集合通信算法对比分析
概述
本文通过 G5 事件驱动仿真器,系统对比不同集合通信算法在 Ring 拓扑下的性能表现。G5 建模了 PAXI 事务管理、credit 流控、Go-Back-N 重传等微架构细节,能够捕获理论模型无法描述的流水线效应和协议开销。
核心问题:各算法的理论优劣排序,在实际硬件行为仿真下是否成立?
仿真平台
| 参数 | 值 |
|---|---|
| 拓扑 | Ring(双向链路) |
| 链路带宽 | 450 GB/s(模拟 H200 NVLink4) |
| SW 开销 | 26 us |
理论参考模型
Alpha-Beta 模型:$T = \text{steps} \times \alpha + \text{coeff} \times M / \beta$,其中 $\alpha = 2$ us/step,$\beta = 450$ GB/s。
后续分析中,理论预期仅用于设定"算法 A 应该比算法 B 快"的方向性预期,不作为精度校验基线。
实验 1:AllReduce 多算法 × 消息尺寸
配置:N = 8 节点,消息尺寸 1KB ~ 512MB,5 种算法。
| 算法 | 理论 steps | 理论带宽系数 | 特点 |
|---|---|---|---|
| Ring (1-port) | $2(N-1)$ | $2(N-1)/N$ | 可流水线,带宽最优 |
| Ring (2-port) | $2\lceil N/2 \rceil$ | $2(N-1)/N$ | 步数减半,需双 DMA |
| SendRecv | $2(N-1)$ | $2(N-1)/N$ | 每步独立事务 |
| Halving-Doubling | $2\log_2 N$ | $2(N-1)/N$ | 步数最少 |
