Torus 拓扑族通信评估
评估范围
在 64 芯片 Torus 拓扑上,评估不同形状、通信算法和消息大小对集合通信延迟的影响。评估维度见 ,通信算法覆盖见 。
| 维度 | 范围 |
|---|---|
| 拓扑形状 | 2D-8x8, 2D-4x16, 2D-2x32, 3D-4x4x4(均 64 芯片) |
| 通信组大小 | 2, 4, 8, 16 |
| 消息大小 | 64KB, 256KB, 1MB |
| 通信原语 | AllReduce, AllGather, ReduceScatter |
| 路由算法 | shortest_path, DOR |
@tbl-torus-eval-scope 评估维度与范围
| 原语 | 算法 |
|---|---|
| AllReduce | Ring, 2-port Ring, Halving-Doubling (HD), Double Binary Tree (DBT) |
| AllGather | Ring, 2-port Ring, Recursive Doubling (RD) |
| ReduceScatter | Ring, 2-port Ring, Recursive Halving (RH) |
@tbl-torus-algo-coverage 各原语评估的通信算法
硬件参数:SG2262 芯片,c2c 带宽 400 GB/s,链路延迟 0.025 us。
通信组与芯片放置
通信组划分、并行策略和评估方法的详细说明参见 TPS186 通信原语评估。
Torus 上通信组由连续芯片 ID 组成,按行优先顺序映射到物理坐标(2D-8x8 中 chip 0-7 为第一行)。由于 Torus 的平移对称性,所有同大小通信组的内部结构完全一致,评估一个组即可代表全部。各拓扑下 TP 通信组的具体放置见 。
| 拓扑 | TP | 组内芯片位置 | 最大跳数 |
|---|---|---|---|
| 2D-8x8 | 2 | 同行相邻:(0,0)-(0,1) | 1 |
| 2D-8x8 | 4 | 同行连续:(0,0)-(0,3) | 2 |
| 2D-8x8 | 8 | 整行:(0,0)-(0,7) | 4 |
| 2D-8x8 | 16 | 连续两行:(0,0)-(1,7) | 5 |
| 3D-4x4x4 | 2 | 同行相邻:(0,0,0)-(0,0,1) | 1 |
| 3D-4x4x4 | 4 | 同行连续:(0,0,0)-(0,0,3) | 2 |
