32 芯片拓扑通信评估报告 v1
生成时间: 2026-04-20 13:53 UTC
摘要
本报告基于 G5 指令级仿真,评估 10 个候选拓扑在 3 种通信原语 (allgather, allreduce, alltoall)下,跨 5 档消息大小的性能。
- 总 cells:450(成功 450,失败 0)
- 拓扑:P1-R1-B4-C32, clos-2tier-32, dragonfly-4group-32, fat-tree-32, full-mesh-32, hypercube-5d-32, mesh-4x8-32, ring-32, single-switch-32, torus-2x4x4-32
- 消息大小:4096 ~ 268435456 bytes
端到端关键发现
- CDMA 是主要瓶颈(非 link 带宽):在当前 SG2262 配置(8 CDMA/chip × 64 GB/s ≈ 512 Gbps 聚合)下, c2c link 带宽从 200 到 800 Gbps 变化几乎不影响 BusBW(差异 < 0.02%)。 这意味着增加 link 带宽不会带来性能收益,除非同时提升芯片端 CDMA 能力。
- 拓扑对直连型拓扑影响小、对交换机型拓扑影响大:Ring/FullMesh/HyperCube/Torus/DragonFly 在 AllReduce 256MB 下 BusBW 均为 ~58.4 GB/s(CDMA 饱和);但 Clos-2tier 和 FatTree 因为 经过交换机额外 hop 延迟,降到 ~35.7 GB/s(约 -39%)。
- AllGather 可达 128.2 GB/s,接近 CDMA 聚合上限;AllReduce 因 2(N-1) 串行化受限在 ~58 GB/s; All2All 由于全互通模式约为 62 GB/s。
评估方法
- 评估对象:通信原语(不绑 LLM workload)
- 仿真引擎:G5 (Rust 指令级事件驱动)
- 变量空间:拓扑 × c2c 带宽 × switch port 带宽 × 原语 × 消息大小
结果
图 1:BusBW 热力图(拓扑 × 带宽)
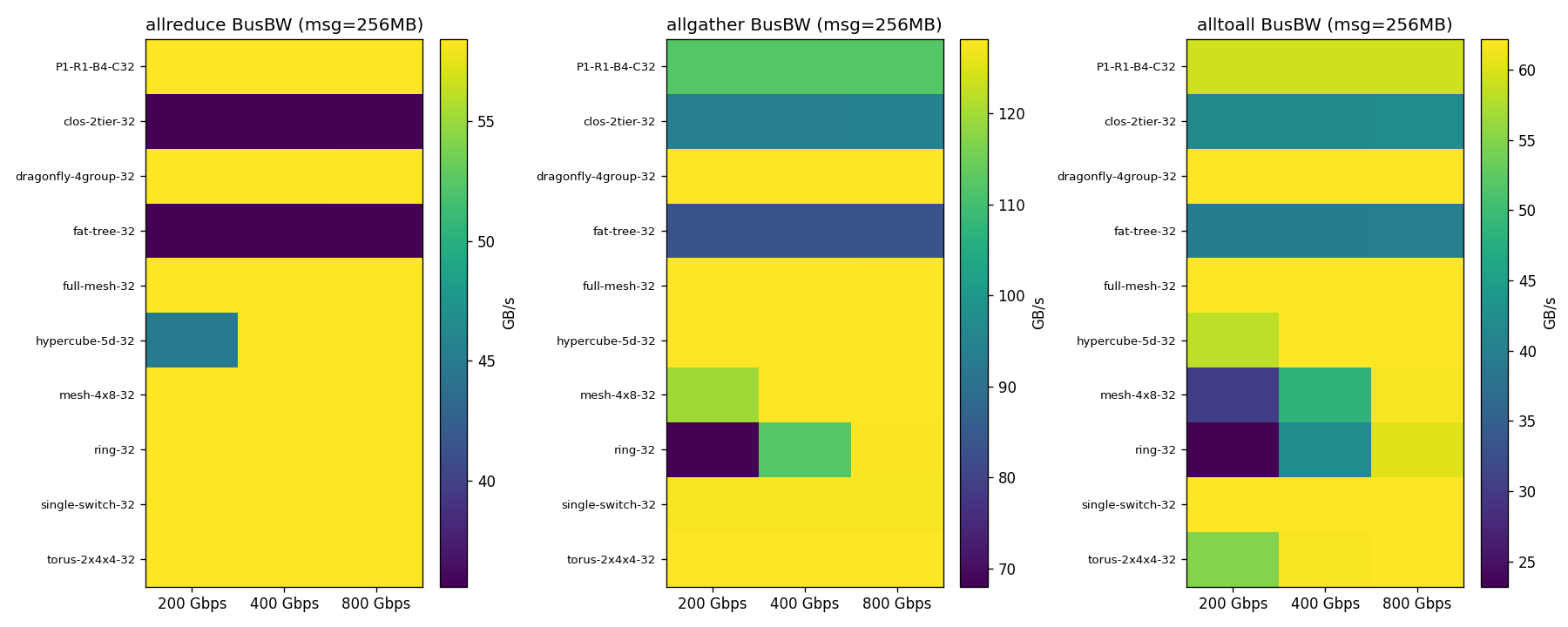
图 2:消息大小 → 延迟曲线
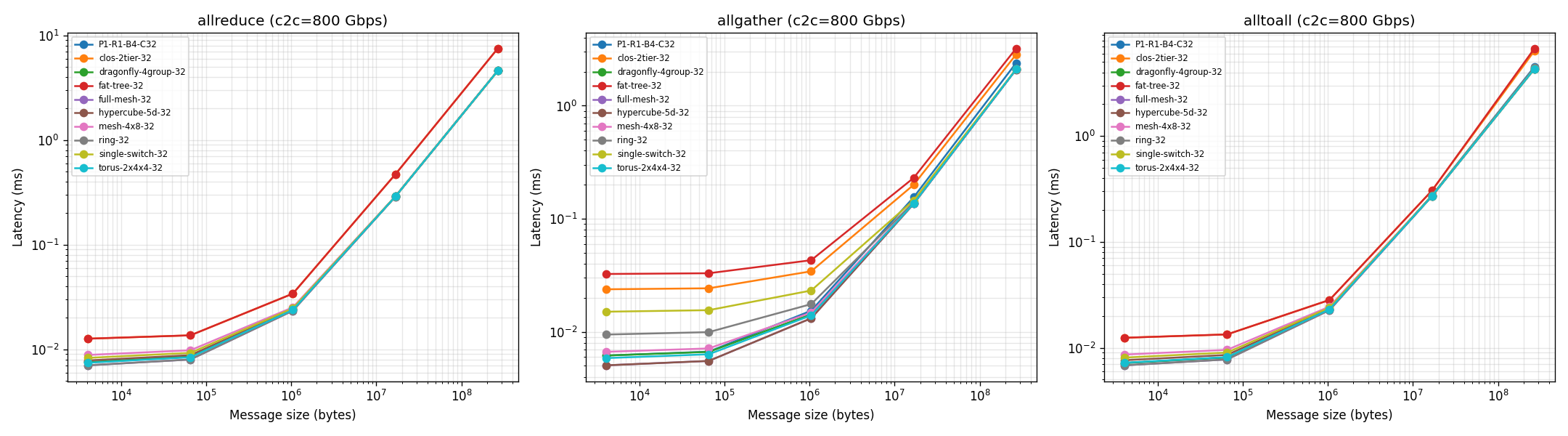
图 3:拓扑对比柱状图
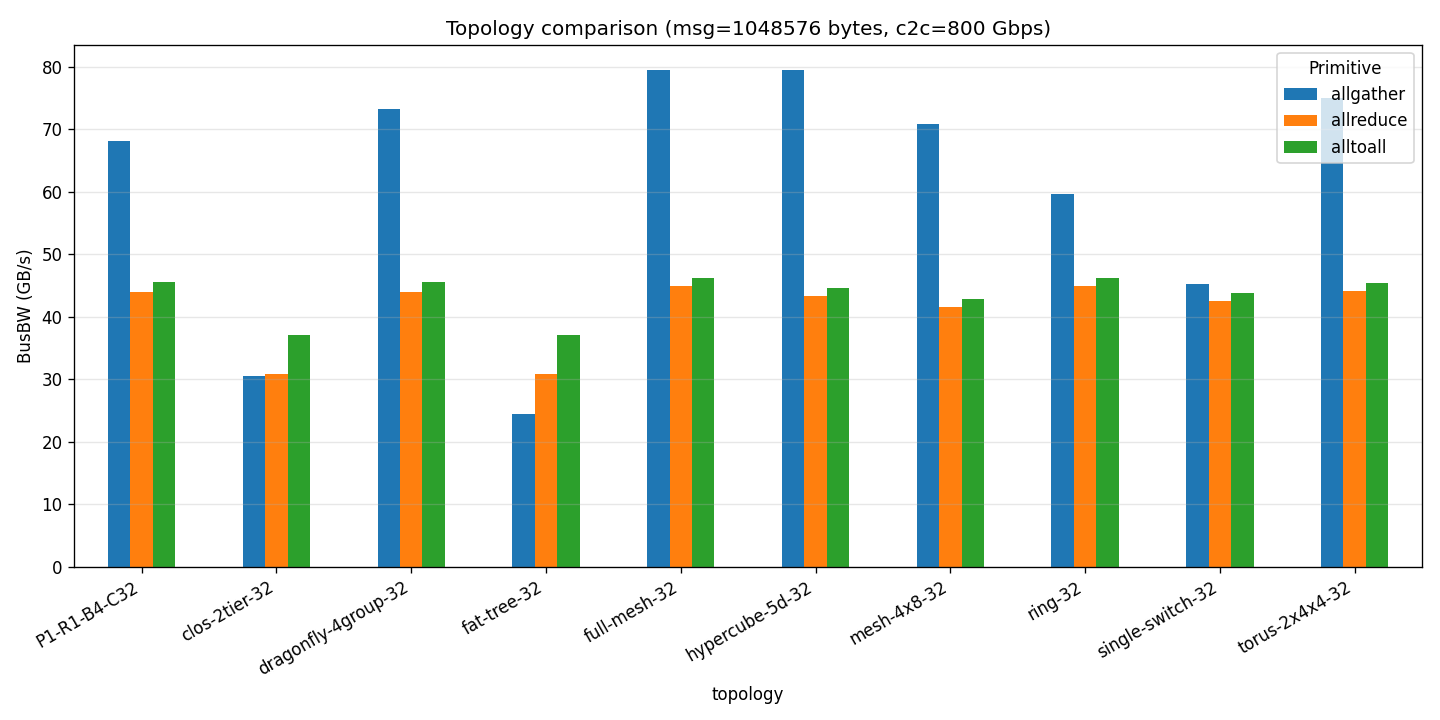