| Tree (Double Binary) | $2\log_2 N$ | $\log_2 N$ | 步数少但带宽效率低 |
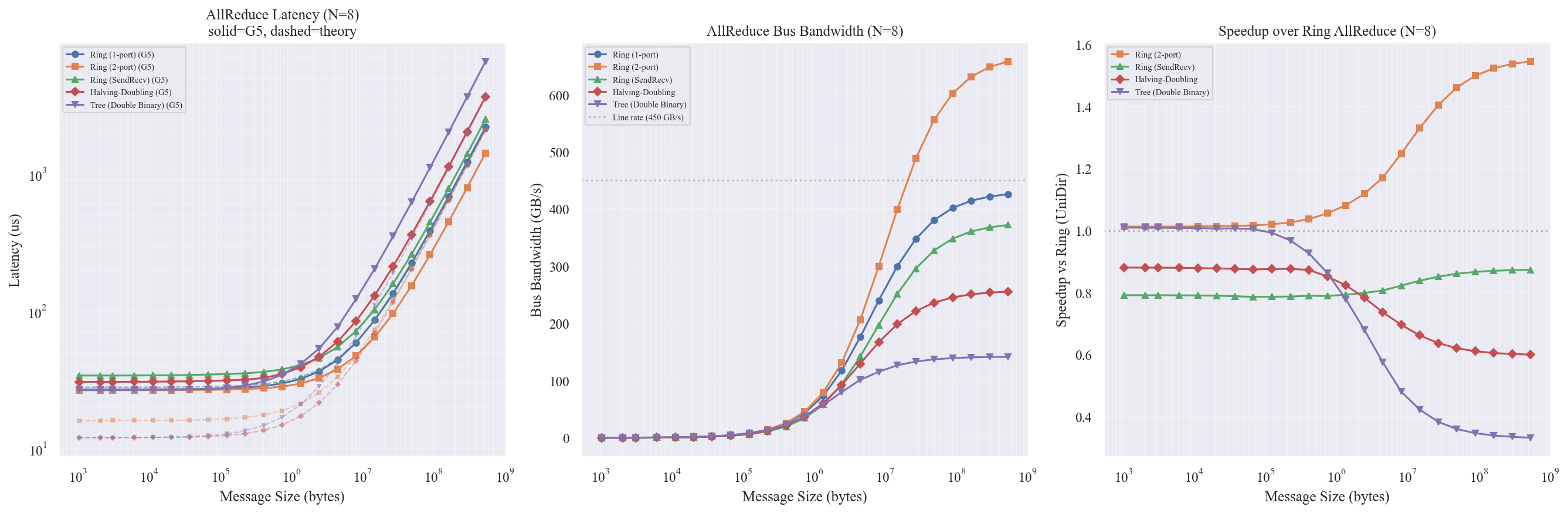
图表解读
左图 — Latency
- Ring (1-port) 在所有消息尺寸下延迟最低或接近最低
- Tree 在大消息区间明显最慢,符合其带宽系数 $\log_2 N$ 远大于 $2(N-1)/N$ 的理论预期(N=8 时差 1.75 倍)
- 小消息区域 (<1MB) 所有算法趋于相同的底噪(~26us SW 开销主导)
中图 — Bus Bandwidth
- Ring (1-port) 大消息时逼近 ~430 GB/s,利用率 ~95%,所有算法中最高
- Tree 仅达 ~240 GB/s,HD 约 ~260 GB/s
- 2-port 在大消息时与 1-port 接近(bandwidth-dominant 区间步数优势被稀释)
右图 — Speedup vs Ring (1-port)
- 所有其他算法的 speedup < 1.0,Ring (1-port) 全面最优
- Tree 在大消息时仅有 Ring 的 ~0.35 倍性能
- HD 约 0.55~0.60 倍,尽管理论步数更少
理论 vs 仿真:关键差异
理论预期 HD 应在小消息时优于 Ring(6 步 vs 14 步的 latency 优势),但仿真中 HD 全面劣于 Ring。原因:
- Ring 的流水线效应:Ring 算法相邻步可以重叠执行(前一步尾部数据传输时后一步头部已开始),实际 latency 开销远小于理论的 $2(N-1) \times \alpha$
- HD 的每步协议开销更高:HD 每步是独立的 PAXI 事务(启动、credit 协商、Send/Recv 握手),实际每步成本 ~3-5us,远超 Ring 流水线中被隐藏的 ~2us