| 3D-4x4x4 | 8 | 同平面两行:(0,0,0)-(0,1,3) | 4 |
| 3D-4x4x4 | 16 | 同平面全部:(0,0,0)-(0,3,3) | 4 |
@tbl-torus-tp-placement TP 连续放置下各拓扑的通信组芯片分布
形状对比
2D 纵横比
三种 2D Torus 纵横比(8x8 方形、4x16 长方、2x32 细长)在 AllReduce 1MB 下的延迟对比见 。
| 形状 | 组大小=4 | 组大小=8 | 组大小=16 |
|---|---|---|---|
| 2D-8x8 (方形) | HD 5.20 / Ring 6.99 / 2-port 4.70 | HD 7.50 / Ring 11.20 / 2-port 5.95 | HD 7.56 / Ring 17.91 / 2-port 9.60 |
| 2D-4x16 (长方) | HD 5.20 / Ring 6.99 / 2-port 4.70 | HD 6.81 / Ring 12.22 / 2-port 7.20 | HD 8.87 / Ring 17.53 / 2-port 8.65 |
| 2D-2x32 (细长) | HD N/A / Ring 6.99 / 2-port 4.70 | HD N/A / Ring 12.22 / 2-port 7.20 | HD N/A / Ring 27.34 / 2-port 15.11 |
@tbl-torus-2d-shape AllReduce 1MB 不同 2D Torus 纵横比延迟对比 (us)
Ring 和 2-port Ring 在 8x8、4x16 上结果几乎一致(环形通信模式不依赖纵横比,shortest_path 在均匀带宽 torus 上选到同跳数路径);2x32 在 n=16 时显著退化(Ring 27.34 vs 8x8 17.91,慢 53%),原因是组大小=16 跨越行边界且 2x32 单维只有 2 个节点,环路必须沿长维绕远。HD 属于 hypercube 类算法,要求拓扑维度 >= log2(N),2x32 维度不足无法运行(表中标注 N/A)。
DBT 和 RH 同样属于 hypercube 类,在 2x32 上无法运行;在能运行的 8x8 vs 4x16 上对纵横比敏感,长方形状退化明显()。
| 形状 | AR DBT 组大小=16 | RS RH 组大小=16 |
