MoE EP alltoallv 拓扑与路由的性能评估与部署推荐
日期:2026-06-03 (v3 数据集)
实验设计:MoE EP alltoallv 拓扑与路由的性能评估:实验设计
KBG
MoE 推理的通信开销与优化动机:
- EP alltoallv 是主要通信开销,V4 靠计算重叠隐藏它:MoE 推理中 EP 层的 dispatch / combine 两次 alltoallv 占据主要互联流量;V4 把两次通信与专家计算重叠,能否隐藏取决于通信耗时与算力-带宽比。
- 优化通信降低硬件门槛:通信耗时越短,隐藏所需的互联带宽阈值越低;优化 alltoallv 让更低互联带宽的硬件也能维持端到端性能。
- 通信耗时对拓扑、路由、摆放、偏度敏感:V4 取消 V3 "≤4 node 路由约束" 后,通信矩阵从均匀变稀疏 + 长尾,放大了 alltoallv 对这几个维度的敏感性。
在此背景下,部署选型缺三块数据:
- 拓扑、路由、摆放选型无数据:fat-tree / torus / single-switch 拓扑族 × shortest_path / ECMP / dmodk / DOR 路由 × 专家摆放 (compact / interleave) 在 32 / 64 芯片规模 EP alltoallv 上的相对优劣无公开实测,部署架构师缺量化依据。
- EPLB 收益与偏度关系无数据:专家负载偏度多大时 EPLB (冗余放置) 才值得开、收益几何,业界引用的 "EPLB 2-3×" 对应何种偏度,未见量化。
- 结论适用边界无数据:上述选型结论在什么数据量、规模、通信方向下成立,边界未划定。
TASK
本研究在 32 / 64 芯片规模上,用 G5 仿真扫描多维通信矩阵 × 真实可部署的拓扑 × 各拓扑适配的路由 (含专家摆放子维度),测量 per-chip 平均出向带宽,产出每个 (数据量,形态,偏度) 场景下的 (拓扑,路由) 推荐组合及适用范围。
KP
在 32 / 64 芯片规模的 V4 EP alltoallv 上,哪种真实可部署的 (拓扑,路由,专家摆放) 组合与 EPLB 开关给出最大 per-chip 出向带宽,且该结论在哪些偏度、数据量、规模、方向范围内成立?
KO
量化真实可部署拓扑 × 各拓扑适配路由在不同形态 / 偏度 / 数据量 / 规模 / 专家摆放下的 per-chip 平均出向带宽 (GB/s),输出推荐表 + 各结论的适用范围。
测量指标定义:per-chip 平均出向带宽
$\begin{equation} \text{per-chip BW} = \frac{\sum_{i,j} C[i][j]}{N \cdot T_{\text{a2av}}} \label{eq:a2av-perchip-bw} \end{equation}$
即矩阵总字节数除以 N 个 chip 与 alltoallv 完成时间的乘积。此口径是 per-chip 平均,不是 NCCL busBw = algBw × (N-1)/N 的全局单值定义,比较 NCCL 报告时不要直接套用。本报告所有表格列名中的 "BW" / "BusBW" 均指上述定义。
实测数据按 KA 分节呈现 (各 KA 的「数据」子节);主推荐汇总见 。
KT
本研究在平坦单层 c2c 平台 (link 400 GB/s,不模拟 NVLink + RDMA 两段非对称) 上以 G5 仿真扫多维网格,用 per-chip 平均出向带宽量化优劣。核心分析框架是两个瓶颈:alltoallv 完成时间 $T_{\text{a2av}}$ 由网络传输时间与接收串行时间中较慢者决定。
$\begin{equation} T_{\text{a2av}} = \max(T_{\text{网络传输}},\ T_{\text{接收 incast}}) \label{eq:a2av-bottleneck} \end{equation}$
所有扫描维度都落到这两侧之一,哪一侧先触顶决定该场景的结论:
- 网络传输侧 (决定 $T_{\text{网络传输}}$):拓扑直连度、路由路径散布、专家摆放 (interleave 增跨网流量)、数据量 (alpha → bandwidth)、规模 (spine 数)
- 接收 incast 侧 (决定 $T_{\text{接收 incast}}$):专家负载偏度、EPLB 冗余放置
三个 KA 按部署决策者的执行优先级展开:先定网络传输侧的 (拓扑,路由) 选型 (KA1,含专家摆放子维度),再按工作负载偏度决定是否开 EPLB (KA2),最后理解结论在数据量 / 规模 / 方向上的适用边界 (KA3)。
扫描的拓扑按"现代 32 / 64 芯片规模真实部署存在性"分两组:
- 真实可部署拓扑 (single-switch / torus / fat-tree):现代生产系统在 32 / 64 芯片规模实际部署的拓扑,部署推荐结论只引这一组
- 学术对照拓扑 (dragonfly / hypercube / hyperx / ring):现代生产部署罕见或不存在的拓扑,数据仅用于路由算法理论行为参考,不进部署推荐
扫描的关键维度:流量形态 (完美均衡 / 未开 EPLB / 开启 EPLB) × 专家负载偏度连续 1.0–10.0 共 13 点 (真实区间 1.0–3.0 密采,主线 2.0;反事实 3–10 用于 EPLB 上限) × 数据量 tokens_per_rank {1..1024 共 20 档加密} × 拓扑 × 路由 × 摆放 (compact / interleave) × EP {N, N/2, N/4} × 规模 {32, 64} × 方向 {dispatch, combine}。v3 数据集共约 3900 cells。
路由算法对比基线选用 ECMP 而非 shortest_path:单 Dijkstra shortest_path 在多 spine fat-tree 上退化为单 spine 使用,真实生产部署默认 ECMP 散布到多 spine,用 SP 作 baseline 会夸大其他路由的相对优势。switch_latency / top_k / ECMP max_paths / torus shape / fat-tree osr 等二阶子维度的扫描结果见限制段。
KA1 — 拓扑与路由决定带宽上限
结论
真实可部署拓扑里,网络传输能力决定带宽上限,主选型是拓扑与路由两层;专家摆放是第三个影响网络传输的因素 (纠正旧报告"摆放无差异"的误判,见下"摆放"项):
- 拓扑:torus (每芯片直连 6 邻居,网络带宽充足) 完美均衡下接近物理上限 (372 / 400 = 93% 利用率),fat-tree (每芯片单上行口) 受单 uplink 限制 (294 / 400 = 73%), torus 比 fat-tree 高 1.27×。single-switch 是 1-hop 直达,带宽上限即 chip 出向 line rate 减 incast 损失。
- 路由:ECMP 在 N=32/64 全部测试 cell 中均未输给其他路由 (其他路由要么持平要么劣 ≥ 5%),是工程默认。shortest_path 在多 spine fat-tree 上退化为单 spine,只达 ECMP 的 35% (104 vs 294,差 2.82×)。dmodk 在 N ≥ 64 + 完美均衡 / EPLB 已开场景下 +29%。
- 摆放:EP < N (多组) 时 compact 比 interleave 高 2-3× (EP=16 时 185 vs 57 = 3.3×, EP=32 时 221 vs 118 = 1.9×);EP = N (单组,无摆放自由度) 时两者相同。interleave 把专家小组打散到全网,增加跨 leaf 流量,在网络传输侧成为瓶颈。
数据
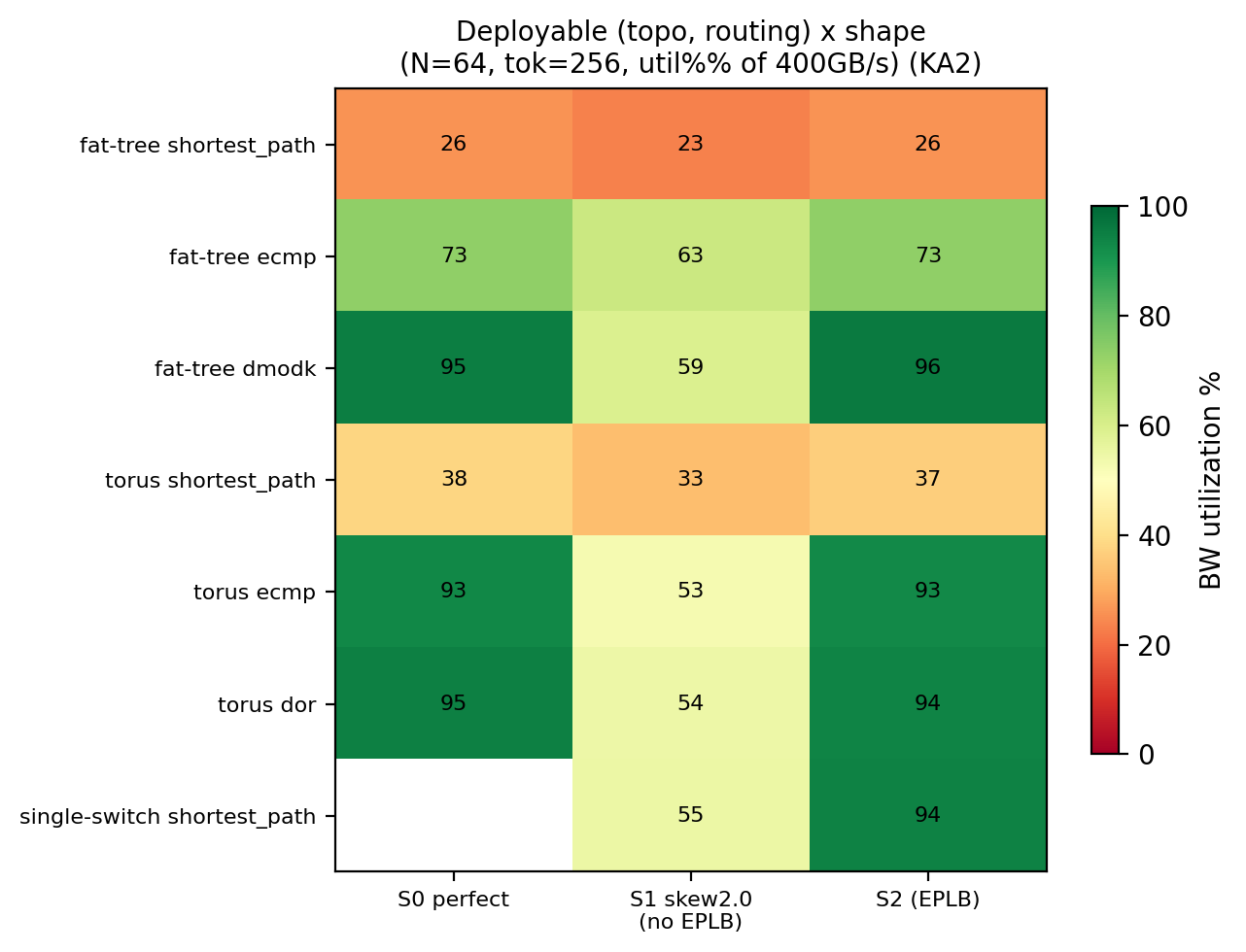
| 拓扑 | 路由 | 完美均衡 | 未开 EPLB (偏度 2.0) | 开启 EPLB |
|---|---|---|---|---|
