Fat-Tree 拓扑族通信评估
评估范围
在 64 芯片 Fat-Tree 拓扑上,评估不同配置、通信算法和消息大小对集合通信延迟的影响。评估维度见 ,通信算法覆盖见 。
| 维度 | 范围 |
|---|---|
| 拓扑配置 | 2L-k16-osr1, 2L-k8-osr1, 2L-k12-osr2, 3L-k8-osr1(均 64 芯片) |
| 通信组大小 | TP: 2, 4, 8, 16; EP: 32, 64 |
| 消息大小 | 32KB, 64KB, 128KB, 256KB, 512KB, 1MB, 2MB, 4MB |
| 通信原语 | AllReduce, AllGather, ReduceScatter, AllToAll |
| 路由算法 | shortest_path |
@tbl-ft-eval-scope 评估维度与范围
| 原语 | 算法 |
|---|---|
| AllReduce | Ring, Halving-Doubling (HD), Double Binary Tree (DBT) |
| AllGather | Ring, Recursive Doubling (RD) |
| ReduceScatter | Ring, Recursive Halving (RH) |
| AllToAll | Pairwise, Bruck |
@tbl-ft-algo-coverage 各原语评估的通信算法
硬件参数:SG2262 芯片,c2c 带宽 400 GB/s,链路延迟 0.025 us,交换机转发延迟 1.0 us。
Fat-Tree 配置说明
4 种配置覆盖层数、leaf 粒度、等分带宽三个维度,参数与结构见 。
| 配置 | 层数 | k (radix) | OSR | d (下行) | u (上行) | Leaf | Spine/Core | 总交换机 | 芯片/Leaf |