结论
在 Ring 拓扑 + N=8 的配置下,Ring (1-port) 是最优 AllReduce 算法。 理论上 HD/Tree 的 $O(\log N)$ 步数优势,在实际协议栈开销下被完全抵消。
实验 2:AllReduce 算法 × 节点数缩放
配置:M = 64MB,N = 2, 4, 8, 16, 32,4 种算法。
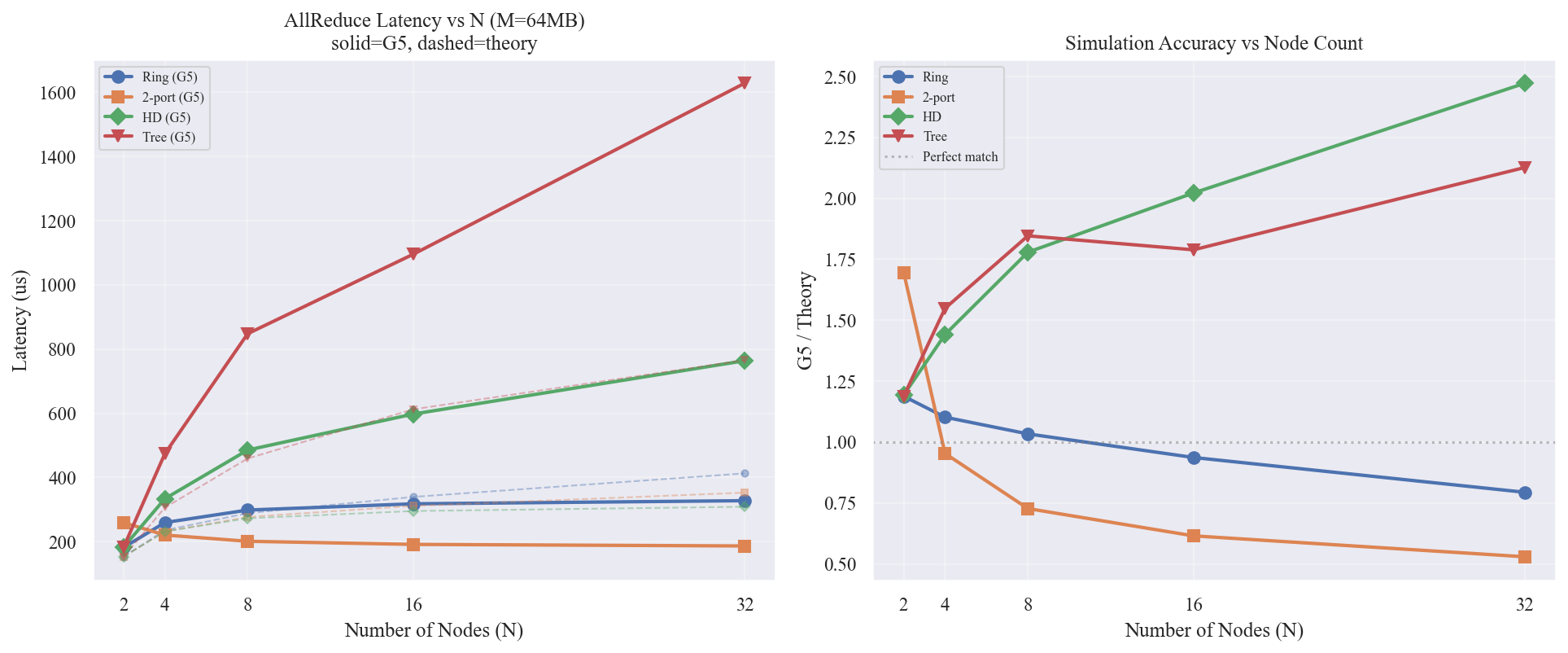
图表解读
左图 — Latency vs N
- Ring (1-port/2-port):延迟随 N 增大增长缓慢(N=2 到 N=32 约 1.8 倍)。M=64MB 时带宽项 $2(N-1)/N \cdot M/\beta \to 2M/\beta \approx 296$us 趋于常数,latency 项被流水线隐藏
- HD:延迟随 N 显著增长(N=2 到 N=32 约 4.2 倍),每步独立事务的开销累积
- Tree:增长最快,N=32 时延迟是 Ring 的 ~5 倍
右图 — Speedup vs Ring (1-port)
- 2-port 随 N 增大加速比扩大(步数减半的收益在 N 大时更明显)
- HD 和 Tree 随 N 增大相对 Ring 越来越慢
关键发现
Ring 的缩放性远优于 HD/Tree。理论上 HD 步数为 $O(\log N)$、Ring 为 $O(N)$,HD 在大 N 时应体现步数优势。但仿真显示相反趋势:
- Ring 的流水线效率随 N 增大而提高(更多步 = 更深的流水线 = 更好的重叠)
- HD 的协议开销随步数线性累积且不可流水线化