|---|---|---|
| 2D-8x8 | 14.17 us | 4.86 us |
| 2D-4x16 | 16.95 us | 11.24 us |
| 2D-2x32 | N/A(dim<=2 不支持 hypercube 类) | N/A |
@tbl-torus-shape-sensitive DBT 和 RH 在不同纵横比下的延迟 (us,组大小=16, 1MB)
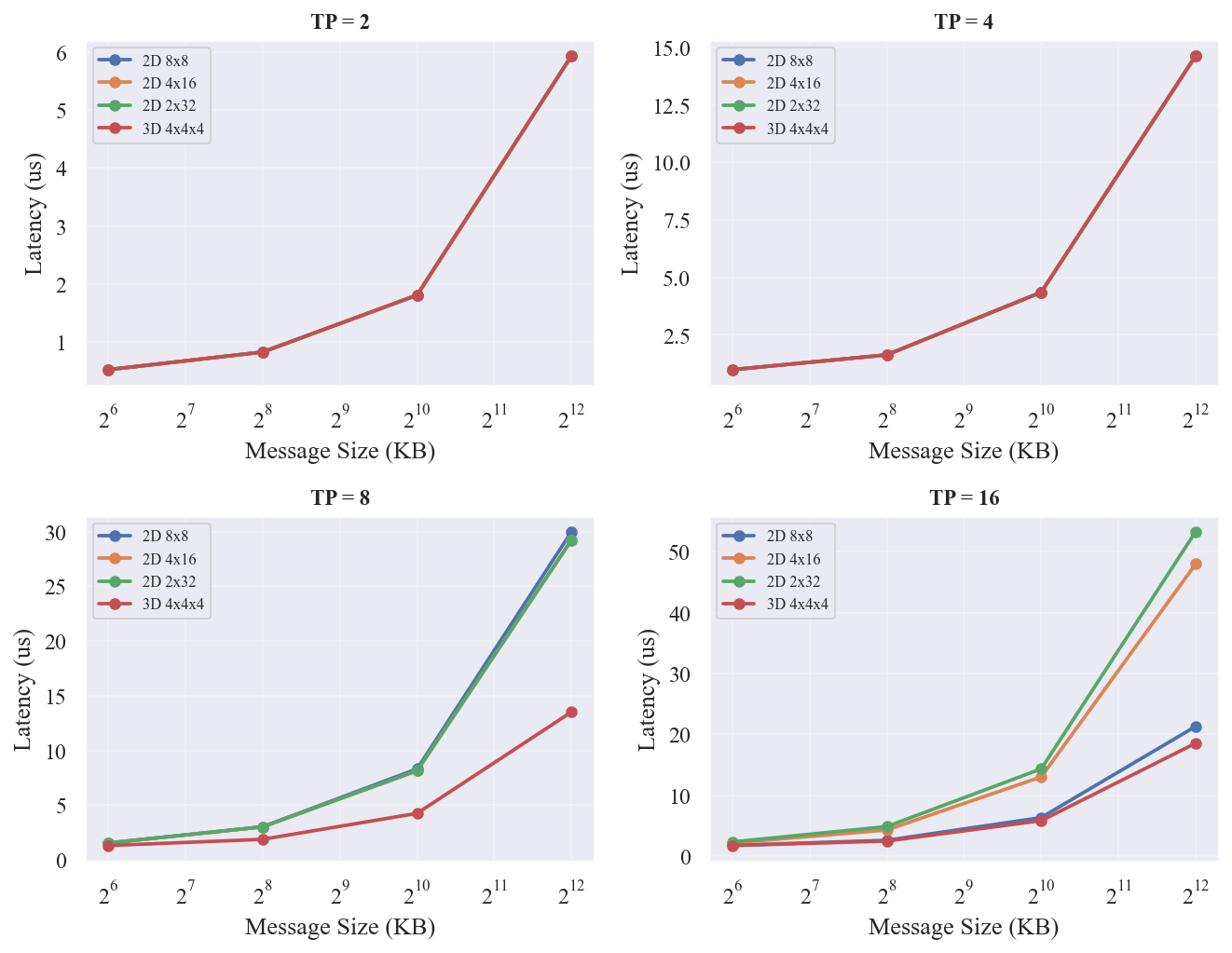
DBT 慢了 20%(8x8 -> 4x16),RH 慢了 131%。长方形状的直径更大(4x16 最大跳数=2+8=10 vs 8x8 最大跳数=4+4=8),tree 和 halving 的非相邻通信路径更长。RH 受影响远大于 DBT,因为 halving 的最后几步在长维上必须跨更多链路。 展示了 RH 在不同 Torus 形状上随消息大小变化的延迟曲线(2x32 无 RH 数据)。
2D vs 3D
3D-4x4x4 相比 2D-8x8,每个节点有 6 个邻居(vs 4 个),最大跳数为 2+2+2=6(vs 4+4=8),连接度更高、直径更小。
| 形状 | 组大小=4 | 组大小=8 | 组大小=16 |
|---|---|---|---|
| 2D-8x8 | 2-port 4.70 / HD 5.20 / DBT 8.68 | 2-port 5.95 / HD 7.50 / DBT 14.17 | HD 7.56 / 2-port 9.60 / DBT 14.17 |
| 3D-4x4x4 | 2-port 4.13 / HD 5.93 / DBT 5.93 | DBT 5.96 / HD 6.26 / 2-port 6.34 | HD 7.12 / DBT 8.51 / 2-port 9.54 |
@tbl-torus-2d-vs-3d-ar AllReduce 1MB 2D-8x8 vs 3D-4x4x4 各算法延迟对比 (us)
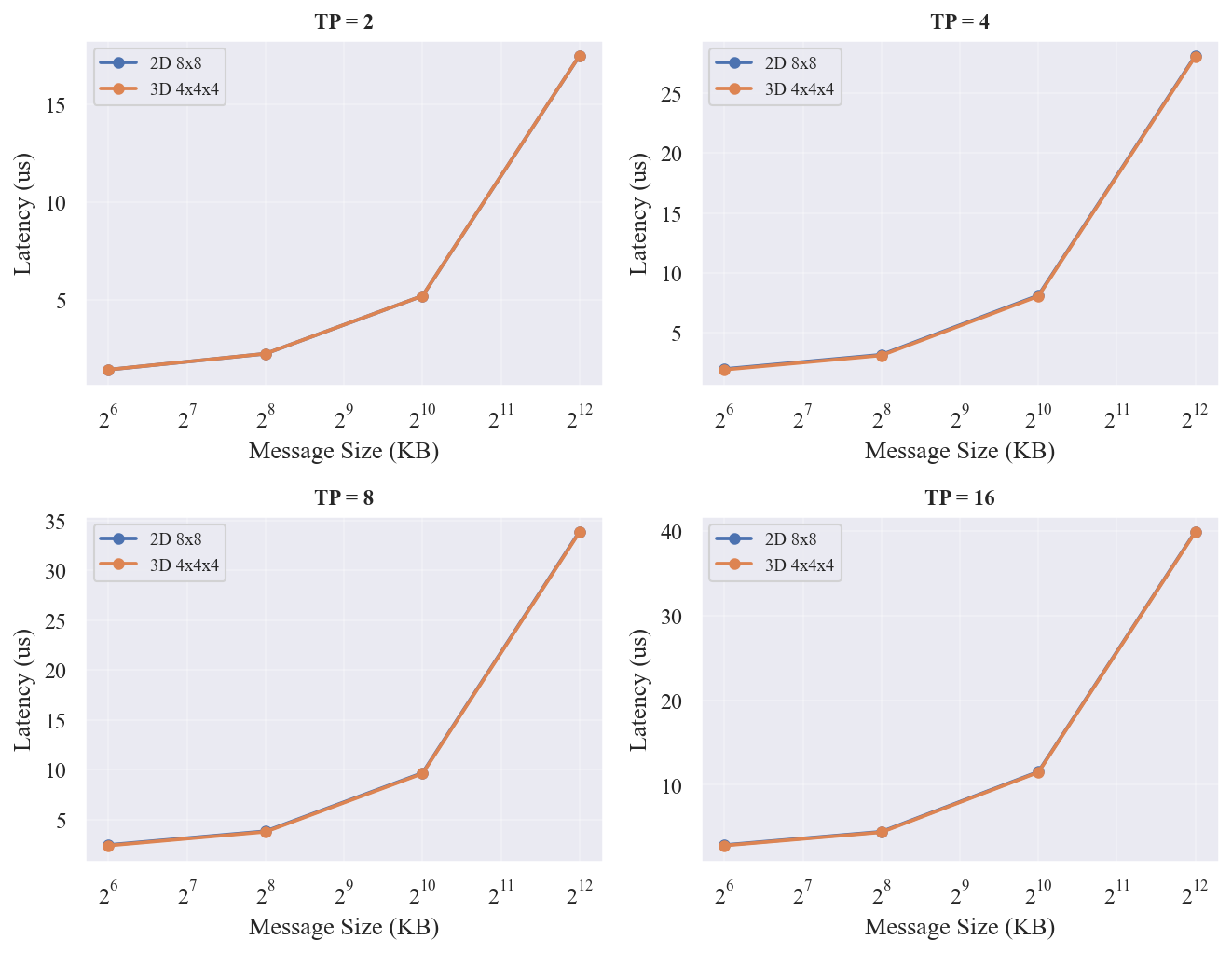
组大小=4 时差异很小(2-port 在两种形状上分别 4.70 vs 4.13,3D 快 14%)。组大小>=8 时 3D 的 DBT 显著受益(n=8 时 3D DBT 5.96 vs 2D DBT 14.17,快 2.4 倍;n=16 时 3D DBT 8.51 vs 2D DBT 14.17,快 66%),因为 tree 的非相邻节点在 3D 上平均路径更短。n=16 时两种拓扑的最优都是 HD(2D 7.56 us vs 3D 7.12 us,3D 快 6%)。