| fat-tree-k16 | shortest_path | 104.1 | 92.7 | 103.5 |
| fat-tree-k16 | ECMP | 293.7 | 250.2 | 289.6 |
| fat-tree-k16 | dmodk | 380.2 | 237.2 | 375.7 |
| torus-4x4x4 | shortest_path | 152.7 | 133.9 | 152.6 |
| torus-4x4x4 | ECMP | 372.1 | 210.9 | 361.8 |
| torus-4x4x4 | DOR | 379.2 | 217.2 | 359.5 |
@tbl-a2av-topo-routing-n64 64 芯片下真实可部署 (拓扑,路由) × 3 形态的 per-chip 出向带宽 (GB/s, heavy / tok=256)
| 对比项 | 倍数 | 场景 |
|---|---|---|
| torus ECMP / fat-tree ECMP | 1.27× | 完美均衡 |
| torus ECMP / fat-tree ECMP | 0.84× | 未开 EPLB (偏度 2.0) |
| torus ECMP / fat-tree ECMP | 1.25× | 开启 EPLB |
| fat-tree dmodk / fat-tree ECMP | 1.29× | 完美均衡 |
| fat-tree ECMP / fat-tree SP | 2.82× | 完美均衡 |
@tbl-a2av-routing-ratios 拓扑间与路由间的关键倍数关系 (N=64)
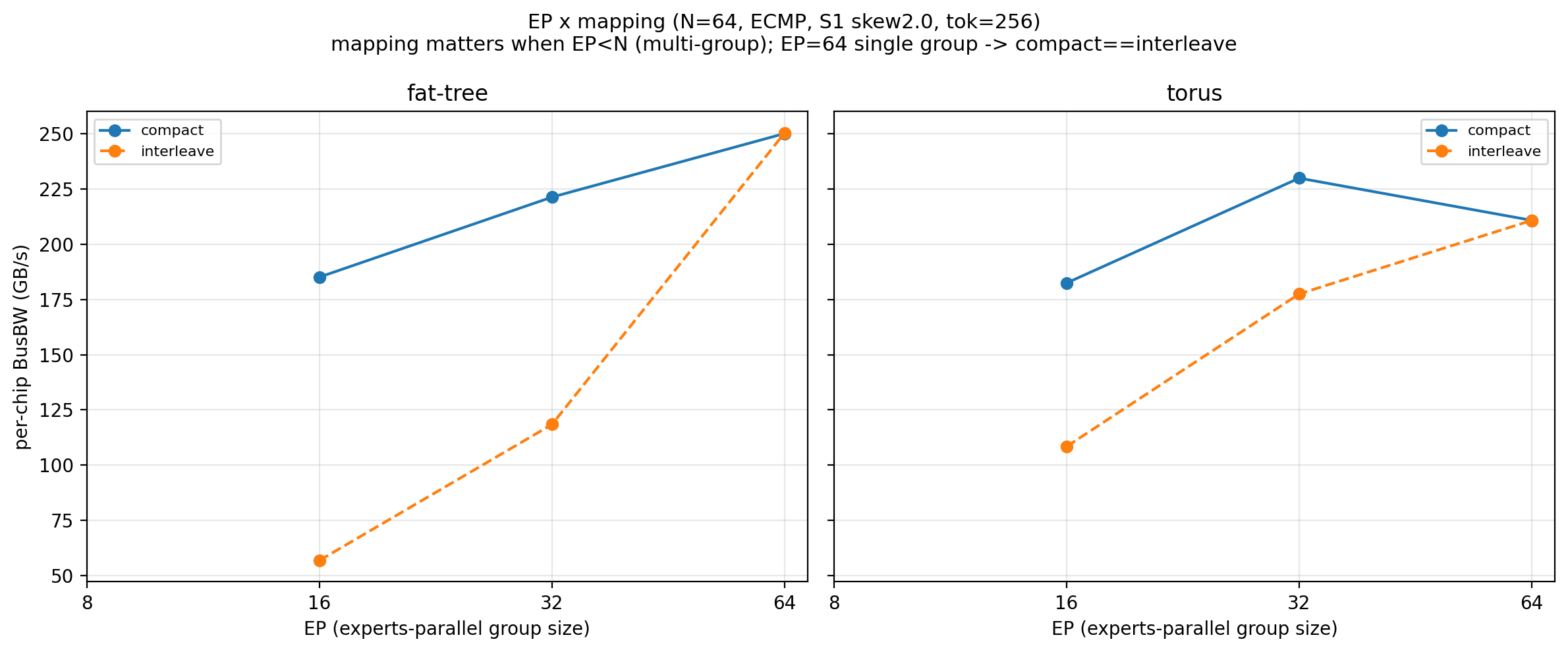
| EP (组数) | compact (GB/s) | interleave (GB/s) | compact / interleave |
|---|---|---|---|
| 16 (4 组) | 185.2 | 56.8 | 3.26× |
| 32 (2 组) | 221.4 | 118.4 | 1.87× |
| 64 (1 组) | 250.2 | 250.4 | 1.00× |
@tbl-a2av-placement N=64 fat-tree-k16 ECMP 下专家摆放对带宽的影响 (偏度 2.0, tok=256)
分析
fat-tree 网络先瓶颈:每芯片仅 1 个 uplink 接 leaf switch,跨 leaf 流量争 8 个 spine 的容量。完美均衡下 busbw 已卡在 294 GB/s (< 物理上限 400 GB/s),瓶颈在网络结构。
torus 网络充足:每芯片直连 6 邻居 (3 维双向),单方向可用网络带宽 400 GB/s,网络不瓶颈,完美均衡接近物理上限 (372 GB/s)。
SP 退化:单 Dijkstra shortest_path 在多 spine fat-tree 上每对源-目的只走固定一条等长路径,实际只用单 spine; ECMP 用 hash 把流量散到 32 条等长路径上,故 ECMP 比 SP 高 2.82×。生产部署默认 ECMP,这是路由对比的 fair baseline。
摆放机理:compact 把同一 EP 组的专家放在物理相邻 chip,组内流量就近、组间隔离;interleave 按 chip 顺序散布,跨 leaf 流量增加,争用 spine。EP = N 时只有 1 个组,无摆放自由度,两者退化为同一矩阵 (250.2 = 250.4) —— 这解释了为何只看 EP=64 切片会误判"摆放无差异"。
适用范围:
- 拓扑可达性:torus 4x4x4 需要 chip-to-chip 直连 6 邻居的专用互联 (TPU v4 单 cube / OCS 等);商用 GPU / AI 加速器一般不可达,此时 fat-tree 是次选