|---|---|---|---|---|---|---|---|---|---|
| 2L-k16-osr1 | 2 | 16 | 1:1 | 8 | 8 | 8 | 8 spine | 16 | 8 |
| 2L-k8-osr1 | 2 | 8 | 1:1 | 4 | 4 | 16 | 4 spine | 20 | 4 |
| 2L-k12-osr2 | 2 | 12 | 2:1 | 8 | 4 | 8 | 4 spine | 12 | 8 |
| 3L-k8-osr1 | 3 | 8 | 1:1 | 4 | 4 | 16 ToR | 16 Agg + 16 Core | 48 | 4 |
@tbl-ft-configs Fat-Tree 配置参数
其中 k 为交换机端口数(radix),OSR 为超订比(downlink:uplink),d/u 为下行/上行端口数,满足 $d = \text{round}(k \cdot \text{osr} / (\text{osr} + 1))$,$u = k - d$。
- 2L-k16-osr1:标准 2 层 Spine-Leaf,全等分带宽(8 spine = 8 leaf),每 leaf 下挂 8 芯片
- 2L-k8-osr1:更多 leaf(16 个),每 leaf 仅 4 芯片,spine 也只有 4 个
- 2L-k12-osr2:2:1 超订,spine 数量减半(4 vs 8),等分带宽为标准配置的 50%
- 3L-k8-osr1:经典 3 层 Fat-Tree(4 个 pod,每 pod 4 ToR + 4 Agg,16 Core),跨 pod 通信需经 3 级交换机
通信组与芯片放置
通信组划分、并行策略和评估方法的详细说明参见 TPS186 通信原语评估。
