MoE EP alltoallv 拓扑与路由的性能评估:实验设计
日期:2026-05-29 状态:实验设计草案,待用户审定后冻结 + 跑数据 Spec 依据:无(validation 研究,从 discuss 派生)
名词定义
仅解释跨领域既有专业名词;本研究自己引入的命名(形态档位、摆放策略等)在对应章节首次出现时就地说明。
| 名词 | 含义 |
|---|---|
| TP / EP / DP / PP | 把大模型拆到多张芯片上的四种并行方式;EP 是把 MoE 的「专家」分散到不同芯片 |
| EP group / EP rank | 一起完成同一次专家数据交换的一组芯片 / 组内某张芯片的编号 |
| expert / top_k | MoE 里的小专家网络 / 每个词元会用到的专家个数(V4-Pro 用 6 个) |
| dispatch / combine | 把词元发给它要用的专家(去程交换)/ 专家算完把结果发回来(回程交换) |
| EPLB | 专家负载均衡:把热门专家复制几份分散到多张芯片,避免某张芯片接收过载 |
| Zipf 分布 | 「少数热门专家被分到大部分词元」的长尾负载分布;本研究用它生成不均衡负载,偏度按实测 max/mean 反解,不主张真实负载就是 Zipf |
| alltoallv | 所有芯片互相发数据,且每对芯片之间发的量可以不一样 |
| incast | 多张芯片同时向同一张芯片发送,使它的接收口过载 |
| BusBW(本研究口径) | 平均每张芯片每秒发出的字节数 $=\sum C[i][j]/(N\cdot T)$(与 NCCL 的 busBw 定义不同,不要混用) |
| line rate | 一条链路每秒最多能传的字节数(SG2262 单向 400 GB/s) |
| alpha-bound / bandwidth-bound | 数据量小时,时间主要花在「启动 + 跳数」上 / 数据量大时,主要受带宽限制 |
| c2c / PAXI / LG | 芯片之间直连 / SG2262 的传输层 / 它的链路分组(8 组 × 50 = 400 GB/s) |
| chip_radix / cpb | 一张芯片对外有几个直连口 / 一块板上有几张芯片 |
| SP / ECMP / dmodk / DOR / UGAL | 五种路由算法:最短路 / 等价多路分流 / 公式均布 / 按维度顺序 / 自适应绕路 |
| 计算-通信重叠 | 通信与计算并行进行,把通信时间隐藏在计算时间内;只要通信比计算短,端到端就不为通信额外等待(V4 的 wave 调度做法详见 2.6 V4 对通信的新需求) |
| 算力-带宽比 | 芯片峰值算力 ÷ 互联带宽(FLOPs/Byte);与每对收发的「计算量 ÷ 通信量」比较,决定通信能否被计算隐藏 |
| 哈希路由 (hash routing) | 按词元 ID 的固定哈希函数分配专家,不学习;负载天然均匀(Roller 等,2021) |
| 亲和度分数 (routing affinity) | 路由网络给「词元-专家」打的匹配分,决定词元选哪些专家;V4 把它的激活函数从 Sigmoid 改为 Sqrt(Softplus) |
| Anticipatory Routing | V4 用历史参数解耦主干与路由网络的更新,抑制训练尖峰 |
@tbl-a2av-terms 名词定义
研究背景与定位
本研究量化 EP alltoallv 的通信时间如何随拓扑、路由、专家摆放、负载偏度、数据量变化,并据此判断通信在什么条件下成为端到端的瓶颈。
EP alltoallv 的通信时间由两层因素决定,是否构成端到端瓶颈取决于能否被计算隐藏:
- 通信对带宽提出要求:EP alltoallv 的去程、回程数据交换占用互联带宽,是 MoE 推理的主要通信开销。
- V4 用计算重叠隐藏通信:V4 系列将去程、回程通信与专家计算重叠,把通信时间隐藏在计算时间内(见 2.6 V4 对通信的新需求)。
- 能否隐藏取决于两个量:算力-带宽比与通信耗时;通信耗时由拓扑、路由、专家摆放、负载偏度共同决定。
- 隐藏不等于不需优化:优化通信降低隐藏所需的带宽阈值、为重叠留出余量、使低带宽硬件也能实现重叠——这正是 V4 在更低互联带宽下维持端到端性能的目标(见 2.6 V4 对通信的新需求)。
当前缺三块数据,部署架构师据此无法量化选型:
- 拓扑选型无数据:fat-tree / torus / single-switch 在 32 / 64 芯片规模 EP alltoallv 上的相对优劣无公开实测。
- 路由与摆放选型无数据:各路由算法、专家小组的就近 / 散布摆放对通信时间的影响幅度未量化。
- 瓶颈区间无数据:在什么(数据量、带宽、拓扑)组合下通信会成为重叠的瓶颈,没有量化边界。
研究范围覆盖小数据量到大数据量全段,不预设只看某一阶段;数据按此框架增量补齐。两端的通信特征不同:小数据量(decode)与大数据量(prefill)的主要瓶颈、路由优化目标见下表。