- 路由规模 scaling:dmodk vs ECMP 的差距随芯片数扩大 (N=32 fat-tree dmodk / ECMP = 1.00, N=64 = 1.29),外推 ≥256 芯片收益可能进一步增大,本研究未验证
- 摆放在 EP=N 下不可见:若部署 EP = 芯片数 (单组),摆放维度无差异;EP < 芯片数 (多组) 时必须选 compact
- 模型 top_k 差异影响拓扑倍数: torus/fat-tree 倍数 (ECMP) 随 top_k 增大缩小 — k4=1.45, k6=1.27, k8=1.23 (完美均衡)。高 top_k 模型矩阵更稠密,fat-tree 更接近 torus,拓扑选择重要性降低
- torus 形状选择:同 N=64 下 cube 形 (4x4x4) 优于扁平形 (2x4x8) 在完美均衡场景 ECMP +29% / DOR +46%,因 cube 直径更小;但 incast 主导时差异消失
KA2 — 专家负载偏度决定 EPLB 收益
结论
接收端 incast (热门专家所在 chip 接收远超均值流量,接收串行成 critical path) 是第二个瓶颈,EPLB 不是恒定收益,收益受专家负载偏度决定。在业界实测偏度区间 (NVIDIA TRT-LLM DeepSeek EP32 (max−mean)/mean=1.56 换算 RX max/mean=2.56[1], DeepSeek EPLB ~2.0[2];主线取下沿 2.0) 下,EPLB 提升 fat-tree 1.16× / torus 1.72× (有限);偏度升到 2.6 (NVIDIA 换算上沿) 收益 1.35× / 2.23×;偏度 3.0 后放大到 ≥1.6×;偏度 5.0 收益 3-4×;偏度 10.0 收益 7-9× (后两档属反事实假设)。
关键反例:未开 EPLB (偏度 2.0) 时 torus 明显劣于 fat-tree (210.9 vs 250.2 = 0.84×) —— torus 网络充足让接收 incast 直接成 critical path, fat-tree 因网络先瓶颈反而对 incast 不敏感。必须先开 EPLB,才能享受 torus 的网络优势。
数据
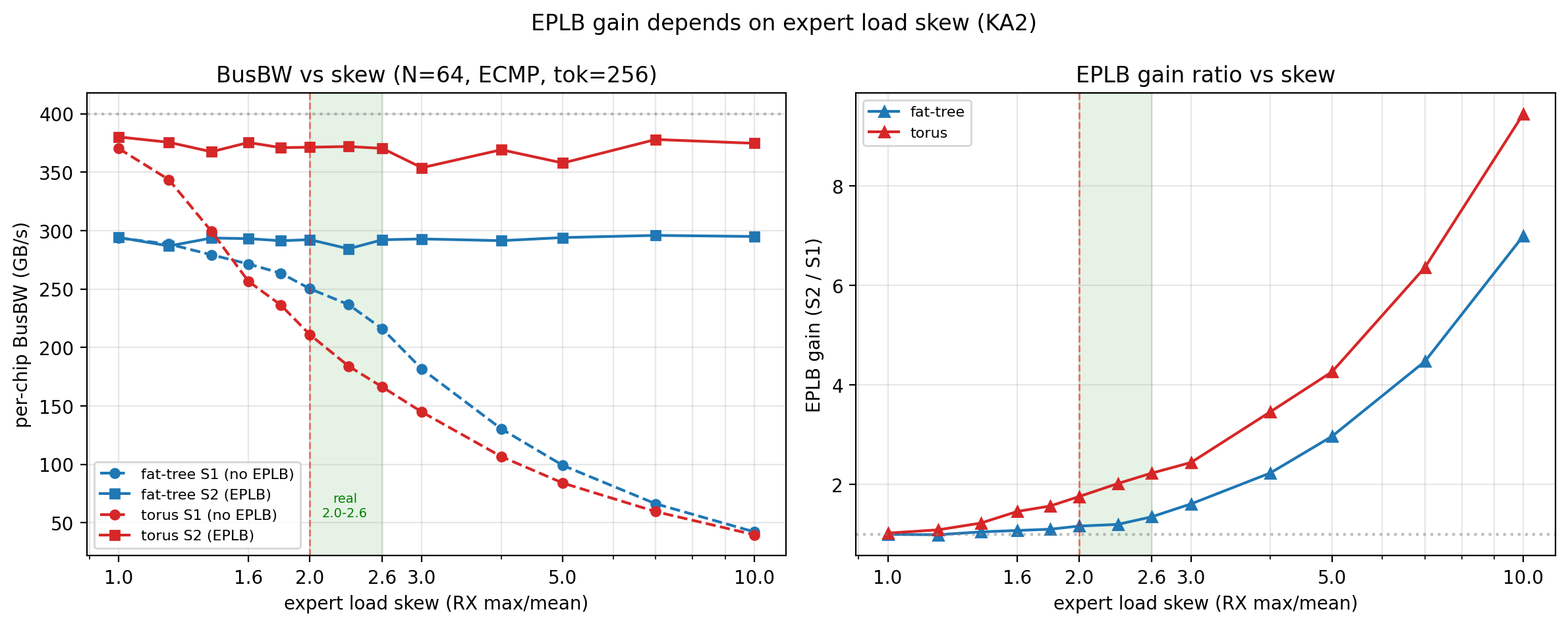
| 偏度 RX max/mean | fat-tree-k16 S1 / S2 / 提升 | torus-4x4x4 S1 / S2 / 提升 | 业界对应 |
|---|---|---|---|
| 1.6 | 271.4 / 293.1 / 1.08× | 256.6 / 374.1 / 1.46× | 部分均衡对照 |
| 2.0 (主线) | 250.2 / 289.6 / 1.16× | 210.9 / 361.8 / 1.72× | DeepSeek EPLB 实测下沿 |
| 2.6 | 215.9 / 292.1 / 1.35× | 166.1 / 370.4 / 2.23× | NVIDIA 换算 (1.56→2.56) 上沿 |
| 3.0 | 181.5 / 292.9 / 1.61× | 144.7 / 353.8 / 2.45× | EPLB 必要性拐点 |
| 5.0 | 99.0 / 294.0 / 2.97× | 83.9 / 357.8 / 4.27× | 反事实场景 |
| 10.0 | 42.2 / 294.9 / 7.00× | 39.7 / 374.7 / 9.45× | 反事实场景 |
@tbl-a2av-eplb-skew-curve EPLB 收益随专家负载偏度的曲线 (N=64, ECMP, tok=256; S1 = 未开 EPLB, S2 = 开启 EPLB 12.5% 冗余)。偏度 1.0–10.0 连续扫描 13 点,主线 2.0。完美均衡上界:fat-tree-k16 = 293.7 GB/s, torus-4x4x4 = 372.1 GB/s。
分析