AllGather 1MB 的 Recursive Doubling 对比见 :
| 形状 | 组大小=8 RD | 组大小=16 RD |
|---|---|---|
| 2D-8x8 | 7.44 | 4.08 |
| 3D-4x4x4 | 3.20 | 4.84 |
@tbl-torus-2d-vs-3d-ag AllGather 1MB 2D vs 3D Recursive Doubling 延迟对比 (us)
3D 在组大小=8 时 RD 快 133%(3.20 vs 7.44,因为 RD 在 2D-8x8 上 n=8 跨行通信路径长),组大小=16 时反而 2D 略快 19%(2D 4.08 vs 3D 4.84,因为 n=16 在 8x8 上是连续两行 16 芯片,每步路径短)。 展示了 DBT 在两种拓扑上随消息大小变化的延迟曲线,3D 在中大组大小时优势明显。
算法对比
以下以 2D-8x8 为基准形状分析。对 3D 差异显著的场景单独标注。
AllReduce
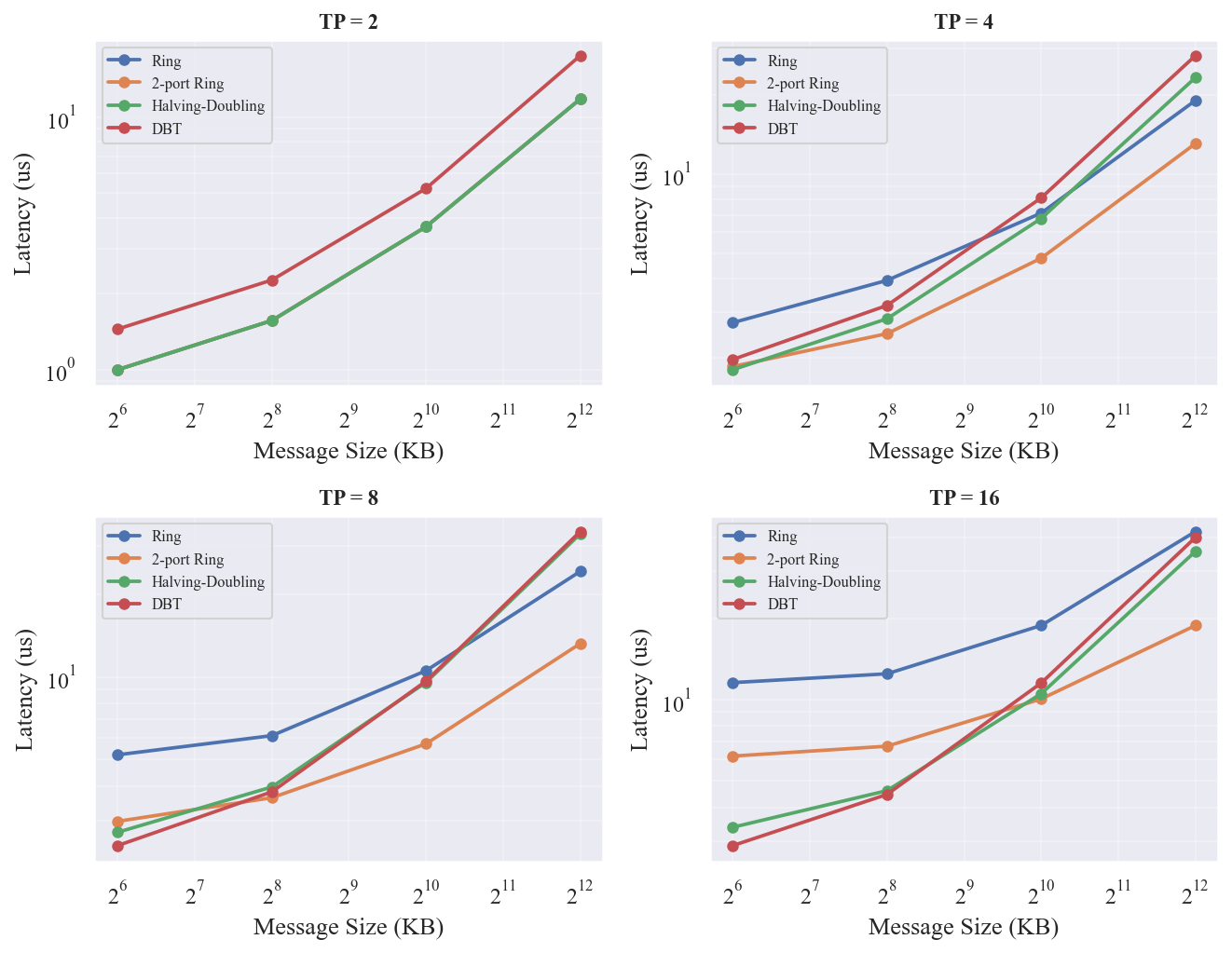
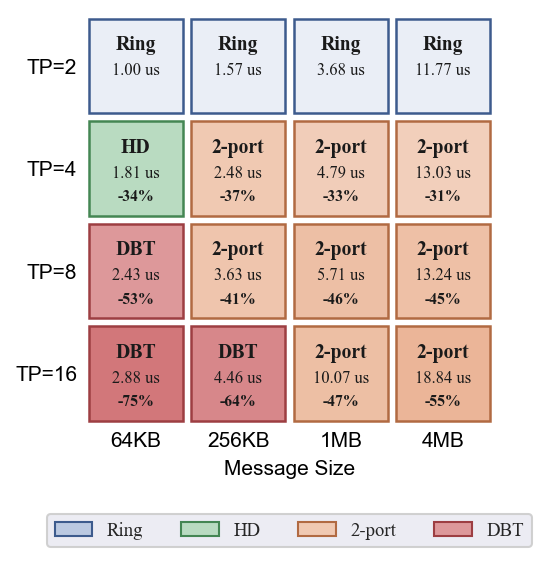
展示了四种 AllReduce 算法在不同组大小和消息大小下的延迟曲线, 汇总了各 (组大小,消息大小) 组合下的最优算法及其相对 Ring 的加速幅度。
- 组大小=2 时所有算法退化为单步通信,结果一致
- HD 在中大消息 + 大组大小时是最优选择:组大小=16、1MB 时比 Ring 快 137%(Ring 17.91 vs HD 7.56),组大小=16、256KB 时比 Ring 快 245%(Ring 12.53 vs HD 3.63)
- DBT 在小消息(64KB)+ 大组大小时占优:组大小=16、64KB 时比 Ring 快 580%(Ring 11.58 vs DBT 1.70),但在 2D 上中大消息(>=1MB)退化严重(n=16 1MB 时 DBT 14.17 vs HD 7.56,慢 87%)
- 2-port Ring 在中等组大小(4~8)+ 中大消息时是稳健选择:组大小=8、1MB 时比 Ring 快 88%(Ring 11.20 vs 2-port 5.95),组大小=8、64KB 时比 Ring 快 75%(5.26 vs 3.00)