| 维度 | Prefill(大数据量) | Decode(小数据量) |
|---|---|---|
| 每芯片词元数(LMSYS 实测) | 16384 | 128 - 256 |
| 关键瓶颈 | 带宽(大量词元竞争网络容量) | 启动开销(路径长度 + 交换机转发) |
| 路由优化价值 | 负载均衡 / 避免热点 | 最短跳数 / 减少跳数 |
| 开启 EPLB 收益(LMSYS 大规模 EP 部署实测) | 1.49× | 2.54× |
@tbl-a2av-decode-vs-prefill prefill / decode 的 EP alltoallv 通信特征差异
通信矩阵:定义与生成
本节定义通信矩阵 $C$ 的生成机制:词元路由与专家放置先决定小组内的逻辑矩阵 $L$,物理映射再把 $L$ 叠加成上网的物理矩阵 $C$。G5 仿真直接消费该矩阵的真实字节;给定一组参数,矩阵被唯一确定。
矩阵定义与热图约定
通信矩阵 $C$ 是 N×N 表,$C[i][j]$ = 芯片 $i$ 发给芯片 $j$ 的字节数。后续所有 N×N / EP×EP 热图都按以下约定读:
- 热图每格 = src→dst 芯片对发送字节
- 对数色阶:拉开低值、压缩高值,避免低值挤成一片、高值过饱和
- 灰色 = 无流量(块外组间不通信 + 对角本地)
- 顶部红条 = 每列接收量 ÷ 均值(RX,接收 incast 倍数)
- 左侧红条 = 每行发送量 ÷ 均值(TX,发送侧)
- 边际条与热图列 / 行严格对齐、按同色阶上色
专家小组范式
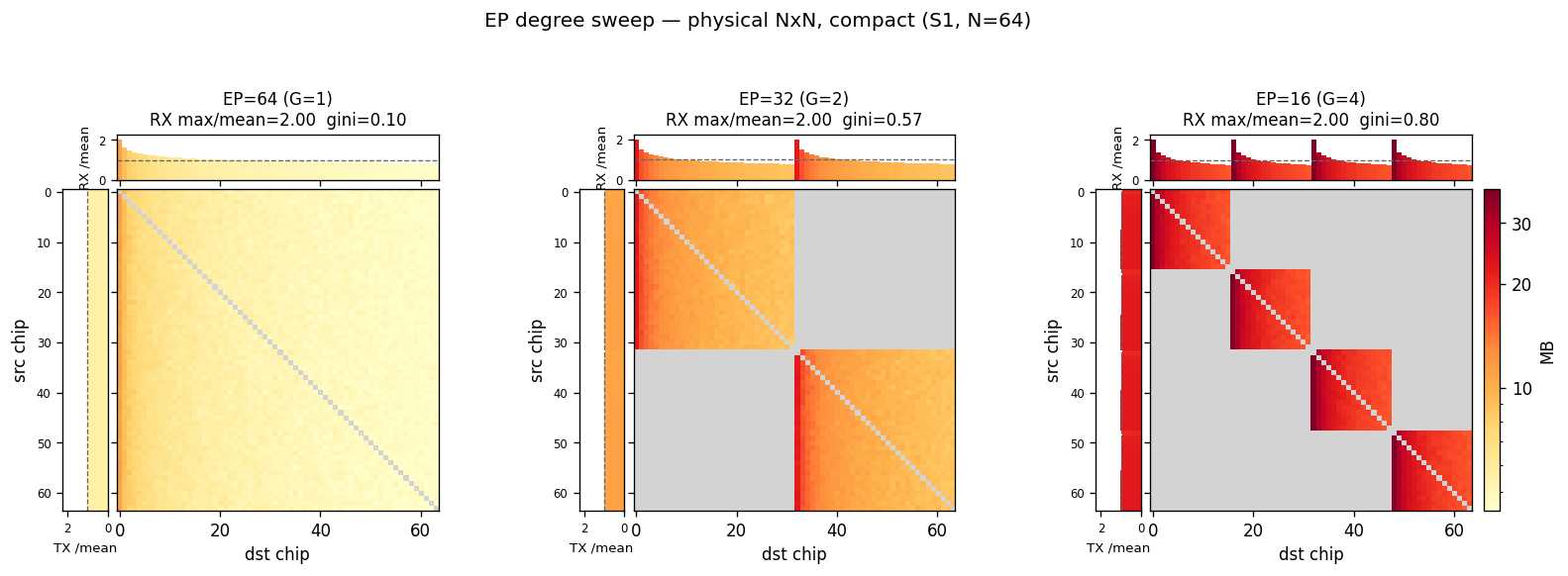
MoE 的数据交换只在「专家并行小组」(EP group)内部进行,不是全体芯片一起做。一个集群分成若干小组,每组在自己内部交换,多组并发、共享同一张物理网络竞争带宽。例:64 张芯片、EP=32 就是 2 个各 32 张的小组。
通信矩阵分两层生成:
- 小组内逻辑交换:一张 EP×EP 的表(谁发给谁、各发多少字节),由流量形态 + 数据量决定。
- 叠加到物理网络:按物理映射把各小组映射到 N 张芯片,多组流量叠加成真正上网的 N×N 矩阵:
$\begin{equation} C[i][j] = \sum_{g=0}^{G-1} L_g\!\left[\phi_g^{-1}(i)\right]\!\left[\phi_g^{-1}(j)\right] \label{eq:a2av-physical-overlay} \end{equation}$
小组数 $G=N/\text{EP}$。小组越多,网络上同时竞争带宽的流量份数越多——单芯片收发量不变,但链路拥塞随小组数上升。
逻辑矩阵 $L$ 的二元输入
逻辑矩阵 $L$(EP×EP)由两个独立输入确定,对角线 $L[a][a]=0$,通常非对称:
[词元-专家 路由分布] + [专家-序号 放置] → L[a][b]
(routing_dist) (placement)
路由分布(routing_dist)
决定每个词元选哪些专家:均匀,或长尾 Zipf(少数热门专家被大量选中)。V4 取消了 V3「每个词元的专家限 ≤4 个节点」约束,词元可选小组内任意专家,逻辑矩阵因此更稠密、流量更全局(机制见 2.4 MoE 架构与路由策略);本研究按 V4 无约束建模。
长尾 Zipf 的生成:把专家按热度排名 1 到 $N$,排名第 $r$ 的专家被选中概率为:
$$\begin{equation} p(r) \;\propto\; \frac{1}{r^{s}} \label{eq:a2av-zipf} \end{equation}$$- 参数 $s$ 控制陡峭度:$s$ 越大头部越陡、尾部越长;$s\!\to\!0$ 退化为均匀分布。
- $s$ 由偏度反解,不直接取值:用二分反解使朴素放置下的 RX max/mean 命中目标偏度;$s$ 无物理含义,真正锚点是 max/mean 数值(扫描档位见下文「流量形态」节)。
- 分布选型不影响结论:业界只用 max/mean 度量专家负载不均,未把专家行为定义成 Zipf;换截断正态、对数正态等能调出同样偏度的分布,结论不应改变。
专家放置(placement)
决定专家落在哪个 EP 序号:朴素(按编号顺序)或冗余(复制热门专家分散)——改变放置会改变序号间流量集中度,即使路由分布不变。
放置只决定逻辑矩阵的流量集中度;流量是否贴物理拓扑邻接(局部性)不在这里决定,由专家摆放(mapping)维度承载(见下文)。
通信矩阵:扫描维度
上一节确定了矩阵的生成机制。本节定义扫描的自变量,每个维度给出取值档位,组合出覆盖真实部署的矩阵集合。
EP 度与小组数
EP 度是通信组大小,也是逻辑矩阵 $L$ 的维度;小组数 $G=N/\text{EP}$ 随 EP 派生,是共享网络的并发 alltoallv 份数。