这一差异表明:在评估集合通信算法时,不能仅看理论复杂度,必须考虑协议栈的流水线能力。能流水线化的 $O(N)$ 算法可以优于不可流水线的 $O(\log N)$ 算法。
实验 3:跨原语对比
配置:N = 8,Ring 算法,5 种原语,消息 1KB ~ 512MB。
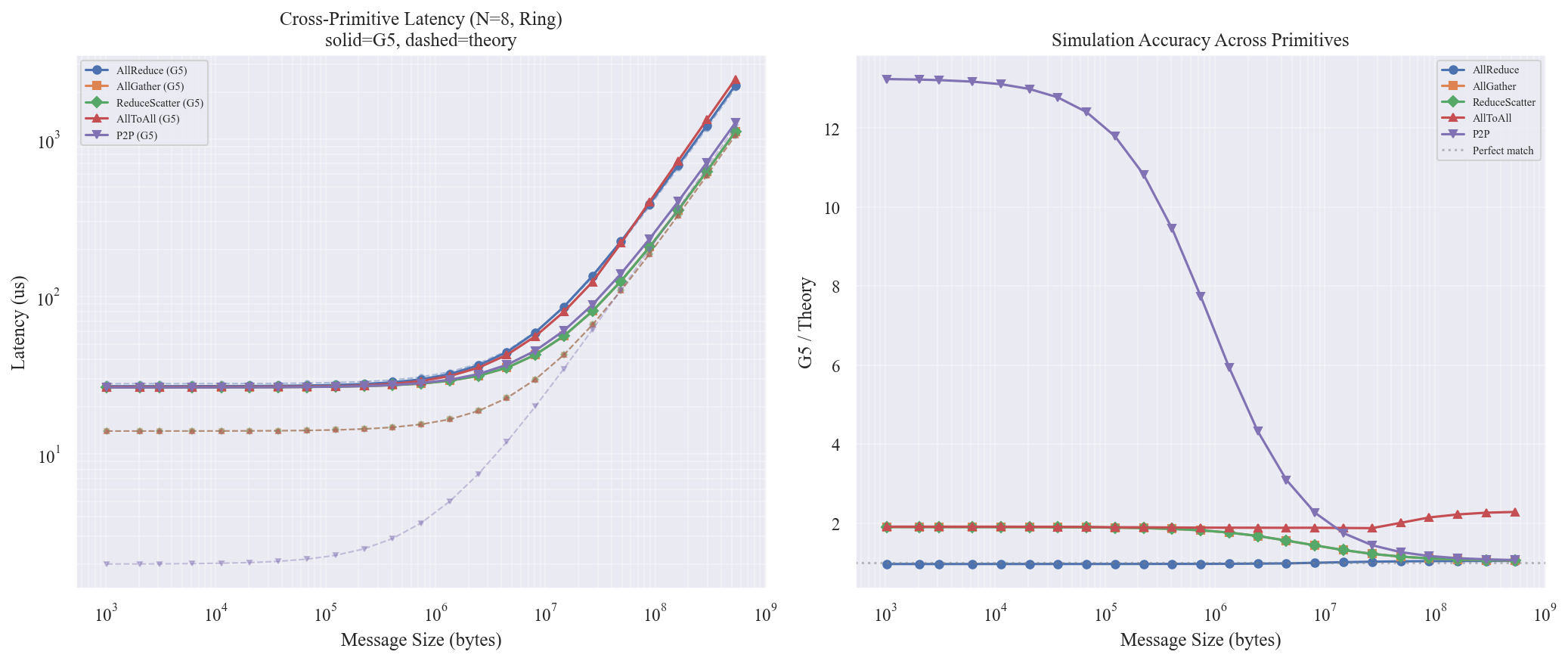
图表解读
左图 — Latency
- AllReduce 延迟约为 AllGather / ReduceScatter 的 2 倍,完全符合 AllReduce = ReduceScatter + AllGather 的组合关系
- AllGather 和 ReduceScatter 曲线完全重合,验证了两者作为对偶操作的对称性
- AllToAll 在大消息时延迟高于 AllGather/ReduceScatter,因为 Pairwise 算法在 Ring 上存在多跳竞争
- P2P 最快(仅 2 个参与者)
右图 — Normalized Latency (相对于 AllReduce)
- AllGather / ReduceScatter 稳定在 ~0.5x,确认了组合关系
- P2P 在大消息时趋向 ~0.5x(单向传输 vs AllReduce 的双向)
- AllToAll 在大消息时比例上升,反映了 Ring 拓扑上的多跳竞争加剧
结论
- AllReduce = ReduceScatter + AllGather 关系在仿真中完全成立
- AllGather 和 ReduceScatter 完全对称,选择哪个取决于应用语义而非性能
- AllToAll Pairwise 在 Ring 拓扑上效率较低,远距离节点需多跳转发,链路竞争严重
实验 4:2-port vs 1-port 加速比
配置:M = 16MB,N = 4, 8, 16, 32,3 种原语。