Fat-Tree 上通信组由连续芯片 ID 组成。由于 Fat-Tree 不是对称拓扑(不同 leaf 下的芯片到其他 leaf 的路径结构不同),不同位置的通信组性能可能不同。但板级模型(每 8 芯片一个 board,板内 full-mesh 直连)使得:
- TP <= 8:整个通信组在同一 board 内,通信走板内直连,不经过任何交换机
- TP = 16:跨 2 个 board,但跨 board 通信的跳数(chip → leaf → spine → leaf → chip)在所有 Fat-Tree 配置中相同
- EP:全局通信(EP=32/64),大量跨 leaf 流量,拓扑配置显著影响延迟
TP 通信评估
拓扑配置对 TP 的影响
4 种 Fat-Tree 配置在所有 TP 值和消息大小上的 AllReduce Ring 延迟见 。
| TP | Size | 2L-k16 | 2L-k8 | 2L-k12-osr2 | 3L-k8 |
|---|---|---|---|---|---|
| 2 | 64KB | 1.503 | 1.503 | 1.503 | 1.503 |
| 2 | 1MB | 4.120 | 4.120 | 4.120 | 4.120 |
| 4 | 64KB | 2.835 | 2.835 | 2.835 | 2.835 |
| 4 | 1MB | 7.964 | 7.964 | 7.964 | 7.964 |
| 8 | 64KB | 4.731 | 4.731 | 4.731 | 4.731 |
| 8 | 1MB | 17.449 | 17.449 | 17.449 | 17.449 |
| 16 | 64KB | 11.241 | 11.241 | 11.241 | 11.241 |
