻结契约——为了几年后回溯设计意图时还能找到可信版本
- 文档分层:主流工具的 design 文档普遍混杂实现细节。三类文档(spec / plan / issue)隔离的目的是让 spec 脱离代码生命周期——代码一重构 spec 还能用作"原本怎么设计"的可信锚点
- 三阶段独立审核:用独立 Agent 从零读而不是自审,是因为自审看不到自己写时形成的盲点。代价是慢——这个权衡只在"设计错误成本远大于审核成本"的场景成立
- Spec 驱动调试:跟传统调试最大的差别在起点——代码当前行为不等于正确行为,盯着代码看容易正中"多个错误抵消看起来正确"的圈套。调查过程记录到 issue 文档,方便追溯