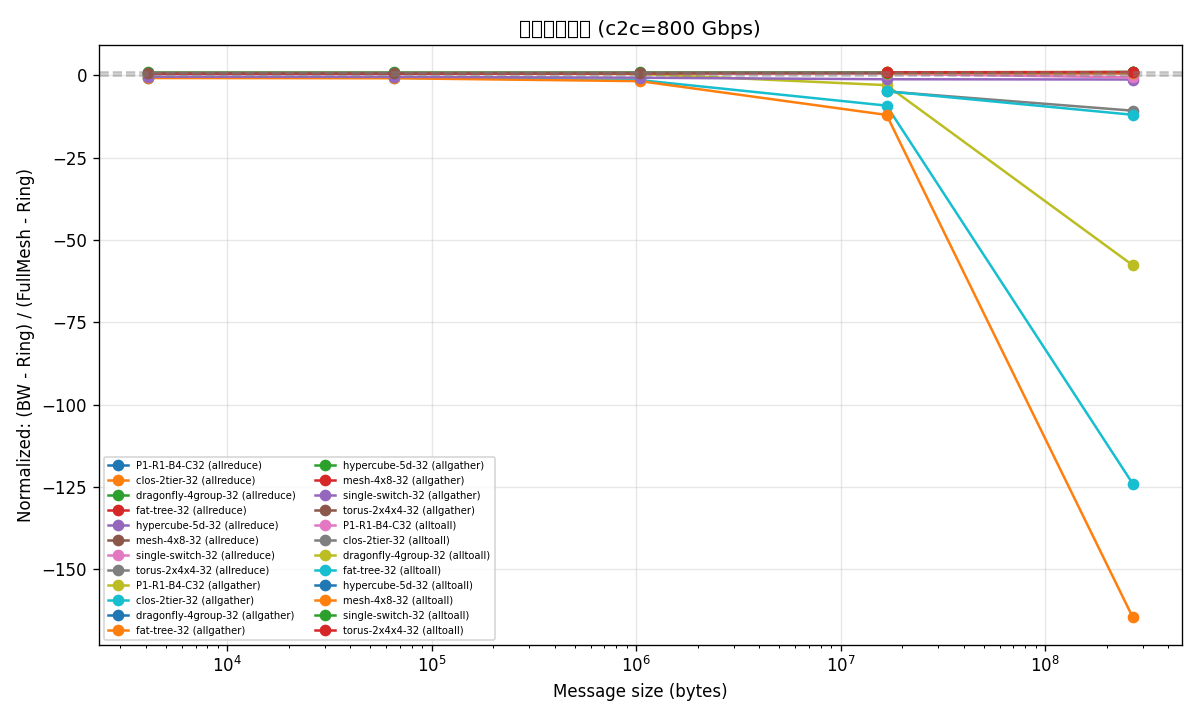
图 4:上下界归一化(Ring=0, FullMesh=1)
Top-3 推荐(最大消息 + 最高带宽下)
| 原语 | 排名 | 拓扑 | BusBW |
|---|---|---|---|
| allgather | 1 | hypercube-5d-32 | 128.2 GB/s |
| allgather | 2 | full-mesh-32 | 128.2 GB/s |
| allgather | 3 | torus-2x4x4-32 | 128.1 GB/s |
| allreduce | 1 | ring-32 | 58.4 GB/s |
| allreduce | 2 | full-mesh-32 | 58.4 GB/s |
| allreduce | 3 | torus-2x4x4-32 | 58.4 GB/s |
| alltoall | 1 | full-mesh-32 | 62.2 GB/s |
| alltoall | 2 | dragonfly-4group-32 | 62.2 GB/s |
| alltoall | 3 | torus-2x4x4-32 | 62.2 GB/s |
已知局限
- 成本函数未改造:当前
cost_analysis.py不区分拓扑结构(交换机数 / link 数 / 介质), 本报告未包含成本结论。Phase 3 将补充。 - c2c bandwidth sweep 无明显区分效果:在 SG2262 配置下 CDMA 是瓶颈,link 带宽变化几乎无差异
(见"端到端关键发现 #1")。若想看到 link 带宽效果,需要同时扫描 CDMA 参数(
bandwidth_per_cdma_gbps和cdmas_per_die),或换用更高算力的芯片预设。 - 未扫描 L3 Switch 内部参数(buffer / ECN 阈值 / iSLIP 迭代)和 L4 PAXI 参数 (OST / credit / DCQCN)。这些细节参数的敏感性留待后续阶段。
- 部分拓扑(如 FullMesh-32 共 496 link)的物理可实现性不在本评估范围。
- 图表中部分中文 label 可能因 matplotlib 默认字体 (DejaVu Sans) 不支持 CJK 而显示为方框;
不影响数据,可通过安装中文字体(如
Noto Sans CJK)修复。
附录:完整数据
完整 cell 数据见 results.parquet。