| 16 | 1MB | 40.041 | 40.041 | 40.041 | 40.041 |
@tbl-ft-tp-topo AllReduce Ring 延迟:4 种配置完全一致 (us)
所有 4 种 Fat-Tree 配置的 TP 延迟完全相同。 原因是板级模型使 TP 通信不经过 Fat-Tree 的交换机网络:
- TP <= 8:通信组(chip 0-7)完全在同一 board 内,走板内 full-mesh 直连(1 跳 c2c),不触及任何 leaf/spine 交换机
- TP = 16:跨 2 个 board(chip 0-7 + chip 8-15),Ring 中只有 chip 7→8 和 chip 15→0 两步跨 board。这两步的路径(chip → leaf → spine → leaf → chip)在所有配置中跳数相同,因此延迟相同
Fat-Tree 的 leaf 数量、spine 数量、层数和超订比对 TP 通信无影响。TP 性能由板级互联参数(c2c 带宽 400 GB/s,链路延迟 0.025 us)完全决定。
算法对比
由于拓扑配置不影响 TP,以下在 2L-k16-osr1 上对比算法。
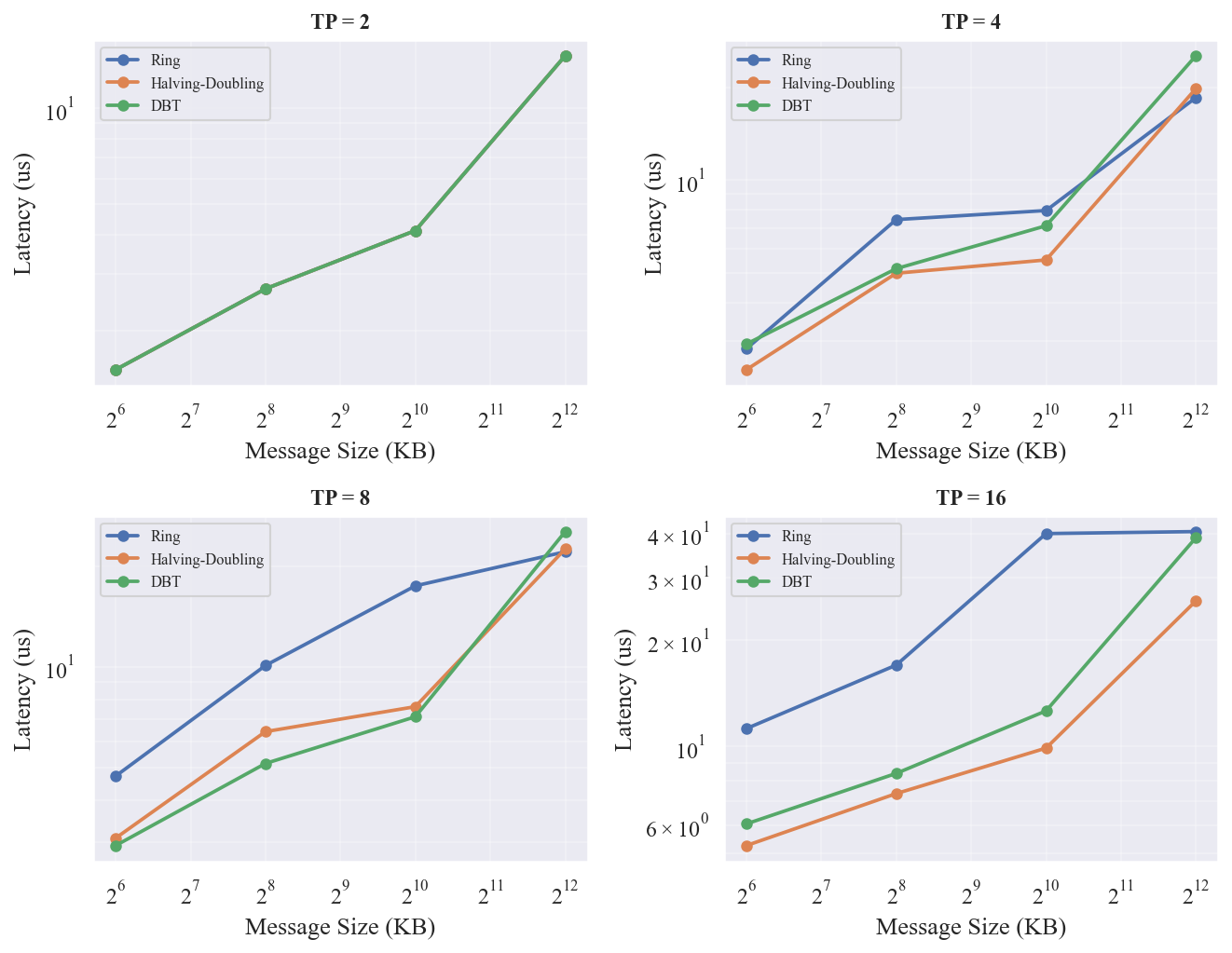
AllReduce 在 TP=2 时所有算法退化为相同行为(单步通信)。TP >= 4 时 Halving-Doubling 显著优于 Ring,TP=16 时 HD 加速最明显(1MB: HD 9.90 us vs Ring 40.04 us,4.0x 加速)。DBT 在 TP=8 时与 HD 接近,但 TP=16 时略慢。各原语的最优算法汇总见 、、。
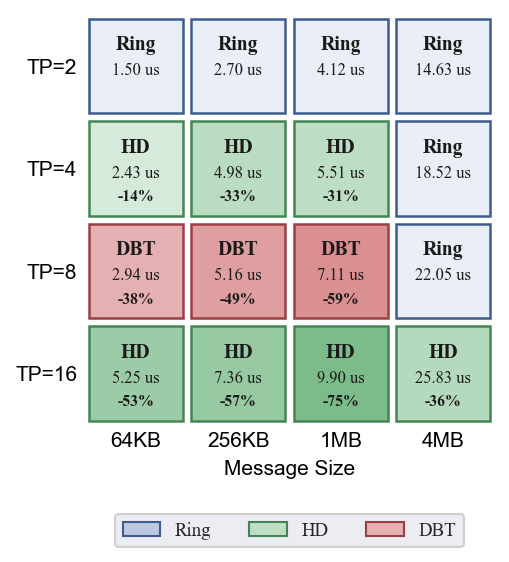