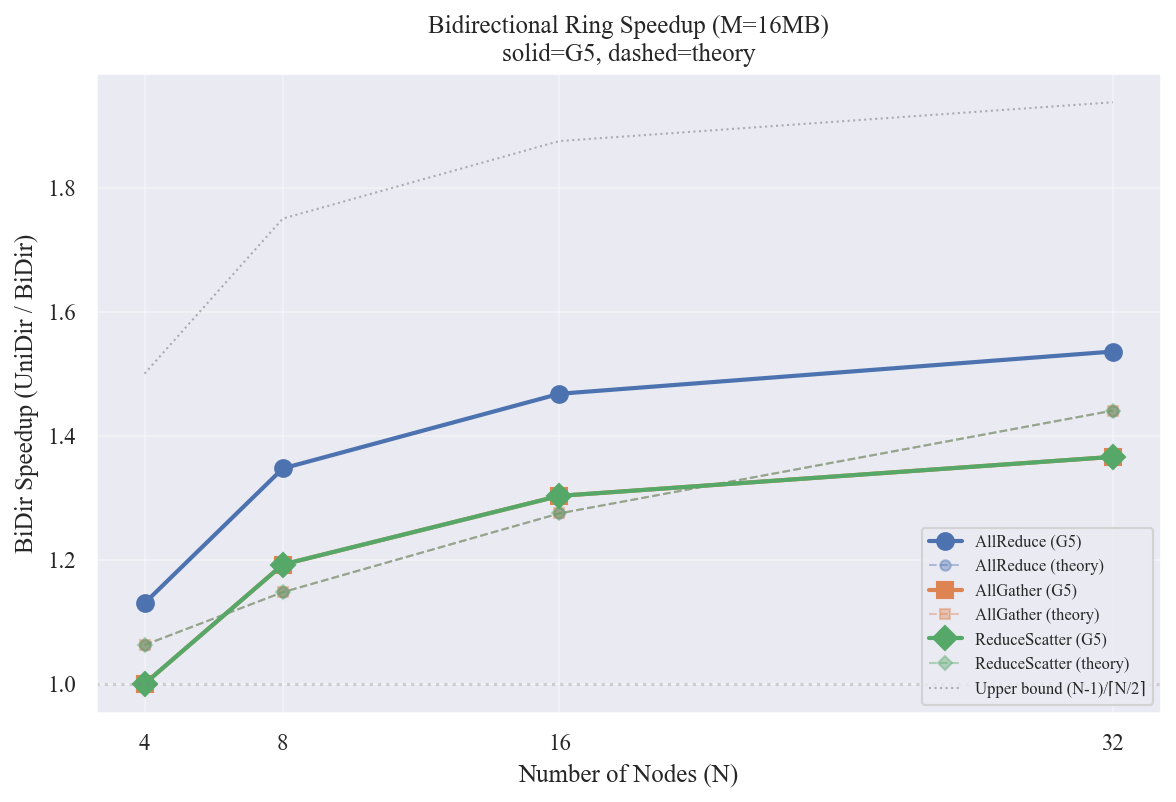
图表解读
实线为仿真结果,虚线为理论预期。
| N | AllReduce 1-port | AllReduce 2-port | 仿真加速比 | 理论加速比 |
|---|---|---|---|---|
| 4 | 84.6 us | 74.9 us | 1.13x | 1.06x |
| 8 | 94.4 us | 70.0 us | 1.35x | 1.15x |
| 16 | 99.2 us | 67.6 us | 1.47x | 1.27x |
| 32 | 102.0 us | 66.4 us | 1.54x | 1.44x |
仿真加速比超过理论值,原因:
- 1-port 的流水线效应使理论计算的 $T_\text{1-port}$ 偏高(理论加速比偏保守)
- 2-port 的两个独立 CDMAUnit(CW/CCW)在 PAXI/RC Link 层面真正并行提交事务,获得了超越"步数减半"的额外收益
AllGather 和 ReduceScatter 的加速趋势与 AllReduce 一致。
结论
2-port(双向 Ring)在所有原语上都带来显著加速,加速比随 N 增大而扩大,且实际收益超过理论预期。硬件支持双独立 DMA 通道时应优先使用 2-port 算法。
实验 5:AllGather 多算法 × 消息尺寸
配置:N = 8 节点,消息尺寸 1KB ~ 512MB,3 种算法。
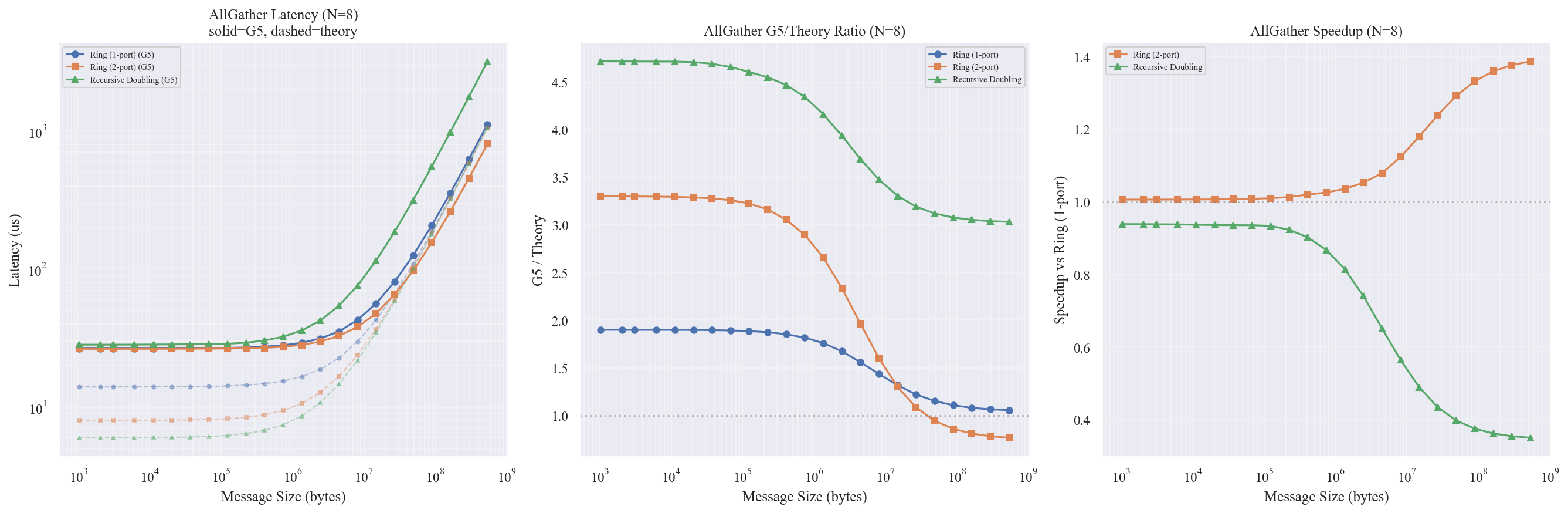
图表解读
左图 — Latency:Ring (1-port/2-port) 在大消息时远优于 Recursive Doubling。512MB 时 Ring 2-port 约 805us,RD 约 3184us(4 倍差距)。