| 维度 | 含义 | 取值 |
|---|---|---|
| EP 度 | 通信组大小 = 逻辑矩阵维度 | 扫描 {N, N/2, N/4}(不固定) |
| 小组数 $G$ | $= N/\text{EP}$,共享网络的并发 alltoallv 份数 | 随 EP 派生 |
| 物理映射 $\phi$ | EP 序号 → 物理芯片放置 | 见下文专家摆放维度 |
@tbl-a2av-ep-dims EP 引入的三个维度
EP 取相对档 {N, N/2, N/4}(对应小组数 $G$ = 1 / 2 / 4),保证每个 N 下都有单组 / 多组对照。
流量形态(shape)
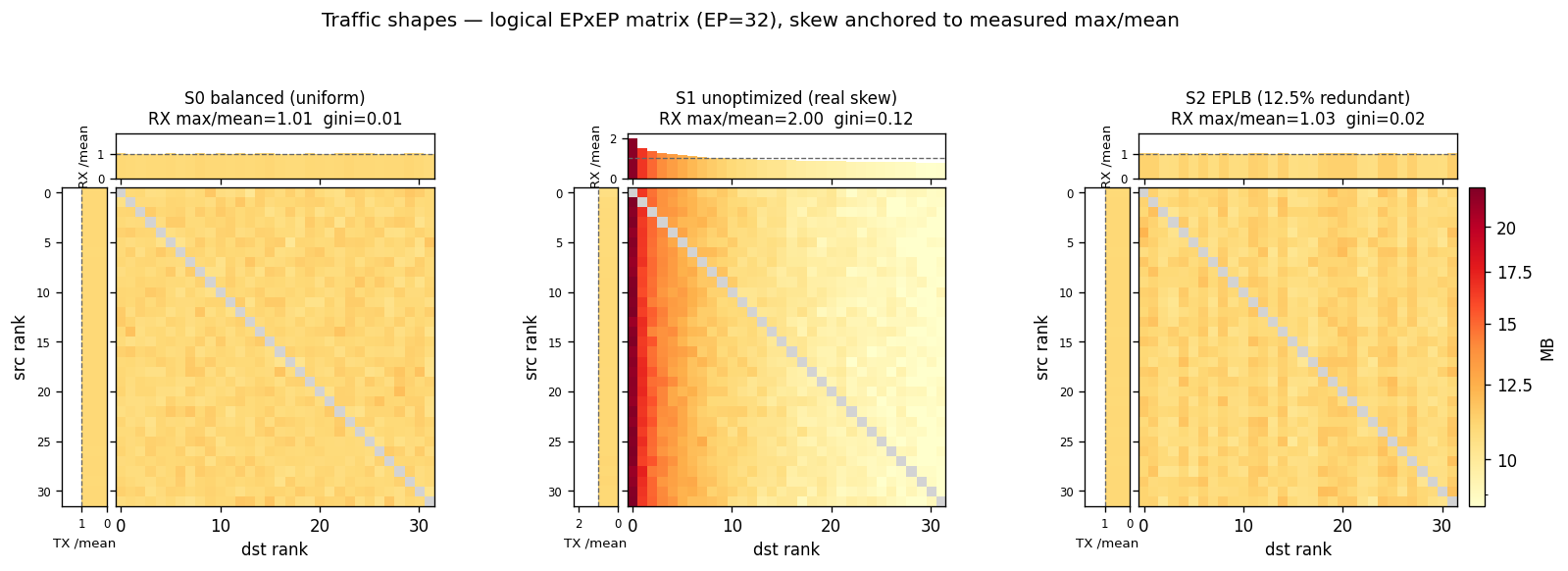
通信矩阵长什么样,取决于两件事:词元爱不爱扎堆选少数热门专家,以及专家怎么摆到芯片上。用三种典型组合覆盖真实部署的演进,分别记作 S0 / S1 / S2(短代号,下文和图表沿用):
| 代号 | 含义 | 词元选专家 | 专家摆放 | 对应真实阶段 |
|---|---|---|---|---|
| S0 均衡上界 | 专家完全不扎堆、流量最均匀的理想情况 | 均匀 | 顺序摊开 | 理论上界,推理部署里不存在,只作对比基准 |
| S1 未优化 | 有热门专家扎堆、还没做均衡 | 长尾扎堆 | 按编号顺序 | 真实部署、未开 EPLB(热门专家使个别芯片接收过载) |
| S2 已均衡 | 把热门专家复制分散之后 | 长尾扎堆 | 复制热门专家分散 | 真实部署、已开 EPLB |
@tbl-a2av-shape-categories 三种流量形态(S0 基准 / S1-S2 真实阶段)
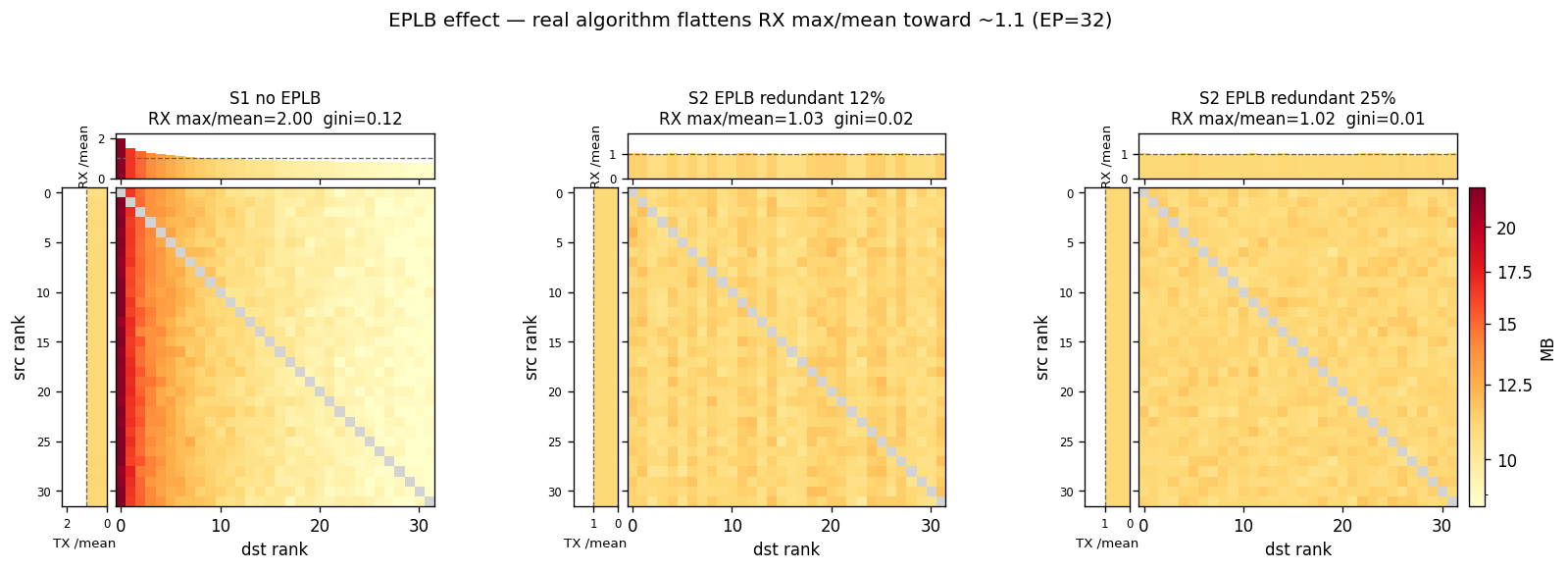
S2 的「复制热门专家分散到多张芯片」就是 EPLB 的真实做法。
三种形态的用途:
- S0 对比 S1:看「热门专家扎堆」对带宽和各拓扑的冲击有多大
- S1 对比 S2:开 EPLB(复制分散热门专家)到底能提升多少
两个建模假设(扫描 + 待校准):专家扎堆程度、S2 复制因子。
专家扎堆程度(接收偏度 RX max/mean)定义为接收最多的芯片字节数 ÷ 平均字节数,是接收串行 critical path 的决定量。业界各来源的负载不均度量口径不同,必须先换算到本研究的 RX max/mean 再锚定:
| 来源 | 原始度量 | 报告值 | 换算成 RX max/mean |
|---|---|---|---|
| NVIDIA(V3 EP32,未开均衡) | (max−mean)/mean | 1.56 | 2.56 |
| DeepSeek EPLB | GPU 间负载倍数 | up to 2× | ~2.0 |
| NVIDIA(开均衡后) | (max−mean)/mean | 0.115 | 1.11 |
@tbl-a2av-skew-sources 业界负载不均度量换算到本研究的 RX max/mean
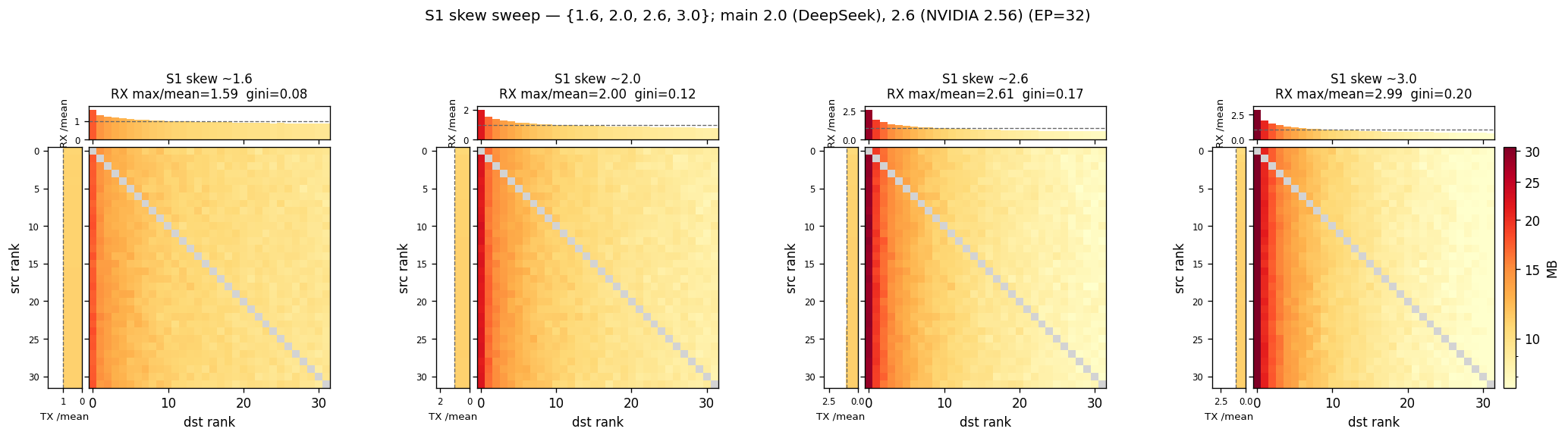
真实未均衡的接收偏度落在 RX max/mean ≈ 2.0–2.6:NVIDIA 报的 1.56 是 (max−mean)/mean,换算后 max/mean = 2.56,不是直接的 1.56(早前把它当 max/mean 是口径误读)。据此 S1 扫 {1.6, 2.0, 2.6, 3.0},主线取 2.0(DeepSeek EPLB 实测下沿,保守不夸大收益)——1.6 作部分均衡对照、2.6 为真实未均衡上沿(NVIDIA 换算 2.56)、3.0 为 EPLB 必要性拐点;反事实高档 {5.0, 10.0} 仅作 EPLB 收益上限参考。Zipf 生成器(见 )的 $s$ 按各档反解。V4 加了序列级均衡损失,真实偏度可能低于 V3,待 V4 部署实测校准。
S2 复制因子(热门专家复制比例)扫 {12.5%, 25%}(12.5% = V3 prefill 256 基础 + 32 冗余)。具体冗余度待 DeepSeek 部署 / DeepEP 实现校准。
S1 偏度敏感性档({1.6, 2.0, 2.6, 3.0})的形态见下图,主线结论用 2.0,其余档用于敏感性验证。
专家摆放(mapping)
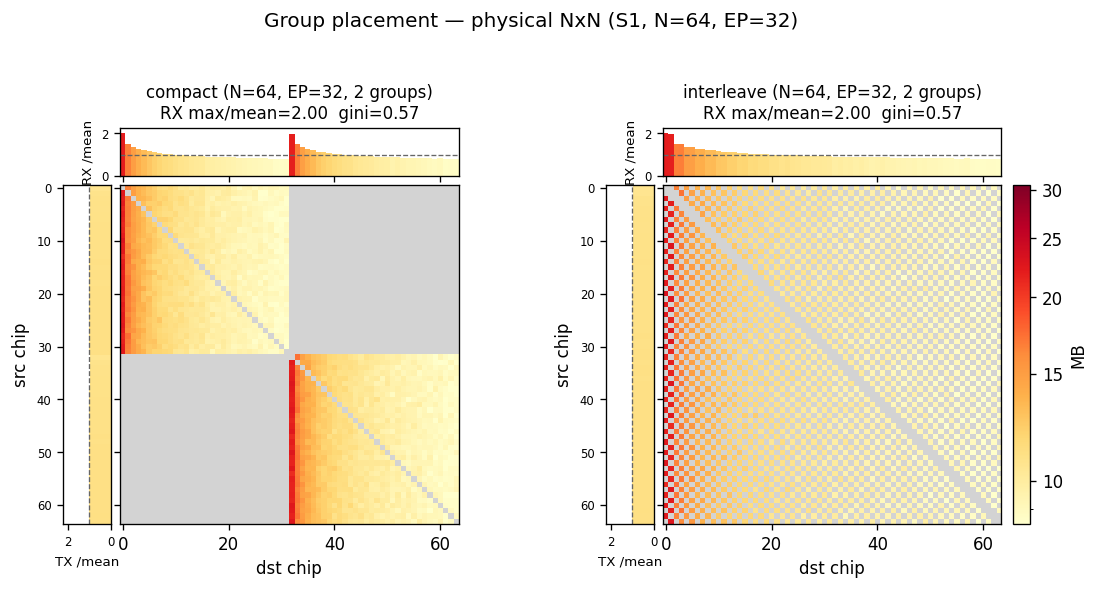
同一个专家小组的成员芯片,可以摆在物理上挨着的位置,也可以打散到全网。这个摆放方式(mapping)决定了组内通信是「就近完成」还是「在全网散布」——而这正是拓扑选型有无意义的关键。用两种典型摆法(短代号 紧凑 compact / 交错 interleave,下文用中文),外加一种理想对齐:
| 代号 | 摆法 | 流量特点 | 小组之间 |
|---|---|---|---|