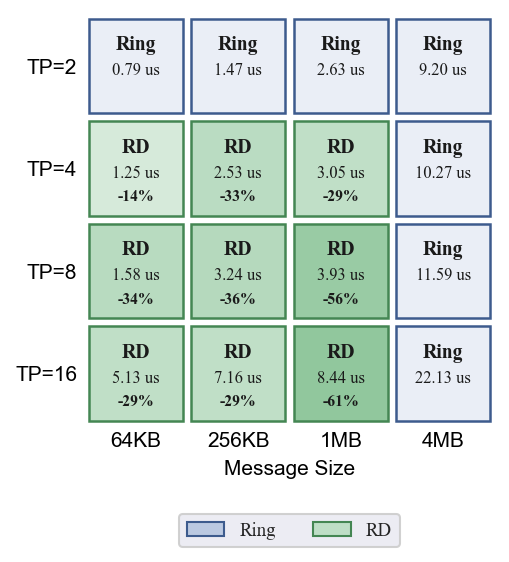
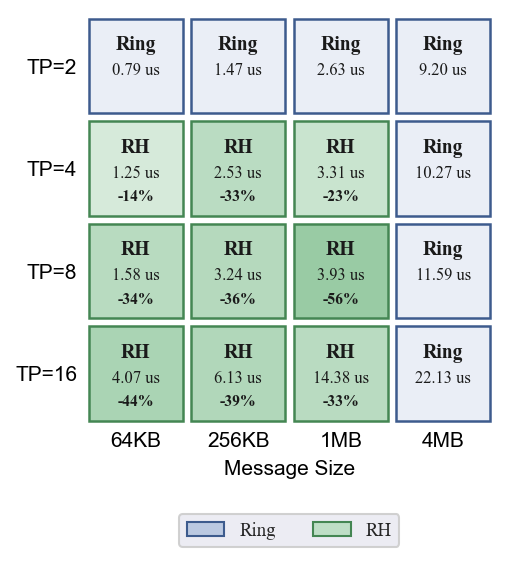
- AllReduce:TP=2 Ring 最优;TP=4 小消息 HD 优,大消息 Ring;TP=8 DBT 全面领先(最高 -59%);TP=16 HD 全面领先(最高 -75%)
- AllGather:TP >= 4 时 Recursive Doubling 显著优于 Ring
- ReduceScatter:TP >= 4 时 Recursive Halving 显著优于 Ring
EP AllToAll 评估
EP AllToAll 是全局通信,大量流量跨 leaf 走交换机网络,Fat-Tree 的配置参数直接影响延迟。
拓扑配置对比
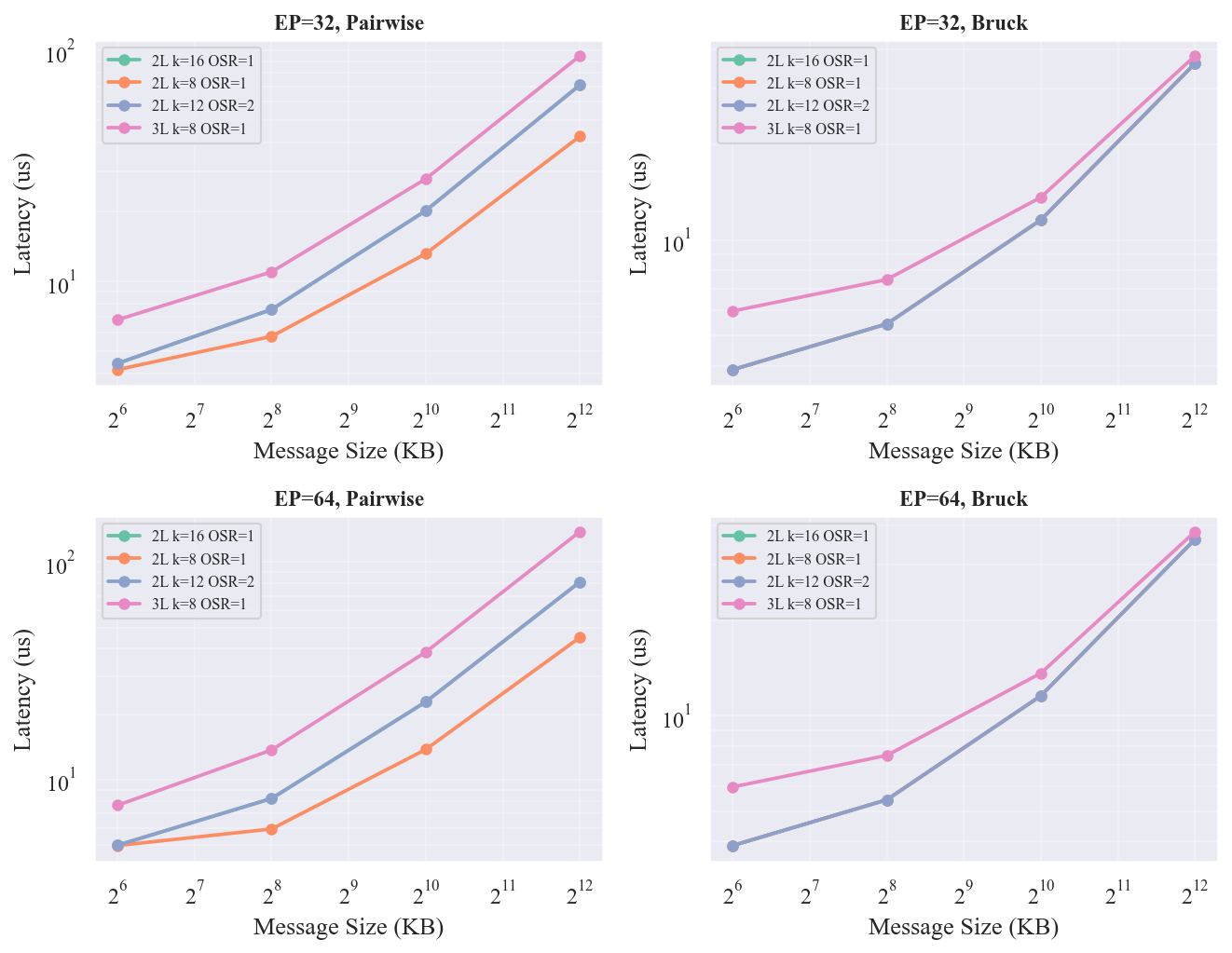
| 配置 | EP=32 Pairwise | EP=32 Bruck | EP=64 Pairwise | EP=64 Bruck |
|---|---|---|---|---|
| 2L-k16-osr1 | 20.25 | 11.57 | 22.79 | 11.57 |
| 2L-k8-osr1 | 13.19 | 11.57 | 13.77 | 11.57 |
| 2L-k12-osr2 | 20.25 | 11.57 | 22.79 | 11.57 |
| 3L-k8-osr1 | 27.82 | 13.64 | 38.61 | 13.64 |
@tbl-ft-ep-topo AllToAll 1MB 延迟 (us)
关键发现:
Pairwise 对 Fat-Tree 配置极敏感:
- 2L-k8 最快(13.77 us):16 个 leaf 各 4 芯片,每对 leaf 之间有 4 条等价 spine 路径。单 leaf 下挂芯片少,跨 leaf 流量分散程度最高