右图 — Speedup:2-port 在中大消息区间加速明显;RD 全程 speedup < 1.0。
理论 vs 仿真
理论预期 RD 应在小消息时优于 Ring($\log_2 N = 3$ 步 vs $N-1 = 7$ 步),但仿真中 RD 在所有消息尺寸下都更慢。
原因与 AllReduce HD 相同:RD 每步的协议开销 (~9us) 远超 Ring 流水线的等效开销。此外,RD 的通信对距离按 $2^j$ 跳跃,在 Ring 拓扑上意味着多跳路由和链路竞争。RD 的理论优势需要 Hypercube 或全连接拓扑才能体现。
实验 6:ReduceScatter 多算法 × 消息尺寸
配置:N = 8 节点,消息尺寸 1KB ~ 512MB,3 种算法。
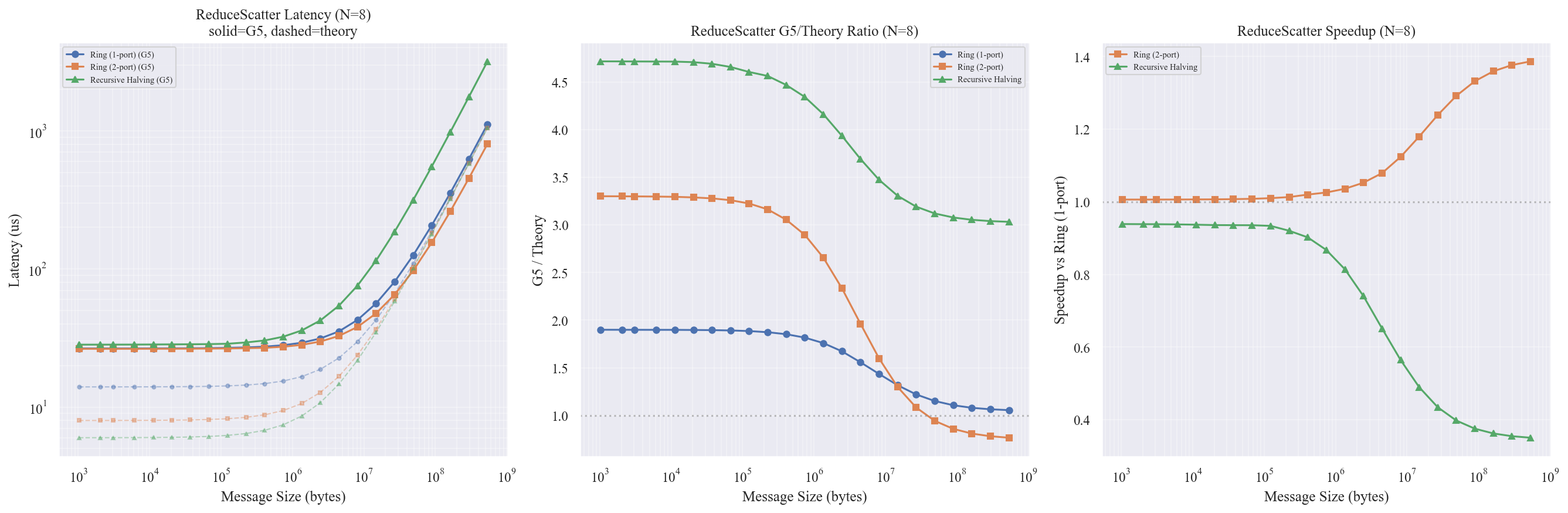
结果与实验 5(AllGather)高度对称,验证了 Recursive Halving 和 Recursive Doubling 的对偶关系在仿真中成立。
- Ring (1-port/2-port) 全面优于 Recursive Halving
- RH 的性能劣势程度与 RD 完全一致
实验 7:AllToAll Pairwise vs Bruck
配置:N = 8 节点,消息尺寸 1KB ~ 512MB。
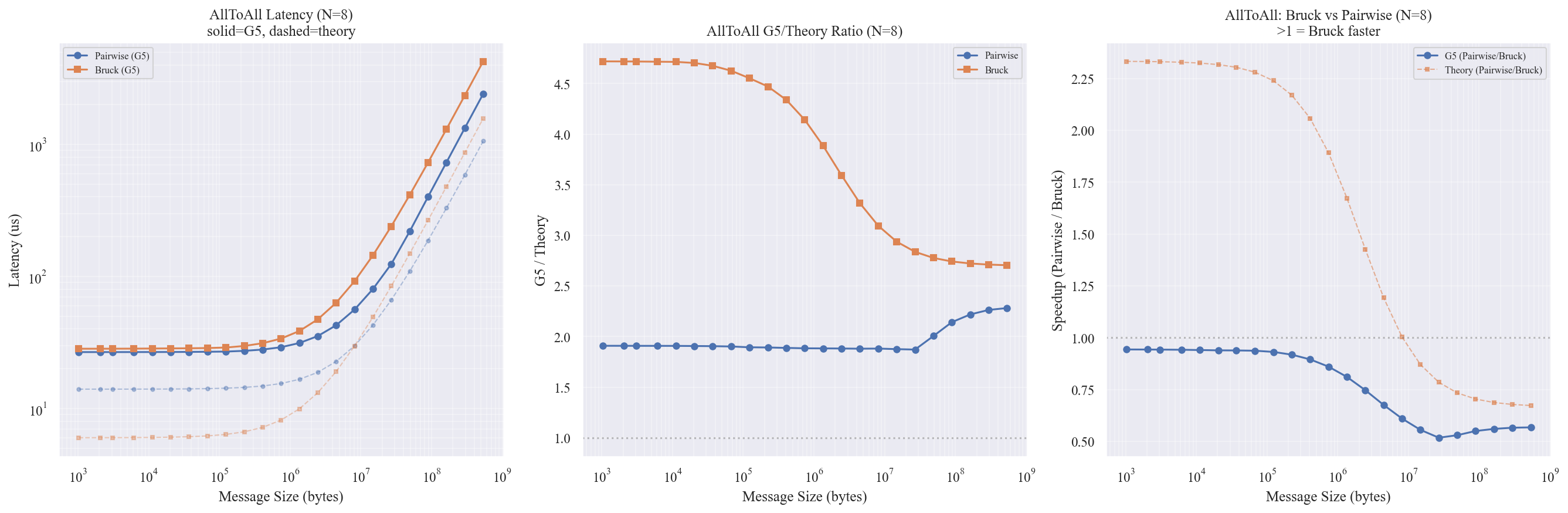
图表解读
左图 — Latency:Pairwise 在所有消息尺寸下都快于 Bruck。512MB 时 Pairwise 2397us vs Bruck 4252us。
右图 — Speedup:Pairwise 相对 Bruck 全程有 1.3x ~ 1.8x 加速。
理论 vs 仿真