EPLB 缓解的是接收端 incast 瓶颈。在主线偏度 2.0 下接收 incast 2.0× 均值,接收时间尚未远超网络瓶颈 (fat-tree 网络先瓶颈,torus 接近上限),EPLB 收益有限 (fat-tree 1.16×, torus 1.72×)。偏度增大后接收时间线性放大,超过网络瓶颈后 EPLB 收益从偏度 3 的 1.6× 升到偏度 10 的 9×。
拓扑差异:torus 对偏度敏感度约 2× 于 fat-tree (同偏度下 EPLB 收益更大),因为 torus 网络带宽充足,接收 incast 直接成 critical path; fat-tree 网络先瓶颈,接收 incast 收益部分被网络瓶颈稀释。
适用范围:
- 业界真实未均衡 (偏度 2.0-2.6):EPLB 收益 fat-tree 1.16-1.35×、torus 1.72-2.23× (主线 2.0)。提升幅度有限,仅在 torus 这种网络充足拓扑下显现可观收益
- EPLB 必要性拐点 (偏度 ≈ 3.0):超过此值 EPLB 收益放大到 ≥1.6×,适用于"不做 EPLB 的 baseline"或异常 workload (突发热点)
- 反事实极端偏度 (≥5.0):业界无公开实测,仅作 EPLB 上限参考。旧报告引用的 "EPLB 2-3×" 对应偏度 5 左右,是反事实假设
- DeepEP / EPLB 实现:真实使用的 redundant placement 比本研究的简化对照更精细,实测收益可能略高于本表
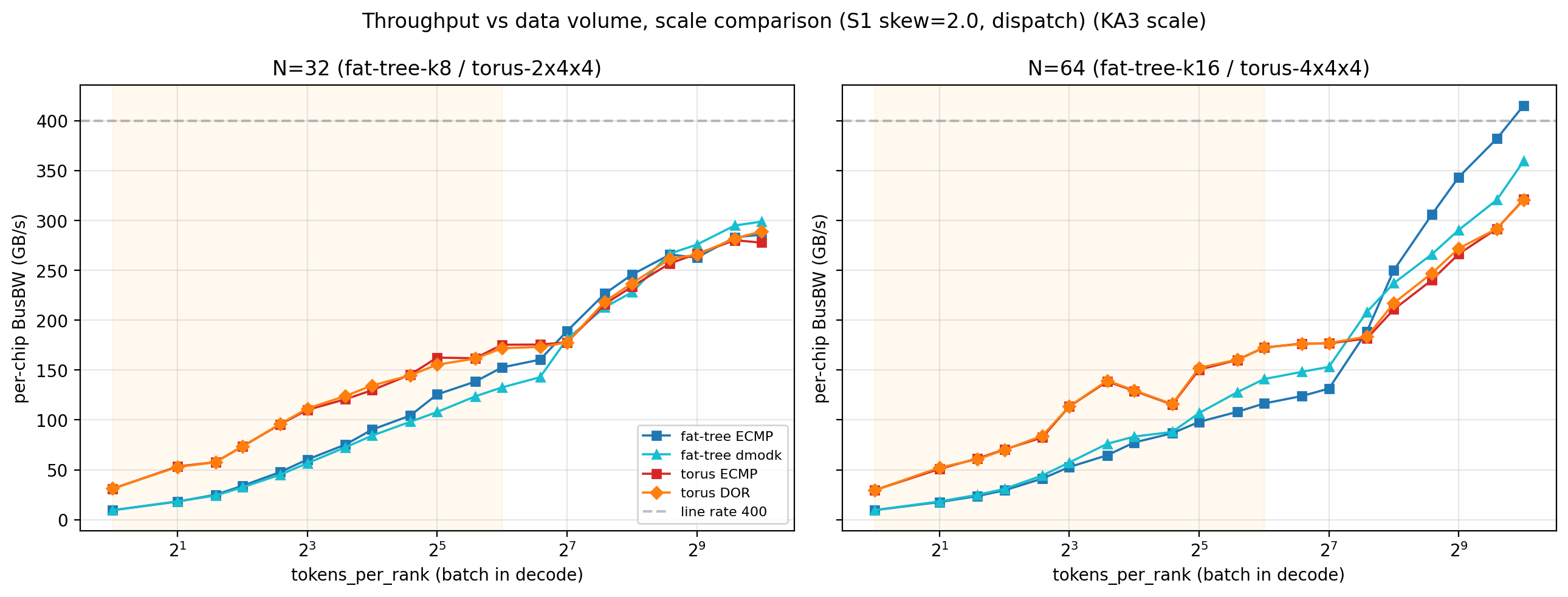
KA3 — 数据量、规模、方向划定结论适用边界
结论
网络传输与接收两侧的差异只在足够数据量下显现,随规模放大,在两个方向上镜像:
- 数据量:小 batch (tok < 64) 时所有路由 / 拓扑都在 alpha-bound 区 (网络启动 + 包头开销主导),选型差异消失;tok ≥ 256 才撑开差异
- 规模:dmodk 相对 ECMP 的收益随规模放大 — N=32 完美均衡 dmodk 与 ECMP 持平 (419 vs 419), N=64 拉开到 1.29×
- 方向:combine 是 dispatch 的转置 (字节翻倍 BF16 vs FP8),流量发送集中、接收分散 (无接收 incast)。combine 的 per-chip 带宽对所有拓扑相同 (226.4 GB/s,仅随数据量变),因为瓶颈落在发送 chip 的 CDMA 出口 (芯片本地资源,拓扑无关),而非网络;dispatch 的接收 incast 瓶颈在网络汇聚 (拓扑相关)。含义:拓扑选型只改善 dispatch, combine 受芯片出口限制,换拓扑不改善,故 (拓扑,路由) 推荐只看 dispatch
数据
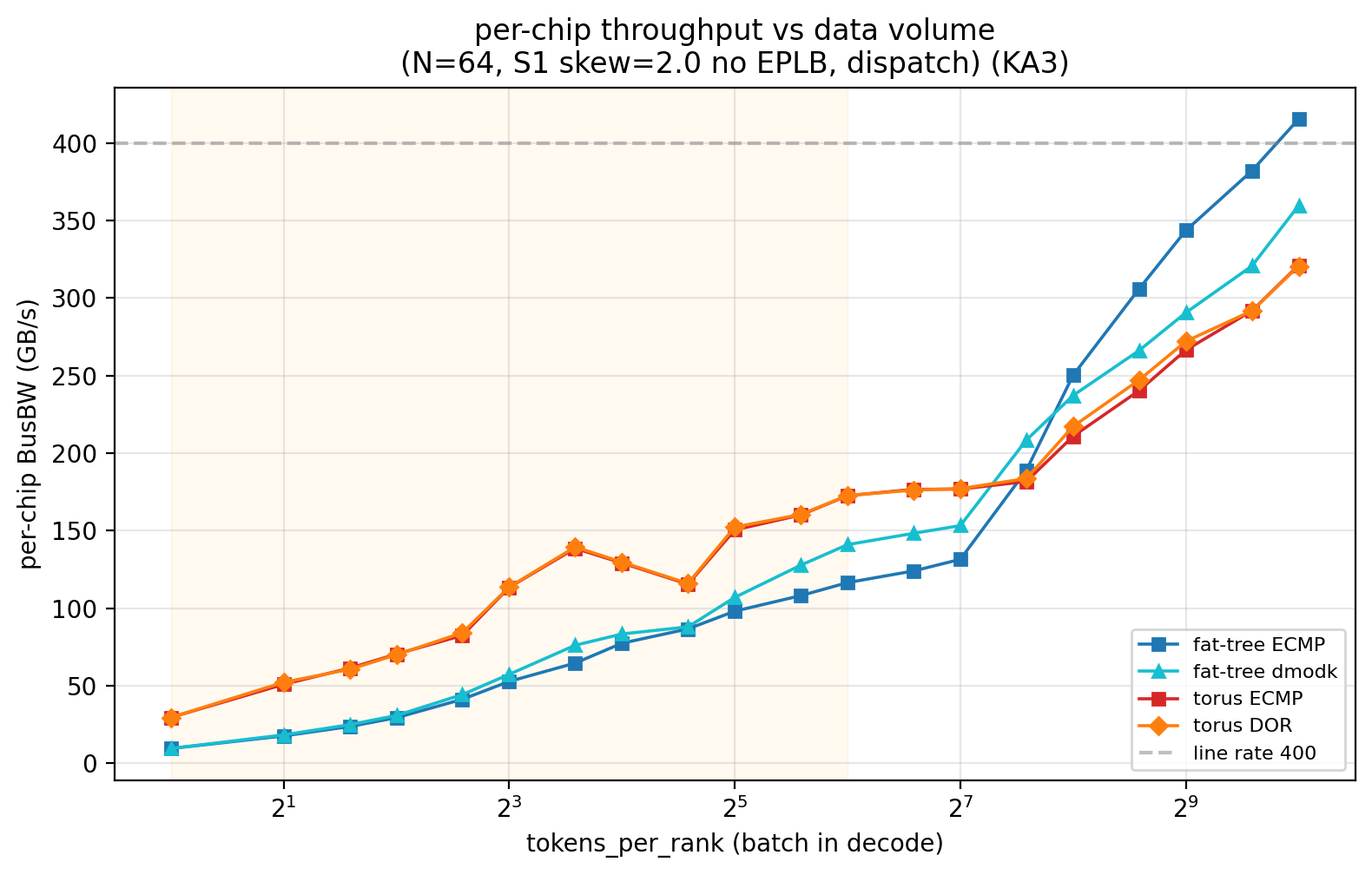
| tokens_per_rank | fat-tree-k16 ECMP (GB/s) | torus-4x4x4 ECMP (GB/s) |
|---|---|---|
| 1 | 10 | 30 |
| 16 | 77 | 129 |
| 64 | 116 | 173 |
| 128 | 131 | 177 |
| 256 | 250 | 211 |
| 512 | 344 | 266 |
| 1024 | 415 | 321 |
@tbl-a2av-tok-curve 数据量曲线:N=64 ECMP 未开 EPLB 时 per-chip 带宽随 tokens_per_rank 的变化 (GB/s)
| N | 完美均衡 dmodk | 完美均衡 ECMP | dmodk / ECMP |
|---|---|---|---|
| 32 (fat-tree-k8) | 419.8 | 419.8 | 1.00× |
| 64 (fat-tree-k16) | 380.2 | 293.7 | 1.29× |
@tbl-a2av-scale-curve dmodk vs ECMP 的规模拐点 (heavy / tok=256,完美均衡)