- 2L-k16 和 2L-k12-osr2 相同(22.79 us):两者都是 8 芯片/leaf,8 个 leaf。虽然 k12-osr2 只有 4 spine(vs k16 的 8 spine),但 Pairwise 的分步调度使每步只有部分流量过 spine,4 spine 未成瓶颈
- 3L 最慢(38.61 us):跨 pod 通信需经 ToR → Agg → Core → Agg → ToR(6 跳 vs 2L 的 4 跳),额外 2 级交换机转发延迟(各 1.0 us × 2 方向 = 4.0 us 额外开销)
Bruck 对 2L 配置不敏感:所有 2L 配置延迟完全相同(11.57 us),原因与 Torus 评估中类似——Bruck 的 $\lceil \log_2 N \rceil$ 步调度中,每步数据量大(~2MB),CDMA 注入时间远大于路径差异。3L 仅比 2L 慢 18%(13.64 vs 11.57 us),虽然跳数差异更大,但 Bruck 的步数优势(6 步 vs Pairwise 的 63 步)大幅削弱了跳数的影响。
算法对比
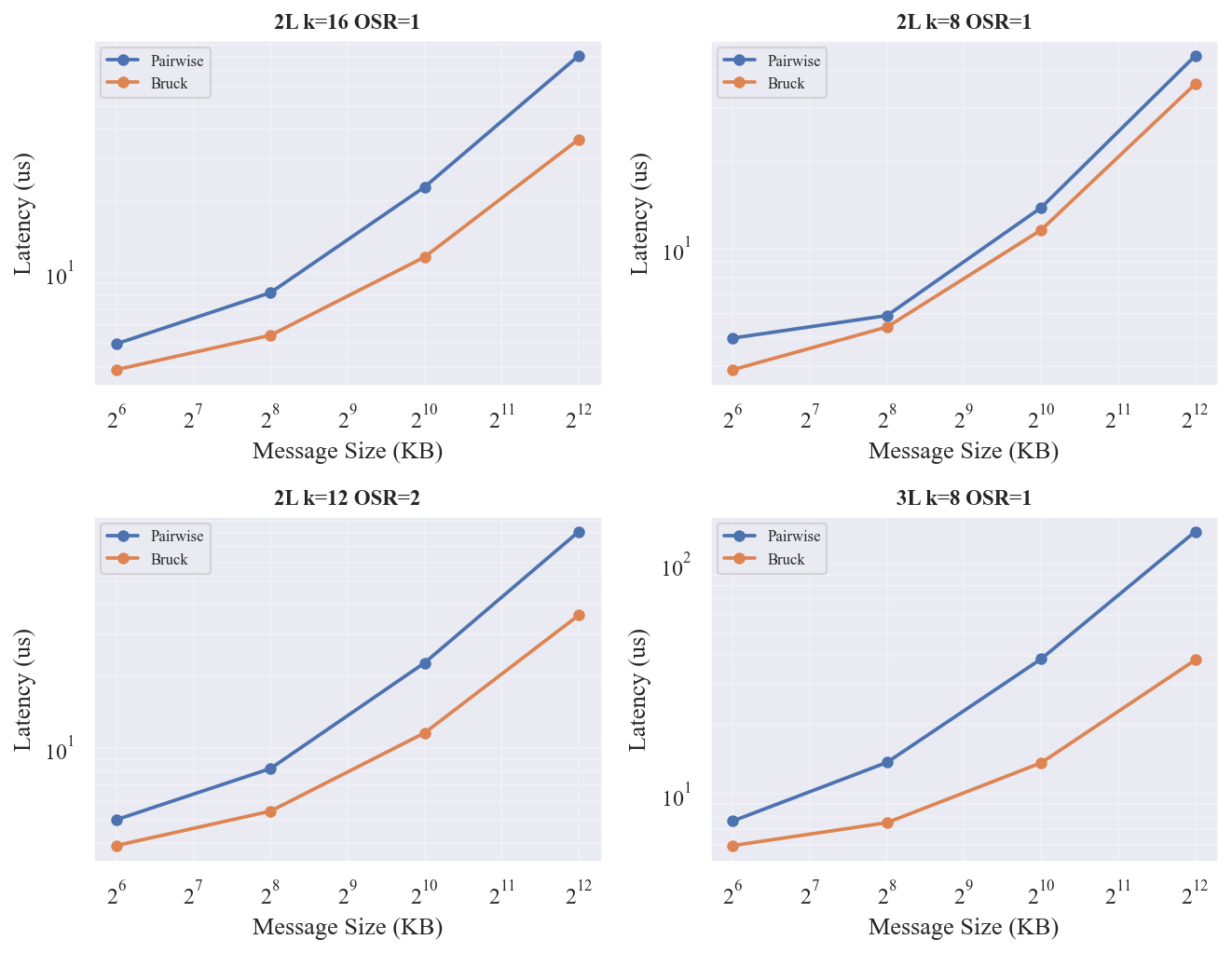
Bruck 在所有 Fat-Tree 配置上均优于 Pairwise。EP=64 时各配置的 Bruck 加速比见 。
| 配置 | Pairwise (us) | Bruck (us) | Bruck 加速 |
|---|---|---|---|
| 2L-k16-osr1 | 22.79 | 11.57 | 1.97x |
| 2L-k8-osr1 | 13.77 | 11.57 | 1.19x |
| 2L-k12-osr2 | 22.79 | 11.57 | 1.97x |