- DBT 在 3D-4x4x4 上组大小=8、1MB 时成为最优(5.96 us vs 2D 上 DBT 14.17 us,快 2.4 倍),受益于更短的 tree 路径;但组大小=16 时 3D 上 HD 反超 DBT(7.12 vs 8.51)
AllGather
展示了三种 AllGather 算法的延迟曲线, 汇总最优算法。
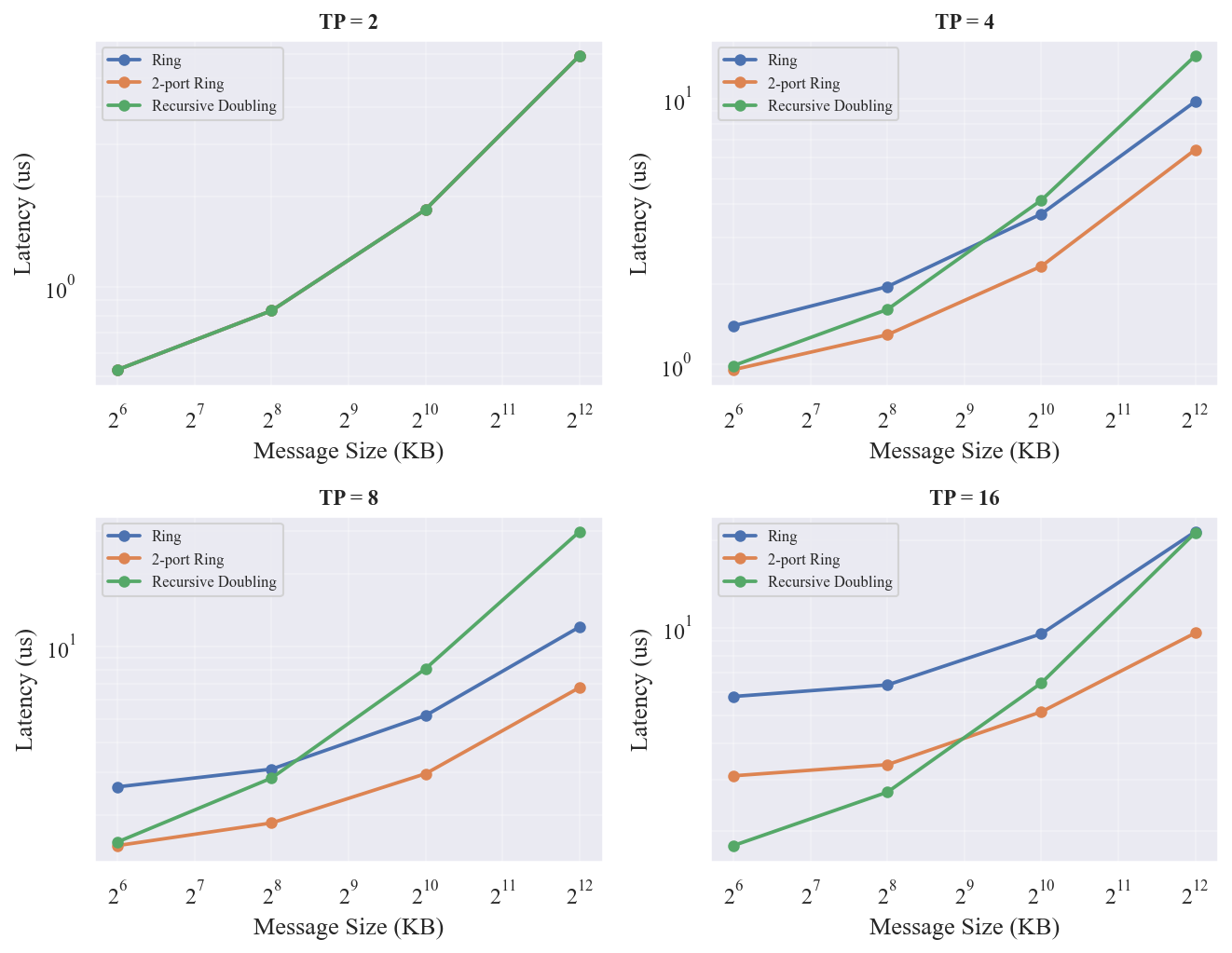
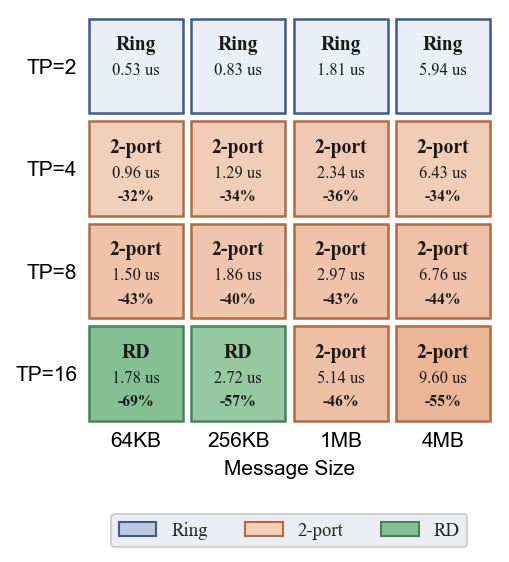
- RD 在组大小=16 时全面占优:1MB 时比 Ring 快 125%(Ring 9.19 vs RD 4.08),64KB 时比 Ring 快 291%(Ring 5.81 vs RD 1.48)
- 2-port Ring 在中等组大小(4~8)+ 中大消息时占优:组大小=8、1MB 时比 Ring 快 85%(Ring 5.58 vs 2-port 3.02),组大小=8、256KB 时比 Ring 快 82%(3.35 vs 1.84)
- n=8 时 RD 受拓扑影响显著:2D-8x8 上 n=8、1MB 时 RD 反而比 Ring 慢(7.44 vs 5.58),需 2-port Ring 才胜出;3D-4x4x4 上 n=8、1MB RD 仅 3.20 us,是 2D 的 2.3 倍速度
- RD 的对数步数优势在组大小增大时非常显著(16 芯片仅需 4 步 vs Ring 的 15 步)
ReduceScatter
展示了三种 ReduceScatter 算法的延迟曲线, 汇总最优算法。
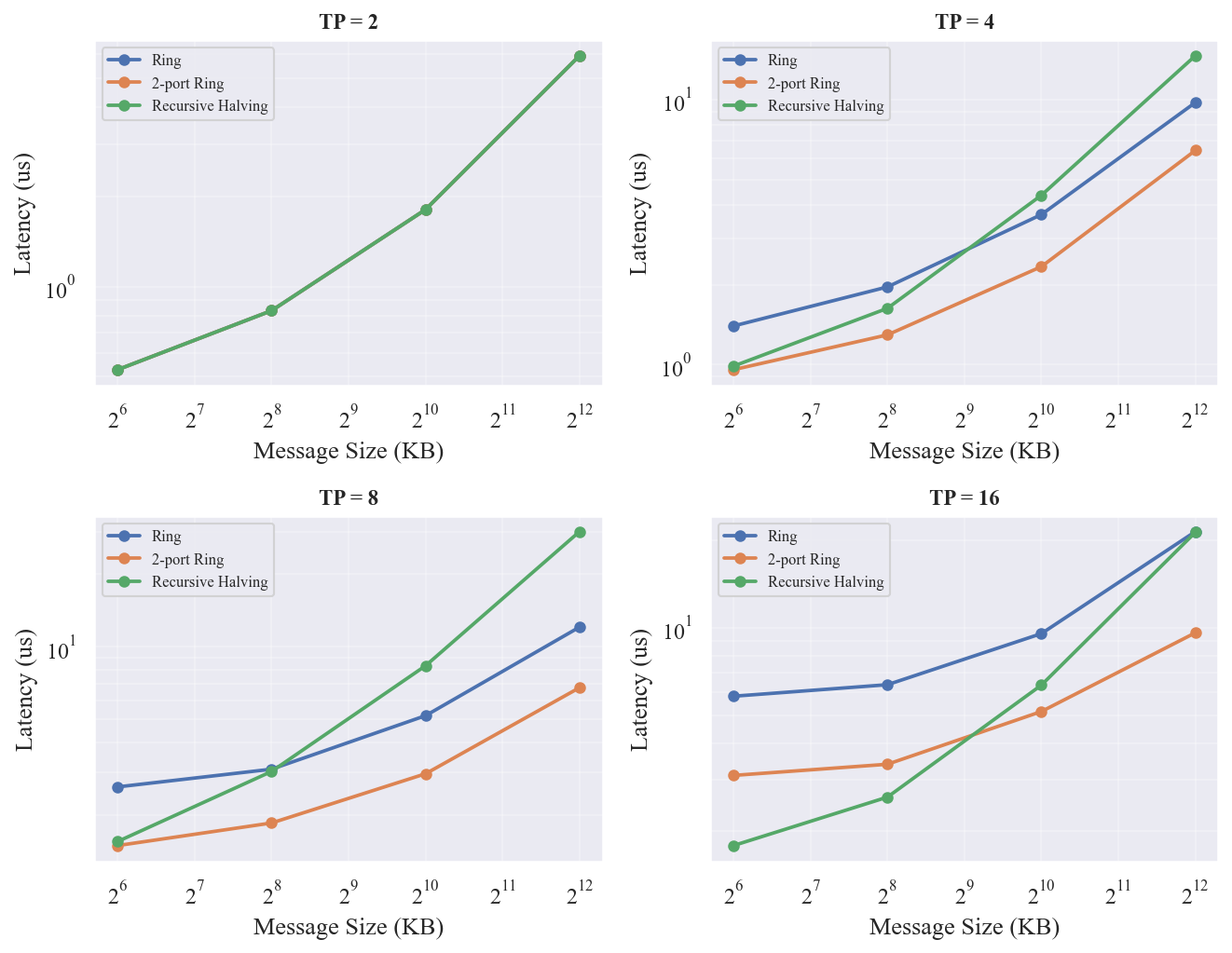
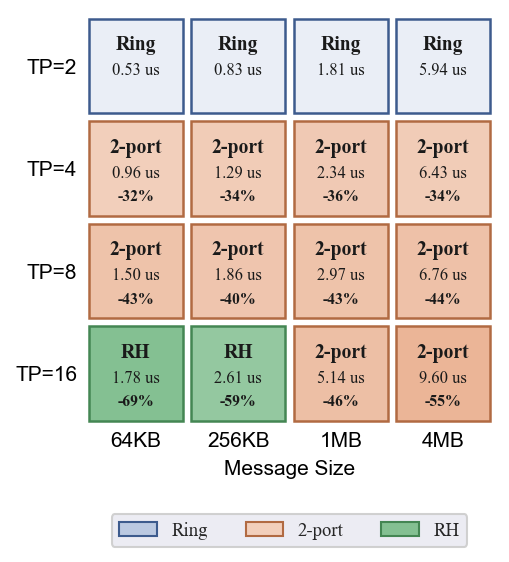
- RH 在组大小=16 时全面占优:1MB 时比 Ring 快 89%(Ring 9.19 vs RH 4.86),64KB 时比 Ring 快 329%(Ring 5.81 vs RH 1.35)
- 2-port Ring 在组大小=8 时是中大消息的稳健选择:n=8、1MB 时 2-port 3.02 us 反超 RH 6.94 us(RH 在小组大小 + 大消息时退化),n=8、64KB 则 RH 最优(1.06 us vs 2-port 1.51 us)