理论预期 Bruck 应在小消息时优于 Pairwise($\log_2 N = 3$ 步 vs $N-1 = 7$ 步),但仿真中 Pairwise 全面胜出。
原因:Pairwise 使用 Transfer 操作(可流水线),Bruck 使用 Send/Recv(每步独立事务,协议开销 ~9us)。步数优势不足以弥补每步开销差异。
Bruck 的适用前提是低协议开销环境(硬件 $\alpha$ 接近 1us),在当前 PAXI 协议栈下不具竞争力。
总体结论
算法选择指南
| 原语 | Ring 拓扑最优算法 | 理由 |
|---|---|---|
| AllReduce | Ring (2-port > 1-port) | 流水线效率最高,带宽利用率 ~95% |
| AllGather | Ring (2-port > 1-port) | 同上,RD 在 Ring 上不具竞争力 |
| ReduceScatter | Ring (2-port > 1-port) | 同上,RH 在 Ring 上不具竞争力 |
| AllToAll | Pairwise | Transfer 可流水线,Bruck 协议开销过高 |
流水线效应:理论与实践的核心差异
本实验揭示的最重要规律是流水线能力决定实际性能排序:
- 可流水线算法(Ring、Pairwise):相邻步数据传输可重叠,步间 latency 被隐藏,大 N 时效率提高
- 不可流水线算法(HD、Tree、RD/RH、Bruck):每步是独立事务,协议开销线性累积
因此,理论复杂度 $O(\log N)$ 步的算法在实际中可能劣于 $O(N)$ 步的流水线算法。选择集合通信算法时,必须同时考虑步数和每步的协议开销特征。
拓扑适配性
以上结论基于 Ring 拓扑。在其他拓扑下:
- 全连接/NVSwitch:HD/RD/Bruck 的多跳竞争消失,步数优势可能体现
- Hypercube:RD 每步直连,理论优势成立
- Fat-tree:需要拓扑感知的算法调度
后续方向
| 方向 | 目的 |
|---|---|
| Ring AllToAll | 消除 Pairwise 的多跳竞争,预期 Ring 拓扑最优 |
| 全连接拓扑验证 | HD/RD 在理想拓扑下是否反超 Ring |
| num_chunks 流水线深度 | 增加分片数是否能改善 HD/Tree |
| NCCL 实测数据对齐 | 用硬件实测数据校验仿真结论 |
运行方式
# 运行全部 7 个实验
python3 run_all_experiments.py
# 运行单个实验
python3 run_all_experiments.py 1 # AllReduce 多算法 × 消息尺寸
python3 run_all_experiments.py 2 # AllReduce × 节点数缩放
python3 run_all_experiments.py 3 # 跨原语对比
python3 run_all_experiments.py 4 # 2-port vs 1-port 加速比
python3 run_all_experiments.py 5 # AllGather 多算法 × 消息尺寸
python3 run_all_experiments.py 6 # ReduceScatter 多算法 × 消息尺寸
python3 run_all_experiments.py 7 # AllToAll Pairwise vs Bruck
# 组合运行
python3 run_all_experiments.py 5 6 7 # 实验 5 + 6 + 7
图表输出至 plots/ 目录。