| 3L-k8-osr1 | 38.61 | 13.64 | 2.83x |
@tbl-ft-ep-speedup EP=64 AllToAll 1MB Bruck vs Pairwise 加速
Bruck 的优势在交换机拓扑上比直连拓扑(Torus)更显著。Pairwise 在 Fat-Tree 上每步都要经过交换机网络(N-1=63 步),交换机转发延迟逐步累积。Bruck 只需 $\lceil \log_2 64 \rceil = 6$ 步,虽然每步数据量更大(bandwidth overhead factor ~2),但步数减少 10x 带来的延迟节省远超带宽损失。3L Fat-Tree 上 Bruck 加速最大(2.83x),因为 3L 的交换机跳数最多,Pairwise 受影响最重。
2 层 vs 3 层
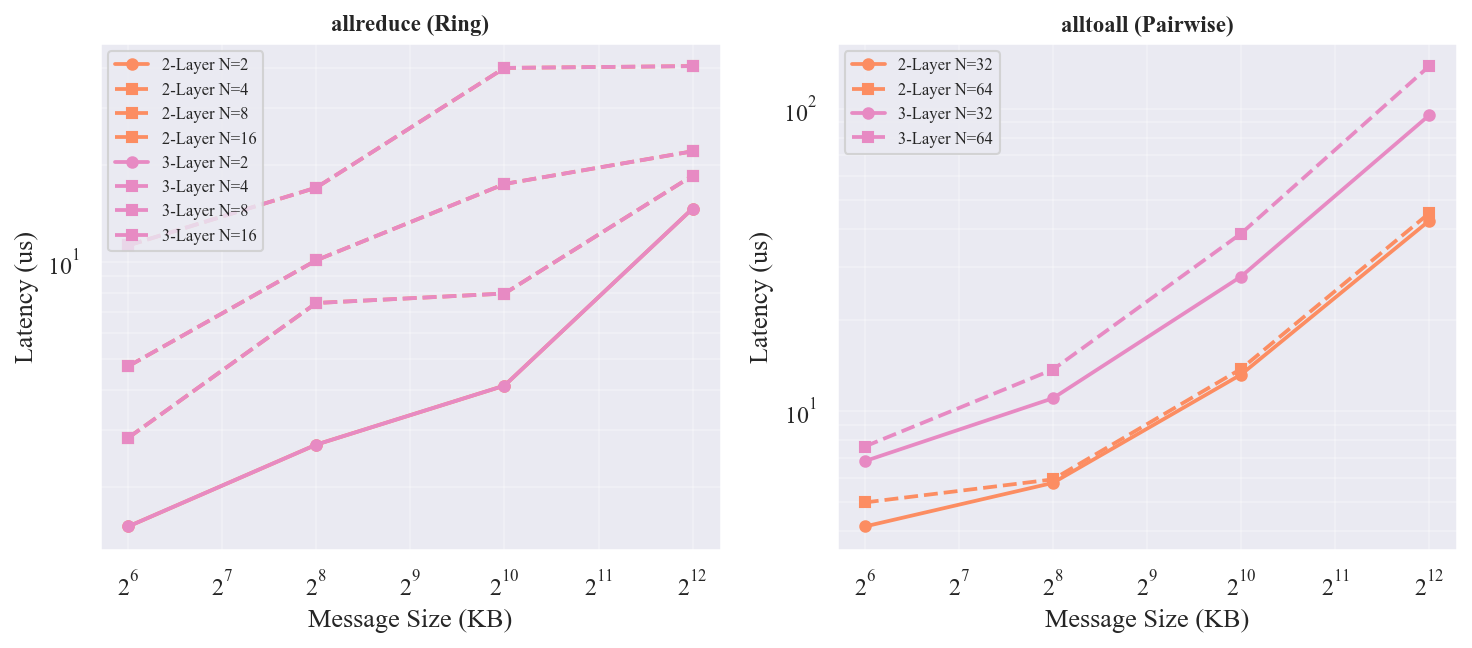
在同参数(k=8, osr=1)下对比 2 层和 3 层 Fat-Tree:
- TP 通信完全相同:板内直连使 TP 不经过交换机,层数无影响
- EP AllToAll 差异巨大:3 层比 2 层慢 2.1x(EP=32)到 2.8x(EP=64)。3 层增加了 Aggregation + Core 两级交换机,跨 pod 通信路径从 4 跳增加到 6 跳,且 Core 层的端口竞争进一步恶化延迟
3 层 Fat-Tree 在 64 芯片规模下没有优势——TP 通信不受影响,EP 通信反而因额外交换机层级显著恶化。3 层 Fat-Tree 的价值体现在更大规模(256+ 芯片),此时 2 层的 spine 端口数成为瓶颈。
超订比影响
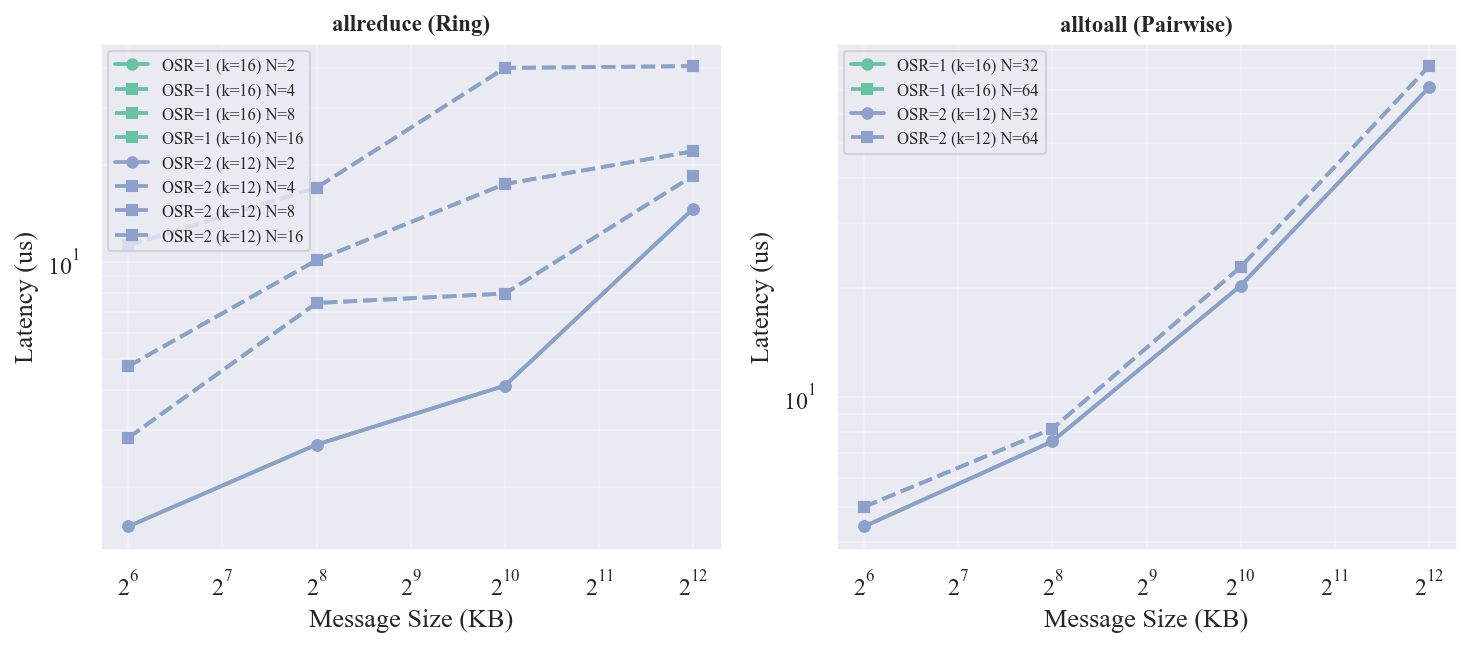