- RH 对拓扑形状敏感:在 2D-4x16 上组大小=16、1MB 时退化到 11.24 us(8x8 上 4.86 us,慢 131%),2D-2x32 不支持 RH(dim<=2),在 3D-4x4x4 上表现最好(3.85 us,比 8x8 快 26%)
- n=16 + 1MB 时 RH 也明显胜过 2-port(4.86 vs 4.92 us 接近,但 64KB/256KB 时 RH 大幅领先 2-port)
路由算法
对 2D-8x8 和 3D-4x4x4 分别用 shortest_path 和 DOR 路由跑 AllReduce,覆盖组大小 {8, 16, 32, 64} × 消息大小 {64KB, 256KB, 1MB, 4MB} × 算法 {Ring, 2-port Ring, HD},共 96 个对比点。总体统计见 。
| DOR/SP 延迟比 | 数量 | 占比 |
|---|---|---|
| ~1.00(完全相同) | 90 | 93.8% |
| 0.91 ~ 0.99(DOR 略快) | 6 | 6.2% |
| < 0.91 | 0 | 0% |
@tbl-torus-routing-summary shortest_path vs DOR 路由 96 个对比点统计
出现差异的 6 个点均为 HD 算法 + 4MB 大消息场景,详见 。
| 拓扑 | 组大小 | SP 延迟 (us) | DOR 延迟 (us) | DOR/SP |
|---|---|---|---|---|
| 2D-8x8 | 8 | 31.94 | 29.19 | 0.914 |
| 2D-8x8 | 16 | 25.10 | 23.04 | 0.918 |
| 2D-8x8 | 32 | 21.66 | 21.22 | 0.979 |
| 3D-4x4x4 | 8 | 25.63 | 23.71 | 0.925 |
| 3D-4x4x4 | 16 | 20.25 | 20.11 | 0.993 |
| 3D-4x4x4 | 32 | 40.38 | 40.07 | 0.992 |
@tbl-torus-routing-diff DOR vs shortest_path 差异点详情 (AllReduce, 4MB)
HD 在大消息下涉及多组 power-of-2 配对同时通信,DOR 的确定性路径选择在多流竞争时路径冲突略少。但最大差异仅 8.6%,且仅出现在 4MB 场景。其余 90 个对比点(含 Ring、2-port Ring 以及所有 <=1MB 的 HD 场景)延迟完全一致。