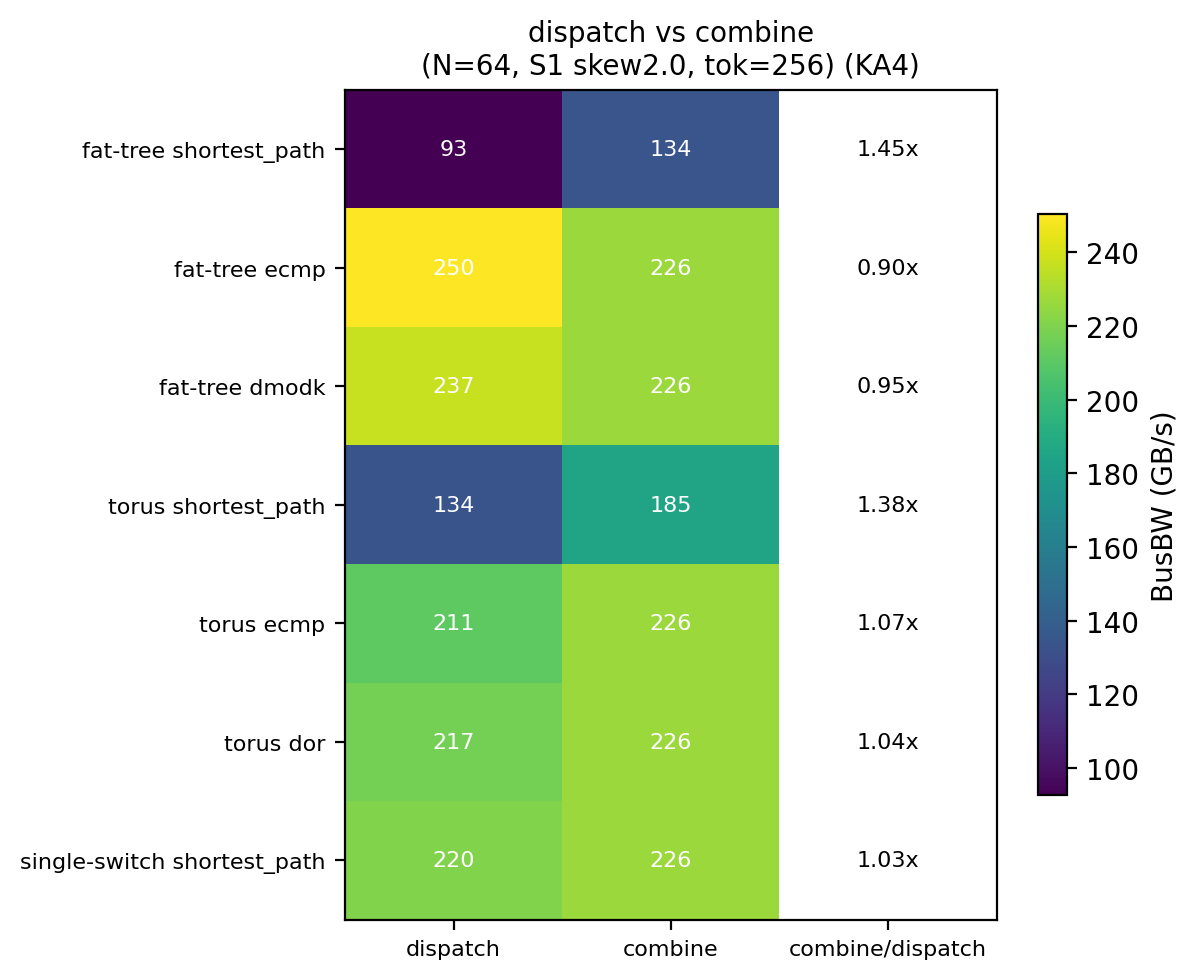
| 拓扑 | dispatch 带宽 | combine 带宽 | combine / dispatch |
|---|---|---|---|
| fat-tree-k16 ECMP | 250.2 | 226.4 | 0.90× |
| torus-4x4x4 ECMP | 210.9 | 226.4 | 1.07× |
@tbl-a2av-combine-mirror N=64 未开 EPLB (偏度 2.0) heavy 下 dispatch vs combine 带宽对比。combine 列所有拓扑同值 226.4,因 combine 瓶颈在发送 CDMA 出口 (芯片本地,拓扑无关),非数据错误。
分析
数据量拐点机理:tok < 64 时 alpha (网络启动 + 包头开销) 主导,路由几乎不可能产生差异 (流量太少,各路由都用得起所有路径);tok ≥ 256 后流量足够拥挤,路由的散布质量才显现。
规模拐点机理:fat-tree-k8 (4 spine) ECMP 已能填满 spine 容量;fat-tree-k16 (8 spine) ECMP hash 在 spine 间分布不够均匀,dmodk 显式公式才能压满每个 spine。规模越大 spine 越多,dmodk 优势越大。
方向不对称机理:dispatch 接收 incast (少数 hot_dst 收得多),瓶颈在接收侧网络汇聚,随拓扑入边数变 (torus 6 / fat-tree 1) → 拓扑相关。combine 是 dispatch 转置,发送集中、接收分散 (无接收 incast),瓶颈转到发送 chip 的 CDMA 出口 (芯片本地资源,拓扑无关) → 所有拓扑同值 226.4 GB/s,仅随数据量变。含义:换拓扑只改善 dispatch 方向,combine 受发送出口限制不随拓扑变;故 (拓扑,路由) 推荐以 dispatch 为准。
适用范围:
- 小数据量 (tok ≤ 64) alpha-bound 区对 switch latency 敏感:fat-tree light batch 下 switch_latency 从 100ns 增到 2000ns, busbw 降 27%; torus 直连无 switch 不受影响。decode heavy (tok ≥ 128) 几乎不敏感 (见限制段)
- 规模外推:dmodk vs ECMP 的差距随芯片数扩大,外推 ≥ 256 芯片收益可能更大,本研究上限仅到 64
- 方向假设:结论仅在"combine 严格转置"假设下成立。真实 DeepEP combine 可能有额外 reduce 操作,实际带宽可能略低
- 学术拓扑无推荐:hypercube / dragonfly / hyperx / ring 数据仅用于路由算法理论参考,不进部署推荐 (见 design.md 拓扑覆盖分层)
部署建议
各场景可部署推荐组合 (N=64, heavy / tok=256, ECMP baseline)
| 部署阶段 | 偏度 | 首选 (硬件可达时) | 次选 (商用通用) | per-chip BW (GB/s) |
|---|---|---|---|---|
| 训练初期 / 完美均衡 | 1.0 | torus-3D 4x4x4 + ECMP | fat-tree-k16 + dmodk | 372 / 380 |
| 实际部署,未开 EPLB | 2.0 | fat-tree-k16 + ECMP | torus 此时 0.84× 劣,须先开 EPLB → 见下行 | 250 |
| 开启 EPLB | 2.0 | torus-3D 4x4x4 + ECMP | fat-tree-k16 + dmodk | 362 / 376 |