2L-k16-osr1(全等分,8 spine)和 2L-k12-osr2(2:1 超订,4 spine)在同 leaf 粒度(8 芯片/leaf)下的对比:
- TP 通信无差异:板内直连,不经过 spine
- EP Pairwise 无差异:两者延迟完全相同(22.79 us)。Pairwise 的分步调度使每步只有少量芯片对同时通信,4 spine 的等分带宽在分步场景下足够
- EP Bruck 无差异:同为 11.57 us
在 64 芯片、Pairwise/Bruck 调度下,2:1 超订的 Fat-Tree 没有性能损失。这是因为 Pairwise 和 Bruck 都不会在同一时刻让所有芯片对同时通信,流量分散后 4 spine 不构成瓶颈。但如果使用 direct all-pairs(所有芯片对同时通信)或更大规模,超订的带宽限制会显现。
总结
| 发现 | 说明 |
|---|---|
| TP 不受 Fat-Tree 配置影响 | 板内直连使 TP <= 8 不经过交换机,TP=16 跨 board 路径在所有配置中相同 |
| 2L-k8 Pairwise 最快 | 更多 leaf (16 vs 8) 分散跨 leaf 流量,单 leaf 下挂芯片少减少端口竞争 |
| 3L 的 EP 延迟显著高于 2L | 额外交换机层级增加 2 跳 + Core 竞争,EP=64 慢 2.8x |
| 2:1 超订对调度算法无影响 | Pairwise/Bruck 的分步特性避免了 spine 带宽瓶颈 |
| Bruck 在 Fat-Tree 上优势更大 | 步数减少 10x,交换机延迟累积效应被大幅削弱,3L 上加速达 2.83x |
| HD/RD/RH 在大 TP 时显著优于 Ring | TP=16 AllReduce HD 比 Ring 快 4.0x |
@tbl-ft-summary 关键发现汇总