在均匀带宽的 Torus 上,shortest_path (Dijkstra) 选出的最短路径和 DOR 的维序路径跳数相同,因此绝大多数场景下两种路由无性能差异。
EP AllToAll 评估
EP 通信的评估方法和局限说明参见 TPS186 评估方法说明。
| 维度 | 范围 |
|---|---|
| 通信组大小 | 32, 64 |
| 消息大小 | 256KB, 512KB, 1MB, 2MB, 4MB |
| 算法 | Pairwise, Bruck |
| 拓扑 | 2D-8x8, 2D-4x16, 2D-2x32, 3D-4x4x4 |
@tbl-torus-ep-config EP AllToAll 评估配置
EP=64
展示了 Pairwise 和 Bruck 在 4 种 Torus 形状上的延迟曲线。Pairwise 延迟随拓扑形状差异显著(2D-2x32 比 3D-4x4x4 慢约 2 倍),而 Bruck 的延迟在所有形状上几乎一致。
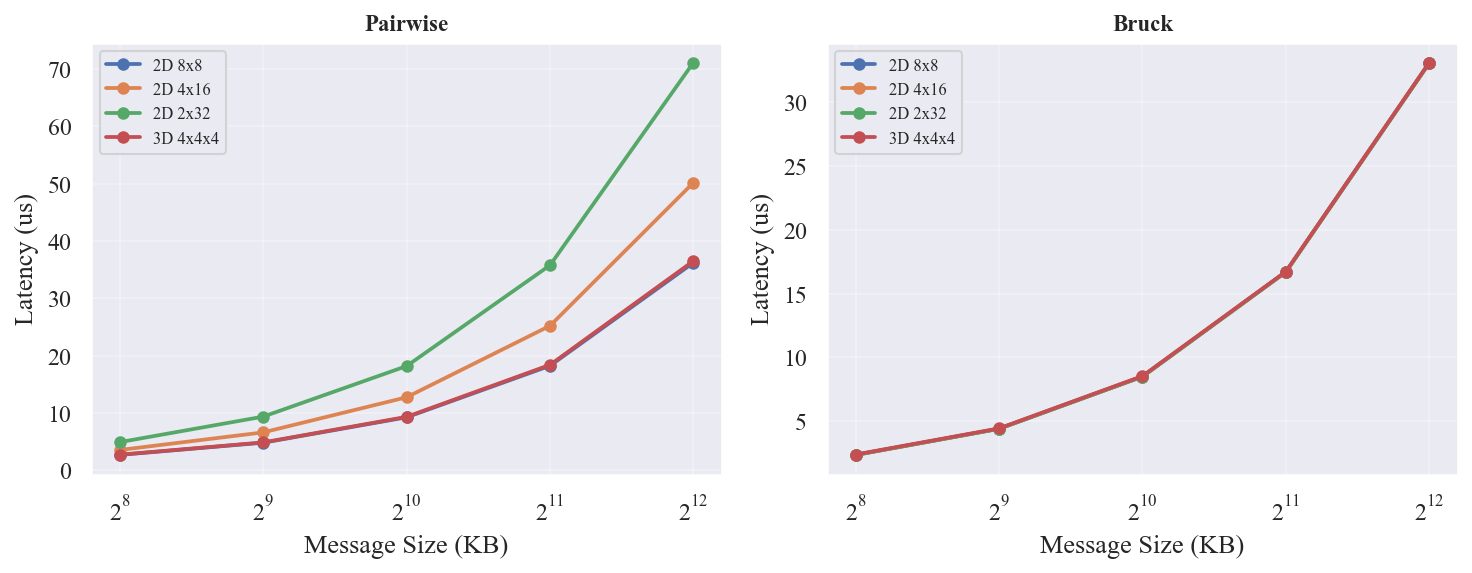
汇总各 (拓扑,消息大小) 下的最优算法。EP=64 时 Bruck 在所有配置下均优于 Pairwise。
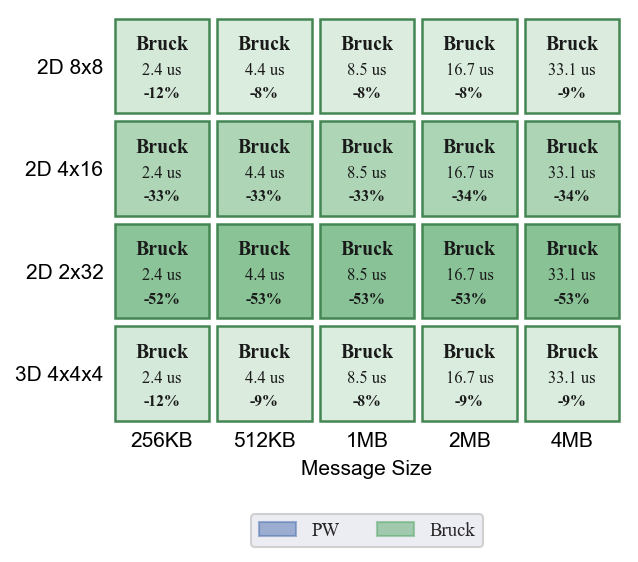
- Bruck 全胜:EP=64(N=64,log2=6 步 vs Pairwise 63 步),Bruck 在所有拓扑和消息大小下均更快
- 形状敏感性差异极大:Pairwise 在 2D-2x32 上 4MB 延迟 71 us,在 3D 上 37 us(差 1.9 倍);Bruck 在所有形状上 ~33 us(差异 <1%)
- 细长形状优势最大:2D-2x32 上 Bruck 快 53%,2D-4x16 快 34%,8x8/3D 快 8-12%
Bruck 拓扑不敏感性分析:Bruck 在 4 种形状上延迟差异 <1%(如 4MB 时 8x8 = 33.07 us, 2x32 = 33.07 us, 3D = 33.10 us)。P2P 单传输验证显示跳数差异确实影响延迟(chip 0→16:8x8 2 跳 0.58 us vs 2x32 16 跳 1.31 us),但 Bruck 每步 64 路并发 transfer 的链路竞争和步间依赖使拓扑差异被抹平。Bruck 每步传输量大(~2MB),CDMA 注入时间(~5 us)远大于跳数差异带来的路由延迟(<0.5 us),传输时间主导了每步延迟。