| 异常 workload / 未做 EPLB | 3.0+ | torus-3D 4x4x4 + ECMP + 开 EPLB | fat-tree-k16 + ECMP + 开 EPLB | 见 KA2 偏度曲线 |
@tbl-a2av-recommendation 各部署阶段的推荐 (拓扑,路由) 组合。所有 EP < 芯片数 (多组) 部署一律选 compact 摆放 (见 KA1)。
torus-3D 4x4x4 对应 TPU v4 单 cube 硬件,chip-to-chip 直连 6 邻居需要专用互联。商用 GPU / AI 加速器在不具备此能力时,次选 fat-tree。
优化优先级 (业界真实偏度 2.0, N=64, ECMP 路由 baseline)
| 优化项 | 实测收益 | 触发条件 | 实施位置 |
|---|---|---|---|
| fat-tree 路由从 SP 换 ECMP | 2.82× | 当前用 SP 的部署 | 软件层 (NCCL 配置) |
| EP < N 时摆放从 interleave 换 compact | 约 1.9-3.3× | 多组 EP 部署 | 软件层 (专家放置策略) |
| 开启 EPLB (torus) | 1.72× | torus 部署 + 偏度 ≥ 2.0 | 软件层 (DeepEP / EPLB 库) |
| 拓扑选 torus (vs fat-tree) | 1.25× (S2 已开 EPLB) / 0.84× (S1 未开 EPLB,反而劣势) | 硬件可达专用直连 + 已开 EPLB | 硬件层 (部署决策) |
| fat-tree 上 ECMP → dmodk | 1.29× | N ≥ 64 + (完美均衡 OR 已开 EPLB) + tok ≥ 256 | 软件层 (G5 已支持) |
| 开启 EPLB (fat-tree) | 1.16× | fat-tree 部署 + 偏度 ≥ 2.0 | 软件层 (DeepEP / EPLB 库) |
@tbl-a2av-priority alltoallv 带宽优化的优先级 (真实偏度 2.0 下)
与旧报告差异:旧报告写 "开启 EPLB 2-3×",基于偏度 5+ 的反事实假设。真实部署偏度 2.0-2.6 下 EPLB 提升 1.16-2.23× (与拓扑相关)。
部署优化执行顺序:软件层最直接见效是"如果还在用 SP 换 ECMP"(2.82×) 与"多组 EP 用 compact 摆放"(2-3×); torus 部署上 EPLB 提升 1.72×, fat-tree 部署上仅 1.16×。关键:未开 EPLB 时 torus 明显劣于 fat-tree (0.84×) —— 必须先开 EPLB 才能享受 torus 的网络优势 (见 KA2)。
限制与未来工作
-
未模拟 NVLink + RDMA 两段非对称带宽:本研究用平坦单层 c2c (400 GB/s 一致)。真实部署 NVLink (~160 GB/s 节点内) + RDMA (~50 GB/s 跨节点) 两段差异,DeepEP normal kernel 的转发优化未覆盖,实际部署 fat-tree 跨节点段会成为新瓶颈
-
未模拟 wave-scheduled fine-grained EP:V4 实际把 alltoallv 切 8-16 wave,每 wave 矩阵更小。本研究单次大矩阵 = 多 wave 累加上界,实际单 wave 行为可能不同
-
EPLB 放置策略只测 naive / 单冗余度:DeepEP 真实使用的"node-limited 路由 + redundant placement"是更复杂的拓扑感知放置,本研究的开启 EPLB 是简化对照,真实 EPLB 收益可能略高
-
EPLB 偏度区间数据已补齐 (旧版缺口已闭合):偏度 1.0–10.0 连续 13 点,每点 S1 / S2 配对,KA2 收益曲线在主线 2.0 与真实区间 2.0–2.6 均有实测点,不再靠外推
-
batch 维度已加密至 20 档 (旧版 11 档已加密):alpha → bandwidth 转折点 (tok=64 附近) 已平滑可见,含 {3,6,12,24,48,96,192,384,768} 等中间档
-
hyperx 未接入 DOR 路由:hyperx 上 DOR 理论可用,本研究只测了 shortest_path / ECMP, hyperx 路由对比不完整
-
芯片数上限仅到 64:dmodk vs ECMP 的差距随芯片数扩大,外推 ≥ 256 芯片收益可能更大,但本研究未验证
-
学术对照拓扑不进部署推荐:hypercube-6d / dragonfly / hyperx / ring 的数据仅用于路由算法理论行为参考,这些拓扑在现代 32 / 64 芯片生产部署中罕见或不存在 (见 design.md 拓扑覆盖分层)
-
极端偏度 (≥3.0) 是反事实场景:业界换算后的真实未均衡区间是 2.0-2.6 (NVIDIA (max−mean)/mean=1.56→max/mean=2.56, DeepSeek EPLB ~2.0),本研究的偏度 ≥ 3.0 数据用于刻画 EPLB 收益的上限和拐点,不代表生产部署的真实状态
-
switch forwarding latency 敏感度:本研究主网格固定 1000 ns (商用 ToR 量级)。扫描 {100, 300, 500, 1000, 2000} ns 显示,decode heavy (tok=256) 下 4 个 KA 主结论几乎不变,仅小数据量 alpha-bound 区敏感 (fat-tree tok=64 从 sw100 → sw2000 降 27%, torus 不受影响)。在 cut-through 交换机 (~300 ns) 下 decode 段结论仍成立
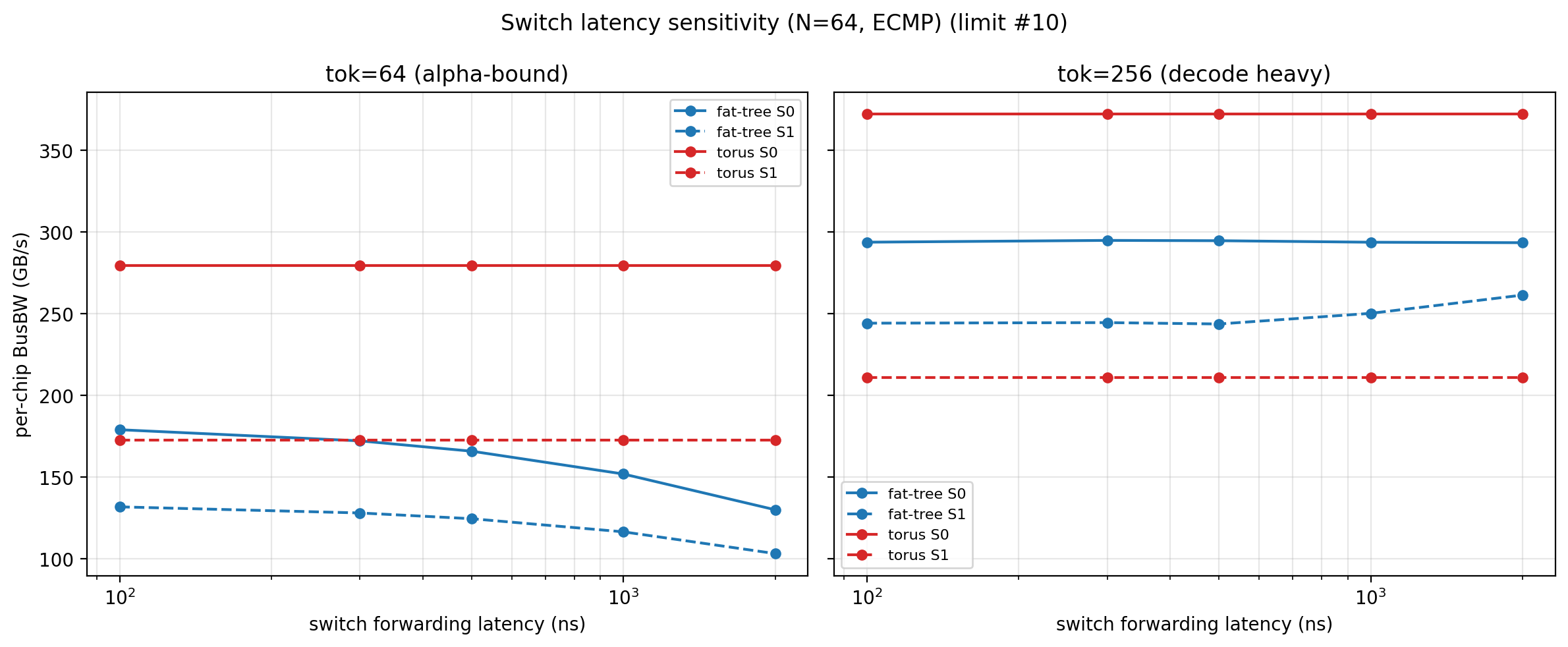
-
ECMP max_paths 敏感度:本研究主网格 max_paths=32 (上限)。扫描 {4, 8, 16, 32} 显示 fat-tree-k16 上 busbw 完全不变 (完美均衡 294 ± 0.5;未开 EPLB 250 ± 0.5)。fat-tree-k16 只有 8 个 spine, max_paths=4 已能覆盖足够多等长路径。部署时硬件 ECMP table 设 4 即可,无需配 32
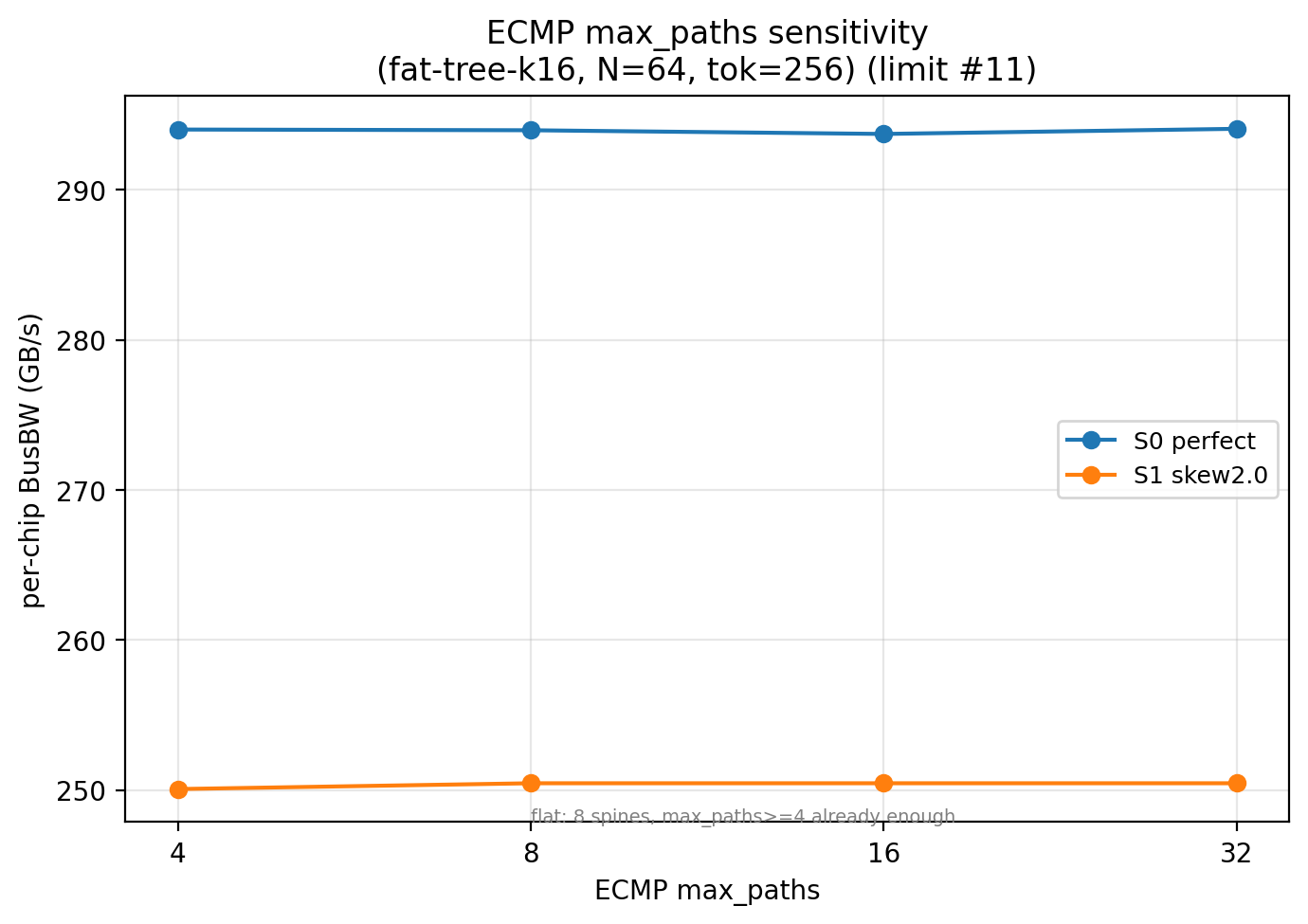
-
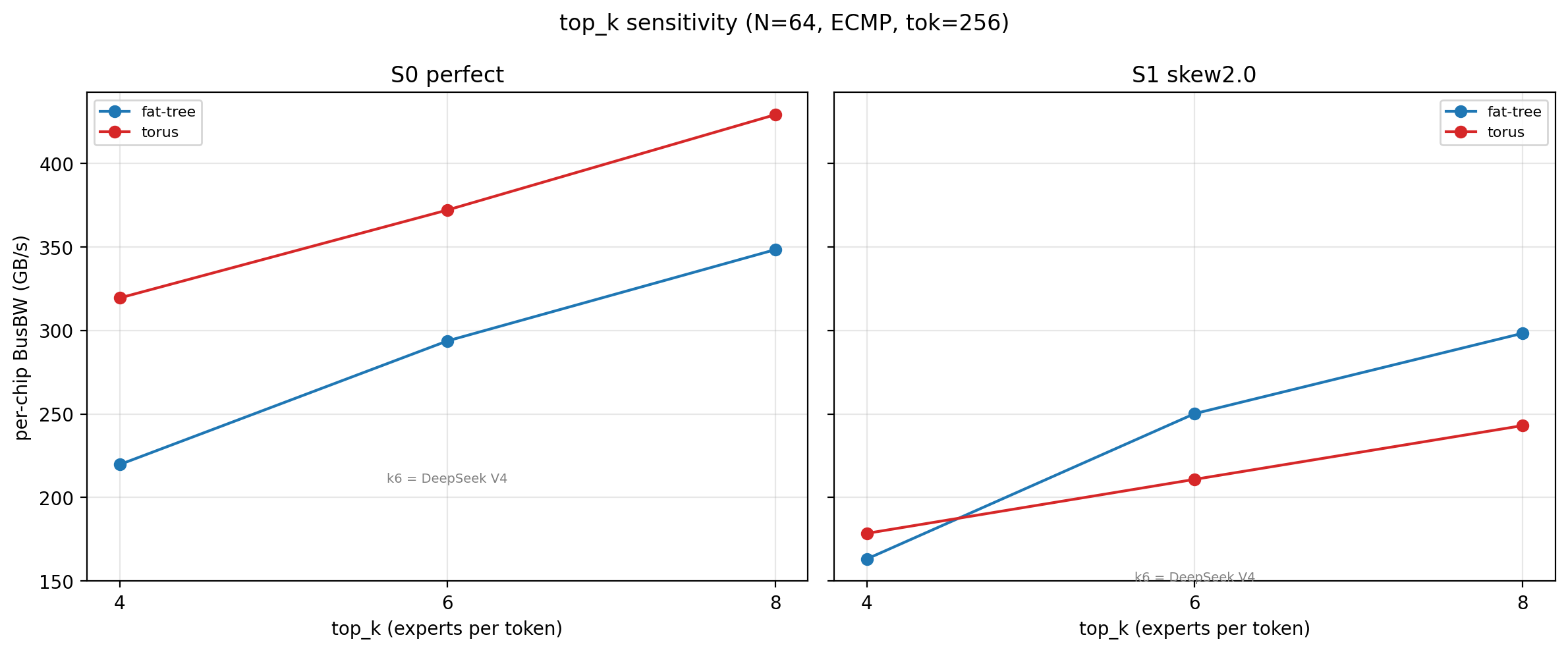
模型 top_k 敏感度:本研究主网格 top_k=6 (DeepSeek V4)。扫描 {4, 6, 8} 显示绝对带宽与 top_k 强相关 (k4 约打折至 63%, k8 约 1.5×),但 EPLB 提升倍数与拓扑相对优劣的结论方向不变,拓扑倍数随 top_k 增大而缩小
-
fat-tree 超订比 osr=1:本研究只测严格 Clos (osr=1, d=u=k/2)。商用 2:1 / 3:1 超订部署受限于 d 必须整除 N 的几何约束,需独立设计新 (k, N) 组合评估。理论上超订使 fat-tree 跨 leaf 带宽折扣 1/osr, torus 不受影响
-
single-switch 未进 KA 主对比:single-switch (大 NVSwitch / 单 spine 直挂) 是 1-hop 直达,带宽上限即 chip 出向 line rate 减 incast 损失,跟 fat-tree 跨 leaf / torus 多跳的路径长度对比不在同一维度。完整 single-switch 数据见 v3 数据集 (experiment alltoallv-topo-routing-v3, topo=single-switch)
参考资料
- NVIDIA TRT-LLM DeepSeek-V3 EP32 部署实测,来源见 MoE EP alltoallv 拓扑与路由的性能评估:实验设计 §流量形态 引用清单。
- SGLang DeepEP 部署博客,同上。