| 紧凑(compact) | 一个小组占一整块挨着的芯片 | 就近完成、跳数少 | 互不干扰 |
| 交错(interleave) | 小组成员打散到全网 | 全网散布、跳数多 | 互相竞争带宽 |
| 拓扑对齐(topology-aware) | 顺着拓扑结构摆(如 torus 的一个子立方体) | 最优 | 互不干扰 |
@tbl-a2av-mapping-dims 三种小组摆放方式
摆放维度为何重要:它直接决定流量是否贴合物理邻接,这是「换拓扑 / 调路由是否有价值」的前提。对比紧凑与交错(同一形态下)即可验证:若紧凑摆放时各拓扑差距大、交错摆放时差距很小,说明拓扑选择的价值依赖流量的就近性。
数据量(横轴)
横轴是每张芯片这次要发的数据量,由每芯片词元数 (tokens_per_rank) 驱动:
tokens_per_rank vs batch(口径关系)
横轴用 tokens_per_rank 而不是 batch,原因:alltoallv 字节量直接由词元数决定 ($\text{bytes} = \text{tokens} \times \text{topk} \times h$),batch 不直接驱动;同一脚本框架要能跨 prefill / decode 统一扫描,prefill 时 batch 与词元数解耦。
两者关系如下:
| 阶段 | tokens_per_rank | 与 batch 关系 | 本研究是否扫描 |
|---|---|---|---|
| decode | 1 - 1024 | $= \text{batch}\_\text{size}\_\text{per}\_\text{rank}$(每序列每步 1 个词元) | ✅ 扫描 |
| prefill | 1024 - 16384 | $= \text{seq\_len} \times \text{batch}\_\text{size}\_\text{per}\_\text{rank}$ | ❌ 本次不扫 |
@tbl-a2av-tokens-vs-batch tokens_per_rank 与 batch 口径关系
本研究覆盖启动开销主导(小数据量)到带宽主导(大数据量)全段:小数据量段量化启动开销下界,大数据量段路由 / 拓扑分化才充分显现,两段都要扫。decode 落在小数据量段、prefill 落在大数据量段;decode 下 tokens_per_rank ≡ batch_size_per_rank,该段图表横轴可直接读成 batch。
seq_len 在 alltoallv 字节公式中不出现(与 attention 不同),因此本研究不引入 seq_len 参数。如未来扩 prefill 段,仅需把 tokens_per_rank 提到 1024-16384 段即可,无需引入新参数。
扫描范围
横轴对数刻度,2 的幂取点 11 个($2^0 \sim 2^{10} = 1, 2, 4, \ldots, 1024$),覆盖 decode 全段。
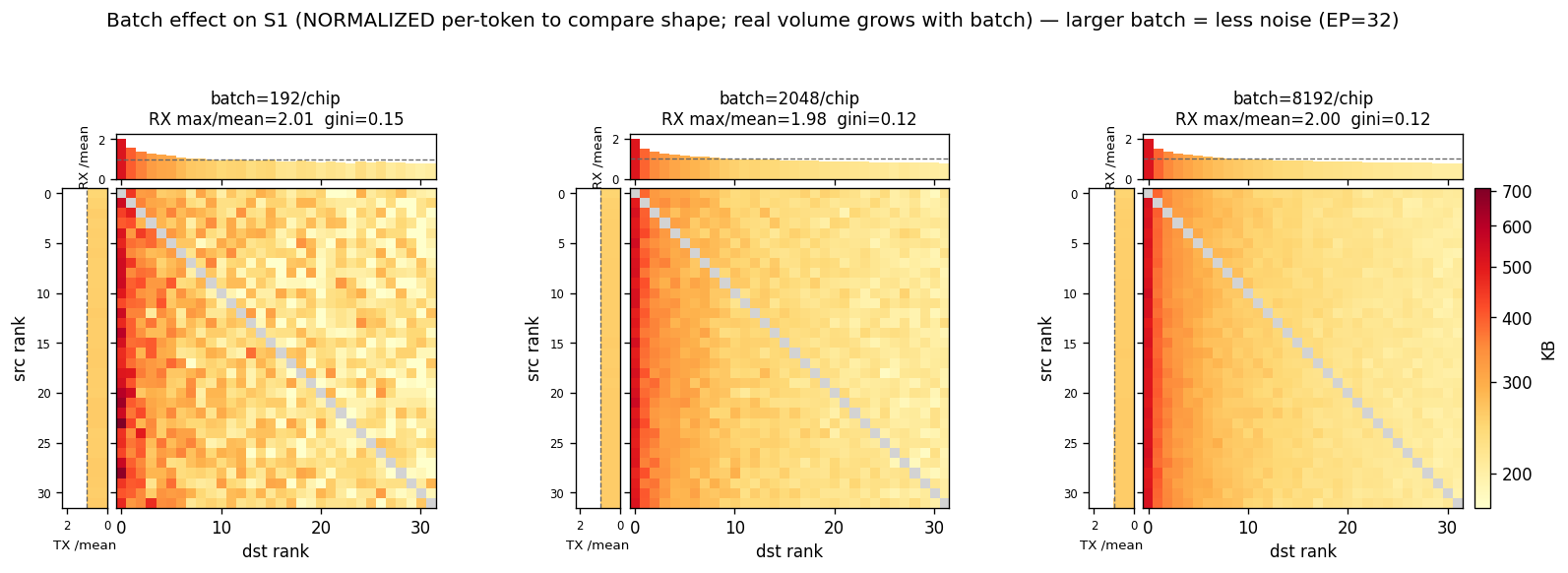
数据流契约:矩阵生成器输出真实字节矩阵,是唯一真值源。G5 仿真直接消费真实字节;上图的归一化仅用于可视化比形态,不回写、不进仿真。
通信方向
一次 MoE 计算包含两次数据交换,两者都需计入:
- 去程(dispatch):词元发给专家,用 FP8 精度(每对 $h$ 字节)
- 回程(combine):结果发回原芯片,流量方向与去程相反(近似去程矩阵的转置),通常用 BF16 精度(每对 $2h$ 字节,是去程的 2 倍)
回程矩阵由去程矩阵推算(转置再乘精度比),不单独设计。
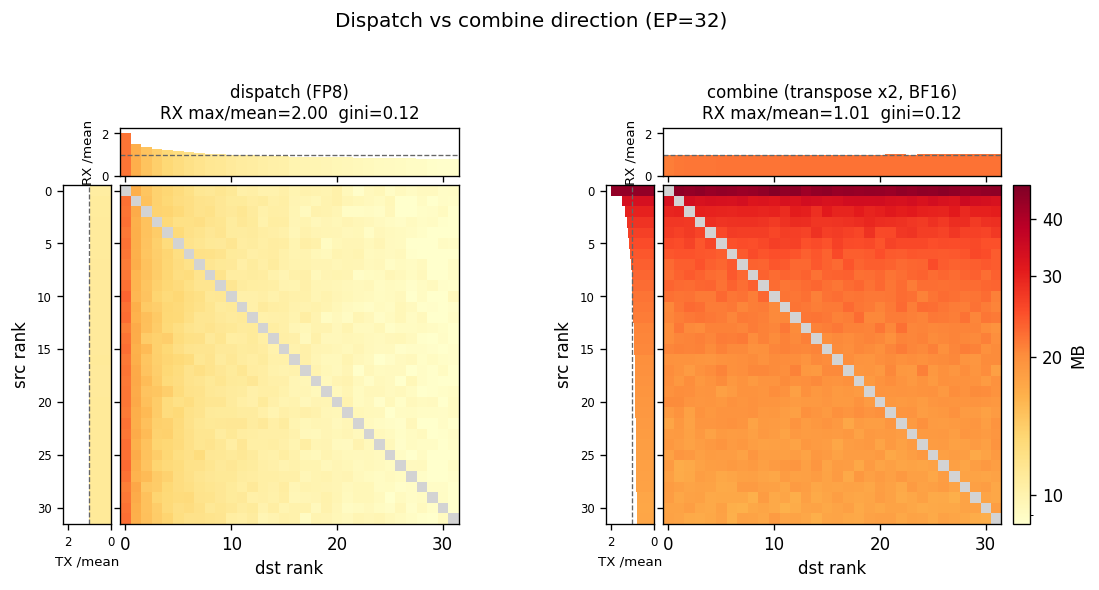
固定生成参数
扫描上述维度时,以下参数取定值,锚定 V4-Pro 配置。
| 参数 | 取值 | 来源 |
|---|---|---|
| $n_{\text{experts}}$ | 384 | V4-Pro 路由专家数 |
| $\text{top\_k}$ | 6 | V4 每个词元激活的专家数 |
| hidden $h$ | 7168 | V4-Pro hidden dim |
| 每对收发字节 | $h = 7168$ Bytes(去程 FP8)/ $2h$(回程 BF16,待确认) | 2.6 V4 对通信的新需求 |
| 每芯片词元数(数据量横轴) | 连续扫描,decode ~ prefill 全段 | 见数据量维度 |
| $N_{\text{chip}}$ | 32, 64 | 本研究规模 |
@tbl-a2av-matrix-params 通信矩阵生成的 V4-Pro 参数
拓扑覆盖
本研究覆盖的 7 拓扑族按"现代 N=32/64 真实部署存在性"分两层:
- 层 1 (真实部署候选):现代生产系统在 N=32/64 实际部署的拓扑,结论可直接用于部署决策
- 层 2 (学术对照):现代生产部署罕见或不存在的拓扑,保留用于路由算法理论行为对照,不进部署推荐
层 1:真实部署候选
| 拓扑族 | 参数定义 | 选入理由 | N=32 / N=64 真实部署 |
|---|---|---|---|
| single-switch | n = 全连到 1 台 sw 的 chip 数 | 中等规模性能上界 baseline, chip 直连 1 跳达 | DGX 节点 8-GPU NVSwitch / Sophgo SG2262 32 chip × 2 spine / NVL72 (72-GPU NVSwitch) |
| torus | 2D: rows × cols; 3D: dx × dy × dz;含 wrap-around; chip 直连 | HPC + AI 加速器实际拓扑,DOR 维度路由经典 | TPU v3 8×8 / TPU v4 4×4×4 cube (N=64 完全等价 TPU v4 单 cube) |
| fat-tree | k = switch 端口数;layers = switch 层数;osr = 超订比;d = round(k·osr/(osr+1)); u = k−d; num_leaf = N/d; num_spine = u; cpb = 板内 chip 数 (cpb=1 纯 clos, cpb=8 板内 mesh + 板间 clos 混合形态) | 数据中心 99% 标准;包含两种真实部署形态:纯 clos (每 chip 直连 leaf,对应 NVIDIA DGX H100 + IB ToR / Meta F16) 和 板内 mesh + 板间 clos 混合 (板内 c2c 直连省 switch 成本,对应 SG2262 低成本部署 / Habana Gaudi-2 服务器) | NVIDIA InfiniBand SHARP / Spectrum / AWS / 商用 GPU 集群 (纯 clos);SG2262 低成本部署 (混合形态) |
@tbl-a2av-layer1-deploy 层 1:真实部署候选 (主结论引用这些)
层 2:学术对照
| 拓扑族 | 参数定义 | 学术价值 | 现代部署现状 |
|---|---|---|---|
| dragonfly | p = 每 sw 接 chip 数;a = 每 group 内 sw 数;g = group 数;h = 每 sw global 链路数;N = a·p·g | UGAL 自适应路由的算法对照 | 设计 1000+ chip 规模 (Slingshot/HPE EX), N=32/64 退化为 1-2 group, 不展现 dragonfly 跨组本质 |
| hypercube | d = 维度数 = log₂(N);每 chip 度 = d | DOR bit-dim 路由对照;与 torus 3D 同 degree/diameter 的结构对照 (验证"维度数 vs 维度长度"影响) | 历史拓扑 (Connection Machine 1987),现代生产系统几乎不用 |
| hyperx | L = 维度数;T = 每 sw 接 chip 数;S = 每维 sw 数列表 | 高 radix switch 平铺架构研究 | 学术热点 (Cray Cascade 后继研究),工业部署极少;T=2 商用不存在 |
| ring | n = 1D 环上 chip 数 | NCCL ring AR baseline | NVLink Ring 仅 8-GPU 节点内;N=32/64 大环不存在直接部署 |
@tbl-a2av-layer2-academic 层 2:学术对照 (用于路由算法理论行为分析,不进部署推荐)
为什么不评估其他拓扑
| 排除拓扑 | 不评估理由 |
|---|---|
| 扁平 Clos / chip 直连 2-spine (如 32 chip × 2 个 51.2T spine 直连,见 fat-tree §2 级 Leaf-Spine 变体) | 路径数 ≤ 2 且等长,路由优化空间退化 (shortest_path 与 ECMP 行为差异 < 5%)。等价于 single-switch 双轨版,硬件部署问题而非路由问题 |
| 3-layer fat-tree (Edge + Agg + Core) | N=32/64 太小,2-layer Spine-Leaf 已装下且端口数足够;3-layer 在 N ≥ 数百时才有意义 |
| dragonfly+ (带 spine 的 dragonfly 变种) | UGAL 路由行为与基础 dragonfly 高度重叠,加入只增 grid 不增信息 |
| full-mesh | 链路数 N(N-1)/2 (N=64 时 2016 链路) → 实际不可部署;且每对 chip 仅 1 跳直达,无路由选择 |
| slimfly | 学术型拓扑,工业部署极少 |
| polarfly | 学术型,本研究聚焦工程可部署方案 |
| jellyfish | 随机正则图,工业部署罕见 |
| xpander | 学术型 expander 图 |
| zcube | 国产新型拓扑,本研究聚焦主流 |
| bcube / dcell | 早期数据中心提案,已被 fat-tree 取代 |
@tbl-a2av-topology-excluded 不评估的拓扑及理由
N=32 拓扑实例
| 层 | 拓扑族 | 实例参数 | switch 数 | 每芯片度 | 备注 |
|---|---|---|---|---|---|
| 1 | single-switch | n=32 | 1 | 1 | 32 chip 全接同一 switch (Sophgo 实部署对照) |
| 1 | torus | 2D 4×8 | 0 | 4 | chip 之间直连 |
| 1 | fat-tree | k=8, layers=2, osr=1, cpb=8 混合形态 | 8 leaf + 4 spine = 12 | 1 (出 leaf) + 7 (板内 mesh) = 8 | d=u=4,板内 c2c 直连 + 板间 clos,对应 SG2262 低成本部署 |
| 1 | fat-tree | k=8, layers=2, osr=1, cpb=1 纯 clos | 8 leaf + 4 spine = 12 | 1 (仅 leaf 端口) | d=u=4,每 chip 直连 leaf 无板内 mesh,对应 DGX H100 + ToR 部署 |
| 1 | fat-tree | k=4, layers=2, osr=1, cpb=8 | 16 leaf + 2 spine = 18 | 1 + 7 板内 = 8 | d=u=2, 极宽浅非商用配置 (商用 4-port switch 不存在) |
| 2 | torus | 3D 2×4×4 | 0 | 6 | 3 维变体,N=32 cube 是 N=64 cube 的小规模演示 |
| 2 | dragonfly | p=4, a=4, g=2 (非 canonical h=1) | 2 × 4 = 8 | 1 | 自实现非 canonical,仅 2 group 失真 |
| 2 | hypercube | 5d ($2^5=32$) | 0 | 5 | 历史拓扑 |
| 2 | hyperx | T=2, S=[4,4] | 16 | 1 | T=2 商用不存在 |
| 2 | ring | n=32 | 0 | 2 | 32-chip 大环现代不存在 |
@tbl-a2av-n32-topologies N=32 下 9 种拓扑实例 (层标:1=真实部署,2=学术对照)
N=64 拓扑实例
| 层 | 拓扑族 | 实例参数 | switch 数 | 每芯片度 | 备注 |
|---|---|---|---|---|---|
| 1 | single-switch | n=64 | 1 | 1 | NVL72 类大 NVSwitch 部署对照 |
| 1 | torus | 2D 8×8 | 0 | 4 | TPU v3 实际部署 |
| 1 | torus | 3D 4×4×4 | 0 | 6 | TPU v4 单 cube,完全等价生产部署 |
| 1 | fat-tree | k=16, layers=2, osr=1, cpb=8 混合形态 | 8 leaf + 8 spine = 16 | 1 + 7 板内 = 8 | d=u=8,对应 SG2262 低成本 64-chip 部署 |
| 1 | fat-tree | k=16, layers=2, osr=1, cpb=1 纯 clos | 8 leaf + 8 spine = 16 | 1 | d=u=8,对应 64-GPU DGX 类 IB 直连部署 |
| 1/2 | fat-tree | k=8, layers=2, osr=1, cpb=8 | 16 leaf + 4 spine = 20 | 1 + 7 板内 = 8 | 中等宽度,仍商用边缘 |
| 2 | fat-tree | k=4, layers=2, osr=1 | 32 leaf + 2 spine = 34 | 1 | 极宽浅非商用配置 (商用 4-port switch 不存在) |
| 2 | dragonfly | p=4, a=4, g=4 (非 canonical h=3) | 4 × 4 = 16 | 1 | 4 group 仍远小于 Slingshot 设计规模 |
| 2 | hypercube | 6d ($2^6=64$) | 0 | 6 | 历史拓扑 |
| 2 | hyperx | T=4, S=[4,4] | 16 | 1 | T=4 算合理但工业部署罕见 |
| 2 | ring | n=64 | 0 | 2 | 64-chip 大环不存在 |
@tbl-a2av-n64-topologies N=64 下 10 种拓扑实例 (层标:1=真实部署,2=学术对照)
各拓扑可用的路由算法
| 拓扑族 | 可用路由 (family-aware) | 算法语义 |
|---|---|---|
| fat-tree | shortest_path / ECMP / d-mod-k | dmodk 是 PGFT 显式 hash 公式:(dst // denom) % modulus 严格均布到 spine |
| dragonfly | shortest_path / ECMP / UGAL | UGAL = minimal + valiant 自适应混合,跨组拥塞时绕路 |
| torus | shortest_path / ECMP / DOR | DOR = 严格按 x → y → z 维度顺序路由,避免死锁 + 链路均匀 |
| hypercube | shortest_path / ECMP / DOR | hypercube 上 DOR = 按 bit 维度顺序翻转 |
| hyperx | shortest_path / ECMP | DOR 在 hyperx 上理论可用,本研究未实现 |
| ring | shortest_path | 单环只有一条路径方向选择,无多路径 |
| single-switch | shortest_path | 所有 chip 1 跳直达,无路径选择 |
@tbl-a2av-routing-per-family 每拓扑可用的路由算法
族无关多路径算法 packet_spray (UEC 2025) 与 flowlet_ar (LetFlow) 因 SG2262 RCLINK Go-Back-N 协议 + alltoallv 无 idle workload 双重物理不兼容,本研究不评估,详见 。
共 (拓扑,路由) 组合:N=32 25 组 (single-switch 1 + torus-2D 3 + torus-3D 3 + fat-tree 3 实例 × 3 + dragonfly 3 + hypercube 3 + hyperx 2 + ring 1 = 25);N=64 28 组 (多 1 个 fat-tree 实例 = 4 实例 × 3 + 其余同 = 28)。
实验设计
本节确定评估网格、平台参数、测量口径、自洽校验和展现形式,决定每个 cell 怎么跑、怎么读、怎么淘汰。
评估网格
评估有两个连续横轴——数据量与接收偏度——分别支撑 KA3(适用边界)和 KA2(EPLB 收益),配合精选对比曲线和分面子图。维度按在图中的角色分工:
| 维度 | 角色 | 取值 |
|---|---|---|
| 数据量(每芯片字节) | 连续横轴① | log scale,15-20 点,decode ~ prefill 全段 |
| 接收偏度 RX max/mean | 连续横轴② | 1.0–10.0 扫 ~15 点(真实区间 1.0–3.0 密、反事实 3–10 疏),主线 2.0 |
| (拓扑,路由) | 对比曲线(≤5 条/图) | 各拓扑族 × 按族适配路由(fat-tree: SP/ECMP/dmodk;torus/hypercube: +DOR;dragonfly: +UGAL;ring/single-switch: SP)。packet_spray / flowlet_ar 均因物理不兼容剔除(见 ISSUE-030) |
| 形态 S1 / S2 | 对比 / 分面 | S1 未开 EPLB vs S2 开 EPLB(收益对比);S0 均衡上界作基准。S2 冗余度 ∈ {12.5%, 25%} |
| EP / 摆放 | 分面子图 | EP {N, N/2, N/4} × 摆放 {紧凑,交错,(拓扑对齐)} |
| N | 分面子图 | 32, 64 |
| 方向 | 分面子图 | 去程,回程 |
@tbl-a2av-grid 评估网格维度分工(两连续横轴 + 对比曲线 + 分面)
扫描密度原则:连续横轴(数据量、偏度)扫密以出平滑趋势曲线;对比曲线(拓扑,路由)单图 ≤5 条,多对比则拆多张子主题图,不堆一张;其余维度正交分面。仿真成本低,密度花在横轴而非维度堆叠。
平台参数
| 项 | 值 |
|---|---|
| c2c 链路 | 400 GB/s, 0.025 us |
| 接收端聚合限速 | 每张芯片接收总带宽不超过 line rate(400 GB/s 单向) |
| 板内 (cpb=8) | full-mesh,注入 role=intra + level=0 兼容 ugal/dmodk |
| 拓扑层级 | 平坦单层 c2c(不模拟 NVLink+RDMA 两段非对称,列为 limitation) |
| 仿真引擎 | G5 + 扩展后的 alltoallv send_counts 接口 |
| 算子 | alltoall pairwise 算法消费 send_counts(bruck 不兼容变长) |
| 芯片 | SG2262 |
@tbl-a2av-platform 评估平台参数
测量指标
| 指标 | 定义 | 备注 |
|---|---|---|
| 完成时间 | $T_{\text{a2av}}$(us) | 由瓶颈芯片决定 |
| per-chip BusBW | $\dfrac{\sum_{i,j} C[i][j]}{N \cdot T_{\text{a2av}}}$(GB/s) | per-chip 平均出向带宽;不是 NCCL busBw = algBw × (N-1)/N 全局单值定义,比较 NCCL 报告时不要直接套用 |
| 瓶颈芯片口径 | 最慢芯片的收 / 发占用 | 平均口径会掩盖瓶颈,故另立 |
spd_topo | $T(\text{fat-tree}, \text{ECMP}) / T(\text{this topo}, \text{ECMP})$ | 隔离拓扑(固定 ECMP 排除路由干扰);回答"该不该换拓扑" |
spd_route | $T(\text{this topo}, \text{ECMP}) / T(\text{this topo}, \text{this routing})$ | 隔离路由(固定拓扑);回答"ECMP / dmodk / packet_spray / flowlet_ar 哪个好" |
spd_eplb | $T(\text{S1}) / T(\text{S2})$ | 隔离 EPLB 开关;回答"开 EPLB 收益" |
ohd_shape | $T(\text{S1}) / T(\text{S0})$ | 不均衡引入的总开销;回答"离理想还差多远" |
@tbl-a2av-metrics 测量指标
物理自洽校验(每个 cell 强制)
每个 cell 跑完强制校验:每张芯片的收 / 发速率都不超过物理链路上限:
- $\max_i (\text{接收}_i) \le$ line rate(400 GB/s 单向)
- $\max_i (\text{发送}_i) \le$ line rate
越界 → 标记为建模违反,不进结论。
展现形式:三种图各司其职
用三种图各司其职:
| 图 | 回答 | 形式 |
|---|---|---|
| 效率热力图 | 全局覆盖率(哪个组合好) | 场景(行) × 方案(列),颜色 = 带宽利用率% |
| 趋势曲线 | 选型切换边界 | 横轴数据量,曲线 = (拓扑,路由),三联 Latency / BusBW / Speedup,仅重点场景 |
| 瓶颈归因图 | 机理 + 物理越界自检 | 拓扑上 link / chip RX-TX 利用率热度 |
@tbl-a2av-display 三种图各司其职
基线定义:
- 拓扑 baseline = fat-tree + ECMP(现存商用默认:NVIDIA DGX + IB / Meta GenAI cluster / DeepSeek 等)
- 路由 baseline = 同拓扑内 ECMP(替代早期的 shortest_path——SP 在多路径拓扑上等价"只用 1 条 leaf-spine 链路",商业不部署,数字虚高无决策意义)
- 形态 baseline = S0 均衡上界(用于
ohd_shape)+ S1 未开 EPLB(用于spd_eplb)
隔离原则:每个倍数计算时其他维度必须一致(同形态 / EP / 摆放 / 方向 / 数据量),保证只对比单一变量。
限制与待校准项
本设计有五处简化与待校准,结论的适用范围据此界定:
- 前 3 层哈希路由未单独建模:V4-Pro 共 61 层,前 3 个 MoE 层用哈希路由(负载均匀、偏度 ≈ 1),占比约 5%;本研究用单一偏度建模其余 95% 的学习路由层,前 3 层的均匀形态未单独扫描(机制见 2.4 MoE 架构与路由策略)。
- 偏度档位用 V3 实测代理:业界 rank 级偏度实测目前只有 V3(NVIDIA EP32)。V4 改了亲和度分数算法、加了序列级均衡损失、引入 Anticipatory Routing,真实偏度可能与 V3 不同,待 V4 部署实测校准。
- 未建模计算-通信重叠:本研究测纯 alltoallv 通信时间,不含 V4 的 wave 调度重叠。结论用于判断「通信在什么(数据量、带宽、拓扑)条件下成为重叠的瓶颈」,不直接等于端到端延迟——通信被计算隐藏时端到端不为它额外等待(见 2.6 V4 对通信的新需求)。
- 去程通信模式有差异:V4 用拉取式去程(各芯片主动读远端),本研究仿真的去程实现(见 ISSUE-031)与之不同,绝对延迟可能有差,但拓扑 / 路由的相对优劣排序应保持。
- 平台简化为单层 c2c:链路统一 400 GB/s,未建模节点内高速直连与跨节点网络的两段非对称带宽。