EP=32
展示了 EP=32 的延迟曲线。与 EP=64 相同,Bruck 曲线在所有形状上完全重叠(差异 <1%),而 Pairwise 曲线随形状发散——但 3D-4x4x4 上 Pairwise 比 Bruck 更快。
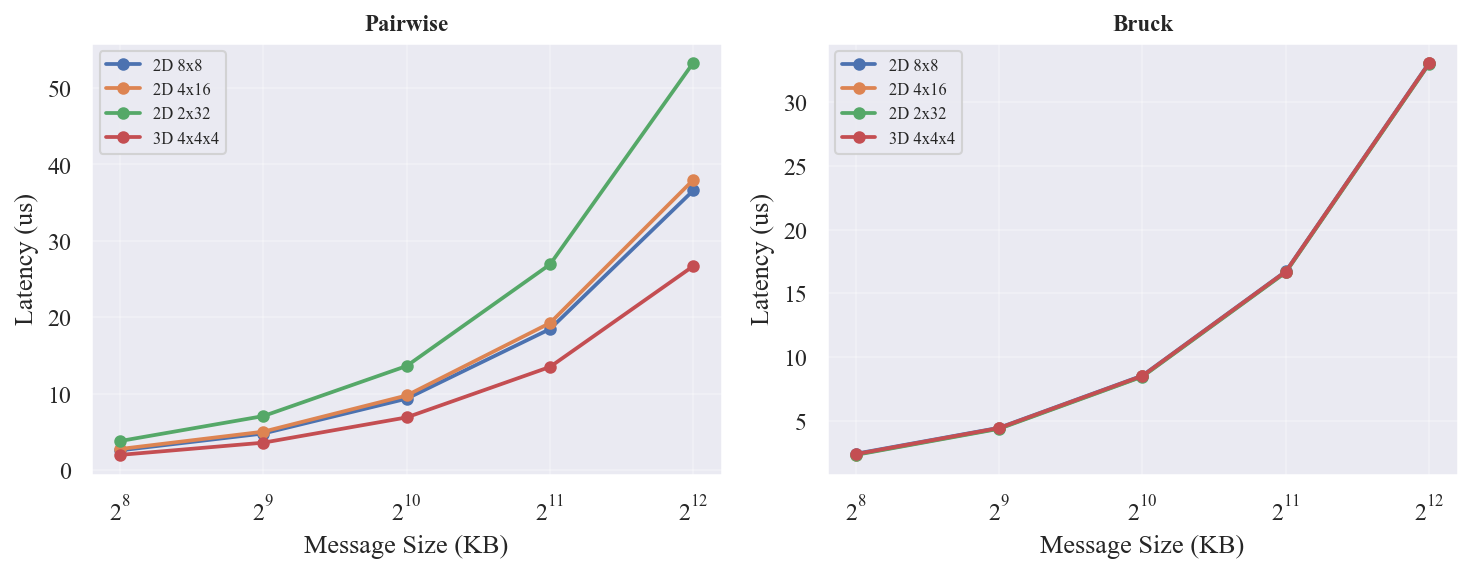
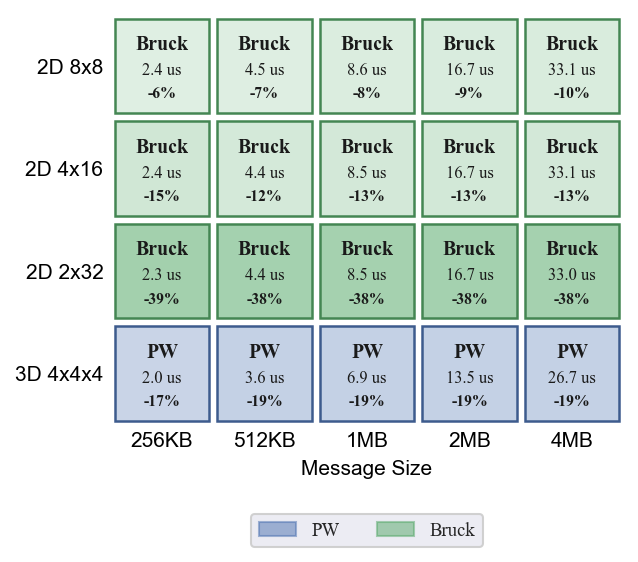
EP=32 时(N=32,log2=5 步 vs Pairwise 31 步),结论不同于 EP=64:
- 2D 上 Bruck 仍然占优:8x8 快 6-10%,4x16 快 12-15%,2x32 快 38-39%
- 3D-4x4x4 上 Pairwise 反超:Pairwise 快 17-19%。3D 的短直径(最大跳数 6)让 Pairwise 31 步中的多跳开销很小,而 Bruck 5 步中每步的冗余带宽(约 N/2 倍数据量)成为负担
结论
算法选择推荐
综合 TP 和 EP 分析,各原语的推荐算法见 。TP 详细分布参见汇总图(、、),EP 参见 和 。
| 原语 | 2D Torus 推荐 | 3D Torus 推荐 |
|---|---|---|
| AllReduce (TP) | 小消息:2-port/DBT;中大消息:HD | 组大小>=8 时 DBT 全消息最优 |
| AllGather (TP) | 小消息:2-port;中大消息+组大小>=16: RD | 无显著差异 |
| ReduceScatter (TP) | 组大小=8: 2-port;组大小>=16: RH | RH 在 3D 上更稳定 |
| AllToAll (EP=64) | Bruck(全消息,快 8-53%) | Bruck(快 8-12%) |
| AllToAll (EP=32) | Bruck(2D,快 6-39%) | Pairwise(3D,快 17-19%) |
@tbl-torus-algo-recommend Torus 各原语算法选择推荐
形状选择
TP 通信:
- 2D 纵横比影响很小:Ring/2-port/HD/RD 完全不受纵横比影响()
- 但 DBT 和 RH 对细长形状敏感:应避免 2x32 这类极端纵横比(、)
- 3D 优于 2D:更高的连接度让 log 算法(特别是 DBT)显著受益()
EP 通信: